A Jina AI e a Elastic estão lançando jina-embeddings-v5-text, uma família de novos modelos compactos de incorporação de texto de alto desempenho, com desempenho de última geração para modelos de tamanho comparável em todos os principais tipos de tarefas.
A família inclui dois modelos:
jina-embeddings-v5-text-smalljina-embeddings-v5-text-nano
Esses modelos são o resultado bem-sucedido de uma nova receita inovadora de treinamento para incorporação de modelos. Ambos superam modelos muitas vezes maiores que eles, gerando economia de memória e recursos computacionais e respondendo mais rápido a solicitações.
O modelo jina-embeddings-v5-text-small possui 677 milhões de parâmetros, é compatível com uma janela de contexto de entrada de 32.768 tokens e gera embeddings de 1.024 dimensões por padrão.
jina-embeddings-v5-text-nano Pesa cerca de um terço do tamanho da nova versão, com 239 milhões de parâmetros e uma janela de contexto de entrada de 8.192 tokens, resultando em embeddings de dimensão 768 compactos.
| Nome do modelo | Tamanho total | Tamanho da janela de contexto de entrada | Tamanho do embedding |
|---|---|---|---|
| jina-v5-text-small | 677M params | 32.768 tokens | 1.024 dims |
| jina-v5-text-nano | 239M params | 8.192 tokens | 768 dimensões |
Esses dois modelos são os melhores da categoria para o desempenho geral do benchmark MMTEB (Multilingual MTEB). Entre os modelos com menos de 500M, jina-embeddings-v5-text-nano é o de melhor desempenho, apesar de ter menos de 250M, e o modelo jina-embeddings-v5-text-small é o líder entre os modelos de embedding multilíngue com menos de 750M.
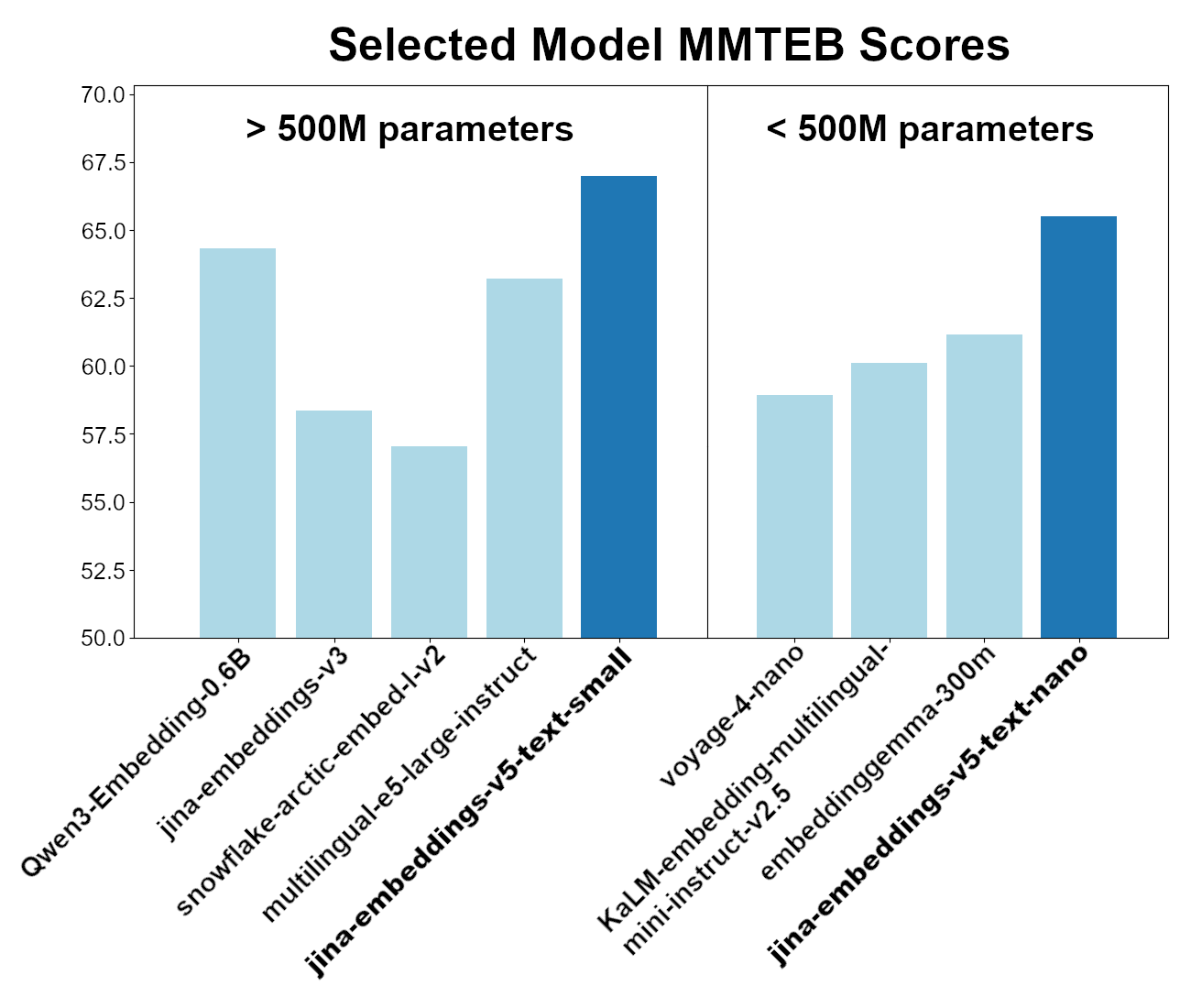
Esses modelos estão disponíveis por meio do Elastic Inference Service (EIS), de uma API online e para hospedagem local. Para instruções sobre como acessar os modelos jina-embeddings-v5-text, veja a seção "Começar" abaixo.
Modelos de incorporação e indexação semântica aumentam muito a precisão dos algoritmos de busca, mas também têm uma variedade de outros usos para tarefas envolvendo similaridade semântica e extração de significado, por exemplo:
- Encontrando textos duplicados.
- Reconhecendo paráfrases e traduções.
- Descoberta de tópicos.
- Mecanismos de recomendação.
- Análise de sentimentos e intenções.
- Filtragem de spam.
- E muitos outros.
Recursos
Essa nova família de modelos possui uma série de recursos projetados para aumentar a relevância e reduzir custos.
Otimização de tarefas
Otimizamos os modelos jina-embeddings-v5-text para quatro tipos amplos de tarefas:
| Tarefa | Exemplos de casos de uso |
|---|---|
| Recuperação | Busca com consultas em linguagem natural e recuperação das correspondências mais relevantes em um conjunto de documentos. |
| Correspondência de texto | Similaridade semântica, desduplicação, alinhamento de paráfrases e traduções, e muito mais. |
| Clustering | Descoberta de tópicos, organização automática de coleções de documentos. |
| Classificação | Categorização de documentos, detecção de sentimentos e intenções, tarefas similares. |
Otimizar para uma tarefa geralmente significa ter que ceder em outra, então a maioria dos modelos de embedding só tem desempenho competitivo para um tipo de tarefa. Mas os modelos jina-embeddings-v5-text são capazes de se especializar em todas as quatro áreas sem comprometer o desempenho, treinando adaptadores compactos de Low-Rank Adaptation (LoRA) específicos para cada tarefa.
Adaptadores LoRA são uma espécie de plugin para um modelo de IA que muda o comportamento, aumentando ligeiramente o tamanho total. Em vez de ter um modelo inteiro para cada tarefa, cada um com centenas de milhões de parâmetros, a família de modelos jina-embeddings-v5-text permite que você use um modelo com um adaptador compacto LoRA para cada tarefa. Isso economiza memória, espaço de armazenamento e custos de inferência.
Truncando embeddings
Treinamos os modelos jina-embeddings-v5-text usando o Aprendizado de representação Matryoshka, que permite reduzir seus embeddings para tamanhos menores com um custo mínimo para a qualidade deles.
Por padrão, jina-embeddings-v5-text-small gera vetores de embedding de 1024 dimensões, cada um representado por um número de 16 bits, fazendo com que cada embedding tenha 2KB de tamanho. Para um grande conjunto de documentos, isso pode representar uma grande quantidade de dados para armazenar, e a busca em um banco de dados vetorial repleto de embeddings é proporcional tanto ao tamanho do banco de dados quanto ao número de dimensões que cada vetor armazenado possui.
Mas você pode reduzir pela metade o tamanho dos embeddings (descartar 512 das 1024 dimensões) e ocupar metade do espaço enquanto dobra a velocidade das buscas. Isso tem um impacto no desempenho. Descartar informações reduz a precisão. Mas, como mostra o gráfico abaixo, mesmo ao eliminar metade do embedding, a redução de desempenho é mínima:
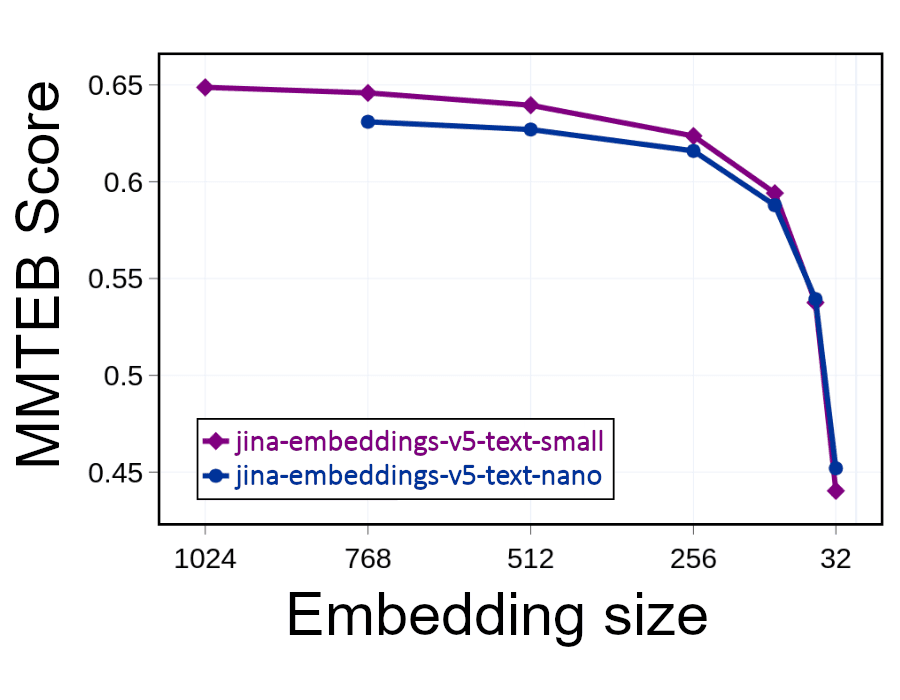
Desde que suas embeddings tenham pelo menos 256 dimensões, a perda de precisão deve permanecer relativamente pequena. Abaixo desse nível, porém, a relevância e a precisão se deterioram rapidamente.
Truncar embeddings como esse permite aos usuários gerenciar as próprias trocas entre precisão e custos computacionais. Ela oferece ferramentas para ter grandes ganhos de eficiência e grandes economias de custos com a IA de busca.
Quantização robusta
Quantização é outra forma de reduzir o tamanho das embeddings. Em vez de descartar parte de cada incorporação, a quantização reduz a precisão dos números na embedding. Os modelos jina-embeddings-v5-text geram embeddings com números de 16 bits, mas podemos arredondar esses números, reduzindo a precisão e o número de bits necessários para armazená-los. No caso mais extremo, podemos reduzir cada número a um bit (0 ou 1), comprimindo as embeddings padrão de 1024 dimensões de jina-embeddings-v5-textde 2 kilobytes para 128 bytes, uma redução de 94% apenas com a quantização binária. Assim como para a truncagem, isso produz grandes economias em memória e custos computacionais. No entanto, assim como a truncagem, a quantização torna as embeddings menos precisas.
Treinamos os modelos jina-embeddings-v5-text para funcionar com a Better Binary Quantization (BBQ) do Elasticsearch, minimizando a perda de precisão. Os testes de benchmark de embeddings binarizados desses modelos mostram desempenho quase igual aos equivalentes não binarizados. Consulte o relatório técnico para estudos detalhados de ablação sobre o desempenho da binarização.
Desempenho multilíngue
Muitos modelos de embedding são multilíngues porque foram treinados com materiais que incluem um grande número de linguagens. Mas isso não significa que todos tenham o mesmo desempenho em todas as linguagens disponíveis.
Identificamos 211 linguagens no benchmark multilíngue MMTEB e os separamos para que pudéssemos comparar nossos modelos com modelos semelhantes linguagem por linguagem. A imagem abaixo resume nossos resultados como um mapa de calor. Cada patch é uma linguagem (identificada pelo código ISO-639), e quanto mais verde ela é, melhor o modelo teve desempenho em comparação com a média de modelos similares:

Embora a precisão varie entre as linguagens, os modelos jina-embeddings-v5-text são de ponta ou quase isso na maioria das linguagens do mundo.
Para saber detalhes sobre o desempenho multilíngue, consulte o jina-embeddings-v5-text relatório técnico.
Jina no Elastic: IA nativa de última geração para busca
Com jina-embeddings-v5-text modelos no EIS, você pode executar modelos de embedding multilíngue de alto desempenho de forma nativa no Elasticsearch, com inferência totalmente gerenciada e acelerada por GPU, sem infraestrutura para provisão ou redimensionamento. jina-embeddings-v5-text modelos ampliam o catálogo cada vez maior de modelos EIS com modelos compactos e multilíngues, impulsionados pelos mais recentes avanços em IA. Esses modelos têm desempenho de ponta em recuperação de informações e benchmarks padrão de análise de dados, além de oferecer suporte multilíngue incomparável e global.
Com dois modelos de tamanhos muito diferentes, os usuários podem definir qual é o mais adequado para as aplicações e orçamentos. Além disso, com embeddings robustas que mantêm o desempenho quando truncadas para tamanhos menores ou quantizadas com menor precisão, jina-embeddings-v5-text modelos oferecem oportunidades para economias concretas adicionais em custos de armazenamento e computação, bem como na latência de processamento.
Com a família jina-embeddings-v5-text , Jina Reranker e a busca vetorial rápida e BM25 da Elastic, os usuários agora têm acesso à busca híbrida de ponta a ponta e de última geração da Elastic. Quando você precisa dos resultados mais relevantes, seja para pipelines de Retrieval-Augmented Generation (RAG), aplicações de busca ou análise de dados, a Elastic com modelos de IA de busca Jina oferece qualidade sólida e econômica.
Para começar
Os modelos jina-embeddings-v5-text estão totalmente integrados ao EIS e você pode usá-los definindo o type campo para semantic_text ao criar seu índice e especificar o modelo (jina-embeddings-v5-text-small ou jina-embeddings-v5-text-nano) no inference_id campo, como neste exemplo:
O Elasticsearch seleciona automaticamente o adaptador LoRA apropriado durante a indexação e a recuperação. As dimensões de embedding (veja a seção "Truncando embeddings ", acima) podem ser definidas ao criar um endpoint de inferência personalizado.
Consulte a documentação do Elasticsearch para saber mais informações sobre como usar os modelos jina-embeddings-v5-text .
Mais informações
Para saber mais sobre os modelos jina-embeddings-v5-text , leia as notas de lançamento no blog da Jina AI e o relatório técnico, que contém informações técnicas mais detalhadas sobre o desempenho e o novo procedimento de treinamento inovador da Jina AI. Para saber informações sobre como fazer download e executar esses modelos de forma local, acesse a página da coleção jina-embeddings-v5-textna Hugging Face.
Os modelos de Jina AI estão disponíveis sob a licença CC-BY-NC-4.0, portanto, você pode baixá-los e experimentá-los de forma livre, mas para uso comercial, entre em contato com a equipe de vendas da Elastic.
Conteúdo relacionado

11 de maio de 2026
Um índice, todas as mídias: Apresentando jina-embeddings-v5-omni
O jina-embeddings-v5-omni permite incorporar texto, imagens, vídeos e áudio em um único índice do Elasticsearch e realizar consultas em todos eles simultaneamente.

22 de abril de 2026
Jina embeddings v3 agora disponível no Gemini Enterprise Agent Platform Model Garden
O modelo de busca Jina, jina-embeddings-v3, agora é autoimplantável na plataforma Gemini Enterprise Agent Platform Model Garden, com mais novidades por vir. Execute jina-embeddings-v3 em uma única GPU L4 dentro da sua própria VPC.
1 de janeiro de 2026
Uma introdução aos modelos Jina, sua funcionalidade e seus usos no Elasticsearch
Confira os embeddings multimodais Jina, o Reranker v3 e os modelos semânticos de embedding, além de como usá-los nativamente no Elasticsearch.

22 de maio de 2026
Kibana reduz o tempo de carregamento do dashboard em até 25% — aqui está a estratégia de sondagem por trás disso
Descubra como o Kibana usa sondagem contínua e detecção de HTTP/2 no navegador para reduzir o tempo de carregamento do dashboard em até 25%, com recurso automático ao HTTP/1.

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.