O Jina by Elastic fornece modelos de base para busca voltados a aplicações e automação de processos de negócio. Esses modelos oferecem funcionalidades essenciais para levar IA a aplicações no Elasticsearch e a projetos inovadores baseados em IA.
Os modelos Jina se enquadram em três grandes categorias, projetadas para dar suporte ao processamento, à organização e à recuperação de informações:
- Modelos de embedding semântico
- Modelos de reclassificação
- Modelos de linguagem generativos de pequeno porte
Modelos de embedding semântico
A ideia por trás dos embeddings semânticos é que um modelo de IA pode aprender a representar aspectos do significado de suas entradas em termos da geometria de espaços de alta dimensionalidade.
É possível pensar em um embedding semântico como um ponto (tecnicamente, um vetor) em um espaço de alta dimensionalidade. Um modelo de embedding é uma rede neural que recebe algum tipo de dado digital como entrada, potencialmente qualquer tipo, mas mais comumente texto ou imagem, e produz a localização de um ponto correspondente em um espaço de alta dimensionalidade, representada por um conjunto de coordenadas numéricas. Quando o modelo executa bem sua função, a distância entre dois embeddings semânticos é proporcional ao quanto os objetos digitais correspondentes compartilham o mesmo significado.
Para entender por que isso é importante para aplicações de busca, imagine um embedding para a palavra “cão” e outro para a palavra “gato” como pontos em um espaço.
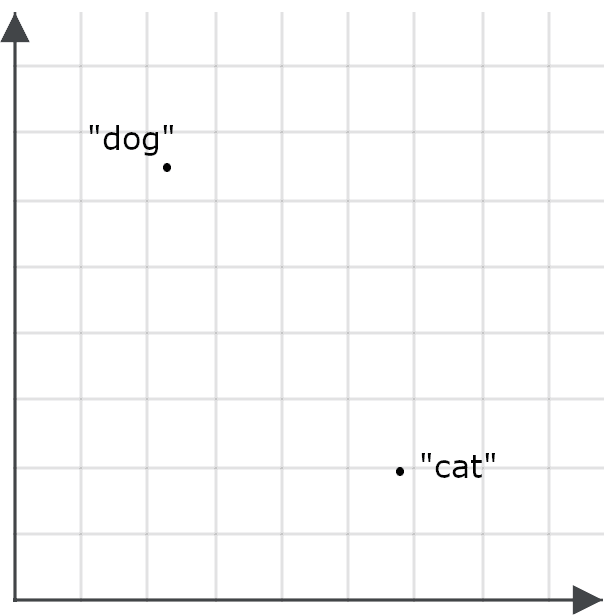
Um bom modelo de embedding deve gerar um embedding para a palavra “felino” muito mais próximo de “gato” do que de “cão”, e “canino” deve ter um embedding muito mais próximo de “cão” do que de “gato”, porque essas palavras têm praticamente o mesmo significado.

Se um modelo for multilíngue, espera-se o mesmo comportamento para traduções de “gato” e “cão” em outros idiomas.

Modelos de embedding traduzem similaridade ou dissimilaridade de significado entre elementos em relações espaciais entre embeddings. As imagens acima têm apenas duas dimensões para que seja possível visualizá-las na tela, mas modelos de embedding produzem vetores com dezenas a milhares de dimensões. Isso permite codificar sutilezas de significado para textos inteiros, atribuindo um ponto em um espaço com centenas ou milhares de dimensões a documentos com milhares de palavras ou mais.
Embeddings multimodais
Modelos multimodais estendem o conceito de embeddings semânticos para além de textos, especialmente para imagens. Espera-se que o embedding de uma imagem fique próximo ao embedding de uma descrição fiel dessa imagem.
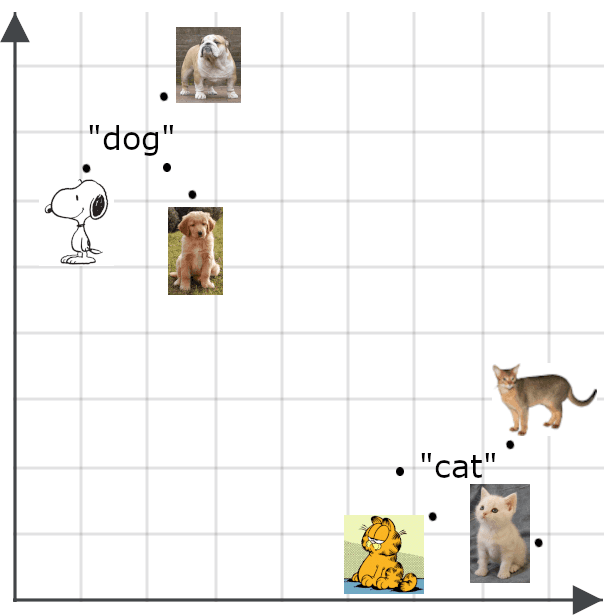
Embeddings semânticos têm muitos usos. Entre outras aplicações, é possível usá-los para criar classificadores eficientes, realizar clustering de dados e executar diversas tarefas, como deduplicação de dados e investigação da diversidade dos dados, ambas importantes para aplicações de big data que lidam com volumes de informação grandes demais para serem gerenciados manualmente.
O principal uso direto de embeddings está na recuperação de informações. O Elasticsearch pode armazenar objetos de recuperação com embeddings como chaves. As consultas são convertidas em vetores de embedding, e a busca retorna os objetos armazenados cujas chaves estão mais próximas do embedding da consulta.
Enquanto a recuperação tradicional baseada em vetores (às vezes chamada de recuperação por vetores esparsos) usa vetores baseados em palavras ou metadados presentes em documentos e consultas, a recuperação baseada em embeddings (também conhecida como recuperação por vetores densos) usa significados avaliados por IA em vez de palavras. Isso a torna, em geral, muito mais flexível e mais precisa do que métodos tradicionais de busca.
Aprendizado de representação Matryoshka
O número de dimensões de um embedding, assim como a precisão dos valores numéricos que o compõem, tem impactos significativos na performance. Espaços de dimensionalidade muito alta e números de precisão extremamente elevada podem representar informações altamente detalhadas e complexas, mas exigem modelos de IA maiores, mais caros para treinar e para executar. Os vetores que esses modelos geram requerem mais espaço de armazenamento, e são necessários mais ciclos de computação para calcular as distâncias entre eles. Usar modelos de embedding semântico envolve fazer concessões importantes entre precisão e consumo de recursos.
Para maximizar a flexibilidade para os usuários, os modelos Jina são treinados com uma técnica chamada Aprendizado de Representação Matryoshka. Essa abordagem faz com que os modelos concentrem as distinções semânticas mais importantes nas primeiras dimensões do vetor de embedding, de modo que seja possível descartar as dimensões mais altas e ainda assim obter bom desempenho.
Na prática, isso significa que usuários dos modelos Jina podem escolher quantas dimensões desejam que seus embeddings tenham. Escolher menos dimensões reduz a precisão, mas a degradação de performance é pequena. Na maioria das tarefas, as métricas de performance dos modelos Jina caem entre 1% e 2% sempre que o tamanho do embedding é reduzido em 50%, até uma redução total de cerca de 95% no tamanho.
Recuperação assimétrica
A similaridade semântica geralmente é medida de forma simétrica. O valor obtido ao comparar “gato” com “cão” é o mesmo que ao comparar “cão” com “gato”. No entanto, quando embeddings são usados para recuperação de informações, o desempenho melhora quando essa simetria é quebrada e as consultas são codificadas de forma diferente dos objetos de recuperação.
Isso ocorre por causa da forma como treinamos modelos de embedding. Os dados de treinamento contêm ocorrências dos mesmos elementos, como palavras, em muitos contextos diferentes, e os modelos aprendem semântica comparando similaridades e diferenças contextuais entre esses elementos.
Assim, por exemplo, pode acontecer de a palavra “animal” não aparecer em muitos dos mesmos contextos que “gato” ou “cão”, e, portanto, o embedding de “animal” não ficar particularmente próximo de “gato” ou “cão”.
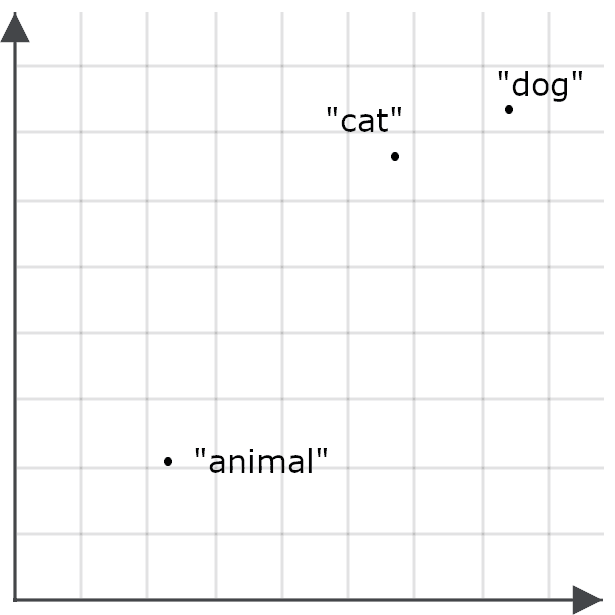
Isso torna menos provável que uma consulta por “animal” recupere documentos sobre gatos e cães — justamente o oposto do nosso objetivo. Por isso, em vez disso, codificamos “animal” de forma diferente quando ele aparece como consulta do que quando é um alvo de recuperação.
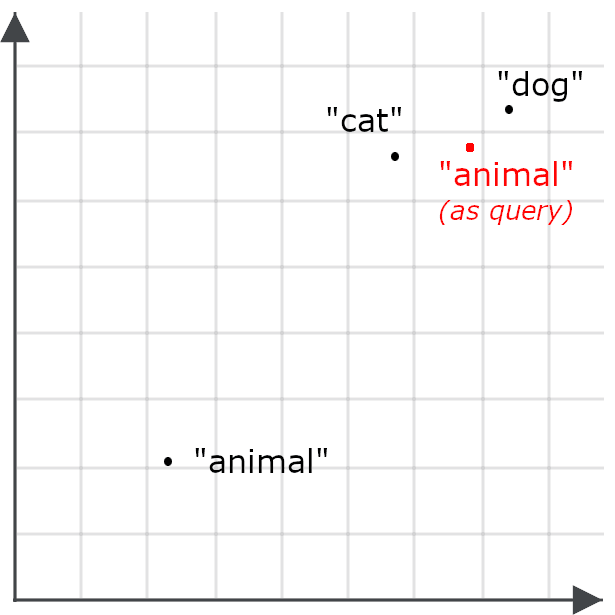
Recuperação assimétrica significa usar um modelo diferente para consultas ou treinar especificamente um modelo de embedding para codificar os dados de uma forma quando são armazenados para recuperação e de outra forma quando são usados como consultas.
Embeddings multivetoriais
Embeddings únicos funcionam bem para recuperação de informações porque se encaixam no modelo básico de um banco de dados indexado: armazenamos objetos para recuperação usando um único vetor de embedding como chave de recuperação. Quando usuários consultam o repositório de documentos, suas consultas são traduzidas em vetores de embedding, e os documentos cujas chaves estão mais próximas do embedding da consulta, no espaço de embeddings de alta dimensionalidade, são recuperados como candidatos.
Embeddings multivetoriais funcionam de forma um pouco diferente. Em vez de gerar um vetor de comprimento fixo para representar uma consulta e um objeto armazenado inteiro, eles produzem uma sequência de embeddings que representam partes menores desses elementos. Essas partes geralmente são tokens ou palavras no caso de textos, e blocos de imagem no caso de dados visuais. Esses embeddings refletem o significado de cada parte dentro de seu contexto.
Por exemplo, considere estas frases:
- Ela tinha um coração de ouro.
- Ela fez das tripas coração.
- Ela teve um ataque do coração.
Superficialmente, essas frases parecem muito semelhantes, mas um modelo multivetorial provavelmente geraria embeddings bem diferentes para cada ocorrência de “coração”, representando como cada uma assume um significado distinto no contexto da frase como um todo.
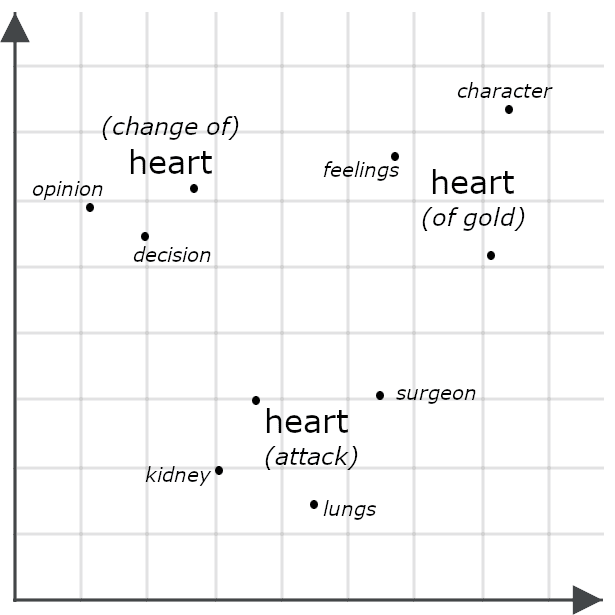
Comparar dois objetos por meio de seus embeddings multivetoriais geralmente envolve medir a distância de Chamfer: comparar cada parte de um embedding multivetorial com cada parte de outro e somar as menores distâncias entre elas. Outros sistemas, incluindo os reclassificadores Jina descritos abaixo, usam esses embeddings como entrada para um modelo de IA treinado especificamente para avaliar sua similaridade. Ambas as abordagens normalmente apresentam maior precisão do que a simples comparação de embeddings de vetor único, porque embeddings multivetoriais contêm informações muito mais detalhadas do que embeddings de vetor único.
No entanto, embeddings multivetoriais não são adequados para indexação. Eles costumam ser usados em tarefas de reclassificação, conforme descrito para o modelo jina-colbert-v2 na próxima seção.
Modelos de embedding Jina
Jina embeddings v4
jina-embeddings-v4 é um modelo de embedding multilíngue e multimodal, com 3,8 bilhões (3,8 × 10⁹) de parâmetros, que oferece suporte a imagens e textos em diversos idiomas amplamente utilizados. Ele utiliza uma arquitetura inédita para aproveitar conhecimento visual e conhecimento linguístico, melhorando o desempenho em ambas as tarefas e permitindo que o modelo se destaque na recuperação de imagens e, especialmente, na recuperação de documentos visuais. Isso significa que ele lida bem com imagens como gráficos, slides, mapas, capturas de tela, digitalizações de páginas e diagramas — tipos comuns de imagens que muitas vezes contêm texto incorporado importante e que ficam fora do escopo de modelos de visão computacional treinados apenas com imagens de cenas do mundo real.
Otimizamos esse modelo para diversas tarefas diferentes usando adaptadores compactos de Low-Rank Adaptation (LoRA). Isso nos permite treinar um único modelo para se especializar em múltiplas tarefas, sem comprometer o desempenho em nenhuma delas, com um custo adicional mínimo de memória ou processamento.
Os principais recursos incluem:
- Desempenho de ponta na recuperação de documentos visuais, além de suporte a texto multilíngue e imagens comuns com resultados que superam significativamente modelos muito maiores.
- Suporte a grandes tamanhos de contexto de entrada: 32.768 tokens equivalem aproximadamente a 80 páginas de texto em inglês com espaçamento duplo, e 20 megapixels equivalem a uma imagem de 4.500 × 4.500 pixels.
- Tamanhos de embedding selecionáveis pelo usuário, de um máximo de 2.048 dimensões até 128 dimensões. Constatamos empiricamente que o desempenho se degrada de forma acentuada abaixo desse limite.
- Suporte tanto a embeddings únicos quanto a embeddings multivetoriais. Para textos, a saída multivetorial consiste em um embedding de 128 dimensões para cada token de entrada. Para imagens, é gerado um embedding de 128 dimensões para cada bloco de 28 × 28 pixels necessário para cobrir a imagem.
- Otimização para recuperação assimétrica por meio de um par de adaptadores LoRA treinados especificamente para esse propósito.
- Um adaptador LoRA otimizado para cálculo de similaridade semântica.
- Suporte especial a linguagens de programação e estruturas de TI, também por meio de um adaptador LoRA.
Desenvolvemos jina-embeddings-v4 para atuar como uma ferramenta geral e multifuncional para uma ampla gama de tarefas comuns de busca, compreensão de linguagem natural e análise com IA. Apesar de ser relativamente pequeno considerando suas capacidades, ainda exige recursos significativos para implantação e é mais adequado para uso por meio de uma API em nuvem ou em ambientes de alto volume.
Jina embeddings v3
jina-embeddings-V3 é um modelo de embedding compacto, multilíngue, somente para texto, com alto desempenho e menos de 600 milhões de parâmetros. Ele oferece suporte a até 8.192 tokens de texto de entrada e gera embeddings de vetor único com tamanhos escolhidos pelo usuário, desde o padrão de 1.024 dimensões até 64.
Treinamos jina-embeddings-v3 para uma variedade de tarefas de texto — não apenas recuperação de informações e similaridade semântica, mas também tarefas de classificação, como análise de sentimento e moderação de conteúdo, além de tarefas de clusterização, como agregação de notícias e recomendação. Assim como jina-embeddings-v4, esse modelo oferece adaptadores LoRA especializados para as seguintes categorias de uso:
- Recuperação assimétrica
- Similaridade semântica
- Classificação
- Clustering
jina-embeddings-v3 é um modelo muito menor do que jina-embeddings-v4 com um tamanho de contexto de entrada significativamente reduzido, mas com custo operacional mais baixo. Ainda assim, apresenta desempenho bastante competitivo, embora apenas para textos, e é uma escolha melhor para muitos casos de uso.
Incorporações de código Jina
Os modelos especializados de embedding de código da Jina — jina-code-embeddings (0.5b e 1.5b) — oferecem suporte a 15 esquemas de programação e estruturas, além de textos em inglês relacionados a computação e tecnologia da informação. São modelos compactos, com meio bilhão (0,5 × 10⁹) e um bilhão e meio (1,5 × 10⁹) de parâmetros, respectivamente. Ambos oferecem suporte a tamanhos de contexto de entrada de até 32.768 tokens e permitem que os usuários escolham os tamanhos dos embeddings de saída, de 896 a 64 dimensões no modelo menor e de 1.536 a 128 no modelo maior.
Esses modelos oferecem suporte a recuperação assimétrica para cinco especializações específicas de tarefa, usando ajuste de prefixo em vez de adaptadores LoRA:
- Código para código. Recuperar código semelhante entre diferentes linguagens de programação. Isso é usado para alinhamento de código, deduplicação de código e suporte a portabilidade e refatoração.
- Linguagem natural para código. Recuperar código que corresponda a consultas em linguagem natural, comentários, descrições e documentação.
- Código para linguagem natural. Associar código a documentação ou a outros textos em linguagem natural.
- Conclusão de código para código. Sugerir código relevante para completar ou aprimorar código existente.
- Perguntas e respostas técnicas. Identificar respostas em linguagem natural para perguntas sobre tecnologias da informação, sendo ideal para casos de uso de suporte técnico.
Esses modelos oferecem performance superior em tarefas que envolvem documentação técnica e materiais de programação, com um custo computacional relativamente baixo. Eles são bem adequados para integração em ambientes de desenvolvimento e assistentes de código.
Jina ColBERT v2
jina-colbert-v2 é um modelo de embedding de texto multivetorial com 560 milhões de parâmetros. Ele é multilíngue, treinado com materiais em 89 idiomas, e oferece suporte a tamanhos variáveis de embedding e recuperação assimétrica.
Como observado anteriormente, embeddings multivetoriais não são adequados para indexação, mas são muito úteis para aumentar a precisão dos resultados de outras estratégias de busca. Com jina-colbert-v2, é possível calcular embeddings multivetoriais antecipadamente e usá-los para reclassificar candidatos à recuperação no momento da consulta. Essa abordagem é menos precisa do que usar um dos modelos de reclassificação descritos na próxima seção, mas é muito mais eficiente, pois envolve apenas a comparação de embeddings multivetoriais armazenados, em vez de invocar todo o modelo de IA para cada consulta e cada correspondência candidata. Ela é especialmente adequada para casos de uso em que a latência e a sobrecarga computacional dos modelos de reclassificação são excessivas ou em que o número de candidatos a comparar é grande demais para esse tipo de modelo.
Esse modelo gera uma sequência de embeddings, um por token de entrada, e os usuários podem selecionar embeddings de tokens com 128, 96 ou 64 dimensões. As correspondências de texto candidatas são limitadas a 8.192 tokens. As consultas são codificadas de forma assimétrica, portanto é necessário especificar se um texto é uma consulta ou uma correspondência candidata, além de limitar consultas a 32 tokens.
Jina CLIP v2
jina-clip-v2 é um modelo de embedding multimodal com 900 milhões de parâmetros, treinado para que textos e imagens gerem embeddings próximos entre si quando o texto descreve o conteúdo da imagem. Seu uso principal é a recuperação de imagens com base em consultas textuais, mas ele também é um modelo somente de texto com alto desempenho, reduzindo custos para os usuários, já que não é necessário manter modelos separados para recuperação de texto para texto e de texto para imagem.
Esse modelo oferece suporte a um contexto de entrada de texto de 8.192 tokens, e as imagens são redimensionadas para 512 × 512 pixels antes da geração dos embeddings.
Arquiteturas de pré-treinamento contrastivo de linguagem e imagem (CLIP) são fáceis de treinar e operar e podem gerar modelos muito compactos, mas apresentam algumas limitações fundamentais. Eles não conseguem usar conhecimento de um meio para melhorar seu desempenho em outro. Ou seja, não conseguem aproveitar informações de um meio para aprimorar o desempenho em outro. Assim, embora um modelo possa saber que as palavras “cão” e “gato” são mais próximas em significado entre si do que qualquer uma delas em relação a “carro”, ele não necessariamente saberá que a imagem de um cão e a imagem de um gato são mais relacionadas entre si do que qualquer uma delas em relação à imagem de um carro.
Esses modelos também sofrem do que se chama de lacuna de modalidade: um embedding de um texto sobre cães tende a ficar mais próximo de um embedding de um texto sobre gatos do que de um embedding de uma imagem de cães. Por causa dessa limitação, recomendamos usar CLIP como um modelo de recuperação de texto para imagem ou como um modelo somente de texto, mas não misturar os dois em uma única consulta.
Modelos de reclassificação
Modelos de reclassificação recebem como entrada uma consulta e uma ou mais correspondências candidatas e as comparam diretamente, produzindo correspondências com precisão muito maior.
Em princípio, seria possível usar um reclassificador diretamente para recuperação de informações, comparando cada consulta com cada documento armazenado, mas isso seria computacionalmente muito caro e impraticável para qualquer coleção que não seja muito pequena. Por isso, reclassificadores tendem a ser usados para avaliar listas relativamente curtas de correspondências candidatas encontradas por outros meios, como busca baseada em embeddings ou outros algoritmos de recuperação. Modelos de reclassificação são ideais para esquemas de busca híbrida e federada, nos quais executar uma busca pode significar enviar consultas a sistemas de busca separados, com conjuntos de dados distintos, cada um retornando resultados diferentes. Eles funcionam muito bem para combinar resultados diversos em um único resultado de alta qualidade.
A busca baseada em embeddings pode exigir um grande investimento, envolvendo a reindexação de todos os dados armazenados e a mudança das expectativas dos usuários em relação aos resultados. Adicionar um reclassificador a um esquema de busca existente pode trazer muitos dos benefícios da IA sem a necessidade de reestruturar toda a solução de busca.
Modelos de reclassificação Jina
Jina Reranker m0
jina-reranker-m0 é um reclassificador multimodal com 2,4 bilhões (2,4 × 10⁹) de parâmetros, que oferece suporte a consultas textuais e a correspondências candidatas compostas por textos e/ou imagens. Ele é o principal modelo para recuperação de documentos visuais, o que o torna uma solução ideal para repositórios de PDFs, digitalizações de texto, capturas de tela e outras imagens geradas ou modificadas por computador que contêm texto ou outras informações semiestruturadas, bem como para dados mistos compostos por documentos de texto e imagens.
Esse modelo recebe uma única consulta e uma correspondência candidata e retorna uma pontuação. Quando a mesma consulta é usada com diferentes candidatos, as pontuações são comparáveis e podem ser usadas para ranqueá-los. Ele oferece suporte a um tamanho total de entrada de até 10.240 tokens, incluindo o texto da consulta e o texto ou imagem candidata. Cada bloco de 28 × 28 pixels necessário para cobrir uma imagem conta como um token no cálculo do tamanho de entrada.
Jina Reranker v3
jina-reranker-v3 é um reclassificador de texto com 600 milhões de parâmetros, com desempenho de ponta entre modelos de tamanho comparável. Ao contrário de jina-reranker-m0, ele recebe uma única consulta e uma lista de até 64 correspondências candidatas e retorna a ordem de ranqueamento. Ele tem um contexto de entrada de 131.000 tokens, incluindo a consulta e todos os candidatos de texto.
Jina Reranker v2
jina-reranker-v2-base-multilingual é um reclassificador multifuncional, de uso geral, muito compacto, com recursos adicionais projetados para oferecer suporte a chamadas de função e consultas SQL. Com menos de 300 milhões de parâmetros, ele fornece reclassificação de texto multilíngue rápida, eficiente e precisa, com suporte adicional para selecionar tabelas SQL e funções externas que correspondam a consultas de texto, o que o torna adequado para casos de uso com IA agêntica.
Modelos de linguagem generativos de pequeno porte
Modelos de linguagem generativos são modelos como o ChatGPT da OpenAI, o Google Gemini e o Claude, da Anthropic, que recebem entradas em texto ou multimídia e respondem com saídas em texto. Não existe um limite bem definido que separe modelos de linguagem grandes (LLMs) de modelos de linguagem pequenos (SLMs), mas os desafios práticos de desenvolver, operar e usar LLMs de ponta são bem conhecidos. Os modelos mais conhecidos não são distribuídos publicamente, portanto só é possível estimar seu tamanho, mas espera-se que ChatGPT, Gemini e Claude estejam na faixa de 1 a 3 trilhões (1–3 × 10¹²) de parâmetros.
Executar esses modelos, mesmo quando estão disponíveis publicamente, está muito além do alcance de hardware convencional, exigindo os chips mais avançados organizados em grandes arranjos paralelos. É possível acessar LLMs por meio de APIs pagas, mas isso envolve custos significativos, alta latência e dificuldades para atender a exigências de proteção de dados, soberania digital e repatriação de nuvem. Além disso, os custos relacionados ao treinamento e à personalização de modelos desse porte podem ser consideráveis.
Consequentemente, uma grande quantidade de pesquisa tem se concentrado no desenvolvimento de modelos menores que, embora não tenham todas as capacidades dos maiores LLMs, conseguem executar tipos específicos de tarefas com a mesma qualidade, a um custo reduzido. Empresas normalmente implantam software para resolver problemas específicos, e com software de IA não é diferente; por isso, soluções baseadas em SLMs costumam ser preferíveis às baseadas em LLMs. Elas geralmente podem ser executadas em hardware comum, são mais rápidas, consomem menos energia e são muito mais fáceis de personalizar.
As ofertas de SLM da Jina estão crescendo à medida que nos concentramos em como levar IA da melhor forma possível a soluções práticas de busca.
Jina SLMs
ReaderLM v2
ReaderLM-v2 é um modelo de linguagem generativo que converte HTML em Markdown ou em JSON, de acordo com esquemas JSON fornecidos pelo usuário e instruções em linguagem natural.
O pré-processamento e a normalização de dados são uma parte essencial do desenvolvimento de boas soluções de busca para dados digitais, mas dados do mundo real, especialmente informações derivadas da web, costumam ser caóticos, e estratégias simples de conversão frequentemente se mostram frágeis. Em vez disso, ReaderLM-v2 oferece uma solução inteligente baseada em modelo de IA, capaz de entender o caos de um dump de árvore DOM de uma página da web e identificar, de forma robusta, elementos úteis.
Com 1,5 bilhão (1,5 × 10⁹) de parâmetros, esse modelo é três ordens de magnitude mais compacto do que LLMs de última geração, mas apresenta desempenho equivalente a eles nessa tarefa específica e bastante restrita.
Jina VLM
jina-VLC é um modelo de linguagem generativo com 2,4 bilhões (2,4 × 10⁹) de parâmetros, treinado para responder a perguntas em linguagem natural sobre imagens. Ele oferece suporte muito robusto a análise de documentos visuais, isto é, responder a perguntas sobre digitalizações, capturas de tela, slides, diagramas e dados de imagem semelhantes que não são naturais.
Por exemplo:

Crédito da foto: usuário dave_7 no Wikimedia Commons.
.jpg){kind=link}
Ele também é muito eficiente na leitura de texto em imagens:

Crédito da foto: usuário Vauxford no Wikimedia Commons.
{kind=link}
Mas é na compreensão do conteúdo de imagens informativas e produzidas pelo ser humano que jina-vlm realmente se destaca:

Crédito da imagem: Wikimedia Commons.
{kind=link}
Ou:

Crédito da imagem: Wikimedia Commons.
.png){kind=link}
jina-vlm é especialmente adequado para geração automática de legendas, descrições de produtos, texto alternativo de imagens e aplicações de acessibilidade para pessoas com deficiência visual. Além disso, cria novas possibilidades para sistemas de geração aumentada por recuperação (RAG) utilizarem informações visuais e para agentes de IA processarem imagens sem assistência humana.
Conteúdo relacionado

11 de maio de 2026
Impulsionando o Elasticsearch: adicionando suporte nativo à API do Prometheus
Consulte o Elasticsearch diretamente de clientes compatíveis com Prometheus via endpoints nativos de PromQL, descoberta e metadados. Envie dados para o Elasticsearch com Prometheus Remote Write.

11 de maio de 2026
Um índice, todas as mídias: Apresentando jina-embeddings-v5-omni
O jina-embeddings-v5-omni permite incorporar texto, imagens, vídeos e áudio em um único índice do Elasticsearch e realizar consultas em todos eles simultaneamente.

22 de abril de 2026
Jina embeddings v3 agora disponível no Gemini Enterprise Agent Platform Model Garden
O modelo de busca Jina, jina-embeddings-v3, agora é autoimplantável na plataforma Gemini Enterprise Agent Platform Model Garden, com mais novidades por vir. Execute jina-embeddings-v3 em uma única GPU L4 dentro da sua própria VPC.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.