Jina AIとElasticは、jina-embeddings-v5-textをリリースします。これは、すべての主要なタスクタイプにおいて、同等サイズのモデルの中で最先端のパフォーマンスを備えた、新しい高性能でコンパクトなテキスト埋め込みモデルのファミリーです。
このファミリーには2つのモデルが含まれます。
jina-embeddings-v5-text-smalljina-embeddings-v5-text-nano
これらのモデルは、埋め込みモデルの革新的な新しいトレーニングレシピの成果です。いずれも、同等サイズのモデルよりも何倍も優れたパフォーマンスを発揮し、メモリとコンピューティングリソースを節約し、リクエストへの応答を高速化します。
jina-embeddings-v5-text-smallモデルは6億7700万パラメーターを持ち、32768トークンのインプットコンテキストウィンドウをサポートし、デフォルトで1024次元の埋め込みを生成します。
jina-embeddings-v5-text-nano はその兄弟の約3分の1のサイズで、239Mのパラメーターと8192トークンのインプットコンテキストウィンドウを持ち、スリムな768次元の埋め込みを生成します。
| モデル名 | 合計サイズ | インプットコンテキストウィンドウサイズ | 埋め込みサイズ |
|---|---|---|---|
| jina-v5-text-small | 677M パラメータ | 32768トークン | 1024次元 |
| jina-v5-text-nano | 2億3900万パラメーター | 8192 トークン | 768次元 |
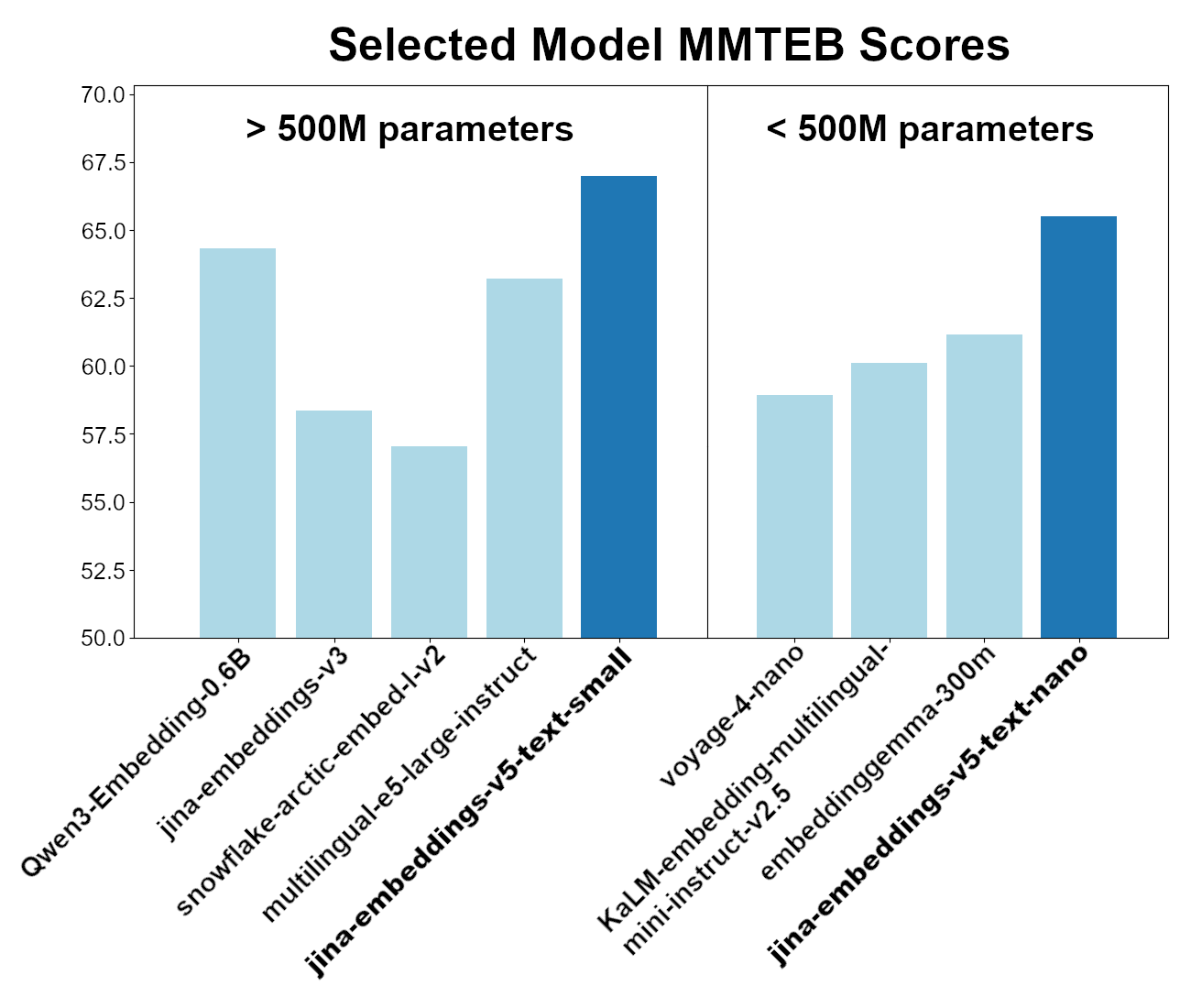
これら2つのモデルは、MMTEB(Multilingual MTEB)ベンチマークの総合的なパフォーマンスにおいてクラス最高です。5億未満のパラメーターを持つモデルの中でjina-embeddings-v5-text-nanoはトップパフォーマーであり、2億5000万未満のパラメータを持ちながらも、7億5000万未満のパラメータを持つ多言語埋め込みモデルの中でjina-embeddings-v5-text-smallモデルがリーダーです。
これらのモデルは、Elastic Inference Service(EIS)やオンラインAPIを介して利用でき、ローカルホスティングでも利用できます。jina-embeddings-v5-textモデルにアクセスする方法については、以下の「はじめに」セクションを参照してください。
埋め込みモデルとセマンティックインデックスにより、検索アルゴリズムの精度が劇的に向上するだけでなく、以下のようなセマンティック類似性や意味抽出を伴うタスクにもさまざまな用途があります。
- 重複したテキストの検索。
- 言い換えや翻訳の認識。
- トピックの発見。
- 推奨エンジン。
- 感情分析と意図分析。
- スパムフィルタリング。
- その他多数。
特徴
この新しいモデルファミリーには、関連性を高め、コストを削減するために設計された多くの特徴があります。
タスクの最適化
私たちは、jina-embeddings-v5-text のモデルを4つの幅広いタスクタイプに最適化しました。
| タスク | ユースケースの例 |
|---|---|
| 検索 | 自然言語クエリを使用して検索し、ドキュメントのコレクション内で最も関連性の高い一致を取得。 |
| テキストマッチング | 意味的類似性、重複除去、言い換えや翻訳の整合性など。 |
| クラスタリング | トピックの検出、ドキュメントコレクションの自動整理。 |
| 分類 | ドキュメントの分類、感情と意図の検出、同様のタスク。 |
あるタスクを最適化するということは、通常、別のタスクを妥協する必要があることを意味します。そのため、ほとんどの埋め込みモデルは、1種類のタスクに対してのみ競争力のあるパフォーマンスを発揮します。しかし、jina-embeddings-v5-textモデルは、タスク固有のLow-Rank Adaptation(LoRA)アダプターをトレーニングすることで、妥協することなく4つのすべての分野に特化できます。
LoRAアダプターはAIモデルのプラグインの一種であり、全体のサイズをわずかに増やすだけでAIモデルの動作を劇的に変化させます。jina-embeddings-v5-text モデルファミリーでは、タスクごとにモデル全体を用意し、それぞれに何億ものパラメーターを持たせる代わりに、各タスクにコンパクトなLoRaアダプターを備えた1つのモデルだけを使用できます。これによりメモリ、ストレージ容量、推論コストを節約できます。
埋め込みの切り捨て
私たちは、 Matryoshka Representation Learningを使用してjina-embeddings-v5-textモデルをトレーニングしました。これにより、品質への影響を最小限に抑えながら、埋め込みを小さなサイズに削減できます。
デフォルトでは、jina-embeddings-v5-text-small は1024次元の埋め込みベクトルを生成し、各ベクトルは16ビットで表されます。大量のドキュメントコレクションの場合、格納するデータ量が多くなり、埋め込みで満たされたベクトルデータベースでの検索は、データベースのサイズと各格納されたベクトルが持つ次元の数に比例します。
しかし、埋め込みのサイズを半分に減らす(1024次元のうち512次元を切り捨てる)だけで、占有スペースを半分にしながら検索速度を2倍にすることができます。これはパフォーマンスに影響を与えます。情報を捨てると精度が低下しますが、下のグラフが示すように、埋め込みの半分を取り除いてもパフォーマンスはわずかしか低下しません。
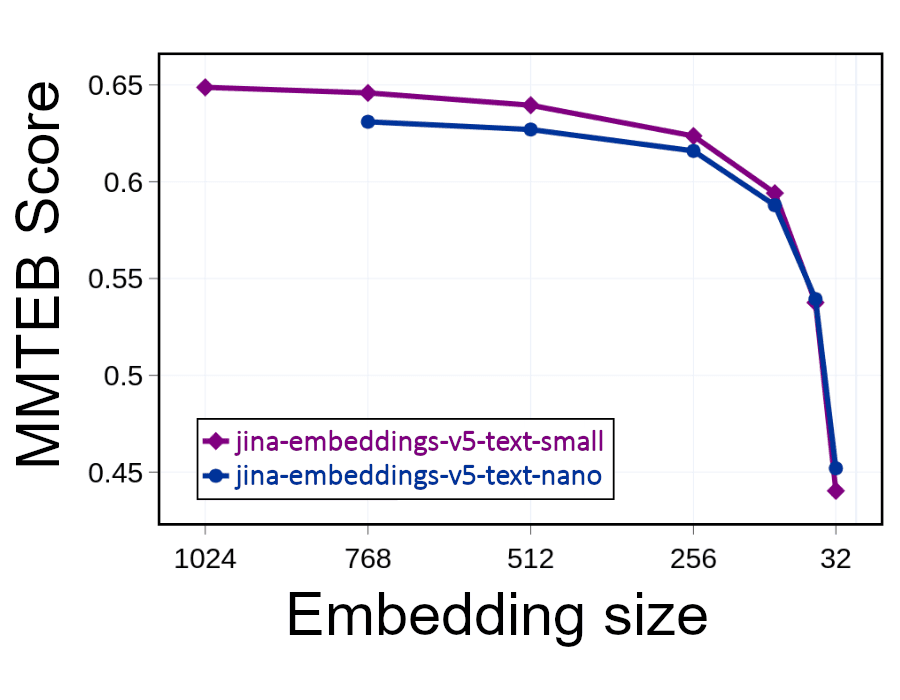
埋め込みが少なくとも256次元であれば、精度の損失は比較的小さいはずです。しかし、そのレベルを下回ると、関連性と正確性はすぐに低下します。
このような埋め込みの切り捨てにより、ユーザーは精度と計算コストのバランスを自分で管理できるようになり、検索AIから大きな効率の向上と大幅なコスト削減を実現するツールを提供します。
堅牢な量子化
量子化は埋め込みのサイズを縮小するもう一つの方法です。量子化では、各埋め込みの一部を破棄するのではなく、埋め込み内の数値の精度を下げます。jina-embeddings-v5-text モデルは16ビット数値で埋め込みを生成しますが、これらの数値を四捨五入して精度と格納に必要なビット数を減らすことができます。最も極端な場合では、各数値を1ビット(0または1)に減らすことで、jina-embeddings-v5-textのデフォルトの1024次元の埋め込みを2キロバイトから128バイトに圧縮できます。これは、バイナリ量子化だけで94%の削減になります。切り捨ての場合と同様に、これによりメモリと計算コストが大幅に節約されますが、切り捨てと同様に、量子化によって埋め込みの精度は低下します。
jina-embeddings-v5-textモデルはElasticsearchのBetter Binary Quantizationに対応し、精度の損失を最小限に抑えるようにトレーニングされており、これらのモデルからの二値化埋め込みのベンチマークテストでは、非二値化モデルとほぼ同等の性能を示しています。二値化性能に関する詳細なアブレーション研究についてはテクニカルレポートをご参照ください。
多言語パフォーマンス
多くの埋め込みモデルは、多数の言語を含む素材でトレーニングされているため、多言語対応です。しかし、サポートされているすべての言語で、すべてが同じように優れたパフォーマンスを発揮するわけではありません。
MMTEBの多言語ベンチマークで211の言語を特定し、それらを分離して、言語ごとにモデルを類似のモデルと比較できるようにしました。下の画像は、私たちの結果をヒートマップとしてまとめたものです。各パッチは言語(ISO-639コードで識別)であり、緑色が濃くなるほど、類似モデルの平均と比較してモデルのパフォーマンスが優れていることを示します。

正確さは言語によって異なりますが、jina-embeddings-v5-text モデルは最先端か、世界のほとんどの言語でほぼ最新です。
詳細な多言語パフォーマンスについては、jina-embeddings-v5-textテクニカルレポートを参照してください。
ElasticにおけるJina:最先端のネイティブAIによる検索
jina-embeddings-v5-textモデルをEISで使用することで、Elasticsearchでネイティブに高パフォーマンスの多言語埋め込みモデルを実行できます。これは、完全に管理されたGPUアクセラレーションによる推論で、インフラを提供したりスケールする必要はありません。jina-embeddings-v5-text モデルは、最新のAI開発によって強化されたコンパクトで多言語対応のモデルで、成長するEISモデルカタログを拡張します。これらのモデルは、情報検索と標準データ分析ベンチマークにおいて最先端のパフォーマンスを発揮し、他に類を見ない世界規模の多言語サポートを提供します。
サイズが大きく異なる2つのモデルが用意されているため、ユーザーは用途や予算に応じてどちらが最適かを判断できます。さらに、より小さなサイズに切り詰められたり、より低い精度に量子化されたりしてもパフォーマンスを維持する堅牢な埋め込みにより、jina-embeddings-v5-text モデルはストレージと計算コストおよび処理遅延においてさらなる具体的な節約の機会を提供します。
jina-embeddings-v5-textファミリー、Jina Reranker、Elasticの高速ベクトルおよびBM25検索により、ユーザーはElasticのエンドツーエンドの最先端のハイブリッド検索にアクセスできるようになりました。最も関連性の高い結果が必要な場合、Retrieval-Augmented Generation(RAG)パイプライン、検索アプリケーション、またはデータ分析において、ElasticとJinaの検索AIモデルは、堅固で費用対効果の高い品質を提供します。
はじめに
jina-embeddings-v5-textモデルはEISに完全に統合されており、インデックス作成時にtype フィールドを semantic_textに設定し、inference_idフィールドでモデル(jina-embeddings-v5-text-smallまたはjina-embeddings-v5-text-nano)を指定することで使用できます(次の例を参照)
Elasticsearchはインデキシングおよび検索時に適切なLoRAアダプターを自動的に選択します。埋め込み次元(上記の「埋め込みの切り捨て」セクション参照)は、カスタム推論エンドポイントを作成する際に設定できます。
jina-embeddings-v5-textモデルの利用については Elasticsearchのドキュメントを参照してください。
詳細情報
jina-embeddings-v5-textモデルについて詳しくは、Jina AIブログのリリースノートとテクニカルレポートをお読みください。パフォーマンスとJina AIの革新的な新しいトレーニング手順に関するより詳細な技術情報が記載されています。これらのモデルのローカルダウンロードや運用については、Hugging Faceのjina-embeddings-v5-textコレクションページをご覧ください。
Jina AIモデルは CC-BY-NC-4.0ライセンスの下で利用可能ですので、自由にダウンロードして試すことができますが、商用利用の場合は Elastic Salesまでお問い合わせください。
関連記事

2026年5月11日
1つのインデックスですべてのメディアに対応:jina-embeddings-v5-omniの紹介
jina-embeddings-v5-omniを使用すると、テキスト、画像、動画、音声を1つのElasticsearchインデックスに埋め込み、それらすべてを一度にクエリできます。

2026年4月22日
Jina embeddings v3がGeminiエンタープライズAgent Platform Model Gardenで利用可能になりました
Jina検索基盤モデルであるjina-embeddings-v3のGemini Enterprise Agent Platform Model Gardenでのセルフデプロイが可能になりました。今後さらに追加される予定です。独自のVPC内の単一のL4 GPU上でjina-embeddings-v3を実行できます。
Jinaモデル、その機能とElasticsearchでの使用方法の紹介
Jinaのマルチモーダル埋め込み、リランカーv3、セマンティック埋め込みモデル、さらにそれらをElasticsearchでネイティブに使用する方法を探ります。

2026年5月22日
Kibanaはダッシュボードの読み込み時間を最大25%短縮 - その背後にあるポーリング戦略を紹介
Kibanaが継続的なポーリングとブラウザ側のHTTP/2検出を使用して、ダッシュボードの読み込み時間を最大25%削減し、HTTP/1に自動的にフォールバックする仕組みをご覧ください。

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。