Jina by Elasticは、アプリケーションとビジネスプロセスの自動化のための検索基盤モデルを提供します。これらのモデルは、Elasticsearchアプリケーションや革新的なAIプロジェクトにAIを導入するためのコア機能を提供します。
Jinaモデルは、情報処理、整理、検索をサポートするように設計された大きく3つのカテゴリーに分類されます。
- セマンティック埋め込みモデル
- リランキングモデル
- 小規模な生成言語モデル
セマンティック埋め込みモデル
セマンティック埋め込みの背後にある考え方は、AIモデルがインプットの意味的側面を高次元空間の幾何学の観点から表現することを学習できるというものです。
セマンティック埋め込みは、高次元空間内の点(技術的にはベクトル)と考えることができます。埋め込みモデルは、ニューラルネットワークの一種で、デジタルデータ(テキストや画像など、あらゆるものが入力となりえますが、最も一般的なのはテキストや画像)を入力として受け取り、対応する高次元点の位置を一連の数値座標として出力します。モデルが適切に機能している場合、2つのセマンティック埋め込み間の距離は、対応するデジタルオブジェクトがどの程度同じ意味を持つかに比例します。
これが検索アプリケーションにとっていかに重要であるかを理解するには、「dog」という単語の埋め込みと「cat」という単語の埋め込みを空間上の点として想像してみましょう。
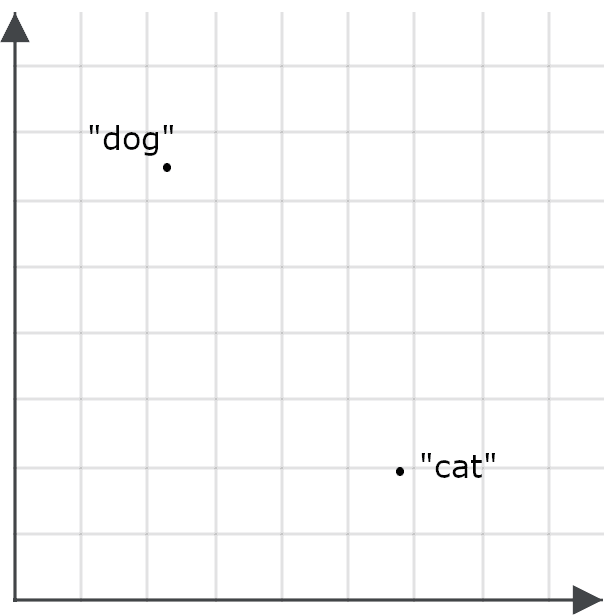
優れた埋め込みモデルは、「feline」という単語に対して「dog」よりも「cat」にずっと近い埋め込みを生成し、「canine」は「cat」よりも「dog」にずっと近い埋め込みを生成するはずです。なぜなら、これらの単語はほぼ同じ意味だからです。

モデルが多言語対応であれば、「cat」と「dog」の翻訳でも同じ結果が期待できます。

埋め込みモデルは、物事間の意味の類似性や不一致を埋め込み間の空間的関係に翻訳します。上の図は2次元のみであるため、画面上で確認できますが、埋め込みモデルでは数十から数千の次元のベクトルが生成されます。これにより、数千語以上を含む文書に対して、何百または何千もの次元を持つ空間上の点を割り当てることで、全体のテキストの意味の微妙なニュアンスをエンコードすることが可能になります。
マルチモーダル埋め込み
マルチモーダルモデルは、セマンティック埋め込みの概念をテキスト以外のもの、特に画像にも拡張します。画像の埋め込みは、その画像の忠実な記述の埋め込みに近いものとなることが期待されます。
セマンティック埋め込みには多くの用途があります。とりわけ、効率的な分類器の構築、データのクラスタリング、データの重複排除やデータの多様性の調査などのさまざまなタスクの実行に使用できます。いずれも、手作業では管理できないほど大量のデータを扱うビッグデータアプリケーションにとって重要です。
埋め込みの最大の直接的な利用は情報検索です。Elasticsearchでは、埋め込みを含む検索オブジェクトをキーとして格納できます。クエリは埋め込みベクトルに変換され、検索によって埋め込みに最も近いキーを持つ格納オブジェクトが返されます。
従来のベクトルベースの検索(低密度ベクトル検索とも呼称)が、ドキュメントやクエリの単語やメタデータに基づくベクトルを使用するのに対し、埋め込みベースの検索(高密度ベクトル検索とも呼称)は、単語ではなくAIによって評価された意味を使用します。これにより、一般に従来の検索方法よりもはるかに柔軟かつ正確になります。
マトリョーシカ表現学習
埋め込みの次元数や数値の精度はパフォーマンスに大きな影響を与えます。空間が非常に高次元で数値が非常に高精度な場合、非常に詳細で複雑な情報を表すことができますが、トレーニングと実行に費用がかかる、より大規模なAIモデルが必要となります。生成されるベクトルはより多くのストレージ容量を必要とし、距離を計算するのにより多くの計算サイクルが必要です。セマンティック埋め込みモデルを使用するには、精度とリソース消費の間で重要なトレードオフを行う必要があります。
ユーザーの柔軟性を最大化するために、Jinaモデルはマトリョーシカ表現学習と呼ばれる技術で訓練されています。これにより、モデルは最も重要な意味的区別を埋め込みベクトルの最初の次元に前もってロードするため、より高い次元を切り捨てても良好なパフォーマンスを得ることができます。
実際には、これはJinaモデルのユーザーが埋め込みの次元数を選択できることを意味します。次元を少なく選択すると精度は低下しますが、パフォーマンスの低下は軽微です。ほとんどのタスクで、Jinaモデルのパフォーマンス指標は、埋め込みサイズを50%縮小するたびに1〜2%低下し、サイズが約95%小さくなります。
非対称検索
意味的類似性は通常、対称的に測定されます。「cat」と「dog」を比較したときに得られる値は、「dog」と「cat」を比較したときに得られる値と同じです。しかし、情報検索に埋め込みを使用する場合、対称性を破り、検索オブジェクトをエンコードする方法とは異なる方法でクエリをエンコードすると、埋め込みがより効果的に機能します。
これは、埋め込みモデルをトレーニングする方法によるものです。トレーニングデータには、単語のような同じ要素が多くの異なるコンテキストでインスタンスとして含まれており、モデルは要素間のコンテキスト上の類似点と相違点を比較することで意味論を学習します。
例えば、「animal」という単語は、「cat」や「dog」と同じ文脈にはあまり出てこないので、「animal」の埋め込みは「cat」や「dog」に特に近いわけではない可能性があります。
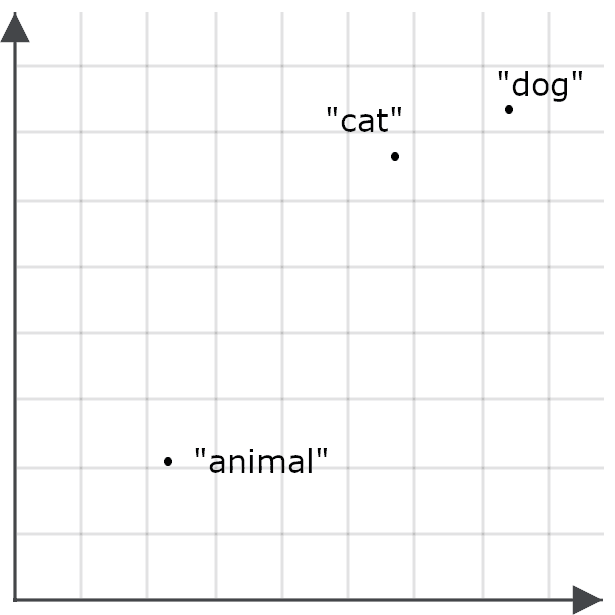
これにより、「animal」のクエリで猫や犬に関するドキュメントが検索される可能性が低くなります。これは目標とは逆の結果となります。そのため、代わりに、クエリの場合と検索のターゲットの場合で「animal」を異なる方法でエンコードします。
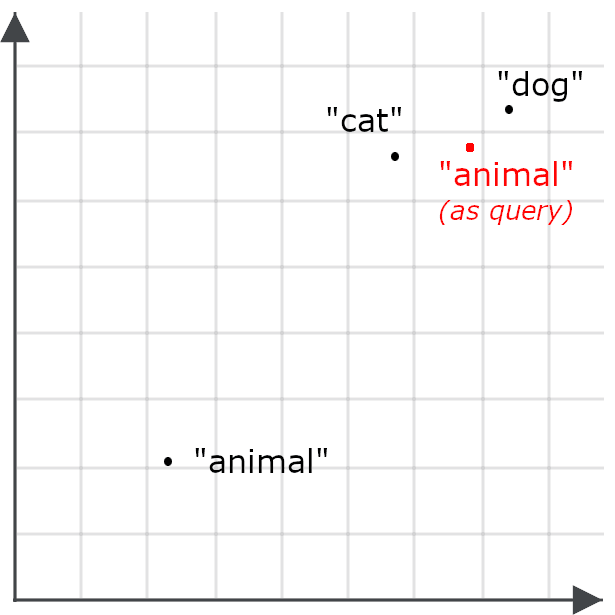
非対称検索とは、クエリに異なるモデルを使用したり、埋め込みモデルを特別に訓練して、検索のために格納する際に一方向にエンコードし、クエリを別の方向にエンコードすることを意味します。
マルチベクトル埋め込み
単一の埋め込みは、インデックス付きデータベースの基本的なフレームワークに適合するため、情報検索に適しています。検索キーとして単一の埋め込みベクトルを使用して、検索用のオブジェクトを格納します。ユーザーがドキュメントストアをクエリする際、そのクエリは埋め込みベクトルに変換され、そのキーが(高次元の埋め込み空間において)クエリ埋め込みに最も近いドキュメントが一致候補として取得されます。
マルチベクトル埋め込みの動作は少し異なります。クエリと格納されたオブジェクト全体を示す固定長のベクトルを生成する代わりに、それらの小さな部分を表す埋め込みのシーケンスを生成します。これらの部分は通常、テキストの場合はトークンまたは単語、視覚データの場合は画像タイルです。これらの埋め込みは、その文脈における部分の意味を反映しています。
例えば、次の文を考えてみましょう。
- She had a heart of gold(彼女は心優しい人でした).
- She had a change of heart(彼女は心変わりしたのです).
- 彼女は心臓発作を起こしました。
表面的には非常によく似ているように見えますが、マルチベクトルモデルでは「heart」の各インスタンスに対して非常に異なる埋め込みが生成され、文全体の文脈の中でそれぞれが別の意味を持つことが示されます。
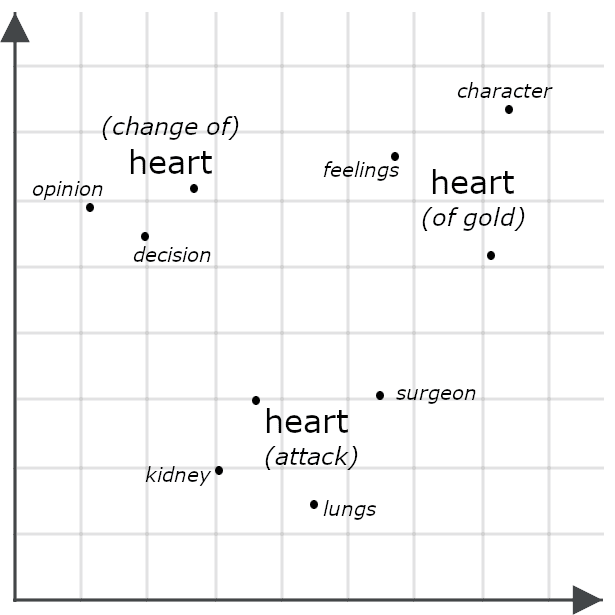
2つのオブジェクトのマルチベクトル埋め込みを比較する場合、多くの場合、面取り距離の測定が必要になります。つまり、1 つのマルチベクトル埋め込みの各部分を別のマルチベクトル埋め込みの各部分と比較し、それらの間の最小距離を合計します。以下に説明するJinaリランカーを含む他のシステムでは、類似性を評価するために特別にトレーニングされたAIモデルにそれらを入力します。マルチベクトル埋め込みには単一ベクトル埋め込みよりもはるかに詳細な情報が含まれているため、通常、両方のアプローチは単一ベクトル埋め込みを単純に比較するよりも精度が高くなります。
しかし、マルチベクトル埋め込みはインデキシングにはあまり適していません。次のセクションのjina-colbert-v2モデルで説明するように、これらはタスクのリランキングによく使用されます。
Jina埋め込みモデル
Jina埋め込みv4
jina-embeddings-v4は、広く使用されているさまざまな言語の画像とテキストをサポートする、38億(3.8x10⁹)パラメーターの多言語およびマルチモーダル埋め込みモデルです。視覚的知識と言語的知識を活用する新しいアーキテクチャを使用して両方のタスクのパフォーマンスを向上させ、画像検索、特に視覚的ドキュメント検索で優れた性能を発揮します。これは、チャート、スライド、マップ、スクリーンショット、ページスキャン、ダイアグラムなどの画像を処理することを意味します。これらは一般的な種類の画像で、しばしば重要な埋め込まれたテキストが含まれており、実世界のシーンの画像で訓練されたコンピュータービジョンモデルの範囲外にあります。
コンパクトなLow-Rank Adaptation(LoRA)アダプターを使って、このモデルを複数の異なるタスクに最適化しました。これにより、メモリや処理の追加コストを最小限に抑えながら、いずれのタスクでもパフォーマンスを犠牲にすることなく、単一のモデルを複数のタスクに特化させることができます。
主な機能には以下のようなものがあります。
- ビジュアルドキュメント検索における最先端のパフォーマンス、および大規模モデルをはるかに凌駕する多言語テキストと通常の画像のパフォーマンス。
- 大きなインプットコンテキストサイズのサポート:32,768トークンは約80ページのダブルスペースの英語テキストに相当し、20メガピクセルは4,500 x 4,500ピクセルの画像に相当します。
- 最大2048次元から128次元まで、ユーザーが選択した埋め込みサイズ。経験的に、そのしきい線を下回るとパフォーマンスが劇的に低下することがわかりました。
- 単一埋め込みとマルチベクトル埋め込みの両方をサポートします。テキストの場合、マルチベクトル出力は、インプットトークンごとに1つの128次元埋め込みで構成されます。画像の場合、28x28ピクセルタイルごとに1つの128次元埋め込みを生成します。
- 目的のために特別に訓練された2つのLoRAアダプターによる非対称検索最適化。
- 意味的類似度計算に最適化されたLoRAアダプター。
- プログラミング言語とITフレームワークへの特別なサポート。LoRAアダプターを介してのサポートも提供します。
私たちは、幅広い一般的な検索、自然言語理解、AI分析タスクのための汎用的な多目的ツールとしてjina-embeddings-v4を開発しました。機能を考えると比較的小規模なモデルですが、導入には依然としてかなりのリソースが必要であり、クラウドAPI経由または高ボリューム環境での使用に最適です。
Jina embeddings v3
jina-embeddings-v3は、6億未満のパラメーターを持つ、コンパクトで高性能な多言語のテキストのみの埋め込みモデルです。最大8192トークンのテキストインプットをサポートし、デフォルトの1024次元から64次元まで、ユーザーが選択したサイズの単一ベクトル埋め込みを出力します。
私たちは、情報検索や意味的類似性だけでなく、感情分析やコンテンツモデレーションなどの分類タスク、ニュースの集約や推奨などのクラスタリングタスクなど、さまざまなテキストタスク向けにjina-embeddings-v3をトレーニングしてきました。jina-embeddings-v4と同様に、このモデルは次の使用カテゴリーに特化したLoRAアダプターを提供します。
- 非対称検索
- 意味的類似性
- 分類
- クラスタリング
jina-embeddings-v3 は jina-embeddings-v4よりもはるかに小さいモデルであり、インプットコンテキストのサイズが大幅に削減されていますが、操作にかかるコストは少なくなります。それにもかかわらず、テキストに関しては非常に競争力のあるパフォーマンスを有し、多くのユースケースにとってより良い選択肢です。
Jinaコード埋め込み
Jinaの専門的なコード埋め込みモデルであるjina-code-embeddings(0.5bおよび1.5b)は、15プログラミング方式とフレームワーク、さらにコンピューティングや情報技術に関連する英語のテキストをサポートしています。これらは、それぞれ5億 (0.5x10⁹)と15億(1.5x10⁹)のパラメーターを持つコンパクトなモデルです。どちらのモデルも、最大32,768トークンのインプットコンテキストサイズをサポートしており、ユーザーは出力の埋め込みサイズを選択(小さいモデルでは896から64次元、大きいモデルでは1536から128次元)できます。
これらのモデルは、LoRAアダプターではなくプレフィックスチューニングを使用して、5つのタスク固有の特殊化のための非対称検索をサポートしています。
- コードからコードへ。さまざまなプログラミング言語で同様のコードを取得できます。コードの調整、コードの重複排除、移植とリファクタリングのサポートに使用されます。
- 自然言語からコードへ。自然言語クエリ、コメント、説明、ドキュメントに合わせたコードを取得します。
- コードから自然言語へ。コードをドキュメントまたはその他の自然言語テキストと一致させます。
- コード間の補完。既存のコードを完成させたり強化したりするために、関連するコードを提案します。
- 技術的な内容のQ&A。情報技術に関する質問に対する自然言語による回答を特定します。テクニカルサポートのユースケースに最適です。
これらのモデルは、比較的小さい計算コストで、コンピューターのドキュメント作成やプログラミング資料に関連するタスクに優れたパフォーマンスを提供します。開発環境やコードアシスタントに統合するのに適しています。
Jina ColBERT v2
jina-colbert-v2は、5億6000万のパラメーターを持つマルチベクトルテキスト埋め込みモデルです。多言語対応で、89言語の素材を使用してトレーニングされており、可変の埋め込みサイズと非対称検索をサポートしています。
前述のように、マルチベクトル埋め込みはインデックス作成にはあまり適していませんが、他の検索戦略の結果の精度を高めるのに非常に役立ちます。jina-colbert-v2を使用すると、マルチベクトル埋め込みを事前に計算し、それを使用してクエリ時に検索候補をリランキングすることができます。このアプローチは、次のセクションのリランキングモデルの1つを使用するほど正確ではありませんが、クエリや候補の一致ごとにAIモデル全体を呼び出すのではなく、格納されているマルチベクター埋め込みを比較するだけなので、はるかに効率的です。これは、リランキングモデルを使用する際の遅延や計算オーバーヘッドが大きすぎる、または比較する候補の数が多すぎるユースケースに最適です。
このモデルは、インプットトークンごとに埋め込みのシーケンスを出力し、ユーザーは128次元、96次元、または64次元の埋め込みのトークンを選択できます。候補テキストの一致は8,192トークンに制限されます。クエリは非対称にエンコードされるため、ユーザーはテキストがクエリか候補一致かを指定する必要があり、クエリは32トークンに制限する必要があります。
Jina CLIP v2
jina-clip-v2は、9億パラメーターのマルチモーダル埋め込みモデルであり、テキストが画像のコンテンツを説明する場合に、テキストと画像が近い埋め込みを生成するようにトレーニングされています。その主な用途は、テクスチャクエリに基づいて画像を取得することですが、テキストからテキストへの検索とテキストから画像への検索に別々のモデルを必要としないため、高性能のテキストのみのモデルでもあり、ユーザーのコスト削減に役立ちます。
このモデルは8,192トークンのテキストインプットコンテキストをサポートし、画像は埋め込みを生成する前に512x512ピクセルに拡大されます。
対照言語画像事前トレーニング(CLIP)アーキテクチャは、トレーニングと操作が簡単で、非常にコンパクトなモデルを作成できますが、基本的な制限がいくつかあります。あるメディアの知識を別のメディアでのパフォーマンスの向上に活用することはできません。あるメディアを利用して別のメディアのパフォーマンスを向上させることはできません。そのため、「dog」と「cat」という単語の意味はどちらも「car」よりも近いことはわかっていても、犬の写真と猫の写真はどちらも車の写真よりも関連性が高いことは必ずしもわかっていません。
また、これらはモダリティギャップと呼ばれる問題も抱えています。これはつまり、犬に関するテキストの埋め込みは、犬の画像の埋め込みよりも、猫に関するテキストの埋め込みに近い可能性が高いということです。この制限のため、CLIPはテキストから画像への検索モデルとして、またはテキストのみのモデルとして使用し、1つのクエリ内でこれら2つを混在させないことをお勧めします。
リランキングモデル
リランキングモデルは、1つまたは複数の候補一致と、クエリをモデルへのインプットとして取り、それらを直接比較して、はるかに高い精度の一致を生成します。
原理的には、各クエリを保存されている各ドキュメントと比較することで、情報検索にリランキングを直接使用できますが、これは計算コストが非常に高く、最小のコレクション以外では実用的ではありません。そのため、リランカーは、埋め込みベースの検索やその他の検索アルゴリズムなど、他の手段によって見つかった候補一致の比較的短いリストを評価するために使用される傾向があります。リランキングモデルは、検索を実行するとクエリが異なるデータセットを持つ個別の検索システムに送信され、それぞれが異なる結果を返す可能性があるハイブリッド検索スキームやフェデレーション検索スキームに最適です。多様な結果を1つの高品質な結果に統合する場合に非常に効果的です。
埋め込みベースの検索は、保存されているすべてのデータの再インデックスや、結果に対するユーザーの期待の変更など、大きな負担を伴う可能性があります。既存の検索スキームにリランカーを追加することで、検索ソリューション全体を再構築することなく、AIの利点の多くを追加することができます。
Jinaリランカーモデル
Jinaリランカーm0
jina-reranker-m0は、24億(2.4x10⁹)パラメーターのマルチモーダルリランカーで、テキストクエリとテキストや画像からなる候補一致をサポートします。これはビジュアルドキュメント検索の主要モデルであり、PDF、テキストのスキャン、スクリーンショット、テキストなど半構造化情報を含むコンピュータ生成または修正された画像、加えてテキストドキュメントと画像からなる混合データの格納に理想的なソリューションです。
このモデルは、単一のクエリと候補一致を受け取り、スコアを返します。同じクエリを異なる候補で使用すると、スコアは比較可能となり、それらのランク付けに使用できます。クエリテキストや候補テキストや画像を含む最大10,240トークンのインプットサイズをサポートします。画像をカバーするために必要な28x28ピクセルのタイルはすべて、入力サイズを計算するためのトークンとしてカウントされます。
Jinaリランカーv3
jina-reranker-v3は、同等のサイズのモデルに対して最先端のパフォーマンスを備えた6億パラメーターのテキストリランカーです。jina-reranker-m0とは異なり、1つのクエリと最大64件の一致候補のリストを受け取り、ランキング順を返します。クエリとすべてのテキスト候補を含む131,000トークンの入力コンテキストがあります。
Jinaリランカーv2
jina-reranker-v2-base-multilingualは非常にコンパクトで汎用的なリランカーで、関数呼び出しやSQLクエリをサポートする追加の機能を備えています。3億弱のパラメーターで、高速、効率的、正確な多言語テキストリランキングを提供し、テキストクエリにマッチするSQLテーブルと外部関数を選択するための追加サポートもあり、エージェント的なユースケースに適しています。
小規模な生成言語モデル
生成言語モデルは、OpenAIのChatGPT、Google Gemini、AnthropicのClaudeのように、テキストまたはマルチメディアのインプットを受け取り、テキスト出力で応答するモデルです。大規模言語モデル(LLM)と小規模言語モデル(SLM)を明確に区別する境界はありませんが、最先端のLLMを開発、運用、使用する際の実用的な問題はよく知られています。最もよく知られているものは一般公開されていないため、そのサイズを推定することしかできませんが、ChatGPT、Gemini、Claudeは1~3兆(1~3x10¹²)のパラメーター範囲にあると予想されます。
これらのモデルを実行することは、たとえ公開されたものであっても、従来のハードウェアの範囲をはるかに超えており、広大な並列アレイに配置された最先端のチップを必要とします。有料のAPIを使ってLLMにアクセスすることもできますが、これには大きなコストがかかり、レイテンシーも大きく、データ保護、デジタル主権、クラウドの本国送還などの要求と整合させるのは困難です。さらに、その規模のモデルのトレーニングとカスタマイズに関連するコストはかなりの額になる可能性があります。
その結果、最大規模のLLMのすべての機能は備えていないものの、特定の種類のタスクを低コストで同様に実行できる小規模モデルの開発に多大な研究が行われてきました。一般的に、企業は特定の問題に対処するためにソフトウェアをデプロイしますが、AIソフトウェアも同様で、LLMよりもSLMベースのソリューションの方が望ましい場合が多いのです。これらは通常、一般的なハードウェア上で実行でき、実行速度が速く、消費電力が少なく、カスタマイズがはるかに簡単です。
JinaのSLMサービスは、AIを実用的な検索ソリューションに最も効果的に組み込む方法に重点を置いて拡大しています。
Jina SLM
ReaderLM v2
ReaderLM-v2は、ユーザーが提供したJSONスキーマや自然言語命令に基づいて、HTMLをMarkdownまたはJSONに変換する生成言語モデルです。
データの前処理と正規化はデジタルデータの優れた検索ソリューションを開発する上で不可欠な部分ですが、現実世界のデータ、特にウェブから得られる情報は混沌としていることが多く、単純な変換戦略では非常に脆弱になることがよくあります。代わりに、ReaderLM-v2 はウェブページのDOMツリーダンプの混沌を理解し、有用な要素を堅牢に識別できるインテリジェントなAIモデルソリューションを提供します。
15億(1.5x10⁹)パラメーターを持つこのシステムは最先端のLLMよりも3桁コンパクトですが、この1つの狭義のタスクにおいては最先端のLLMと同等のパフォーマンスを発揮します。
Jina VLM
JINA-VLMは、画像に関する自然言語の質問に答えるために訓練された24億(2.4×10⁹)パラメーターの生成言語モデルです。視覚的ドキュメント分析、つまりスキャン、スクリーンショット、スライド、図表、類似の非自然画像データに関する質問に回答する機能を非常に強力にサポートしています。
例:

写真提供 : Wikimedia Commonsユーザー dave_7
画像内のテキストの読み取りにも非常に優れています。

.jpg){kind=link}
{kind=link}
しかし、jina-vlmの真に優れた点は、情報収集や人工画像の内容を理解することです。

画像提供 : Wikimedia Commons
{kind=link}
または:

画像提供 : Wikimedia Commons
.png){kind=link}
jina-vlm 自動キャプション生成、製品の説明、画像の代替テキスト、視覚障害者向けのアクセシビリティ用途に最適です。また、検索拡張生成(RAG)システムが視覚情報を使用したり、AIエージェントが人間の助けを借りずに画像を処理したりする可能性も生まれます。
関連記事

2026年5月11日
Elasticsearchに火を灯す:Prometheus APIのネイティブサポートを追加
Prometheus互換のクライアントから、ネイティブのPromQL、ディスカバリー、メタデータエンドポイント経由でElasticsearchに直接クエリを実行できます。Prometheus Remote WriteでElasticsearchにデータを送信します。

2026年5月11日
1つのインデックスですべてのメディアに対応:jina-embeddings-v5-omniの紹介
jina-embeddings-v5-omniを使用すると、テキスト、画像、動画、音声を1つのElasticsearchインデックスに埋め込み、それらすべてを一度にクエリできます。

2026年4月22日
Jina embeddings v3がGeminiエンタープライズAgent Platform Model Gardenで利用可能になりました
Jina検索基盤モデルであるjina-embeddings-v3のGemini Enterprise Agent Platform Model Gardenでのセルフデプロイが可能になりました。今後さらに追加される予定です。独自のVPC内の単一のL4 GPU上でjina-embeddings-v3を実行できます。

Elasticsearch Inference APIとHugging Faceモデルを組み合わせて使用
推論エンドポイントを使用してElasticsearchをHugging Faceモデルに接続する方法と、セマンティック検索とチャット補完機能を備えた多言語ブログ推奨システムを構築する方法を学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。