Elastic의 Jina는 애플리케이션과 비즈니스 프로세스 자동화를 위한 검색 기반 모델을 제공합니다. 이러한 모델은 Elasticsearch 애플리케이션과 혁신적인 AI 프로젝트에 AI를 도입하기 위한 핵심 기능을 제공합니다.
Jina 모델은 정보 처리, 정리, 검색을 지원하도록 설계된 세 가지 큰 카테고리로 나뉩니다.
- 시맨틱 임베딩 모델
- 모델 순위 재지정
- 소규모 생성형 언어 모델
시맨틱 임베딩 모델
시맨틱 임베딩의 핵심 아이디어는 AI 모델이 입력의 의미적 측면을 고차원 공간의 기하학적 형태로 표현하는 방법을 학습할 수 있다는 것입니다.
시맨틱 임베딩은 고차원 공간에 있는 점(엄밀히 말하면 벡터)으로 생각할 수 있습니다. 임베딩 모델은 일부 디지털 데이터(어떤 것이든 가능하지만 대부분 텍스트나 이미지)를 입력으로 받아 해당 고차원 점의 위치를 일련의 숫자 좌표로 출력하는 신경망입니다. 모델이 제대로 작동한다면 두 시맨틱 임베딩 사이의 거리는 해당 디지털 객체가 동일한 의미를 갖는 정도에 비례합니다.
검색 애플리케이션에서 이것이 얼마나 중요한지 이해하려면 '개'라는 단어와 '고양이'라는 단어에 대한 임베딩을 공간의 점으로 상상해 보세요.
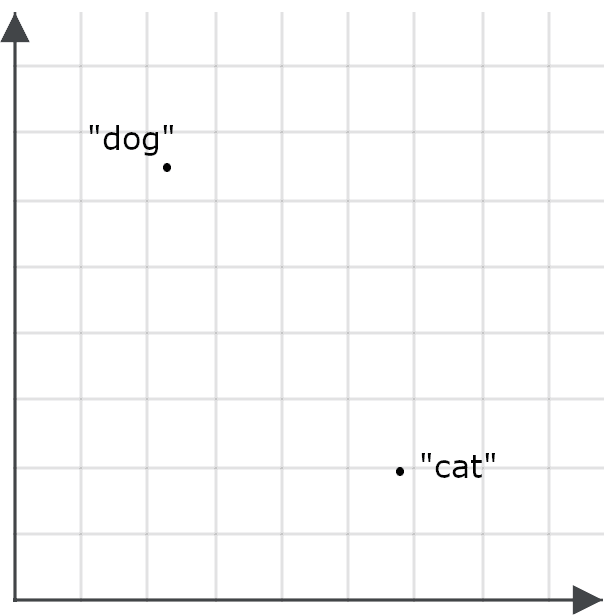
좋은 임베딩 모델은 '고양이'라는 단어에 대해 '개'보다 '고양이'에 훨씬 가까운 임베딩을 생성해야 하며, '개'는 거의 같은 의미이므로 '고양이'보다 '개'에 훨씬 가까운 임베딩을 가져야 합니다.

모델이 다국어인 경우 '고양이'와 '개'의 번역에 대해 동일한 결과를 기대할 수 있습니다.

임베딩 모델은 사물 간 의미의 유사성 또는 유사성을 임베딩 간의 공간적 관계로 변환합니다. 위의 그림은 화면에서 볼 수 있도록 2차원으로만 표현했지만, 모델을 임베드하면 수십에서 수천 개의 차원을 가진 벡터가 만들어집니다. 이를 통해 전체 텍스트의 미묘한 의미를 인코딩할 수 있으며, 수천 단어 이상의 문서에 대해 수백 또는 수천 개의 차원을 가진 공간에 지점을 할당할 수 있습니다.
멀티모달 임베딩
멀티모달 모델은 시맨틱 임베딩의 개념을 텍스트 이외의 것, 특히 이미지로 확장합니다. 사진에 대한 임베딩은 사진에 대한 충실한 설명을 임베딩하는 것과 비슷할 것으로 예상합니다.
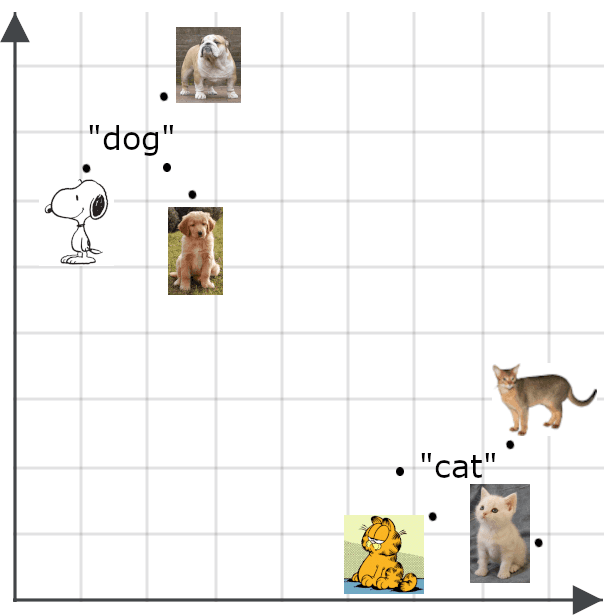
시맨틱 임베딩은 다양한 용도를 가지고 있습니다. 무엇보다도 효율적인 분류기를 구축하고, 데이터 클러스터링을 수행하고, 데이터 중복 제거 및 데이터 다양성 조사와 같은 다양한 작업을 수행하는 데 사용할 수 있으며, 이는 모두 수작업으로 관리하기에는 너무 많은 데이터를 다루는 빅데이터 애플리케이션에 중요한 작업입니다.
임베딩의 가장 큰 직접적인 용도는 정보 검색입니다. Elasticsearch는 임베딩을 키로 사용하여 검색 객체를 저장할 수 있습니다. 쿼리는 임베딩 벡터로 변환되고 검색은 쿼리 임베딩에 가장 가까운 키가 있는 저장된 객체를 반환합니다.
전통적인 벡터 기반 검색(때때로 희소 벡터 검색이라고 함)이 문서와 쿼리에서 단어나 메타데이터를 기반으로 한 벡터를 사용하는 반면, 임베딩 기반 검색(또한 밀집 벡터 검색이라고 함)은 단어가 아닌 AI가 평가한 의미를 사용합니다. 따라서 일반적으로 기존 검색 방법보다 훨씬 더 유연하고 정확합니다.
Matryoshka 표현 학습
임베딩의 차원 수와 임베딩에 포함된 숫자의 정밀도는 성능에 상당한 영향을 미칩니다. 매우 높은 차원의 공간과 매우 정밀한 숫자는 매우 상세하고 복잡한 정보를 표현할 수 있지만, 학습과 실행에 더 많은 비용이 드는 더 큰 AI 모델을 필요로 합니다. 벡터를 생성하려면 더 많은 저장 공간이 필요하고 벡터 사이의 거리를 계산하는 데 더 많은 컴퓨팅 사이클이 필요합니다. 시맨틱 임베딩 모델을 사용하는 것은 정밀도와 자원 소비 간의 중요한 절충을 포함합니다.
사용자의 유연성을 극대화하기 위해 Jina 모델은 마트료시카 표현 학습이라는 기법으로 훈련됩니다. 이렇게 하면 모델이 가장 중요한 의미적 구분을 임베딩 벡터의 첫 번째 차원에 미리 로드하므로 상위 차원을 잘라내도 여전히 좋은 성능을 얻을 수 있습니다.
실제로 이는 Jina 모델 사용자가 임베딩에 원하는 차원 수를 선택할 수 있음을 의미합니다. 차원을 적게 선택하면 정밀도가 감소하지만, 성능 저하는 미미합니다. 대부분의 작업에서 Jina 모델의 성능 지표는 임베딩 크기를 50% 줄일 때마다 1~2% 감소하며, 크기가 약 95% 감소할 때까지 이러한 경향이 지속됩니다.
비대칭 검색
시맨틱 유사성은 일반적으로 대칭적으로 측정됩니다. '고양이'와 '개'를 비교할 때 얻는 값은 '개'와 '고양이'를 비교할 때 얻는 값과 동일합니다. 그러나 정보 검색에 임베딩을 사용할 때는 대칭을 깨고 검색 객체를 인코딩하는 방식과 다르게 쿼리를 인코딩하면 더 잘 작동합니다.
이는 임베딩 모델을 훈련하는 방식 때문입니다. 훈련 데이터에는 단어와 같은 동일한 요소가 다양한 맥락에서 나타나는 사례들이 포함되어 있으며, 모델은 요소 간의 맥락적 유사점과 차이점을 비교하여 의미를 학습합니다.
예를 들어 '동물'이라는 단어가 '고양이' 또는 '개'와 같은 문맥에서 많이 나타나지 않으므로 '동물'에 대한 임베딩이 '고양이' 또는 '개'와 특별히 가깝지 않을 수 있습니다.
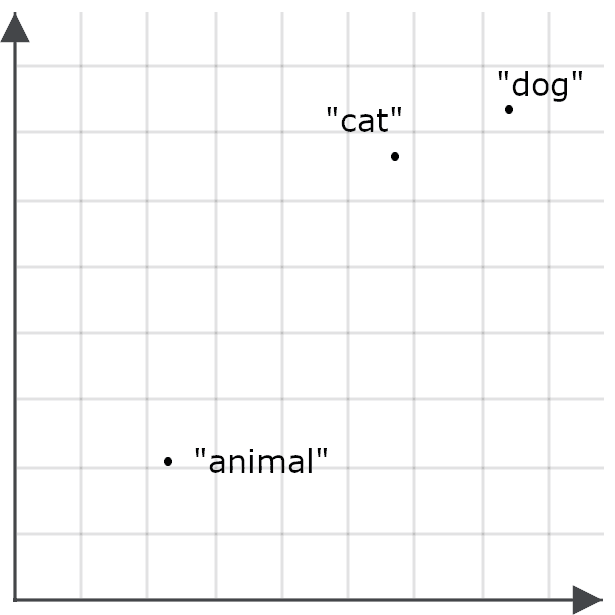
따라서 '동물'을 검색하면 목표와는 정반대로 고양이와 개에 관한 문서가 검색될 가능성이 줄어듭니다. 따라서 '동물'이 검색 대상일 때와 쿼리일 때를 다르게 인코딩합니다.
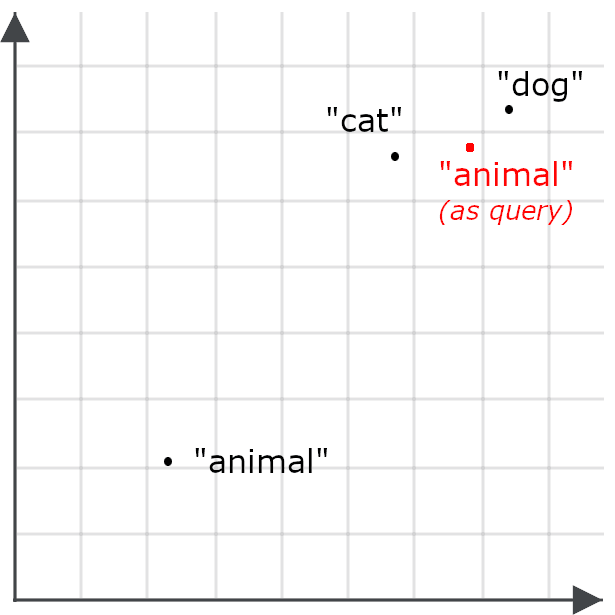
비대칭 검색이란 쿼리에 다른 모델을 사용하거나, 저장된 데이터를 한 가지 방식으로 인코딩하고 쿼리를 다른 방식으로 인코딩하도록 임베딩 모델을 특별히 학습시키는 것을 의미합니다.
멀티벡터 임베딩
단일 임베딩은 인덱스 데이터베이스의 기본 프레임워크에 적합하기 때문에 정보 검색에 유용합니다. 즉, 검색 키로 단일 임베딩 벡터를 사용하여 검색 대상 객체를 저장합니다. 사용자가 문서 저장소를 쿼리하면 쿼리가 임베딩 벡터로 변환되고 쿼리 임베딩에 가장 가까운 키(고차원 임베딩 공간에서)를 가진 문서가 후보 일치 항목으로 검색됩니다.
멀티벡터 임베딩은 약간 다르게 작동합니다. 쿼리와 전체 저장된 객체를 나타내는 고정 길이 벡터를 생성하는 대신, 쿼리의 작은 부분을 나타내는 임베딩 시퀀스를 생성합니다. 구성 요소는 일반적으로 텍스트의 경우 토큰 또는 단어이며, 시각적 데이터의 경우 이미지 타일입니다. 이러한 임베딩은 해당 부분의 의미를 그 컨텍스트 내에서 반영합니다.
예를 들어 다음 문장을 생각해 보세요.
- 그녀는 상냥한 마음씨를 가졌습니다.
- 그녀는 마음이 바뀌었습니다.
- 그녀는 심장 마비를 일으켰습니다.
표면적으로는 매우 비슷해 보이지만 멀티벡터 모델은 'heart'의 각 인스턴스에 대해 매우 다른 임베딩을 생성하여 전체 문장의 맥락에서 각각이 어떻게 다른 의미를 갖는지를 표현합니다.
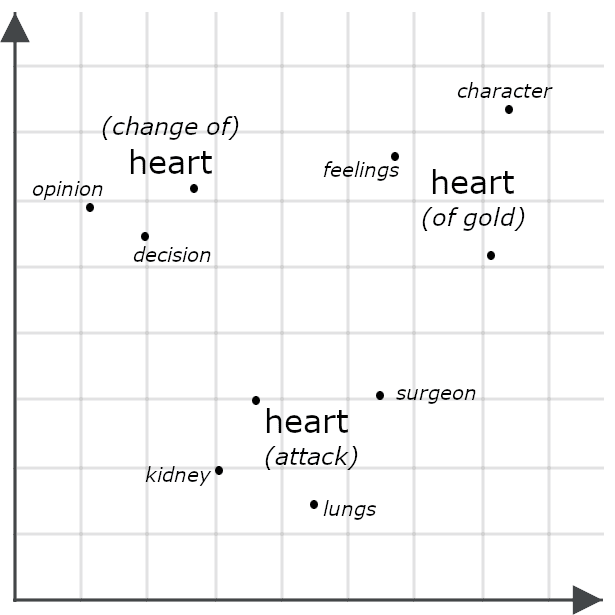
멀티벡터 임베딩을 통해 두 개체를 비교하려면 한 멀티벡터 임베딩의 각 부분을 다른 멀티벡터 임베딩의 각 부분과 비교하고 그 사이의 최소 거리를 합산하는 모따기 거리를 측정하는 경우가 많습니다. 아래에서 설명하는 Jina Rerankers를 포함한 다른 시스템들은 이들을 이들의 유사성을 평가하도록 특별히 훈련된 AI 모델에 입력합니다. 멀티벡터 임베딩은 단일 벡터 임베딩보다 훨씬 더 자세한 정보를 포함하기 때문에 일반적으로 두 접근 방식 모두 단일 벡터 임베딩을 비교하는 것보다 정밀도가 높습니다.
그러나 멀티벡터 임베딩은 색인에 적합하지 않습니다. 다음 섹션에서 설명된 jina-colbert-v2 모델과 같이 순위 재지정 작업에서 자주 사용됩니다.
Jina 임베딩 모델
Jina 임베딩 v4
jina-embeddings-v4는 38억(3.8x10⁹) 매개변수의 다국어 및 멀티모달 임베딩 모델로, 다양한 널리 사용되는 언어의 이미지와 텍스트를 지원합니다. 시각적 지식과 언어 지식을 활용하여 두 작업의 성능을 향상시키는 새로운 아키텍처를 사용하여 이미지 검색, 특히 시각적 문서 검색에서 탁월한 성능을 발휘합니다. 이는 차트, 슬라이드, 맵, 스크린샷, 페이지 스캔 및 다이어그램과 같은 이미지를 처리한다는 것을 의미합니다. 이러한 이미지는 일반적인 종류의 이미지로, 종종 중요한 내장 텍스트가 포함되어 있으며, 실제 장면의 사진으로 훈련된 컴퓨터 비전 모델의 범위를 벗어납니다.
컴팩트한 로우랭크 적응(LoRA) 어댑터를 사용하여 여러 가지 작업에 맞게 이 모델을 최적화했습니다. 이를 통해 메모리나 프로세싱의 추가 비용을 최소화하면서 여러 작업의 성능 저하 없이 단일 모델을 여러 작업에 특화하도록 훈련할 수 있습니다.
주요 기능은 다음과 같습니다:
- 시각적 문서 검색의 최첨단 성능과 함께 다국어 텍스트 및 일반 이미지 성능은 훨씬 더 큰 모델을 능가합니다.
- 큰 입력 컨텍스트 크기 지원: 32,768토큰은 대략 두 줄짜리 영어 텍스트 80페이지에 해당하며, 20메가픽셀은 4,500 x 4,500픽셀 이미지에 해당합니다.
- 임베딩 크기는 최대 2048개에서 최소 128개까지 사용자가 선택할 수 있습니다. 경험적으로 이 임계값 이하에서는 성능이 급격히 저하되는 것으로 나타났습니다.
- 단일 임베딩과 멀티벡터 임베딩을 모두 지원합니다. 텍스트의 경우, 멀티벡터 출력은 각 입력 토큰에 대해 128차원 임베딩 하나로 구성됩니다. 이미지의 경우, 이미지를 커버하는 데 필요한 각 28x28 픽셀 타일에 대해 하나의 128차원 임베딩을 생성합니다.
- 비대칭 검색을 위한 최적화는 특별히 이를 위해 훈련된 LoRA 어댑터 한 쌍을 통해 이루어집니다.
- 시맨틱 유사도 계산에 최적화된 LoRA 어댑터입니다.
- LoRA 어댑터를 통해서도 컴퓨터 프로그래밍 언어 및 IT 프레임워크를 특별히 지원합니다.
광범위한 일반 검색, 자연어 이해 및 AI 분석 작업을 위한 범용 다목적 도구로 사용할 수 있도록 jina-embeddings-v4를 개발했습니다. 기능에 비해 비교적 작은 모델이지만 배포하는 데 상당한 리소스가 필요하며 클라우드 API를 통해 사용하거나 대용량 환경에서 사용하기에 가장 적합합니다.
Jina 임베딩 v3
jina-embeddings-v3는 6억 개 미만의 매개변수를 가진 소규모 고성능 다국어 텍스트 전용 임베딩 모델입니다. 최대 8192개의 텍스트 입력 토큰을 지원하며, 기본 1024개부터 최대 64개까지 사용자가 선택한 크기의 단일 벡터 임베딩을 출력합니다.
정보 검색 및 의미적 유사성뿐만 아니라 감정 분석 및 콘텐츠 조정과 같은 분류 작업, 뉴스 집계 및 추천과 같은 클러스터링 작업 등 다양한 텍스트 작업에 대해 jina-embeddings-v3를 학습시켰습니다. jina-embeddings-v4와 마찬가지로 이 모델은 다음 사용 범주에 특화된 LoRA 어댑터를 제공합니다.
- 비대칭 검색
- 의미적 유사성
- 분류
- 클러스터링
jina-embeddings-v3 입력 컨텍스트 크기가 크게 줄어든 jina-embeddings-v4 모델보다 훨씬 작지만 운영 비용은 더 적게 듭니다. 그럼에도 불구하고 텍스트에만 해당되긴 하지만 성능 경쟁력이 매우 뛰어나고 많은 사용 사례에서 더 나은 선택입니다.
Jina 코드 임베딩
Jina의 특수 코드 임베딩 모델인 jina-code-embeddings(0.5b 및 1.5b)는 15가지 프로그래밍 체계와 프레임워크, 그리고 컴퓨팅 및 정보기술 관련 영어 텍스트를 지원합니다. 각각 5억(0.5x10⁹) 및 15억(1.5x10⁹) 크기의 소규모 모델입니다. 두 모델 모두 최대 32,768개의 토큰 입력 컨텍스트 크기를 지원하며, 작은 모델의 경우 896개에서 64개까지, 큰 모델의 경우 1536개에서 128개까지 사용자가 출력 임베딩 크기를 선택할 수 있습니다.
이러한 모델은 접두사 튜닝을 사용하여 LoRA 어댑터 대신 5가지 작업별 특화를 위한 비대칭 검색을 지원합니다.
- 코드-코드. 프로그래밍 언어 전반에서 유사한 코드를 검색합니다. 이는 코드 정렬, 코드 중복 제거, 이식 및 리팩토링 지원에 사용됩니다.
- 자연어-코드. 코드를 검색하여 자연어 쿼리, 댓글, 설명 및 문서와 일치시킵니다.
- 코드-자연어.코드를 문서 또는 기타 자연어 텍스트와 일치시킵니다.
- 코드-코드 완성. 관련 코드를 제안하여 기존 코드를 완료하거나 향상시킵니다.
- 기술 관련 Q&A. 정보 기술에 관한 질문에 대한 자연어 답변을 식별합니다. 이는 기술 지원 사용 사례에 이상적입니다.
이러한 모델은 컴퓨터 문서화 및 프로그래밍 자료와 관련된 작업에서 상대적으로 적은 컴퓨팅 비용으로 우수한 성능을 제공합니다. 개발 환경 및 코드 어시스턴트에 통합하는 데 적합합니다.
Jina ColBERT v2
jina-colbert-v2는 5억 6천만 개의 매개변수를 가진 멀티벡터 텍스트 임베딩 모델입니다. 다국어 지원, 89개 언어의 자료를 사용하여 학습되었으며 다양한 임베딩 크기와 비대칭 검색을 지원합니다.
앞서 언급했듯이, 멀티벡터 임베딩은 색인하는 데에는 적합하지 않지만 다른 검색 전략의 결과 정확도를 높이는 데 매우 유용합니다. jina-colbert-v2를 사용하여 멀티벡터 임베딩을 미리 계산한 다음 쿼리 시 검색 후보의 순위를 재조정하는 데 사용할 수 있습니다. 이 접근 방식은 다음 섹션의 재순위 모델 중 하나를 사용하는 것보다 정확도는 떨어지지만 모든 쿼리와 후보 일치에 대해 전체 AI 모델을 호출하는 대신 저장된 멀티벡터 임베딩을 비교하기 때문에 훨씬 더 효율적입니다. 이는 순위 재지정 모델을 사용할 때의 지연 시간과 계산 부하가 너무 큰 사용 사례나 비교할 후보의 수가 순위 재지정 모델에 너무 많은 경우에 이상적으로 적합합니다.
이 모델은 입력 토큰당 하나씩 일련의 임베딩을 출력하며, 사용자는 128차원, 96차원 또는 64차원 임베딩의 토큰 임베딩을 선택할 수 있습니다. 후보 텍스트 매칭은 8,192개 토큰으로 제한됩니다. 쿼리는 비대칭적으로 인코딩되므로, 사용자는 텍스트가 쿼리인지 후보 일치인지 지정해야 하며, 쿼리 수를 32개의 토큰으로 제한해야 합니다.
Jina CLIP v2
jina-clip-v2는 9억 개의 매개변수를 가진 멀티모달 임베딩 모델로, 텍스트가 이미지의 내용을 설명할 경우 텍스트와 이미지가 서로 가까운 임베딩을 생성하도록 학습되었습니다. 주요 용도는 텍스처 쿼리를 기반으로 이미지를 검색하는 것이지만, 텍스트 전용 모델로도 고성능을 발휘하여 사용자 비용을 절감할 수 있습니다. 텍스트-텍스트 및 텍스트-이미지 검색을 위해 별도의 모델이 필요하지 않기 때문입니다.
이 모델은 8,192개의 토큰으로 구성된 텍스트 입력 컨텍스트를 지원하며, 이미지는 임베딩을 생성하기 전에 512x512 픽셀로 크기가 조정됩니다.
대조적 언어-이미지 사전 훈련(CLIP) 아키텍처는 훈련 및 운영이 쉽고 매우 컴팩트한 모델을 생성할 수 있지만, 몇 가지 근본적인 한계가 있습니다. 그들은 한 매체에서 얻은 지식을 다른 매체에서의 성능 향상에 사용할 수 없습니다. 한 매체에서 다른 매체로 사용하여 성능을 향상시킬 수 없습니다. 따라서 '개'와 '고양이'라는 단어가 '자동차'보다 의미상 서로 가깝다는 것은 알 수 있지만, 개 그림과 고양이 그림이 자동차 그림보다 더 관련이 있다는 것을 반드시 알지는 못합니다.
또한 양식 격차라는 문제도 있습니다. 개에 대한 텍스트 임베딩은 개 사진 임베딩보다 고양이에 대한 텍스트 임베딩에 더 가깝게 느껴질 가능성이 높습니다. 이러한 제한 때문에 CLIP을 텍스트-이미지 검색 모델 또는 텍스트 전용 모델로 사용하는 것이 좋지만, 단일 쿼리에서 둘을 혼합하지 않는 것이 좋습니다.
모델 순위 재지정
순위 재지정 모델은 하나 이상의 후보 일치 항목과 쿼리를 모델에 입력으로 받아 이를 직접 비교하여 훨씬 더 높은 정밀도의 일치 항목을 생성합니다.
원칙적으로, 각 쿼리를 저장된 각 문서와 비교하여 정보 검색을 위해 직접 순위 재지정 도구를 사용할 수 있지만, 이는 매우 계산 비용이 많이 들고 가장 작은 컬렉션을 제외하고는 비실용적입니다. 결과적으로, 순위 재지정 도구는 임베딩 기반 검색이나 다른 검색 알고리즘과 같은 다른 방법을 통해 찾은 비교적 짧은 후보 목록을 평가하는 데 사용되는 경향이 있습니다. 순위 재지정 모델은 하이브리드 및 연합 검색 체계에 이상적으로 적합합니다. 여기서 검색을 수행한다는 것은 쿼리가 별도의 검색 시스템으로 전송되어 각각 고유한 데이터 세트를 가지고 각기 다른 결과를 반환할 수 있음을 의미합니다. 다양한 결과를 하나의 고품질 결과로 병합하는 데 매우 효과적입니다.
임베딩 기반 검색은 저장된 모든 데이터를 재색인하고 검색 결과에 대한 사용자 기대치를 변경해야 하므로 상당한 노력이 필요합니다. 기존 검색 체계에 리랭커를 추가하면 AI의 많은 이점을 추가할 수 있으며, 전체 검색 솔루션을 다시 설계할 필요 없이 이를 달성할 수 있습니다.
Jina 순위 재지정 모델
Jina 순위 재지정 m0
jina-reranker-m0는 24억(2.4x10⁹)개의 매개변수를 가진 다중 모드 순위 재지정 도구로, 텍스트 쿼리와 텍스트 및/또는 이미지로 구성된 후보 매치를 지원합니다. 이 모델은 시각적 문서 검색의 선도적 모델로, PDF 저장소, 텍스트 스캔, 스크린샷 및 텍스트 또는 반구조화된 정보를 포함한 기타 컴퓨터 생성 또는 수정 이미지뿐만 아니라 텍스트 문서와 이미지로 구성된 혼합 데이터에도 이상적인 솔루션입니다.
이 모델은 단일 쿼리와 일치하는 후보를 입력받아 점수를 반환합니다. 동일한 쿼리를 다른 후보와 함께 사용하면 점수를 비교하여 순위를 매기는 데 사용할 수 있습니다. 쿼리 텍스트와 후보 텍스트 또는 이미지를 포함하여 최대 10,240개 토큰의 총 입력 크기를 지원합니다. 이미지를 덮는 데 필요한 28x28 픽셀 타일 하나하나가 입력 크기 계산을 위한 토큰으로 간주됩니다.
Jina 순위 재지정 v3
jina-reranker-v3는 비슷한 크기의 모델을 위한 최첨단 성능을 갖춘 6억 개의 매개변수 텍스트 순위 재지정 도구입니다. jina-reranker-m0와 달리, 단일 쿼리와 최대 64개의 후보 매칭 목록을 받아 순위 순서를 반환합니다. 쿼리와 모든 텍스트 후보를 포함하여 131,000개의 토큰으로 구성된 입력 컨텍스트가 있습니다.
Jina 순위 재지정 v2
jina-reranker-v2-base-multilingual은 함수 호출 및 SQL 쿼리를 지원하도록 설계된 추가 기능을 갖춘 매우 컴팩트한 범용 순위 재지정 도구입니다. 3억 개 미만의 매개변수를 포함하며, 빠르고 효율적이며 정확한 다국어 텍스트 순위 재지정을 제공하며, 텍스트 쿼리에 맞는 SQL 테이블과 외부 함수 선택 지원도 추가하여 에이전트 사용 사례에 적합합니다.
소규모 생성형 언어 모델
생성형 언어 모델은 텍스트 또는 멀티미디어 입력을 받아 텍스트 출력으로 응답하는 OpenAI의 ChatGPT, Google Gemini, Anthropic의 Claude와 같은 모델입니다. 대규모 언어 모델(LLM)과 소규모 언어 모델(SLM)을 구분하는 명확한 경계는 없지만, 최고급 LLM을 개발, 운영 및 사용하는 데 따르는 실질적인 문제는 잘 알려져 있습니다. 가장 잘 알려진 것들은 공개적으로 배포되지 않았기 때문에 우리는 그 크기를 추정할 수만 있지만, ChatGPT, Gemini 및 Claude는 1~3조(1~3x10¹²) 매개변수 범위 내에 있을 것으로 예상됩니다.
이러한 모델을 실행하는 것은, 심지어 공개적으로 이용 가능하더라도, 기존 하드웨어의 범위를 훨씬 넘어서며, 방대한 병렬 어레이로 구성된 최첨단 칩을 필요로 합니다. LLM에는 유료 API를 통해 액세스할 수 있지만, 이는 상당한 비용이 발생하고 높은 대기 시간을 가지며 데이터 보호, 디지털 주권 및 클라우드 재환원에 대한 요구 사항과 일치하기 어렵습니다. 또한 이 정도 규모의 모델을 교육하고 사용자 지정하는 데 드는 비용도 상당할 수 있습니다.
그 결과, 대형 LLM의 모든 기능은 부족할 수 있지만 저렴한 비용으로 특정 종류의 작업을 잘 수행할 수 있는 소규모 모델을 개발하기 위해 많은 연구가 진행되었습니다. 기업은 보통 특정 문제를 해결하기 위해 소프트웨어를 배포하며, AI 소프트웨어도 다르지 않습니다. 따라서 SLM 기반 솔루션이 LLM 기반 솔루션보다 나은 경우가 많습니다. 일반적으로 상용 하드웨어에서 실행할 수 있고, 더 빠르며 실행에 필요한 에너지를 덜 소비하고, 훨씬 더 쉽게 사용자 정의할 수 있습니다.
AI를 실용적인 검색 솔루션에 가장 효과적으로 도입할 수 있는 방법에 집중하면서 Jina의 SLM 제품군은 성장하고 있습니다.
Jina SLMs
ReaderLM v2
ReaderLM-v2는 사용자가 제공한 JSON 스키마와 자연어 명령어에 따라 HTML을 Markdown 또는 JSON으로 변환하는 생성형 언어 모델입니다.
데이터 전처리 및 정규화는 디지털 데이터에 대한 효과적인 검색 솔루션을 개발하는 데 필수적인 부분이지만, 실제 세계의 데이터, 특히 웹에서 파생된 정보는 종종 혼란스럽고, 단순한 변환 전략은 매우 취약한 것으로 드러나는 경우가 많습니다. 대신, ReaderLM-v2 웹페이지의 DOM 트리 덤프의 혼란을 이해하고 유용한 요소를 강력하게 식별할 수 있는 지능형 AI 모델 솔루션을 제공합니다.
15억(1.5x10⁹)개의 매개변수로, 최첨단 LLM보다 세 자릿수 차이로 작지만 이 특정 작업에서는 동등한 수준의 성능을 발휘합니다.
Jina VLM
jina-vlm은 이미지에 대한 자연어 질문에 답하도록 훈련된 24억 (2.4x10⁹)개의 매개변수 생성형 언어 모델입니다. 그것은 스캔, 스크린샷, 슬라이드, 다이어그램 및 유사한 비자연적 이미지 데이터에 대한 질문에 답변하는 시각적 문서 분석을 매우 강력하게 지원합니다.
그 예는 다음과 같습니다.

사진 출처: Wikimedia Commons의 사용자 dave_7.
.jpg){kind=link}
이미지 속 텍스트를 읽는 데도 매우 능숙합니다.

사진 출처: Wikimedia Commons의 사용자 Vauxford.
{kind=link}
하지만 jina-vlm의 진정한 강점은 정보성 이미지와 인공 이미지의 콘텐츠를 이해하는 것입니다.

이미지 출처: Wikimedia Commons.
{kind=link}
또는:

이미지 출처: Wikimedia Commons.
.png){kind=link}
jina-vlm 자동 캡션 생성, 제품 설명, 이미지 대체 텍스트, 시각 장애인을 위한 접근성 애플리케이션에 적합합니다. 또한 검색 증강 생성(RAG) 시스템이 시각 정보를 사용하고 AI 에이전트가 사람의 도움 없이 이미지를 처리할 수 있는 가능성을 열어줍니다.
관련 콘텐츠

2026년 5월 11일
강력한 기능을 더한 Elasticsearch: 네이티브 Prometheus API 지원 추가
기본 ProMQL, 탐색 및 메타데이터 엔드포인트를 통해 Prometheus 호환 클라이언트에서 직접 Elasticsearch를 쿼리하세요. Prometheus Remote Write로 Elasticsearch에 데이터를 보낼 수 있습니다.

2026년 5월 11일
모든 미디어, 단 하나의 인덱스: jina-embeddings-v5-omni
jina-embeddings-v5-omni를 사용하면 텍스트, 이미지, 동영상 및 오디오를 단일 Elasticsearch 인덱스에 임베드하고 모든 항목을 한 번에 쿼리할 수 있습니다.

2026년 4월 22일
Gemini Enterprise Agent Platform Model Garden에서 Jina Embeddings v3를 사용할 수 있습니다
Jina 검색 기반 모델인 jina-embeddings-v3는 이제 Gemini Enterprise Agent Platform Model Garden에서 자체 배포할 수 있으며, 더 많은 기능이 추가될 예정입니다. 자체 VPC 내부의 단일 L4 GPU에서 jina-embeddings-v3를 실행하세요.

Elasticsearch 추론 API와 Hugging Face 모델 함께 사용하기
추론 엔드포인트를 사용하여 Elasticsearch를 Hugging Face 모델에 연결하고, 시맨틱 검색 및 채팅 완성을 갖춘 다국어 블로그 추천 시스템을 구축하는 방법을 알아보세요.

TypeScript로 Elasticsearch MCP 서버 생성
TypeScript와 Claude Desktop을 사용하여 Elasticsearch MCP 서버를 생성하는 방법을 알아보세요.