Agent Builder는 이제 이제 정식 버전으로 이용 가능합니다. Elastic Cloud 체험판으로 시작하고, 여기에서 Agent Builder 문서를 확인 해 보세요.
컨텍스트 엔지니어링은 안정적인 AI 에이전트 및 아키텍처를 구축하는 데 있어 점점 더 중요해지고 있습니다. 모델이 점점 더 개선됨에 따라 그 효과와 신뢰성은 학습된 데이터보다는 올바른 맥락에 얼마나 잘 근거를 두고 있는지에 따라 달라집니다. 가장 관련성 높은 정보를 적시에 검색하고 적용할 수 있는 에이전트가 정확하고 신뢰할 수 있는 결과물을 만들어낼 가능성이 훨씬 높습니다.
이 블로그에서는 Mastra를 사용해 사용자가 말한 내용을 기억하고 나중에 관련 정보를 불러올 수 있는 지식 에이전트를 구축하는 데 Elasticsearch를 메모리 및 검색 백엔드로 사용하겠습니다. 동일한 개념을 실제 사용 사례로 쉽게 확장하여 지원 상담원이 과거의 대화와 해결 방법을 기억할 수 있어 특정 사용자에게 맞춤형 응답을 제공하거나 이전 컨텍스트를 기반으로 더 빠르게 해결책을 제시할 수 있다고 생각하면 됩니다.
여기를 따라 단계별로 구축하는 방법을 알아보세요. 길을 잃었거나 완성된 예제를 실행하고 싶다면 여기에서 리포지토리를 확인하세요.
마스트라란 무엇인가요?
Mastra는 추론, 메모리 및 도구에 대한 교체 가능한 부품으로 AI 에이전트를 구축하기 위한 오픈 소스 TypeScript 프레임워크입니다. 시맨틱 리콜 기능을 통해 상담원은 메시지를 벡터 데이터베이스에 임베딩으로 저장하여 과거 상호작용을 기억하고 검색할 수 있습니다. 이를 통해 상담원은 장기적인 대화 맥락과 연속성을 유지할 수 있습니다. Elasticsearch는 효율적인 고밀도 벡터 검색을 지원하기 때문에 이 기능을 활성화하는 데 탁월한 벡터 저장소입니다. 시맨틱 리콜이 트리거되면 에이전트는 관련 과거 메시지를 모델의 컨텍스트 창으로 가져와서 모델이 검색된 컨텍스트를 추론 및 응답의 기초로 사용할 수 있도록 합니다.
시작하기 위해 필요한 사항
- 노드 v18+
- Elasticsearch(버전 8.15 이상)
- Elasticsearch API 키
- OpenAI API 키
참고: 데모에서는 OpenAI 공급자를 사용하므로 이 공급자가 필요하지만, Mastra는 다른 AI SDK 및 커뮤니티 모델 공급자를 지원하므로 설정에 따라 쉽게 교체할 수 있습니다.
Mastra 프로젝트 구축
Mastra에 내장된 CLI를 사용하여 프로젝트의 스캐폴딩을 제공하겠습니다. 명령을 실행합니다:
다음과 같은 일련의 프롬프트가 표시됩니다:
1. 프로젝트 이름을 지정합니다.

2. 이 기본값을 그대로 사용해도 되므로 비워두셔도 됩니다.

3. 이 프로젝트에서는 OpenAI에서 제공하는 모델을 사용합니다.

4. 모든 환경 변수를 이후 단계에서 구성할 '.env' 파일에 저장하므로 '지금은 건너뛰기' 옵션을 선택합니다.

5. 이 옵션을 건너뛸 수도 있습니다.

Mastra의 MCP 서버 설치 건너뛰기
초기화가 완료되면 다음 단계로 넘어갈 수 있습니다.
종속성 설치
다음으로 몇 가지 종속성을 설치해야 합니다:
ai- 자바스크립트/타입스크립트에서 AI 모델, 프롬프트 및 워크플로를 관리할 수 있는 도구를 제공하는 핵심 AI SDK 패키지입니다. Mastra는 Vercel의 AI SDK를 기반으로 구축되었으므로 에이전트와의 모델 상호 작용을 활성화하려면 이 종속성이 필요합니다.@ai-sdk/openai- AI SDK를 OpenAI 모델(예: GPT-4, GPT-4o 등)에 연결하여 OpenAI API 키를 사용하여 API 호출을 가능하게 하는 플러그인입니다.@elastic/elasticsearch- Node.js용 공식 Elasticsearch 클라이언트, 인덱싱, 검색, 벡터 작업을 위해 Elastic Cloud 또는 로컬 클러스터에 연결하는 데 사용됩니다.dotenv- .env에서 환경 변수를 로드합니다. 파일을 process.env에 추가합니다, API 키와 Elasticsearch 엔드포인트와 같은 자격 증명을 안전하게 삽입할 수 있습니다.
환경 변수 구성
프로젝트 루트 디렉터리에 .env 파일이 없는 경우 이 파일을 만듭니다. 또는 리포지토리에 제공한 예제 .env 를 복사하여 이름을 바꿀 수 있습니다. 이 파일에서 다음 변수를 추가할 수 있습니다:
이것으로 기본 설정이 끝났습니다. 여기에서 이미 상담원 구축 및 오케스트레이션을 시작할 수 있습니다. 여기서 한 걸음 더 나아가 저장 및 벡터 검색 레이어로 Elasticsearch를 추가하겠습니다.
벡터 저장소로 Elasticsearch 추가하기
stores 이라는 새 폴더를 만들고 그 안에 이 파일을 추가합니다. Mastra와 Elastic이 공식 Elasticsearch 벡터 저장소 통합을 출시하기 전에 Abhi Aiyer(Mastra CTO)가 초기 프로토타입 클래스( ElasticVector)를 공유했습니다. 간단히 말해, Mastra의 메모리 추상화와 Elasticsearch의 고밀도 벡터 기능을 연결하여 개발자가 에이전트를 위한 벡터 데이터베이스로 Elasticsearch를 도입할 수 있습니다.
통합의 중요한 부분을 자세히 살펴보겠습니다:
Elasticsearch 클라이언트 수집
이 섹션에서는 ElasticVector 클래스를 정의하고 표준 배포와 서버리스 배포를 모두 지원하는 Elasticsearch 클라이언트 연결을 설정합니다.
ElasticVectorConfig extends ClientOptions: 이렇게 하면 모든 Elasticsearch 클라이언트 옵션(예:node,auth,requestTimeout)을 상속하고 사용자 정의 속성을 추가하는 새로운 구성 인터페이스가 생성됩니다. 즉, 사용자는 서버리스 전용 옵션과 함께 유효한 모든 Elasticsearch 구성을 전달할 수 있습니다.extends MastraVector: 이를 통해ElasticVector은 모든 벡터 스토어 통합이 준수하는 공통 인터페이스인 Mastra의 기본MastraVector클래스에서 상속할 수 있습니다. 이렇게 하면 Elasticsearch가 에이전트의 관점에서 다른 모든 Mastra 벡터 백엔드처럼 작동합니다.private client: Client: Elasticsearch JavaScript 클라이언트의 인스턴스를 보관하는 개인 속성입니다. 이렇게 하면 클래스가 클러스터와 직접 대화할 수 있습니다.isServerless및deploymentChecked: 이러한 속성은 함께 작동하여 서버리스 또는 표준 Elasticsearch 배포에 연결되어 있는지 여부를 감지하고 캐시합니다. 이 감지는 처음 사용할 때 자동으로 수행되거나 명시적으로 구성할 수 있습니다.constructor(config: ClientOptions): 이 생성자는 구성 객체(Elasticsearch 자격 증명 및 선택적 서버리스 설정이 포함된)를 가져와서this.client = new Client(config)줄에서 클라이언트를 초기화하는 데 사용합니다.super(): 이것은 Mastra의 기본 생성자를 호출하므로 로깅, 유효성 검사 헬퍼 및 기타 내부 훅을 상속합니다.
이 시점에서 Mastra는 다음과 같은 새로운 벡터 스토어가 있다는 것을 알고 있습니다. ElasticVector
배포 유형 감지
인덱스를 생성하기 전에 어댑터는 표준 Elasticsearch를 사용 중인지 아니면 Elasticsearch 서버리스를 사용 중인지 자동으로 감지합니다. 서버리스 배포에서는 수동 샤드 구성을 허용하지 않기 때문에 이 점이 중요합니다.
무슨 일이 일어나고 있나요?
- 먼저 구성에서
isServerless을 명시적으로 설정했는지 확인합니다(자동 감지 건너뛰기). - Elasticsearch의
info()API를 호출하여 클러스터 정보를 가져옵니다. build_flavor field(서버리스 배포는serverless)를 확인합니다.- 빌드 플레이버를 사용할 수 없는 경우 태그 라인 확인으로 돌아가기
- 반복되는 API 호출을 방지하기 위해 결과 캐시
- 탐지에 실패하면 표준 배포로 기본 설정됩니다.
사용 예시:
Elasticsearch에서 "메모리" 저장소 만들기
아래 함수는 임베딩을 저장하기 위한 Elasticsearch 인덱스를 설정합니다. 인덱스가 이미 존재하는지 확인합니다. 그렇지 않은 경우 임베딩 및 사용자 정의 유사성 메트릭을 저장할 dense_vector 필드가 포함된 아래 매핑을 사용하여 매핑을 생성합니다.
몇 가지 주의해야 할 사항:
dimension매개변수는 각 임베딩 벡터의 길이로, 사용 중인 임베딩 모델에 따라 달라집니다. 이 경우,1536크기의 벡터를 출력하는 OpenAI의text-embedding-3-small모델을 사용하여 임베딩을 생성하겠습니다. 이 값을 기본값으로 사용하겠습니다.- 아래 매핑에 사용된
similarity변수는metric매개변수의 값을 받아 선택한 거리 메트릭에 대해 Elasticsearch 호환 키워드로 변환하는 도우미 함수 const similarity = this.mapMetricToSimilarity(metric)에서 정의됩니다.- 예를 들어: 예를 들어, Mastra는
cosine,euclidean,dotproduct와 같은 벡터 유사성에 대한 일반적인 용어를 사용합니다.euclidean메트릭을 Elasticsearch 매핑에 직접 전달하면, Elasticsearch는l2_norm키워드가 유클리드 거리를 나타낼 것으로 예상하기 때문에 오류가 발생합니다.
- 예를 들어: 예를 들어, Mastra는
- 서버리스 호환성: 서버리스 배포를 위한 샤드 및 복제본 설정은 Elasticsearch 서버리스에서 자동으로 관리되므로 코드에서 자동으로 생략됩니다.
상호 작용 후 새 메모리 또는 노트 저장하기
이 함수는 각 상호 작용 후에 생성된 새 임베딩을 메타데이터와 함께 가져온 다음 Elastic의 bulk API를 사용하여 인덱스에 삽입하거나 업데이트합니다. bulk API는 여러 개의 쓰기 작업을 단일 요청으로 그룹화하여 인덱싱 성능을 개선함으로써 에이전트의 메모리가 계속 증가함에 따라 업데이트가 효율적으로 유지되도록 합니다.
시맨틱 리콜을 위해 유사한 벡터 쿼리하기
이 기능은 시맨틱 리콜 기능의 핵심입니다. 에이전트는 벡터 검색을 사용하여 인덱스 내에서 유사한 저장된 임베딩을 찾습니다.
내부를 들여다보세요:
- Elasticsearch에서
knnAPI를 사용하여 kNN (k-nearest neighbors) 쿼리를 실행합니다. - 입력 쿼리 벡터와 유사한 상위 K개의 벡터를 검색합니다.
- 선택적으로 메타데이터 필터를 적용하여 결과 범위를 좁힐 수 있습니다(예: 특정 카테고리 또는 시간 범위 내에서만 검색).
- 문서 ID, 유사도 점수, 저장된 메타데이터를 포함한 구조화된 결과를 반환합니다.
지식창고 만들기
이제 ElasticVector 통합을 통해 Mastra와 Elasticsearch 간의 연결을 확인했으니, 지식 에이전트 자체를 생성해 보겠습니다.
agents 폴더 안에 knowledge-agent.ts 이라는 파일을 만듭니다. 환경 변수를 연결하고 Elasticsearch 클라이언트를 초기화하는 것으로 시작할 수 있습니다.
여기, 우리:
dotenv을 사용하여.env파일에서 변수를 로드합니다.- Elasticsearch 자격 증명이 올바르게 주입되고 있는지 확인하면 클라이언트에 성공적으로 연결할 수 있습니다.
ElasticVector생성자에 Elasticsearch 엔드포인트와 API 키를 전달하여 앞서 정의한 벡터 저장소의 인스턴스를 생성합니다.- 선택적으로 Elasticsearch 서버리스를 사용하는 경우
isServerless: true을 지정합니다. 이렇게 하면 자동 감지 단계를 건너뛰고 시작 시간이 단축됩니다. 이 옵션을 생략하면 처음 사용할 때 어댑터가 자동으로 배포 유형을 감지합니다.
다음으로 Mastra의 Agent 클래스를 사용하여 에이전트를 정의할 수 있습니다.
정의할 수 있는 필드는 다음과 같습니다:
name및instructions: 아이덴티티와 기본 기능을 부여합니다.model:@ai-sdk/openai패키지를 통해 OpenAI의gpt-4o를 사용하고 있습니다.memory:vector: Elasticsearch 저장소를 가리키므로 임베딩이 저장되고 거기에서 검색됩니다.embedder: 임베딩 생성에 사용할 모델semanticRecall옵션은 리콜 작동 방식을 결정합니다:topK: 검색할 의미적으로 유사한 메시지 수입니다.messageRange: 각 경기에 포함할 대화 분량입니다.scope: 메모리 경계를 정의합니다.
거의 다 끝났습니다. 새로 생성된 에이전트를 Mastra 구성에 추가하기만 하면 됩니다. index.ts 라는 파일에서 지식 에이전트를 가져와서 agents 필드에 삽입합니다.
다른 필드에는 다음이 포함됩니다:
storage: 실행 기록, 통합 가시성 메트릭, 점수 및 캐시를 위한 Mastra의 내부 데이터 저장소입니다. Mastra 스토리지에 대한 자세한 내용은 여기를 참조하세요.logger: Mastra는 경량 구조화된 JSON 로거인 Pino를 사용합니다. 상담원 시작 및 중지, 도구 호출 및 결과, 오류, LLM 응답 시간 등의 이벤트를 캡처합니다.observability: 상담원의 AI 추적 및 실행 가시성을 제어합니다. 추적합니다:- 각 추론 단계의 시작/종료
- 어떤 모델 또는 도구를 사용했는지.
- 입력 및 출력.
- 점수 및 평가
Mastra Studio로 에이전트 테스트
축하합니다! 여기까지 왔다면 이 에이전트를 실행하여 시맨틱 리콜 기능을 테스트할 준비가 된 것입니다. 다행히도 Mastra는 기본 제공 채팅 UI를 제공하므로 자체적으로 구축할 필요가 없습니다.
Mastra 개발 서버를 시작하려면 터미널을 열고 다음 명령을 실행합니다:
서버를 처음 번들링하고 시작하면 플레이그라운드의 주소가 제공됩니다.

이 주소를 브라우저에 붙여넣으면 마스트라 스튜디오로 이동합니다.
knowledgeAgent 옵션을 선택하고 채팅을 시작합니다.
모든 것이 올바르게 연결되었는지 간단히 테스트하려면 "팀은 10월의 판매 실적이 12% 증가했다고 발표했습니다%, 주로 기업 리뉴얼에 힘입은 것입니다."와 같은 정보를 입력합니다. 다음 단계는 미드 마켓 고객으로 범위를 넓히는 것입니다." 다음으로 새 채팅을 시작하고 "다음에 어떤 고객 세그먼트에 집중해야 한다고 했나요?"와 같은 질문을 하세요. 지식 상담원은 첫 번째 채팅에서 제공한 정보를 기억할 수 있어야 합니다. 다음과 같은 응답이 표시되어야 합니다:

이와 같은 응답을 보면 에이전트가 이전 메시지를 Elasticsearch에 임베딩으로 성공적으로 저장하고 나중에 벡터 검색을 사용하여 검색했다는 뜻입니다.
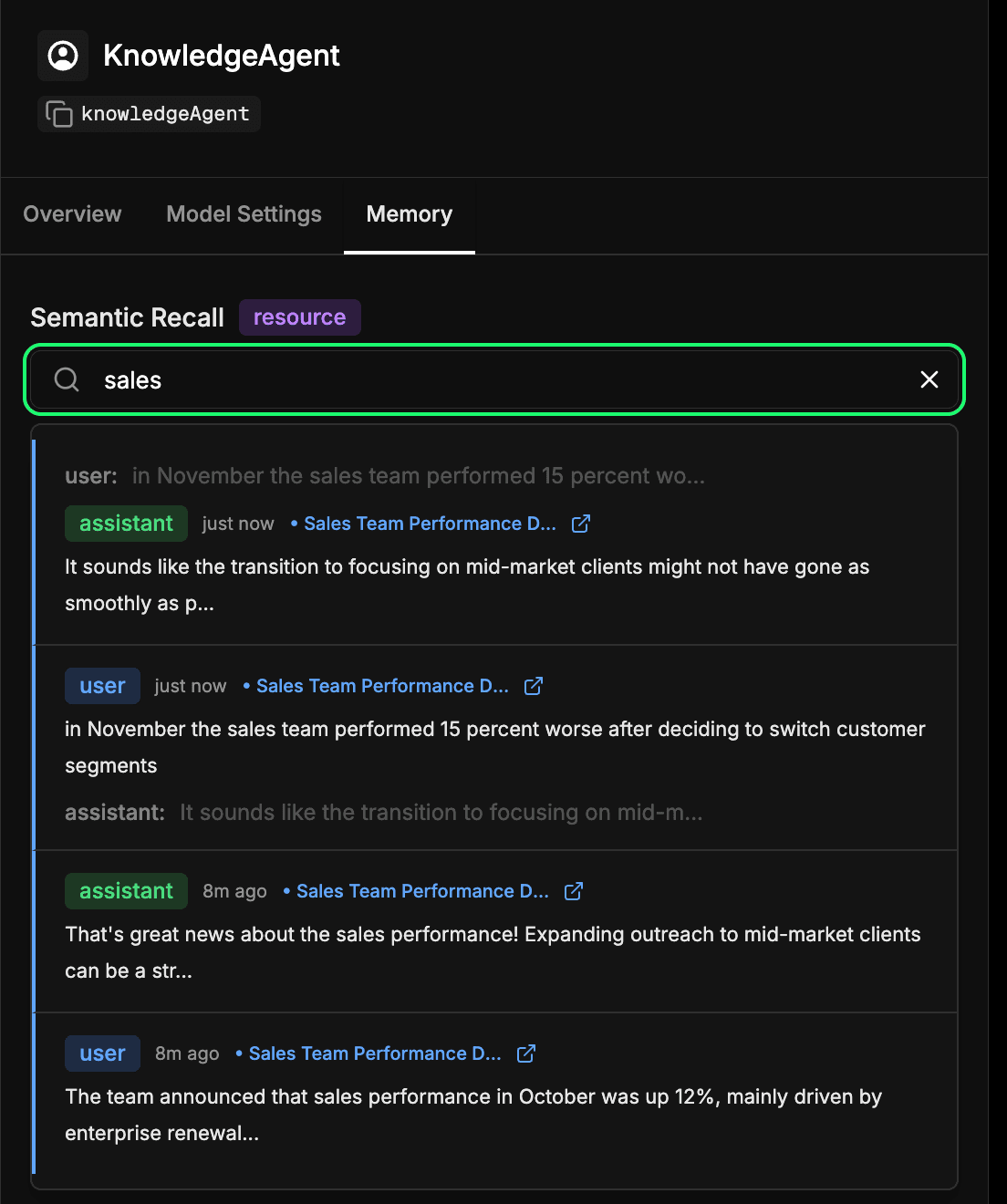
상담원의 장기 기억 저장소 검사하기
Mastra Studio의 상담원 구성에서 memory 탭으로 이동합니다. 이를 통해 상담원이 시간이 지남에 따라 학습한 내용을 확인할 수 있습니다. Elasticsearch에 포함되고 저장되는 모든 메시지, 응답, 상호 작용은 이 장기 기억의 일부가 됩니다. 과거 상호작용을 의미론적으로 검색하여 상담원이 이전에 학습한 정보나 컨텍스트를 빠르게 찾을 수 있습니다. 이는 기본적으로 에이전트가 시맨틱 리콜 중에 사용하는 것과 동일한 메커니즘이지만, 여기서 직접 검사할 수 있습니다. 아래 예시에서는 '판매'라는 용어를 검색하여 판매에 관한 내용이 포함된 모든 상호작용을 반환하고 있습니다.
결론
Mastra와 Elasticsearch를 연결하면 컨텍스트 엔지니어링의 핵심 계층인 메모리를 에이전트에게 제공할 수 있습니다. 시맨틱 리콜을 통해 상담원은 시간이 지남에 따라 컨텍스트를 구축하여 학습한 내용을 기반으로 응답할 수 있습니다. 이는 보다 정확하고 안정적이며 자연스러운 상호작용을 의미합니다.
이 초기 통합은 시작에 불과합니다. 여기서 동일한 패턴으로 과거 티켓을 기억하는 지원 상담원, 관련 문서를 검색하는 내부 봇, 대화 중에 고객 세부 정보를 기억할 수 있는 AI 어시스턴트 등을 만들 수 있습니다. 또한, 가까운 시일 내에 이 페어링이 더욱 원활하게 이루어질 수 있도록 공식적인 Mastra 통합을 위해 노력하고 있습니다.
여러분이 다음에 무엇을 만들지 기대가 됩니다. 한 번 사용해보시고 Mastra와 그 메모리 기능을 살펴보고 발견한 내용을 커뮤니티와 자유롭게 공유하세요.
관련 콘텐츠

2026년 5월 11일
강력한 기능을 더한 Elasticsearch: 네이티브 Prometheus API 지원 추가
기본 ProMQL, 탐색 및 메타데이터 엔드포인트를 통해 Prometheus 호환 클라이언트에서 직접 Elasticsearch를 쿼리하세요. Prometheus Remote Write로 Elasticsearch에 데이터를 보낼 수 있습니다.

2026년 4월 20일
Elastic Cloud Serverless 및 Elasticsearch용 통합 API 키 소개
Elastic이 글로벌 분산형 IAM 아키텍처를 통해 서버리스 환경에서 컨트롤 플레인과 데이터 플레인 인증을 어떻게 통합하는지 알아보세요. 클라우드 및 Elasticsearch API에 하나의 API 키를 사용하세요.

2026년 4월 8일
Mastra와 Elasticsearch로 에이전틱 AI 애플리케이션을 구축하는 방법
실제 예제를 통해 Mastra와 Elasticsearch로 에이전틱 AI 애플리케이션을 구축하는 방법을 알아보세요.
2026년 4월 3일
Elastic Workflows를 활용한 Kibana 대시보드 조회수 모니터링
Elastic Workflows를 사용하여 30분마다 Kibana 대시보드 조회 지표를 수집하고 이를 Elasticsearch에 인덱싱하는 방법을 알아보세요. 수집된 데이터를 바탕으로 맞춤형 분석 및 시각화 기능을 직접 구축할 수 있습니다.

2026년 3월 25일
셸 도구는 컨텍스트 엔지니어링을 위한 만능 해결책이 아닙니다
컨텍스트 엔지니어링을 위해 존재하는 컨텍스트 검색 도구와 그 작동 방식, 장단점에 대해 알아보세요.