Elasticオブザーバビリティで実施するSREとインシデントレスポンス
サービスの信頼性
何もかもが“デジタル”な時代に突入し、ソフトウェアサービスは最新のビジネスを代表する存在となっています。お手元のスマートフォンにも多種多様なアプリが入っているのではないでしょうか。ショッピング、バンキング、ストリーミング、ゲーム、読書、メッセージ、ライドシェア、スケジュール、検索…挙げればキリがありません。今、ソフトウェアサービスは社会を動かす仕組みの一部です。需要に応じてこの業界は爆発的に成長し、消費者が金銭や関心を消費する選択肢も増えました。企業はスワイプの操作1つでサービスを乗り換える消費者を惹きつけ、維持するために激しく競い合っています。
サービスの信頼性はユニバーサルな期待値です。つまり、あらゆるサービスが高速かつ機能的であることを期待されています。その期待に応えられないサービスはスワイプ1つで脱落し、消費者は彼らの時間を尊重してくれるサービスへ乗り換えてゆきます。広く知られている例として、2018年のAmazonプライムデーに生じたダウンタイム中、Amazonは1分あたり120万米ドルの売り上げを喪失したと推定されています。しかしサービスの信頼性は、テック業界の巨大企業でなくても実現できます。あらゆるビジネスにおいて、ダウンタイムやサービスの質の低下はただちに収益機会を奪い、やがて企業の評価を傷つけます。企業各社がオペレーションに多額を投資するのはそのためです。2018年のDevOpsソフトウェアへの投資額は52億米ドルに上ると試算されています。
本ブログ記事は、サービスの信頼性を最大に保つSite Reliability Engineeringおよびインシデントレスポンスライフサイクルの実践と、Elasticオブザーバビリティが信頼性の向上に果たす役割について説明します。このコンテンツは、ソフトウェアのサービスがエンドユーザーの期待値を満たすことに責務を負うテクニカルリーダーおよびエンジニアに向けて提供されています。本記事は、運用チームがSite Reliability Engineeringとインシデントレスポンスを実施する基本的な方法と、Elasticオブザーバビリティに代表されるテクノロジーソリューションが運用チームの各種目的達成に役立つ仕組みを解説します。
SREとは?
Site Reliability Engineering(SRE)とは、エンドユーザーのパフォーマンス期待値を確実に満たすための取り組みです。つまり、SREがサービスの信頼性を保ちます。信頼性という責務の歴史の長さは、"software as a service"と同一です。近年、Googleのエンジニアたちは"Site Reliability Engineering"という語を新たに作り、彼らのフレームワークを成文化しました。その内容は『Site Reliability Engineering』というタイトルで書籍化され、広い範囲に影響をもたらしています。本ブログ記事も、この書籍が提案するコンセプトを借用しています。
Site Reliability Engineers(SREs)は可用性、レイテンシー、質、利用率といった指標を使用し、サービス水準目標を達成する責務を負います。このようなタイプの変数は、サービスのユーザーエクスペリエンスに直接の影響を与えます。企業がSREsを重視するのもそれが理由です。満足度の高いサービスは収益を生み出し、効率的な運用はコスト制御を可能にします。その目的に鑑み、多くの現場でSREsは2つの業務にあたります。1つがサービス信頼性を守るためのインシデントレスポンス管理、もう1つが開発及び運用チームがサービス信頼性を最適化し、作業コストを抑制するために起用するソリューションとベストプラクティスの制定です。
またSREsは多くの場合、望ましいサービスの状態をSLAやSLO、SLIで定義します。
- Service Level Agreement(SLA) - "ユーザーは何を期待するか?"を定義します。SLAは、サービスプロバイダーがユーザーに提示するサービスの挙動の保証です。SLAの中には正式な契約として交わされ、不履行により顧客が被る影響について、サービスプロバイダーによる補償を強制するものもあります。契約によらない場合は暗示的な保証であり、オブザーブされるユーザーの挙動に依拠します。
- Service Level Objective(SLO) - "いつアクションするか?"を定義します。SLOは、サービスプロバイダーがSLAの不履行を防ぐ目的でアクションに踏み切る内部的な閾値です。たとえばサービスプロバイダーが99%の可用性を保証するSLAを提示している場合、より厳密な水準となる可用性99.9%のSLOを設定することで、SLAの不履行を回避するための十分な時間を持てる可能性があります。
- Service Level Indicator(SLI) - "何を測定するか?"を定義します。SLIは、SLAまたはSLOの状態を説明する観測可能なメトリックです。たとえば、サービスプロバイダーが99%の可用性を保証するSLAを提示している場合、サービスに対する正常なpingsのパーセンテージをSLIとして設定できます。
以下は、SREsが監視する一般的なSLIの例です。
- 可用性は、サービスのアップタイムを測定します。ユーザーはサービスがリクエストに応答することを期待します。可用性は、監視対象となるメトリックの中で最も基本的で重要な指標の1つです。
- レイテンシーは、サービスのパフォーマンスを測定します。ユーザーは、サービスがタイミングよくリクエストに応答することを期待します。"タイミングがよい"とユーザーが知覚する基準は、送信するリクエストのタイプによって異なります。
- エラーは、サービスの質と適正性を測定します。ユーザーはサービスが正常にリクエストに応答することを期待します。"正常"とユーザーが知覚する基準は、送信するリクエストのタイプによって異なります。
- 利用率はサービスのリソース使用状況を測定します。この指標は、サービスの需要を満たすためにリソースをスケールする必要性を示すこともあります。
サービスを開発、および運営するすべての担当者は、Site Reliability Engineerの肩書を持っていない場合も、そのサービスの信頼性に対する責務を有します。以下は、典型的に該当するチームの一部です。
- サービスを主導するプロダクトチーム
- サービスを開発する開発チーム
- インフラを実行する運用チーム
- ユーザーのインシデントをエスカレーションするサポートチーム
- インシデントを解決するオンコールチーム
複雑なサービスを展開する組織は、SREを主導し、他のチームの仲介役となる専任のSREsチームを設けていることもあります。その場合、SREsは"Dev"(開発)と"Ops"(運用)チームの架け橋として機能します。 結局のところ、実装の状況を問わず、サイトの信頼性はDevOpsサイクル全体が負う集合的な責任です。
インシデントレスポンスとは?
SREの文脈においてインシデントレスポンスとは、望ましくない状態のデプロイを望ましい状態に戻す取り組みです。SREsは望ましい状態がどういうものかを把握しており、その状態を維持するための、インシデントレスポンスライフサイクル管理を引き受けることも多くあります。このライフサイクルには一般的に防止、検出、解決のステップが含まれ、また最終目的として可能な限り自動化することを目指します。各項目ついて、詳しく見てみましょう。
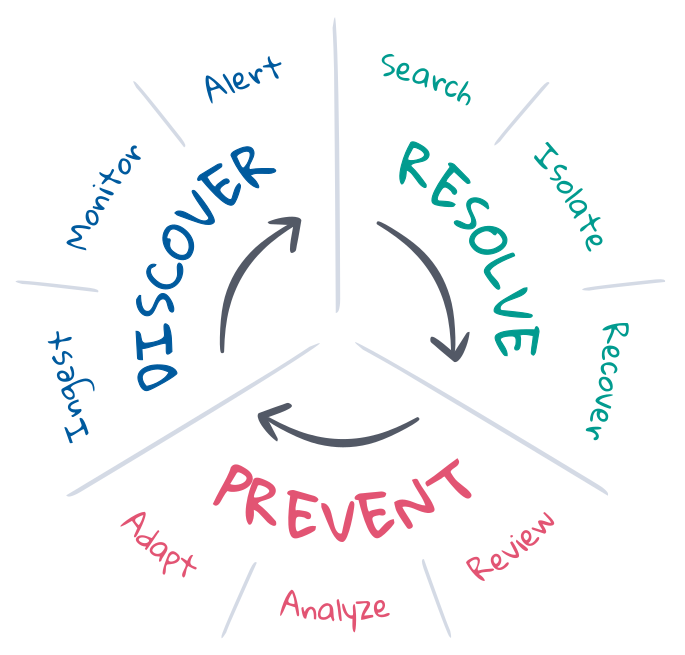
防止は、インシデントレスポンスの最初と最後に実施されるステップです。理想のシナリオは、CI/CDパイプラインでテスト主導の開発を行い、インシデントをあらかじめ防ぐことです。しかし運用段階においては物事が計画通りにいかないこともあります。SREsはプランニング、自動化、フィードバックを通じて防止の取り組みを最適化します。インシデントに先んじて、SREsは望ましい状態の基準を定義し、また望ましくない状態を検出、および解決するために必要なツーリングを実装します。インシデントの発生後は、ポストモーテムを実施して何が起きたかをレビューし、適応するための方法を検討します。SREsは長期にわたって各種KPIを分析し、そのインサイトを活用してプロダクト・開発・運用の各チームに対して改良のリクエストを提出します。
検出は、インシデントが生じた可能性のあるタイミングを特定し、適切なチャネルに対応を促すアラートを送信するステップです。インシデントレスポンスがカバーする範囲を最大化し、かつ平均復旧時間(MTTD)を最小化して、SLOを遵守するためには、検出を自動化する必要があります。自動化には、デプロイ全体の状態に対する継続的なオブザーバビリティと、望ましい状態の継続的監視、望ましくない状態となるイベントが生じた場合には速やかに通知する能力が必要です。機械学習は、インシデントの兆候や説明となりうる"予期しない状態変化"の検出に役立ちますが、インシデントの検出対象となる範囲および検出の有用性は、"望ましい状態"の定義に大きく依存します。
解決は、デプロイを望ましい状態に戻すステップです。インシデントの中には、自動のソリューションで解決されるものもあります。たとえばキャパシティが飽和状態に近づくと自動でスケールするサービスなどが該当します。しかし、多くのインシデントには人間の関与が必要です。特に、未知の症状や原因が不明なインシデントでその傾向は顕著です。解決には、根本原因の調査、および問題の切り分けと再現を行って解決策を規定し、デプロイを望ましい状態に復元する作業が必要です。これは、多数のエキスパートが調査や試行錯誤を行う反復的なプロセスです。このプロセスを成功に導く上で大きな役割を果たすのが、検索とコミュニケーションです。情報があれば、プロセスのサイクルを短縮し、平均復旧時間(MTTR)を最小化してSLOを遵守することができます。
SREとインシデントレスポンスにElasticプロダクトを活用する
Elasticオブザーバビリティはオブザーバビリティ、監視、アラート、検索の機能を搭載し、インシデントレスポンスライフサイクルを稼働させます。本記事は、このソリューションのフルスタックのデプロイの状態に対する継続的なオブザーバビリティ能力、SLOからの逸脱に対するSLIの継続監視能力、逸脱時にインシデントレスポンスチームに自動でアラートを送信する能力、担当者の早期解決を支援する直感的な検索エクスペリエンスについて説明します。Elasticオブザーバビリティはこれらの能力と機能を結集させて平均修復時間(MTTR)を最小化し、サービスの信頼性と顧客ロイヤルティを守ります。
オブザーバビリティとデータ
観測できない問題を解決することはできません。インシデントレスポンスを実行するには、時間とともに影響を受けるデプロイのスタック全体への可視性が必要です。しかし、下の図に示すように、分散型サービスの内部では単体の論理イベントすら非常に複雑です。スタックの各コンポーネントは、ダウンストリームで生じるあらゆる質の低下やエラーのソースである可能性があります。インシデントレスポンスの担当者は解決にあたって、制御や再現まではできないとしても、各コンポーネントの状態を考慮する必要があります。複雑さは生産性の敵です。1つのインターフェースで、時系列に沿ってあらゆるものの状態を観測することができなければ、要求水準の高いSLAの制限時間内にインシデントを解決することは不可能です。

こうした複雑性の問題について、Elasticが示す回答がElastic Common Schema(ECS)です。ECSは、オブザーバビリティのためのオープンソースのデータモデル規格であり、命名の規定やデータタイプ、モダンな分散型サービスやインフラの関係性を正規化します。ECSのスキーマは、従来はサイロ化されていたデータを使い、デプロイスタック全体の一元的なビューを時系列で提供します。スタックの各レイヤーのトレース、メトリック、ログがECSという1つのスキーマに共存することで、インシデントレスポンスにシームレスな検索エクスペリエンスを構築することが可能になります。
「手間をかけずにオブザーバビリティを確立する」、そんなことが、ECSによる正規化で実現します。ElasticのAPMエージェント、およびBeatsエージェントはデプロイから自動でトレースやメトリック、ログを収集し、そのデータをCommon Schemaの規格に準拠させ、調査のための一元的な検索プラットフォームにシッピングします。クラウドプラットフォームやコンテナー、システム、アプリケーションフレームワークといった一般的なデータソースの統合機能を搭載しており、デプロイが複雑化してもこのようなエージェントで簡単にデータを取り込み、管理することができます。
あらゆるデプロイスタックは、そのビジネスに固有のものです。そのため、ECSはユーザーが拡張して、組織のインシデントレスポンスワークフローを最適化できる仕様になっています。たとえばサービスやインフラのプロジェクト名は、インシデントレスポンス担当者によるデータの検索に役立ったり、それが何のデータであるかを判断する手助けとなったりします。アプリケーションのCommit IDは、開発時のバージョンコントロールシステム内で最初にバグが混入したバージョンを特定する手がかりとなります。機能フラグは、カナリアデプロイの状態やA/Bテストの結果についてのインサイトを提供します。デプロイの説明や、ワークフローの実行、ビジネス要件の遂行に役立つデータならなんでも、ECSのスキーマに埋め込むことができます。
監視、アラート、そしてアクション
Elasticオブザーバビリティは重要なSLIやSLOの監視、検出、アラートを実行することにより、インシデントレスポンスを自動化します。このソリューションは監視の4つの領域、すなわちUptime、APM、Metrics、Logsをカバーします。Uptimeは外部の稼働状況データをサービスのエンドポイントに送信することで、可用性(アベイラビリティ)を監視します。APMは、アプリケーション内で直接イベントを測定および捕捉することにより、レイテンシーと質を監視します。Metricsは、インフラリソースの使用量を測定することで、利用率を監視します。Logsはシステムとサービスからくるメッセージを捕捉することにより、適正性を監視します。
Elasticオブザーバビリティのユーザーは組織のSLIとSLOをアラートとアクションとして定義し、SLOから逸脱した場合に適切なデータが適切な担当者に共有されるよう設定することができます。Elasticのアラートは、あらかじめ予定したクエリの結果が一定の条件を満たす場合にトリガーされます。この条件は、メトリック(SLI)や閾値(SLO)の式です。アクションとは、ページングシステムやイシュートラッカーシステムなど1つ以上のチャネルに伝達されるメッセージであり、インシデントレスポンスのプロセスを開始するシグナルとなります。
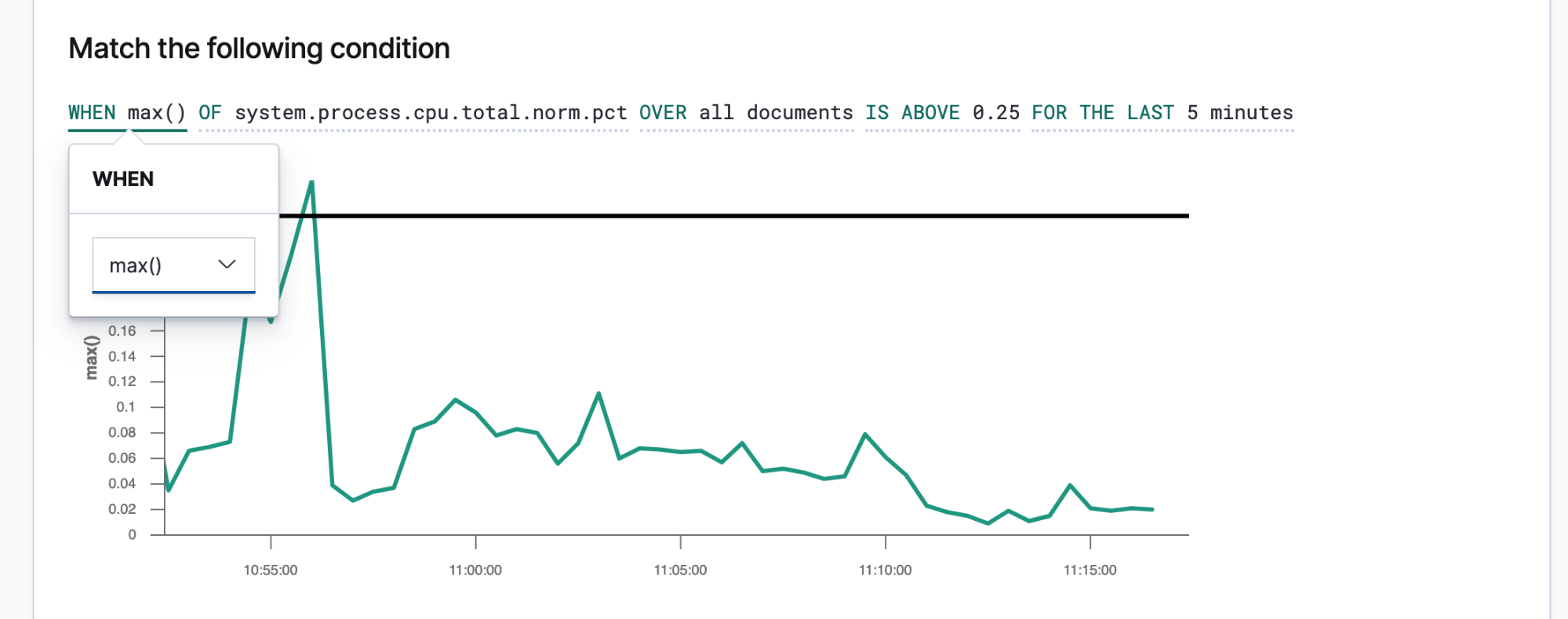
簡潔で実践的なアラートは、インシデントレスポンス担当者を迅速な解決に導きます。担当者が環境の状態と観測された問題を再現するには、十分な情報を入手する必要があります。そうした詳細情報を担当者に提供するには、メッセージテンプレートを作成する必要があります。以下は、テンプレートに入れるとよい情報の例です。
- 件名 - "インシデントの内容"
- 深刻度 - "インシデントの優先度"
- 論理的根拠 - "インシデントがビジネスにもたらす影響"
- 観測された状態 - "何が起きたか"
- 望ましい状態 - "何が起きる想定だったか"
- コンテクスト - "環境の状態はどうだったか"、アラートのデータを使用して日時、クラウド、ネットワーク、、オペレーティングシステム、コンテナー、プロセス、およびインシデントに関するその他のコンテクストを記述します。
- リンク - "次にどこを開くか?"アラートのデータを使用して、担当者がダッシュボードやエラーレポート、その他の便利な参照先を開くためのリンクを作成します。
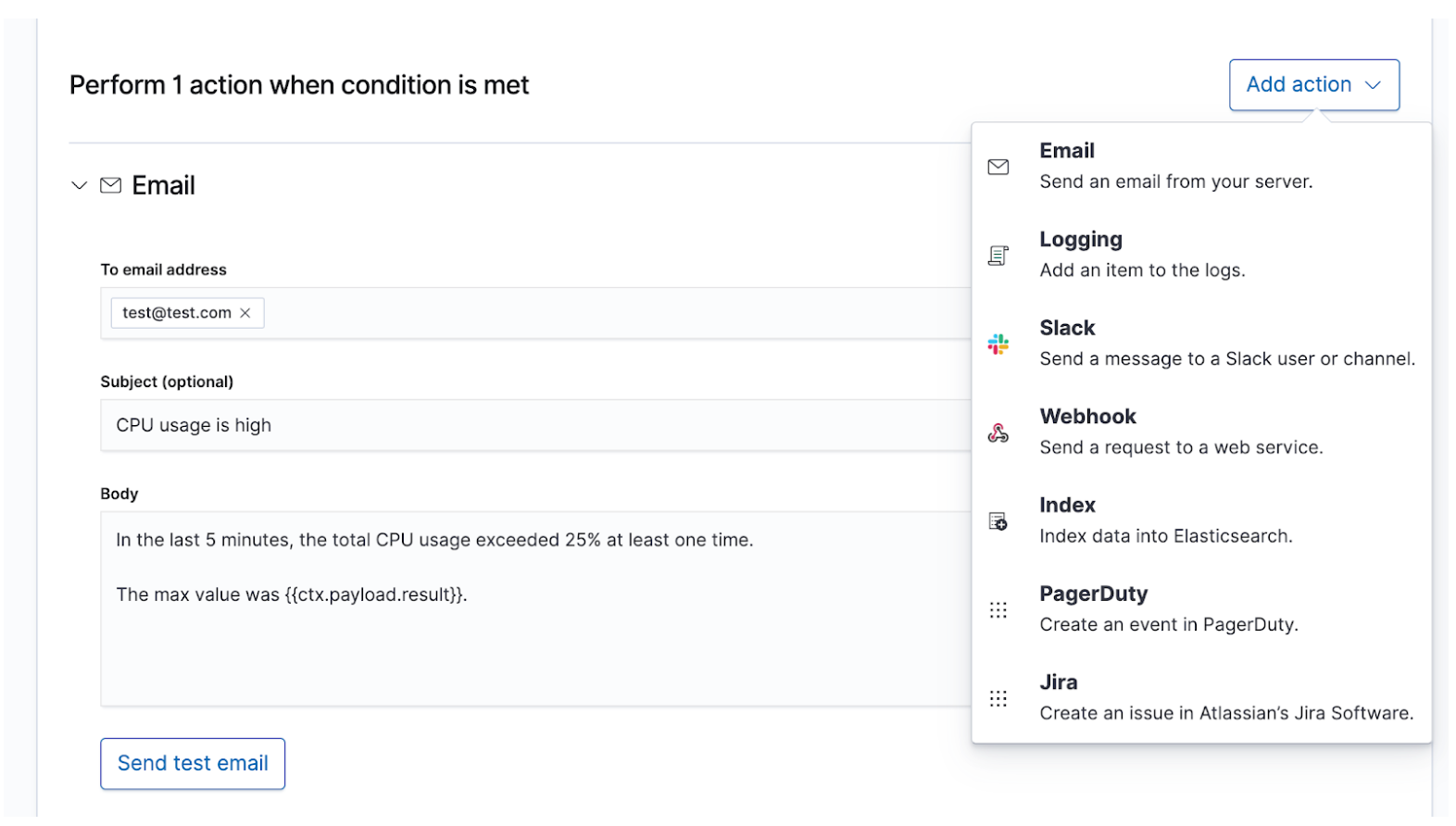
人間の目で至急確認する必要がある、深刻度の高いインシデントについては、PagerDutyやSlackなどのリアルタイムなチャネルを経由してオンコールのインシデントレスポンスチームにアラートを送信する必要があります。たとえば、最低でも99%の可用性を求められるサービスのダウンタイムなどが該当します。このSLAで許可されるダウンタイムは1日あたり15分未満ですが、これはインシデントレスポンスチームが問題解決までに必要とする時間より短いかもしれません。最終的に人間の目で確認するが、深刻度が低いインシデントについては、JIRAなどのイシュートラッキングシステムでチケットを作成することができます。たとえば、サービスのレイテンシーやエラー率の上昇があり、売上に直接的な影響がない場合が該当します。履歴の保存やオーバーコミュニケーションの目的で、1つのアラートに複数の宛先を設定し、それぞれに独自のメッセージコンテンツを含めることもできます。
調査と検索
アラートによってオンコールチームが呼び出された後は、どうなるでしょうか。解決のパスはインシデントによって異なりますが、共通することもあります。データという消火ホースを配備する間も、異なるスキルや経験を持った担当者が不確かな問題をすばやく、正確に解決しなければならないというプレッシャーの下で作業しています。報告された症状を見つけ、問題を再現し、根本原因を調査して解決策を適用し、問題が解決するかどうか確認する必要があります複数の仮説を試す必要がある場合もあります。解明できない現象に遭遇することもあるかもしれません。こうした取り組みのすべての現場に、カフェイン回答が求められています。不確実性から解決へと、インシデントレスポンスを推し進める原動力は情報です。
インシデントレスポンスは検索の課題です。検索は、問いに対してすばやく、関連性のある回答を返します。すぐれた検索エクスペリエンスには、単なる"検索バー"以上の価値があります。すぐれた検索エクスペリエンスは、ユーザーインターフェース全体でユーザーの質問を予期し、適切な回答に導くことができます。最近、オンラインでした買い物のことを思い出してみてください。商品リストの閲覧中、アプリケーションはあなたがクリックしたり、検索しそうな商品を予測して、おすすめの商品や絞り込み条件を表示したはずです。そのような表示はユーザーに予定よりたくさんの買い物をさせたり、すばやく決済を完了させるといった影響を及ぼします。ところで、この買い物の間、あなたは一度も構造化クエリを記述していません。自分でもどの商品を探しているか知らなかったのに、すばやく見つかったかもしれません。この原理は、インシデントレスポンスにも適用できます。検索エクスペリエンスの設計は、インシデントの解決時間に大きな影響を与えます。
検索というテクノロジーがインシデントレスポンスにおいて重要な役割を持つのは、単に高速だから、というだけではありません。エクスペリエンスが直感的であることも大きな理由です。担当者の誰一人として、クエリ言語の構文を学習する必要がありません。誰もスキーマを参照する必要はありません。誰もマシンのように完璧である必要などないのです。検索するだけで、数秒のうちに探している情報が見つかります。そもそも、検索というテクノロジーの目的はそういうことです。そして検索は、ガイダンスを提示することもできます。特定のフィールドで検索を実行するかどうか、オプションを提示します。入力をはじめると、検索バーがフィールドを提案します。たとえば「チャート上のスパイクに関心がおありですか?」といった提案です。スパイクをクリックすると、ダッシュボードの別の場所にスパイクの最中に何が起きたか表示されます。人間は生来“不完全”ですが、検索は高速で寛容な技術です。インシデントレスポンスの担当者は検索を適切に実行することで、すばやく、適切に行動する力を手にすることができます。
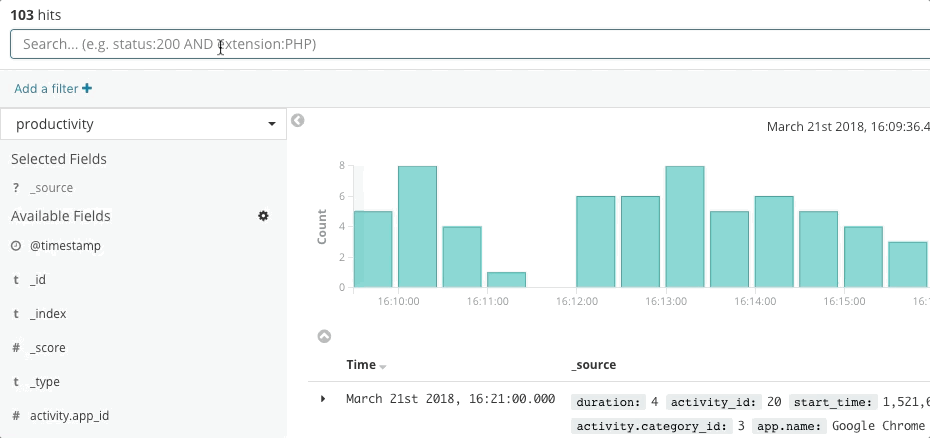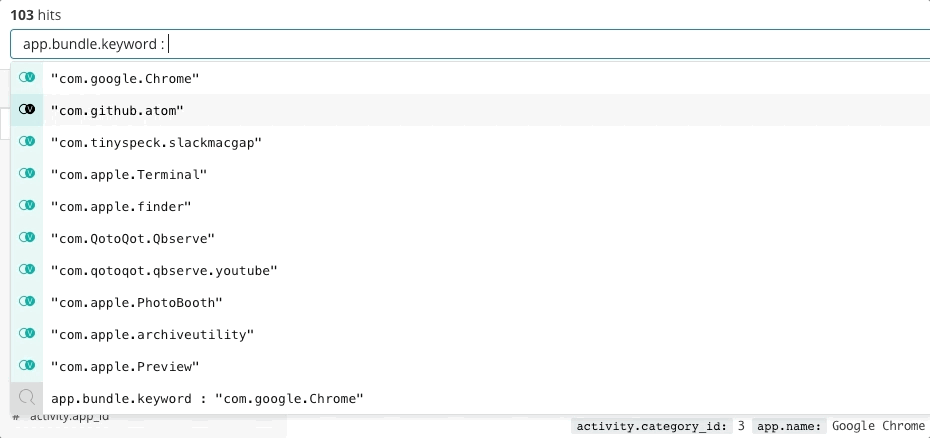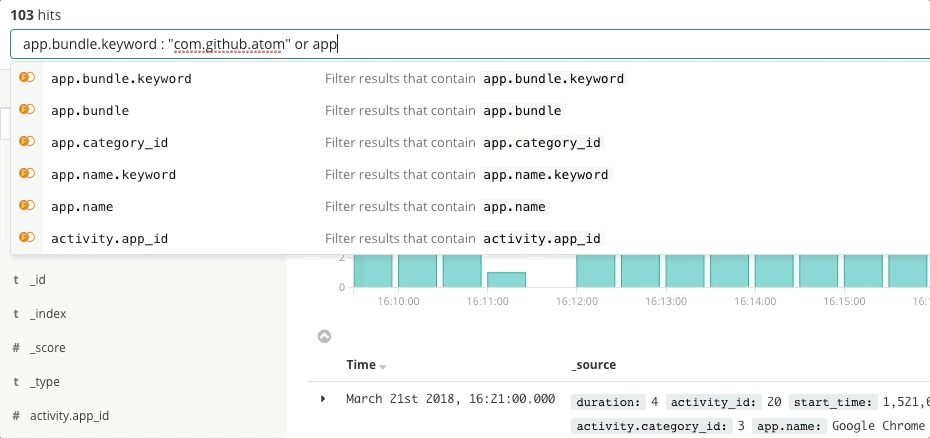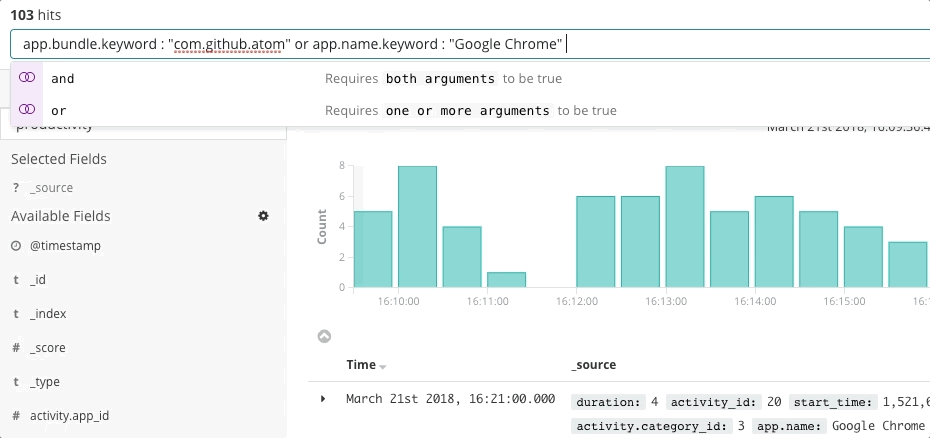
Elasticオブザーバビリティはインシデントレスポンスに役立つ検索エクスペリエンスを提供します。つまり、担当者の質問や期待値、目的を予期する能力を備えています。操作のエクスペリエンスは一見、従来の各データサイロのものとあまり変わりません。担当者はUptime、APM、Metrics、Logsの各アプリでデータを検索できます。従来型のプロダクトと異なるのは、そこからさらに横断的な検索ガイドを使ってデプロイの完全なスタックを確認できるよう設計されている点です。データ自体がサイロではなく、Common Schema内に存在することで、このようなエクスペリエンスが可能になります。この設計は、可用性、レイテンシー、エラー、利用率という基本的な質問に効果的に回答し、最適なエクスペリエンスを経由して根本原因へとナビゲートします。
このエクスペリエンスの例をいくつか見てみましょう。
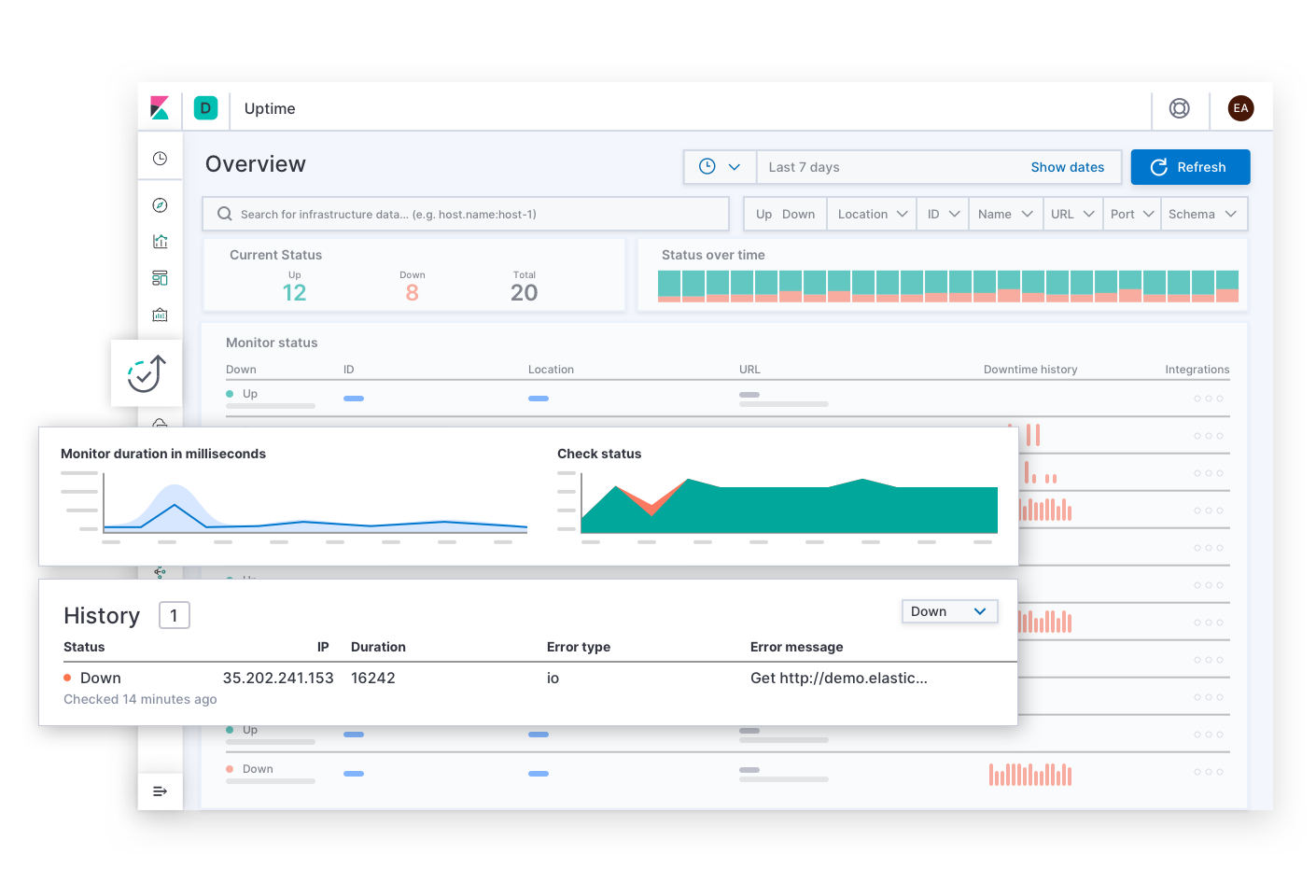
Elastic Uptimeは、"どのサービスがダウンしているか?、いつダウンしたのか?、稼働状況の監視エージェントはダウンしたか?"といった、サービスの可用性に関する基本的な質問に回答します。インシデントレスポンス担当者は、可用性に関するSLOのアラートからこのページを開くことも可能です。利用不可となっているサービスの兆候を見つけたら、次に担当者は各種のリンクをたどって影響を受けたサービスのトレースやメトリック、ログのほか、エラーが生じたときのデプロイインフラについて調査することができます。担当者が操作する間、調査のコンテクストとして、影響を受けたサービスのフィルターはずっと適用されており、担当者がサービスのダウンタイムの根本原因まで詳細をドリルダウンする手助けとなります。
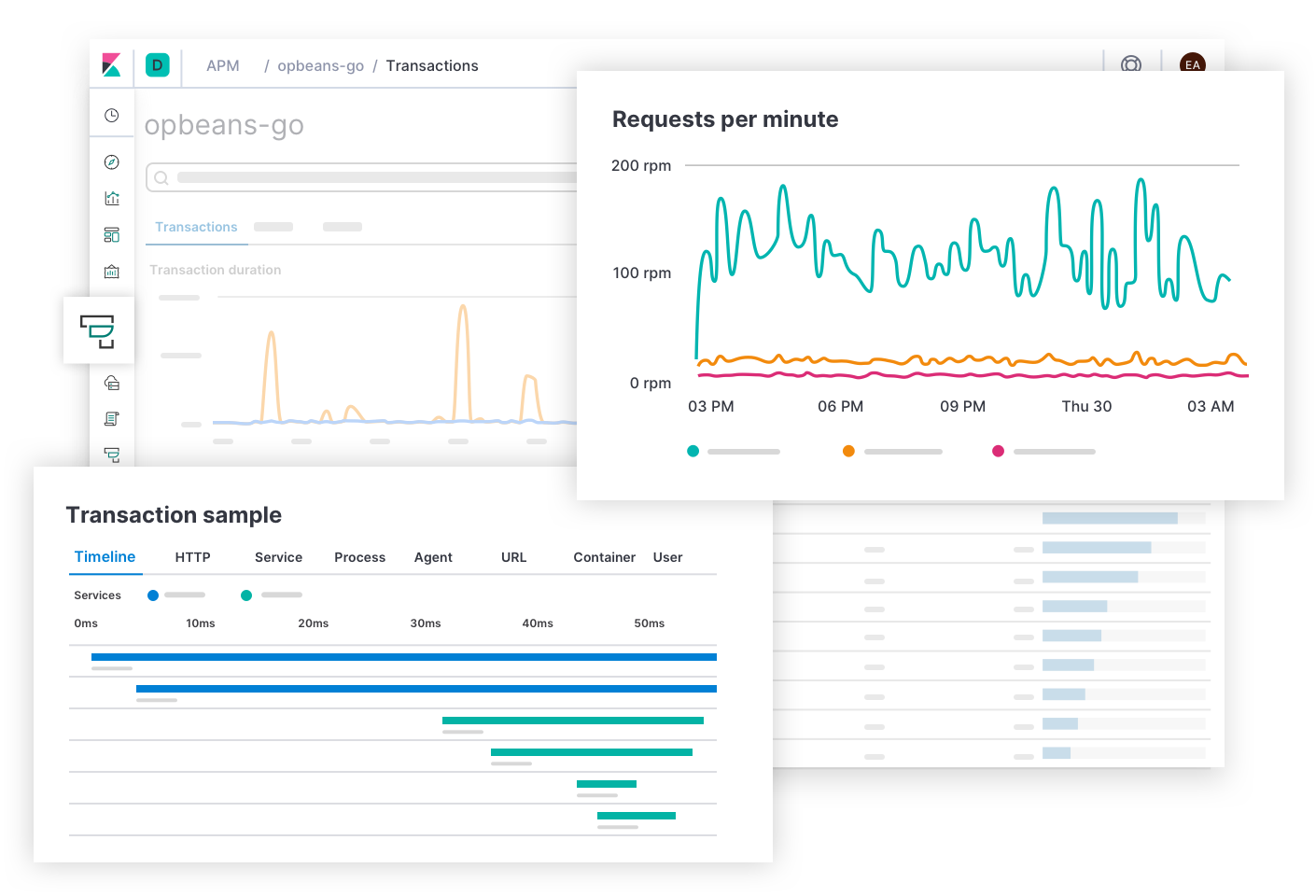
Elastic APMは、"どのエンドポイントがユーザーエクスペリエンスに最もネガティブな影響を与えているか?、どのスパンでトランザクションが低速化しているか?、分散サービスのトランザクションをどのようにトレースできるか?、ソースコードのどこにエラーがあるか?、運用環境の条件と一致する開発環境で、どのようにエラーを再現できるか?"といった、サービスのレイテンシーとエラーに関する質問に回答します。インシデントレスポンス担当者は、レイテンシーやエラーに関するSLOのアラートからこのページを開くことも可能です。APMのエクスペリエンスを活用することで、アプリ開発者は必要な情報を入手し、バグの再現や修正を行うことができます。インシデントレスポンス担当者はスタックの下層に移動して、影響を受けたサービスがデプロイされているインフラのメトリックを表示し、レイテンシーの原因を探ることができます。
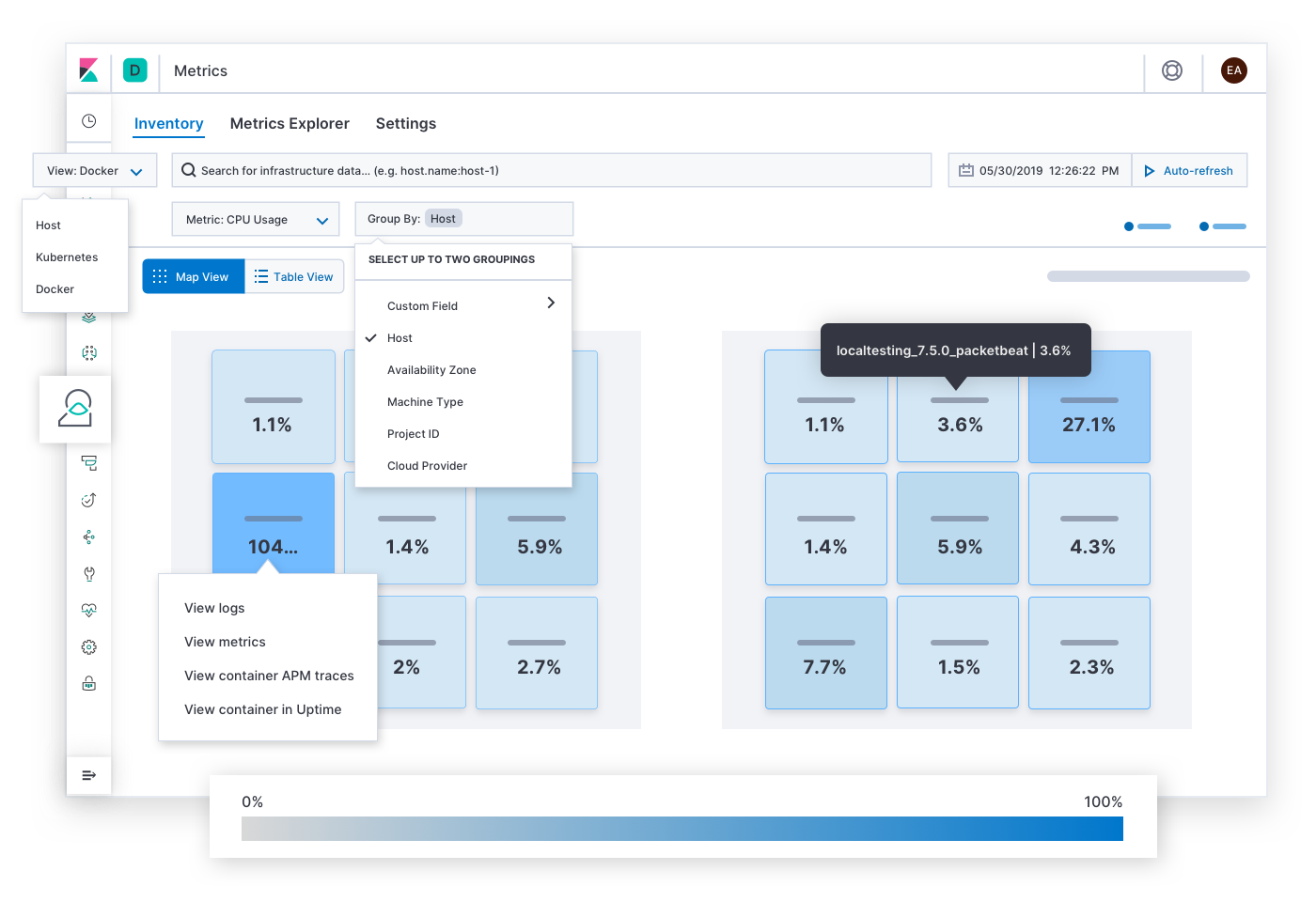
Elastic Metricsは、"どのホストやpod、コンテナーがメモリを大量に、あるいは少量消費しているか?、ストレージはどうか?、演算処理は?、ネットワークトラフィックは?、クラウドプロバイダー別や、地理空間地域別、アベイラビリティゾーン別、その他の値ごとにグループ化すると何が分かるか?"といった、リソース利用率に関する質問に回答します。インシデントレスポンス担当者は、利用率に関するSLOのアラートからこのページを開くことも可能です。輻輳やホットスポット、ブラウンアウトの症状を発見したら、次に担当者は影響を受けたインフラのメトリックやログの履歴範囲を広げたり、インフラ上でのサービスの挙動をドリルダウンして探ったりできます。
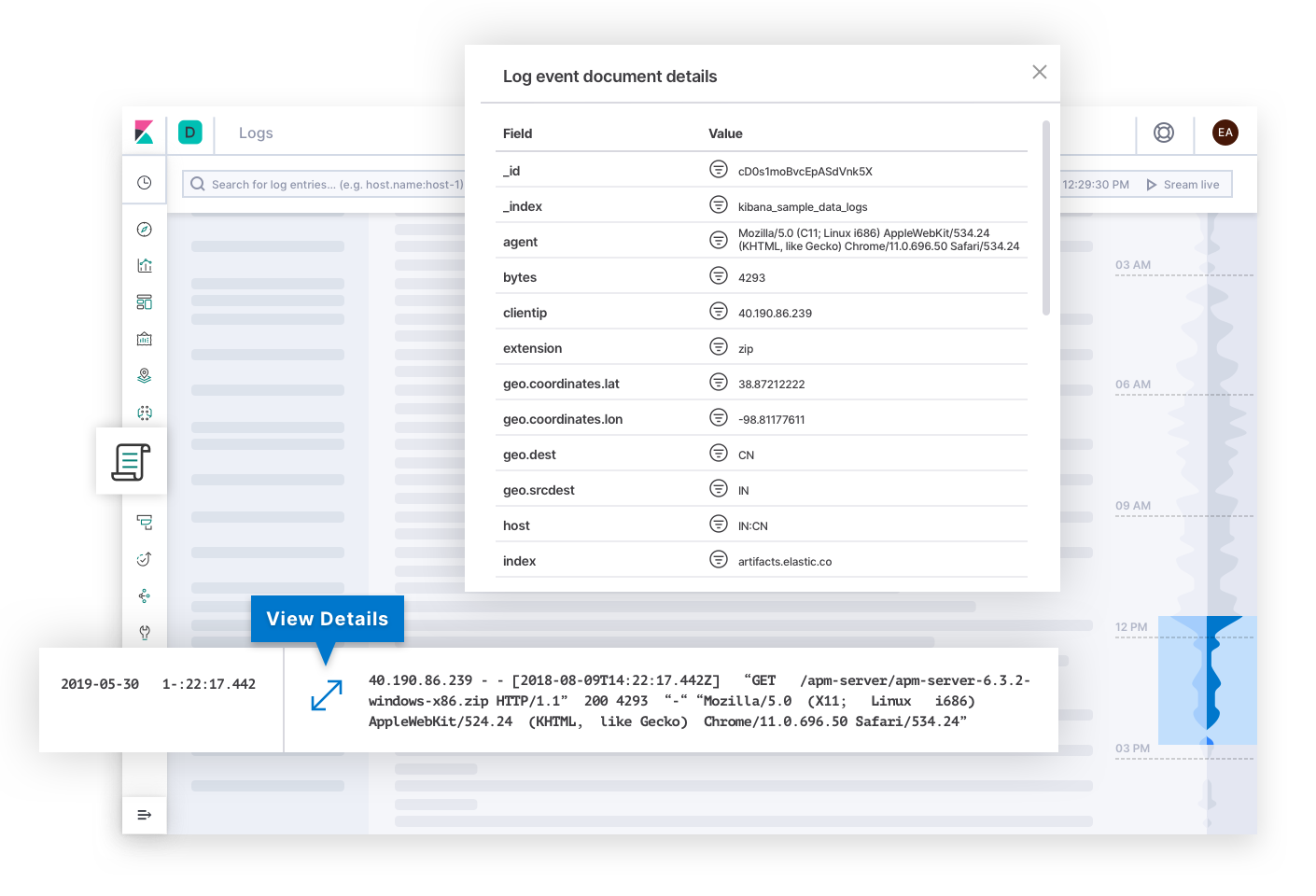
Elastic Logsは、システムとアプリケーションから発されたイベントの信頼できるソースに関する質問に回答します。インシデントレスポンス担当者は、質や適性性に関するSLOのアラートからこのページを開くことも可能です。ログはエラーの根本原因を説き明かすことがあり、調査の終点となる可能性もあります。あるいは、ログが他の症状の原因の説明を提供し、それが手がかりとなって担当者が根本原因にたどり着くこともあります。Elastic Logsのテクノロジーは水面下でログを分類したり、テキストに潜む傾向を発見し、デプロイの状態変化を説明するシグナルを担当者に提示することができます。
数千人ものお客様やコミュニティメンバーからお寄せいただいた意見やフィードバックのおかげで、Elasticのエンジニアはオブザーバビリティの目的に幅広く応用できる検索エクスペリエンスを設計することができました。しかし結局のところ、特定のデプロイを熟知しているのは現場のSREsです。Elasticの提案とは異なる、組織固有の運用ニーズに特化したエクスペリエンスを求めることもあるかもしれません。Elasticオブザーバビリティが、Elastic Stackに入れたデータで独自のカスタムダッシュボードや可視化を作成したり、必要な人に共有したりできる設計となっているのはそのためです。このような作業は、ドラッグ&ドロップするだけのシンプルな操作で実行できます。
毎日の更新作業を必要としないCanvasは、チームを横断して、あるいは経営陣への報告用にKPIを表現できるクリエイティブなメディアです。ダッシュボードが技術的な問題解決のためのメディアであるのに対し、こちらはビジネスストーリーを伝えるインフォグラフィックとして使えます。その日のユーザーエクスペリエンスを、SLOのマス目をニコニコ顔と悲しい表情のマークで表現するなんて最高だと思いませんか?エラーバジェットの現在の残額を説明するのに、「運用環境でのコードテストに使える時間はあと12分です。(やめておきましょう!)」と書くことだってできます。つまり、対象となるオーディエンスを把握していれば、Canvasを使って、複雑な状況も有意義なストーリーの形式で表現できるということです。

活用例
ここからは、Elasticオブザーバビリティのより実践的な活用例をいくつか見てみましょう。以下で取り上げるシナリオは、いずれも異なるSLIのアラートからはじまり、それぞれ解決のパスが異なります。解決の過程では、複数のチームの担当者の関与を必要とする可能性があります。Elasticのソリューションは、多様な状況下で迅速な解決を目指すインシデントレスポンスチームをサポートします。
可用性 - なぜサービスはダウンしているのか
99%の可用性が求められるデプロイで、Elasticオブザーバビリティが応答しないサービスを検知し、オンコールチームを呼び出しました。運用チームに所属するラメシュさんが指揮をとります。彼はリンクをクリックして、アップタイムの履歴を確認しました。監視エージェントが正常であることが確認され、このアラートが誤検知である可能性は乏しいと判断できます。次にラメシュさんは、影響を受けたサービスからそのホストのメトリックに移動し、そのメトリックをホスト別、およびコンテナー別にグループ化しました。該当のホストに、メトリックを報告しているコンテナーはありません。「問題は、スタックのさらに上層で起きているはずだ」と考え、データをアベイラビリティゾーン別とホスト別にグループ化し直しました。影響を受けたゾーンにある他のホストはすべて正常です。しかし、彼が影響を受けたサービスの複製を実行するホストでフィルターをかけると、ホストの報告が見当たりません。「一連のホストはなぜ、この1つのサービスに限ってエラーを起こすのだろう?」ラメシュさんはそう考え、リンクをSlackの#opsチャンネルに共有しました。するとあるエンジニアが、最近、そのサービスを実行するホストを設定するplaybookを更新したと言います。彼女がその変更をロールバックすると、画面にメトリックのストリーミングが現れました。一命をとりとめることができました。この問題の解決には12分かかりましたが、それでも99%のSLAを維持できています。その後、別のエンジニアがホストのログをレビューして、ホストをダウンさせた変更の原因についてトラブルシューティングを実施し、再度適切な変更を行いました。
レイテンシー - なぜサービスは低速なのか
Elasticオブザーバビリティが複数のサービスで異常なレイテンシーを検知し、イシュートラッキングシステムでチケットが作成されました。担当のアプリ開発者たちはミーティングを開き、このレイテンシーに最も関与するスパンを見つけようと、サンプルトレースをレビューしました。そしてサービスのレイテンシーのパターンが、あるデータ検証サービスと連動していることを発見しました。サービスの開発者のリーダーを務めるサンディープさんは、これらのスパンを詳しく調べることにしました。一連のスパンは実行時間の長いクエリをデータベースに報告しており、その事実はslowlogの異常なログレートでも確認することができます。彼はそのクエリを調査し、ローカルの環境で再現してみました。このクエリのステートメントはインデックスが未了の行を組み合わせており、最近になってデータがバルクで挿入され、低速化を起こすまで気づかれないままでした。サンディープさんが表を最適化するとサービスのレイテンシーは改善しましたが、まだ必要なSLOに到達しません。そこで方向性を転換し、コンテクスチュアルフィルターを使って、サンプルトーレスを初期のバージョンのサービスのトレースと比較することにしました。すると、クエリ結果を処理している複数の新しいスパンがあるとわかりました。さらにローカル環境のスタックトレースをたどると、各クエリ結果について一連の正規表現を評価するメソッドに行きつきました。彼はこのコードを調整し、ループの手前でパターンをプリコンパイルしました。変更をコミットすると、サービスのレイテンシーはSLOを満たす水準に戻りました。サンディープさんは、問題を"解決済み"としてマークしました。
エラー - なぜサービスでエラーが生じるのか
エスターさんは、オンライン小売業者向けのアカウント登録サービスでリーダーを務めるソフトウェア開発者です。今、彼女はチームのイシュートラッキングシステムから通知を受け取りました。通知には、シンガポールリージョンのプロダクション登録サービスで過度のエラーレートが検知されているとあり、新たなビジネス機会を失う可能性があります。エスターさんが問題の説明に含まれたリンクをクリックすると、登録フォームの送信エンドポイントに未処理の"Unicode Decode Error"のエラーグループがありました。サンプルを開くと、ファイル名、エラーを起こした部分のコード行、スタックトレース、環境についてのコンテクスト、アプリケーション開発時のソースコードのコミットハッシュも含む、“犯人像”の詳細情報がありました。エスターさんはそこで、プライバシー法規に準拠する目的で登録フォームが何らかの編集されたデータをインプットしていることを確認しました。さらにエスターさんは、そのインプットにベトナム語のUnicode文字が含まれていることに気づきました。これらのすべての情報を使って、彼女はローカルのマシンで問題を再現しました。そしてUnicodeハンドラーを修正し、変更をコミットします。CI/CDパイプラインがテストを実行した結果は「パス」となり、エスターさんは更新したアプリを運用環境にデプロイしました。彼女は問題を"解決済み"としてマークし、通常業務に戻りました。
利用率 - 上限に達しそうなサービスを特定せよ
Elasticオブザーバビリティがメモリ使用量の異常を検知し、インフルエンサーとなるクラウドリージョンのリストが作られるとともに、イシュートラッキングシステムでチケットが作成されました。オペレーターがこのリンクをクリックすると、時系列でリージョン別のメモリー使用量が表示されます。ベルリンのリージョンで何の前触れもなく、赤い点のスパイクが生じており、それ以降使用量は緩やかに上昇しています。この状態が続けば、まもなくメモリが不足すると予測されます。彼女は世界中の全podの最近のメモリメトリックを確認しました。ベルリンのpodの利用率は、他のリージョンより明らかに高くなっています。そこでpodをサービス名でグループ化し、また"ベルリン"でフィルタリングして検索範囲を絞り込みました。すると、あるサービスが突出していました。商品をおすすめするサービスです。次に検索範囲を拡大し、世界中でこのサービスの複製を確認したところ、ベルリンリージョンのメモリ使用量が最も多く、複製podの数も最多であることがわかりました。彼女はベルリンにおけるこのサービスのトランザクションをドリルダウンし、このサービスのリーダーを務めるアプリ開発者にダッシュボードのリンクを共有しました。この開発者は、トランザクションのコンテクストを読み解きました。彼が見つけたのは、あるA/Bテストのためにベルリンだけでリリースされた機能フラグのカスタムラベルです。彼はサービスを調整して、時間とともに増大するあるデータセットの読み込みパフォーマンスを下げました。更新したサービスをCI/CDパイプラインにデプロイすると、メモリ使用量は正常に戻りました。オペレーターは問題を"解決済み"としてマークしました。この問題がビジネスに影響する兆候はありませんでしたが、Elasticオブザーバビリティがスパイクを検知しなければ、いずれ影響していたと予測されます。
ケーススタディー
Elasticオブザーバビリティのバリューを実証する導入事例は枚挙にいとまがありません。そのような素晴らしいストーリーの1つに、米国の通信コングロマリットであり、ダウ平均株価の構成銘柄にも選出されているベライゾン・コミュニケーションズ社の事例があります。ベライゾン社は証券取引委員会に対する2019年度の年間報告書で、ビジネスにおける競争リスクの最大要因は"ネットワークの質、キャパシティ、範囲"および"カスタマーサービスの質"であると記述しています。この年、同社の総収入となる1309億ドルのうち、69.3%をワイヤレス部門の"ベライゾンワイヤレス"の収入が占めました。ベライゾンワイヤレスのインフラストラクチャー運用チームは、レガシーの監視ソリューションをElasticのソリューションにリプレースしたことで、「20-30分だったMTTRが2-3分に短縮」し、それが「顧客へのすぐれたサービス提供に直接貢献した」と証言しています。 サービス信頼性とインシデントレスポンス、そしてElastic Stack - この3要素は、通信業界をはじめ、信頼あるサービスの提供責務を負う他のビジネス分野で競争力を発揮するための基礎となります。
次のステップへ
ソフトウェアサービスの信頼性を最大に高め、自信をもってサービスを提供する上で役立つステップをいくつかご紹介します。