The stateless architecture of Elasticsearch Serverless
Exploring the stateless architecture of Elasticsearch Serverless. Learn how the stateful architecture was transformed into stateless for Serverless.
We're thrilled to announce the publication of our new peer-reviewed paper, Serverless Elasticsearch: the Architecture Transformation from Stateful to Stateless, which was accepted and presented at the industrial track of the 2025 Association for Computing Machinery (ACM) Symposium on Cloud Computing (SoCC). The paper gives a concise view of our recent innovations in Elasticsearch. At Elastic, we’re relentlessly focused on the future of search. From optimizing performance to simplifying operations, our teams are always exploring what's next.
This paper isn't just an academic exercise. It's a foundational exploration of how the core of a search engine could be reimagined for a purely serverless world. We decouple storage from compute: Data lives in a cloud blob store with virtually infinite storage and scalability. That vision is the main driver behind our Elastic Cloud Serverless offering: seamless search over massive datasets, with the economics and operational simplicity of serverless.
The challenge: Rethinking stateful search for the cloud
For decades, search engines have been powerful, stateful systems. Deploying a production-grade cluster like Elasticsearch has meant:
Provisioning servers and managing storage.
Carefully tuning configurations for cost, performance, and reliability.
Paying for idle capacity when workloads are spiky or unpredictable.
Significant operational effort to scale up and down.
Modern cloud platforms have made some of this easier, but the fundamental tension remains:
Can we build a search engine that delivers the power and rich query capabilities of Elasticsearch with the economics and operational simplicity of a serverless architecture?
That question drove our research.
Our key contributions
The paper presents concrete innovations that make Elasticsearch Serverless possible:
Object store as single source of truth: We offload index data, the transaction log (translog), and cluster state to a cloud object store. That eliminates replica shards for durability and makes the object store the sync point between indexing and search.
"Thin" (stateless) shards: Shards recover and relocate quickly across nodes without copying large amounts of data. Disks are used only for caching, not for persistent storage.
Batched compound commits (BCC): We wrap index commits in a custom format, cutting upload costs, while keeping the same read-after-write semantics as Elasticsearch.
Batched translog uploads: Translog uploads are batched at the node level, cutting upload costs.
Smart garbage collection: We track the usage of BCCs and translogs we’ve uploaded, and we delete them once they’re unused, to reduce storage footprint and retention costs.
Autoscaling: We scale automatically with ingestion and search load so clients can call APIs without managing cluster size.
The bottom line: In our experiments, Elasticsearch Serverless achieves up to twice the indexing throughput of stateful Elasticsearch on comparable hardware and scales linearly with autoscaling to match ingestion load.
Visualizing the architecture
Figure 1 in the paper gives a clear side-by-side view: stateful Elasticsearch versus the new stateless architecture Elasticsearch Serverless.
Stateful Elasticsearch (top): Familiar data tiers: hot, warm, cold, frozen. Data lives on local disks; primaries and replicas are spread across nodes; colder tiers may use searchable snapshots on an object store.
Elasticsearch Serverless (bottom): Just two tiers: indexing and search. All durable data (Lucene commits, translogs, cluster state) lives in the object store. Indexing nodes write and upload; search nodes read from the object store and a shared cache, with no local persistence of index data.
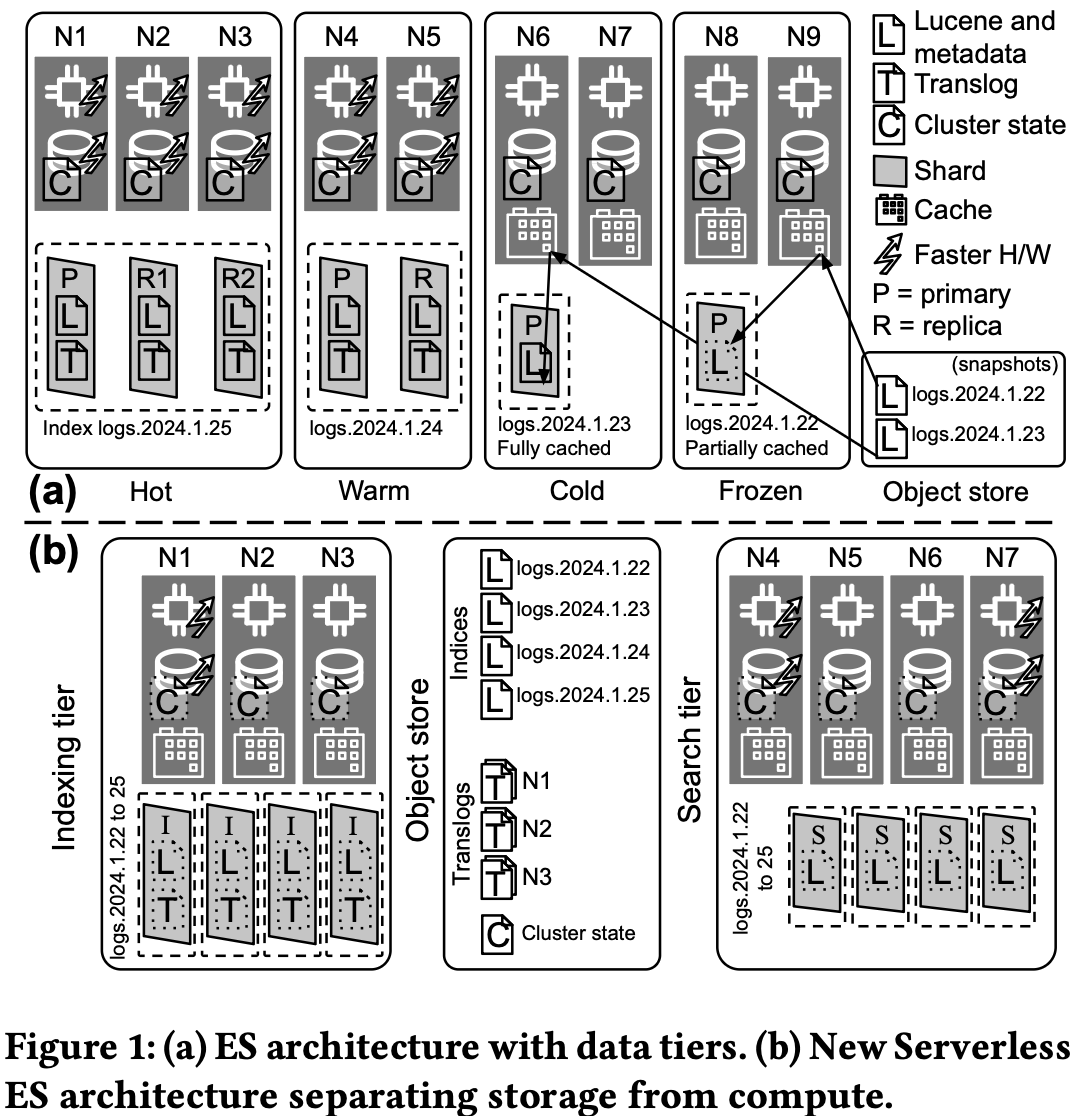
The takeaway: a complete separation between the resources used for indexing and those used for querying.
A tale of two data flow paths
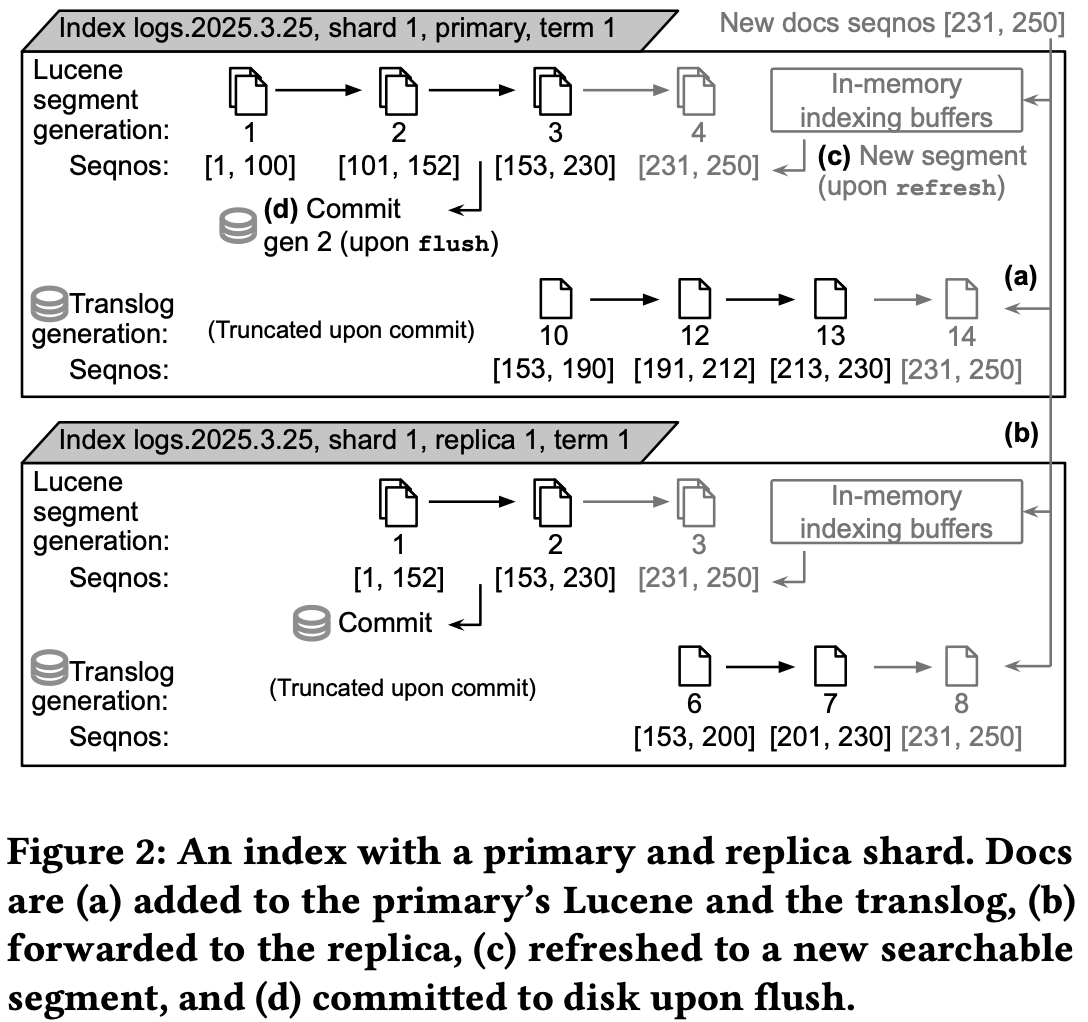
Figures 2 and 3 in the paper contrast how data flows in stateful versus Elasticsearch Serverless.
Stateful Elasticsearch (figure 2):
Documents go to the primary shard's Lucene buffers and translog and then to replica shards.
After refresh, the documents go to new searchable segments.
After flush, they’re committed to disk.
Thus, durability is given by the disk and the replicas.
Elasticsearch Serverless (figure 3):
Documents go to Lucene and the translog on an indexing node.
Before acknowledging the client, the translog is uploaded to the object store.
After refresh, the documents go to new searchable segments and are committed to disk in the indexing nodes.
After flush, they go into BCCs and are uploaded to the blob object store.
Search nodes serve queries from the object store (and, for recent data not yet uploaded, directly from the indexing node).
Thus, durability comes from the object store, not from disk or replicas.
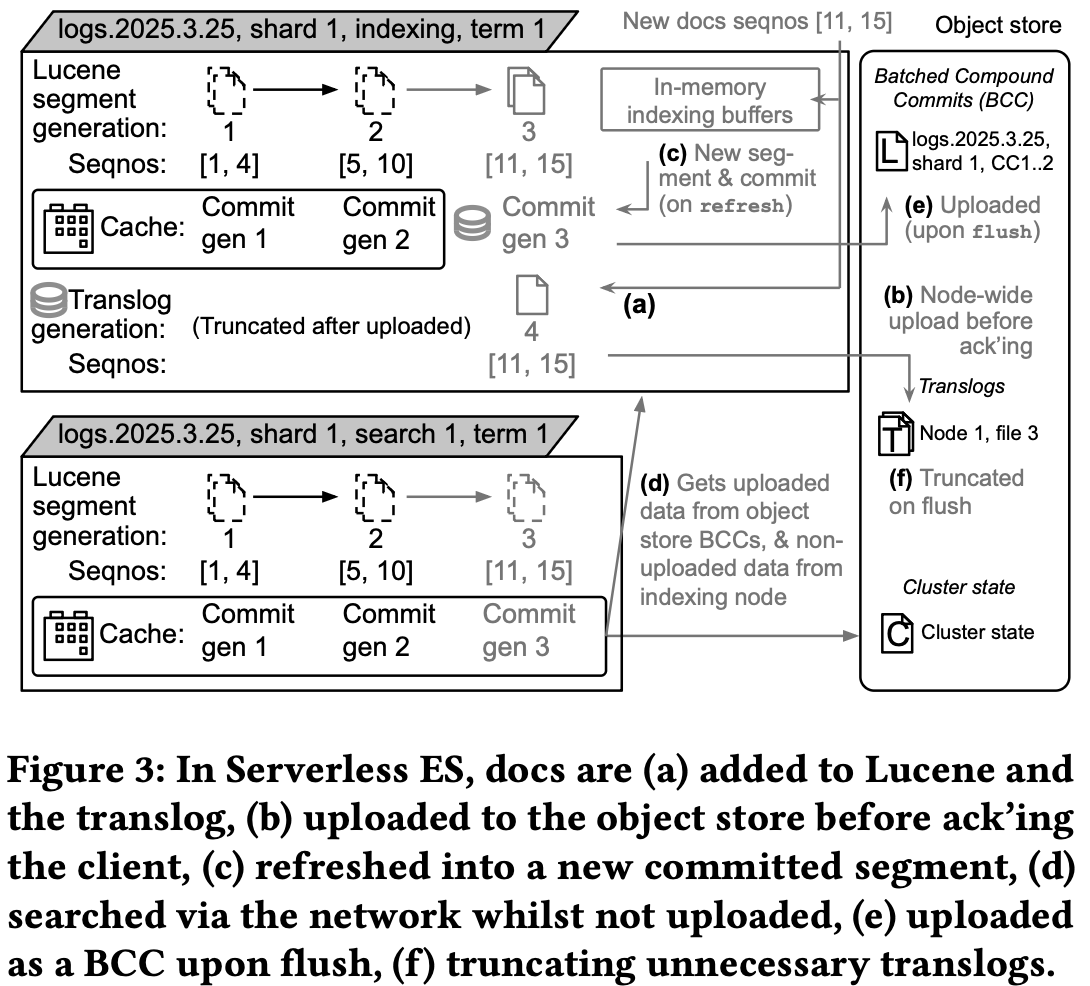
Result: The indexing and search paths are fully decoupled.
Autoscaling
Section 7 of the paper describes the autoscaler. Because data lives in the object store, relocating shards doesn't mean copying full segment data; only metadata and, when needed, cache warming. So the cluster can scale up and down much faster than in stateful Elasticsearch.
How it works:
The autoscaler is an external component that monitors metrics from Elasticsearch Serverless.
Indexing tier: Scale-up is driven by memory usage and ingestion load (including queued work).
Search tier: Scale-up is driven by memory, search load, and the user-configurable "search power" (how much of the dataset is cached locally).
It polls every few seconds and adjusts each tier independently.
Outcome: automatic, workload-driven scaling so clients can focus on their applications instead of on capacity planning.
The experimental results
Section 8 of the paper presents our experimental evaluation.
Microbenchmarks show the impact of batching: fewer object store operations for both commits and translogs, with some trade-offs.
Autoscaling experiments: As we increase the number of indexing clients, throughput scales linearly while P50 and P99 latency stay stable. A real-world example shows bulk response times improving and stabilizing as the indexing tier scales up with demand.
Head-to-head comparison of stateful Elasticsearch versus Elasticsearch Serverless:
Elasticsearch Serverless achieves roughly twice the indexing throughput of stateful Elasticsearch at the 50th percentile.
The gain comes largely from using the object store for durability instead of replicating every operation to replica shards.
Latency stays competitive.
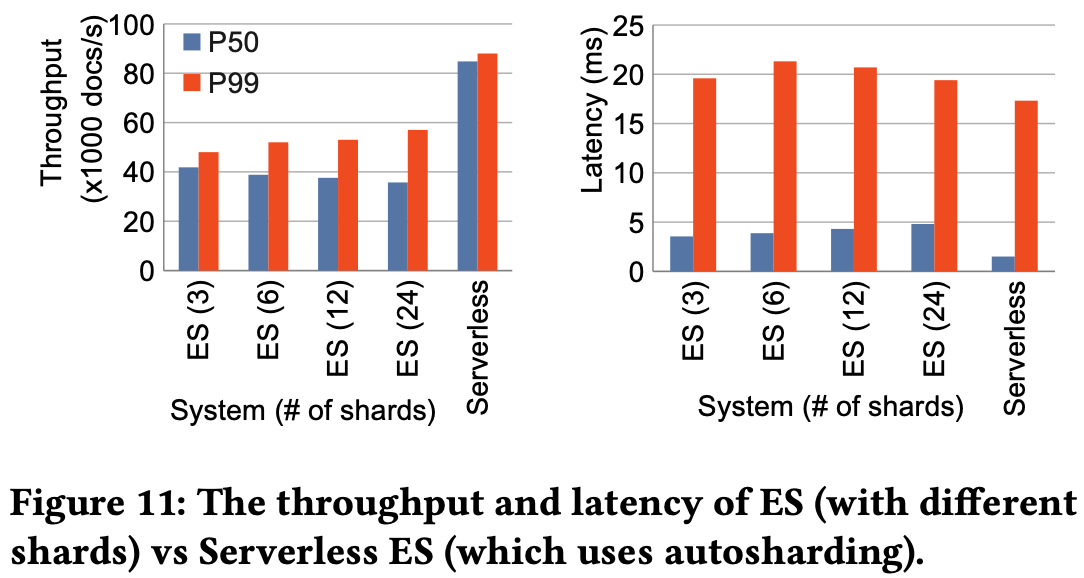
The takeaway: The stateless design delivers both better peak performance and more efficient, automatic scaling.
Why this matters for the future of Elastic
The stateless architecture isn't just a technical achievement; it's the foundation for how we want search to work in the cloud.
Pay-as-you-go: Customers can index and search over practically limitless data without provisioning clusters, tuning tiers, or managing replicas and snapshots.
Automatic scaling: Each tier scales on its own automatically; no capacity planning required.
Frequent, automated upgrades: Better security and time-to-value, without the operational cost of rolling upgrades over stateful data.
This work is a step toward making powerful search more accessible, cost-effective, and scalable for everyone.
Read the full paper, and join the conversation
We believe in the power of open research and collaboration to move technology forward. We encourage you to dive into the details. We provide a preprint of this paper for your information, which details in depth the architecture transformation.
Dive deeper: Explore related blog posts
While our paper offers a concise overview of the Elasticsearch Serverless architecture, the details and underlying innovations are explored more fully in a collection of in-depth blog posts written by our engineering team. These articles provide the background, nuance, and specific technical deep dives that make the stateless transformation possible.
We encourage you to delve into the following resources to gain a richer understanding of the components and concepts presented in the paper:
Stateless — your new state of find with Elasticsearch (2022) and Serve more with Serverless (2023). Read the foundational posts introducing the concept of decoupling storage and compute.
Stateless: Data safety in a stateless world (2024). Learn how data durability is achieved in the absence of local replicas.
Autosharding of data streams in Elasticsearch Serverless (2024). Discover the logic behind automatic and dynamic data stream sharding.
How we optimized refresh costs in Elasticsearch Serverless (2024). Understand the specific optimizations applied to reduce the cost of making data searchable.
Introducing Serverless Thin Indexing Shards (2024). Explore the innovation of "thin" shards that enable rapid relocation and recovery.
Search tier autoscaling in Elasticsearch Serverless (2024). Gain insight into the mechanisms driving the automatic scaling of search resources.
Ingest autoscaling in Elasticsearch (2024). Learn how the ingestion tier scales automatically to meet fluctuating indexing load.
Elastic Cloud Serverless pricing and packaging (2025). Learn how the pricing and packaging was initially structured for Elastic Cloud's Serverless offering.
Elasticsearch vs. OpenSearch: Unraveling the performance gap (2023). Learn about the performance differences and key optimizations that distinguish Elasticsearch from OpenSearch, as observed in 2023.
Acknowledgments
We would like to thank all the co-authors of the paper: Iraklis Psaroudakis, Pooya Salehi, Jason Bryan, Francisco Fernández Castaño, Brendan Cully, Ankita Kumar, Henning Andersen, and Thomas Repantis. We would also like to thank the Elasticsearch Distributed Systems team for their contributions, and also the entire Elasticsearch engineering team.