Free yourself from operations with Elastic Cloud Serverless. Scale automatically, handle load spikes, and focus on building—start a 14-day free trial to test it out yourself!
You can follow these guides to build an AI-Powered search experience or search across business systems and software.
With the introduction of cross-project search (CPS) in our Elastic Cloud Serverless offering, we wanted to provide our customers with a streamlined search experience. Our vision is for our users to not worry about which project the data is stored in but instead to focus on the information they want an answer for.
Users familiar with cross-cluster search (CCS) know that to include a remote cluster in a search you must specifically reference it with a cluster alias prefix, such as remote:metrics* (or *:metrics* to target all remotes). With CPS, "bare" index names or patterns such as metrics* in a search index expression implicitly reference all instances of that index that can be found on the origin project and on all of its linked projects.
In this post, we pull back the curtains on how the Elasticsearch TransportSearchAction, the code that underlies the _search API (and _async_search) APIs, determines which indices, aliases, and datastreams to search on which projects when running a cross-project search.
Analyzing index expressions
One important consequence of the new CPS model is that the Elasticsearch query parameters allow_no_indices and ignore_unavailable require different handling than before. In general, these parameters control whether a search should throw an error if a concrete index name (for example, "logs") cannot be found or isn’t accessible (ignore_unavailable=false), or a wildcard pattern (for example, "logs*") doesn’t match anything or if there are no indices at all to search (allow_no_indices=false).
In CCS, those parameters are analyzed on each cluster separately: Each cluster can just consult which indices, aliases, or data streams exist locally. But in CPS, we need to account for whether each resource (index, alias, or data stream) referenced by an index expression matches on any project (origin or linked), rather than every project.
To illustrate, suppose a user has one linked project (linked1) and they issue a cross-project query with index expression logs*,metrics-1, along with allow_no_indices=false,ignore_unavailable=false. As long as we find one resource (index, alias, or data stream) that matches logs* and one that matches metrics-1 on any project, then the search can proceed. If metrics-1, for example, is found on linked1 but not the origin project, that suffices to pass the ignore_unavailable=false constraint. Only if it’s found nowhere would we throw an IndexNotFoundException.
To handle this, the _search API in cross-project search mode needs to gather information from each linked project before kicking off the actual search.
The serverless node that receives the _search REST request is considered to be the origin project, and it acts as the overall search coordinator. To fully analyze and process an index expression before kicking off the actual search, the search coordinator needs to:
- Determine which projects are in scope for the search.
- Determine which indices, aliases, or data streams should be searched in each individual project.
- Do a final reconciliation step of all the information gathered: 1) Have we found all the indices required to proceed (as defined by the allow_no_indices and ignore_unavailable settings)?; and 2) Are there any projects that should be skipped since they have no matching indices?
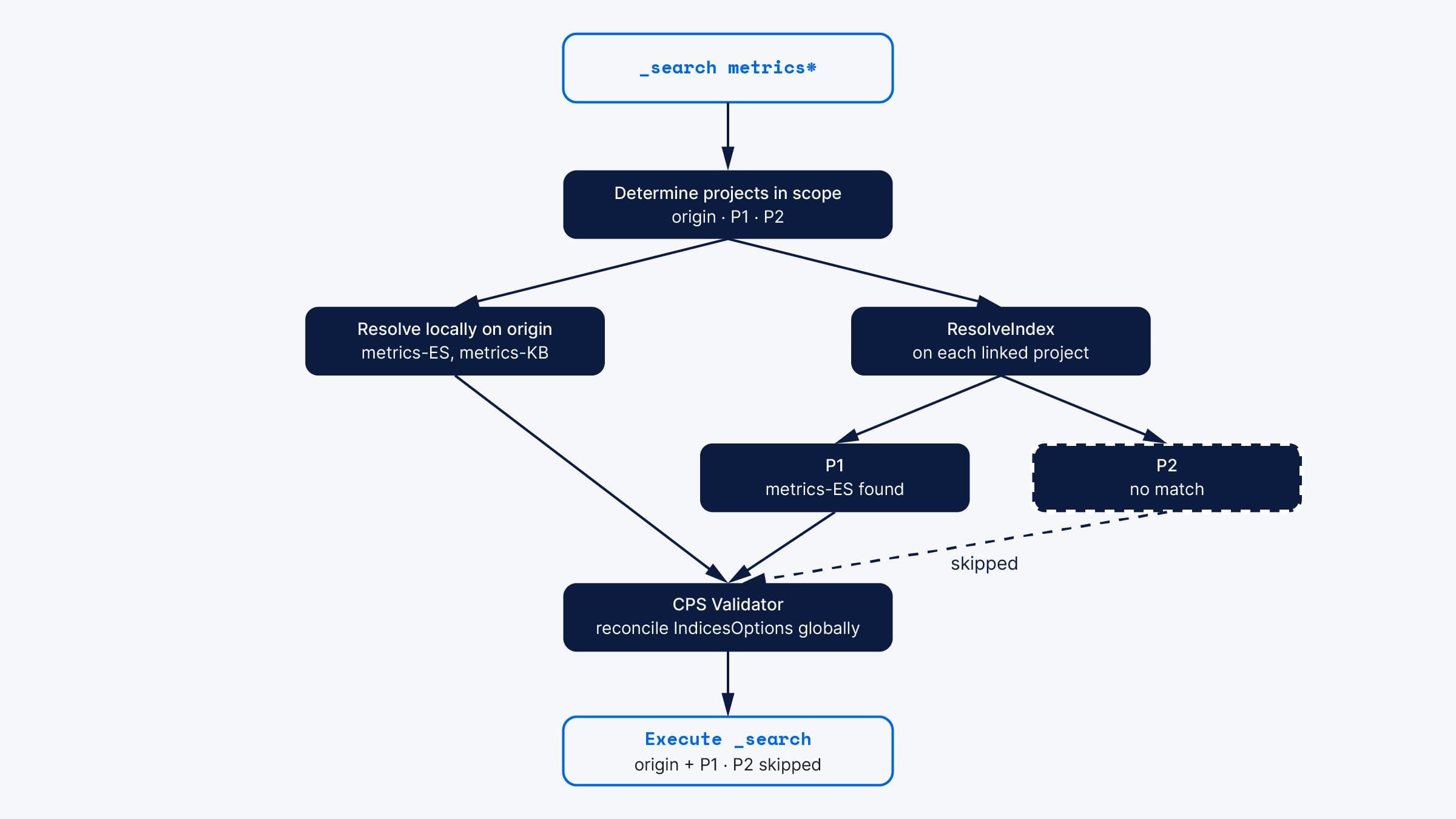
To illustrate, we’ll follow a CPS request against the _search API from start to finish. Suppose that the incoming user request is to search metrics* and that the origin project has two indices which match the expression, namely metrics-ES and metrics-KB, and that the origin project is linked to projects P1 and P2, where P1 has index metrics-ES and P2 has no index, alias, or data stream that matches metrics*.
Determining projects in scope
The search coordinator starts by grabbing the full list of linked projects from Elasticsearch cluster state. It then determines, based on Universal Identity and Access Management (UIAM) credentials provided with the query, which of those projects the user has access to and keeps the subset of projects that the user is allowed to access.
If a project_routing parameter is present on the request, that can further limit which projects are in scope for the query. For instance, "project_routing":"_alias:_origin" would cull the list to just the origin project, while "project_routing":"_alias:P*" would include the linked projects P1 and P2 and remove the origin project from the list of projects in scope for the query.
The index expression itself can also limit which projects to access. Qualified index expressions, like "P*:metrics*", would indicate that we should search only on projects whose alias starts with "P". For our case, the "bare" or unqualified index expression "metrics*" means "search on all projects that are in scope," where "in scope" is modified by security access and project_routing.
Determining which indices each project has
Once we know which projects to search, we need to determine which matching indices each one has. To support this, the search coordinator creates a ResolvedIndexExpressions data structure that allows tracking which indices on each project should be included in the search.
For each index expression provided by the user, that data structure tracks:
- Original expression: The index expression, as provided by the user.
- Local resolution: The local expressions that will replace the original together with the resolution result.
- Remote expressions: A set of remote expressions one for each project a query can target.
On the search coordinator that received the request, we’ve so far been able to determine which projects are in scope (origin, P1, and P2) and which, if any, matching indices exist on origin. So, for our example search against metrics*, we’ll have the following structure at that point in time:
- Original expression:
metrics*. - Local resolution:
SUCCESS,<metrics-ES, metrics-KB>. - Remote expressions:
<P1:metrics*, P2:metrics*>.
The remote expressions are left unresolved until we later contact the P1 and P2 projects to fill in that information.
The index resolution can be any of the following:
SUCCESS: Local resolution completed successfully.NOT_VISIBLE: Indicates that a non-wildcard expression was resolved to nothing, either because the index doesn’t exist or is closed.UNAUTHORIZED: Indicates that the expression could be resolved to a concrete index, but the requesting user isn’t authorized to access it.NONE: No local resolution was attempted, typically because the expression is remote-only (for example,P1:index).
Check indices on the linked projects
In the search API, how we check for indices on the linked projects depends on whether the cross-project search is being run with minimize round trips or not. Most searches in CPS are set internally to run with minimize_roundtrips=true, so we’ll focus on that pathway.
In CCS, where index expression analysis is done locally on each cluster, we just send the same request to every cluster and, with minimize_roundtrips=true, each remote cluster sends back an entire SearchResponse that the primary search coordinator collects and eventually merges into all the other responses it receives.
By contrast, for CPS, an additional phase was introduced to search where we contact each linked project to assess which indices are present and which ones the user has access to. This is an additional round trip that uses ResolveIndexAction, the class that implements the functionality of the _resolve/index endpoint. Upon receiving the ResolveIndex responses from all the linked projects, we can fill in the ResolvedIndexExpressions data structure on the primary search coordinator. For this case, since P1 has index metrics-ES and P2 has no matching indices, the updated data structure would be:
- Original expression:
metrics*. - Local resolution:
SUCCESS,<metrics-ES, metrics-KB>. - Remote expressions:
<P1: SUCCESS <metrics-ES>, P2: NOT_VISIBLE>.
CPS validator
Once we have all the linked project information, we can run the validation to honor the IndicesOptions specified by the caller.
If the user had specified a qualified index expression (for example, original=P1:metrics*), the CPS validator needs to make sure that project P1 has at least one index matching metrics*, otherwise a 404 index not found exception would be returned to the user. In other words, qualified expressions imply that an index, alias, or data stream matching that name must be present on all projects specified by the qualifier.
On the other hand, for “bare” (unqualified) CPS index expressions (for example, original=metrics*), we only need to check whether the original index expression exists anywhere.
For the example we’re following in this post, the ResolveIndexExpressions show that at least one index, alias, or data stream matching metrics* was found, so the search can proceed.
However, we can also see that the P2 cluster has no matching indices. In that case, we can remove it from the rest of the query. So now, for the actual query, we’ll:
- On the origin project, search
metrics-ES, metrics-KB. - On the
P1project, searchmetrics-ES. - Skip the
P2project. Note: Since it wasn’t included in the query at all, it won’t show up on the _cluster/details of the SearchResponse.
Conclusions
We’ve described how the TransportSearchAction class in Elasticsearch supports some key new features of cross-project search. That class supports a large number of Elasticsearch REST APIs, such as, _search, _async_search, _msearch, _eql, _sql and _count, all of which use the mechanisms described in this document.
Related Content

July 9, 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.

July 7, 2026
Your compliance posture just got an upgrade: Elasticsearch now supports FIPS 140-3
Elastic 9.4 brings FIPS 140-3 support for Elasticsearch and Kibana to GA. Here's what changes for federal, defense and regulated deployments, and how to migrate from 140-2.

July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

June 29, 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.

June 11, 2026
How Elasticsearch cut metrics storage by 41% by dropping sequence numbers after replication
Find out how Elasticsearch trims sequence numbers at merge time to cut TSDS storage by 41%, what you give up, and why it's safe for metrics workloads.