Free yourself from operations with Elastic Cloud Serverless. Scale automatically, handle load spikes, and focus on building—start a 14-day free trial to test it out yourself!
You can follow these guides to build an AI-Powered search experience or search across business systems and software.
In this article we present Elasticsearch's thin indexing shards, a new type of shard we developed for Elastic Cloud Serverless that allows storing Elasticsearch indices in a cloud object store.
We'll start by recalling how Elasticsearch stores and replicates data today before diving into the changes introduced by thin indexing shards to store data remotely. We will see that thin indexing shards got their name from the fact that they manage the lifecycle of data files from their creation on local disks to their upload in the object store and their final deletion from disk, increasing disk space only temporarily. We'll then describe how files are read once persisted in the object store and how we mitigated the high latency of cloud storage services by using a block based cache. Finally, we'll say a word on our future plan to improve them.
How stateful Elasticsearch stores and replicates data on local disks
Elasticsearch manages two main types of data:
- The cluster state, which is an internal data structure containing a variety of information needed by Elasticsearch instances to operate correctly. It typically contains the identity and attributes of the other nodes in the cluster, the current state of running tasks, the cluster-wide settings, the indices metadata with their mappings etc.
- The indices, which contain users' business data in the form of documents that are indexed by Elasticsearch so that they can be searched or aggregated.
This article focuses on indices, where documents are stored. Indices represent the largest part of the total volume of data stored in an Elasticsearch cluster, which can be composed of many indices on multiple nodes. Indices are divided into shards, called the primaries, to distribute the volume of documents as well as the search and indexing loads across nodes. Primary shards can also have copies called replicas: when a document is indexed in a primary shard, it is also indexed in its replicas to ensure that the data is safely persisted in multiple places. That way, if a shard is lost or becomes corrupted for whatever reason there will be another copy to recover from. Note that the cluster state is also persisted accross a subset of nodes (which are identified by a specific master-eligible node role) on the local disk.

We describe this model as a "node-to-node" replication model, where each node is "stateful" in that they rely on their local disks to safely and durably persist the data for the shards they host. In this model, stateful Elasticsearch instances always have to communicate to keep the primary and replica shards in sync. This is achieved by replicating the write operations (new document indexed, updated or deleted) from the primary shard to the replica shards. Once replicated and durably persisted, the operation is acknowledged back to the client application:

While this stateful architecture serves us well, replicating every operation has a non-neglictable cost in term of resources. CPUs are necessary on primary shard nodes as well as on replica shards nodes to ingest documents. Network is involved to transport operations from one node to another, and that can be costly at scale when nodes are located in different availability zones. Finally, storage is required for persisting data on multiple disks.
In Elastic Cloud Serverless, we leveraged the benefits of using a cloud storage service to implement a new stateless model for Elasticsearch.
What changes in stateless?
We implemented two major changes in stateless Elasticsearch:
- We shifted the persistence of shard data from the local disk to an object store;
- We changed the replication model from replicating operations between nodes to replicating shard files through the object store.
When combined, those two changes bring some interesting improvements. Shifting the persistence of shards from the disk to an object store basically means that shard files remain only temporary on disk: soon after being created, files are uploaded to the object store and deleted from the local disks. If a file must be read again, it is retrieved from the object store and stored locally in a block-based cache for future reads. Once the files are durably persisted in the object store, all nodes can access them. There is no need to maintain shard copies on several nodes anymore nor to replicate operations, therefore we can greatly simplify our replication model.
Index & search tiers
In order to avoid confusion between the existing model and the new stateless model, we have introduced some new terminology:
- A shard in charge of indexing documents and uploading shard files to the object store is called an indexing shard and is automatically allocated to nodes from the Index Tier. Because those shards do not require storing the full data set locally on indexing nodes, we called them thin indexing shards.
- A shard in charge of searching documents is simply called a search shard. Those shards are allocated on nodes in the Search Tier.
Let's illustrate the difference between the existing stateful model and the new stateless model:
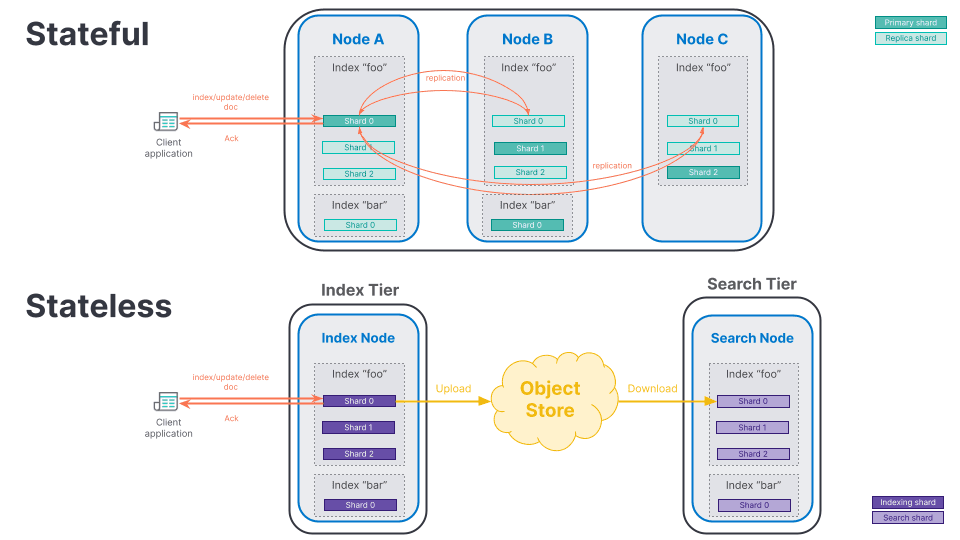
Benefits
The new stateless model has many benefits. By removing the replication of write operations, we can save hardware resources like CPU, network and disk. Those resources can now be dedicated to ingest more data, or seen differently, the same amount of data can be ingested with less resources. Persisting data in a single, highly available place allows to scale each tier independently. Adding more indexing or search nodes to a tier won’t be dictated by local disk performance or inter-node network performance. And the cost of object stores, usually cheaper than fast local SSD disks, can help reduce the overall cost of running Elasticsearch instances.
Now we have seen an overall picture of the stateless architecture, let's dive into the implementation details.
From local disks to cloud storage
Indexing documents in an Elasticsearch index involves multiple steps. The document may be ingested through an ingest pipeline that transforms or enriches the document before being routed to one of the primary shards of the index. There the source of the document is parsed and any version conflict is resolved. The document is then indexed into the primary and forwarded to the replica shards where it is also indexed. If all of those operations succeed, the indexing operation is acknowledged back to the client application.
When a document is indexed into a shard, it is in reality indexed in two different places: first in Lucene and then in a translog.
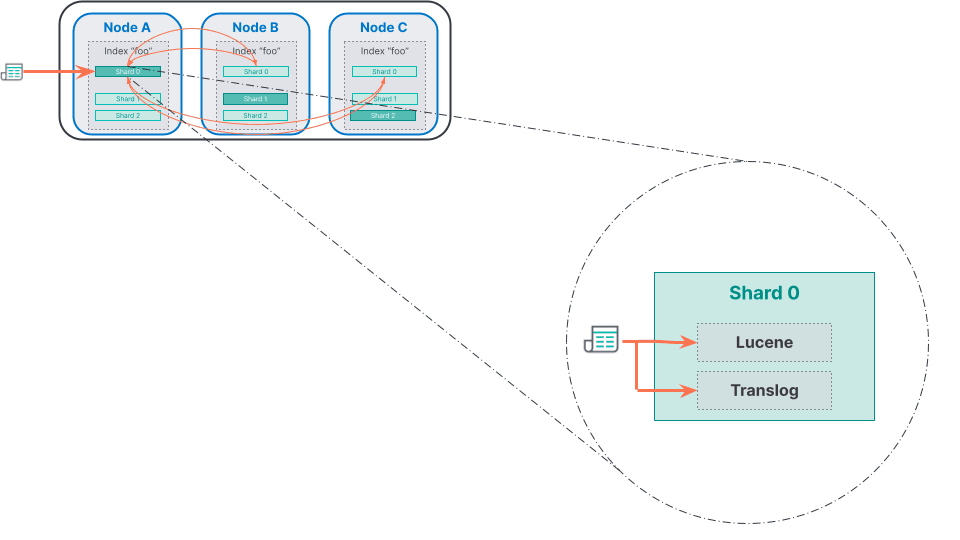
Lucene is used by Elasticsearch to index and to search documents. Every time a document is indexed into Lucene, Lucene analyzes the document in order to build various internal data structures whose types depend on the search queries we plan to execute later on the docs. In order to keep indexing fast, the data structures are kept in memory in Lucene indexing buffers. When enough data has been indexed into memory, Lucene flushes its memory buffers to write the data structures on disk, creating a set of immutable files that is called a segment. Once the segment is written on disk the subset of indexed documents it contains can become searchable. Note that Elasticsearch automatically makes newly indexed documents searchable by flushing Lucene buffers and opening new segments every second: we call this a refresh in Elasticsearch terminology.
The fact that Lucene segments files never change after being created makes them very cache friendly: the operating system can map files (or part of files) directly in memory for faster access. We'll see later that this immutability also simplifies the block-based implementation we use in thin indexing shards. Immutable segment files also implies that updates and deletions of documents create new segments, in which the previous version of the document is soft deleted and a new version potentially added. Over time, Lucene takes care of merging small segments into single, more optimized ones in order to maintain a Lucene index that is efficient to search and to reclaim unused space left behind by updated/deleted documents.

In a shard where documents are actively being indexed, segments are continously created and merged and small segments remain on disk only for a short period of time. For this reason, Lucene does not instruct the operating system to ensure that the bytes of files are durably written to the storage device. Instead the files can remain in the operating system's filesystem cache, located in memory, where they can be accessed much faster than on disk. As a consequence, if the node hosting the shard were to crash the segments files would be lost.
In order to safely persist segments files on disk, Elasticsearch makes sure to periodically create a Lucene commit, a relatively expensive operation that cannot be performed after every index or delete operation. To be able to recover operations that have been acknowledged but are not part of a commit yet, each shard writes operations into a transaction log called the translog. In the event of a crash, operations can be replayed from the translog.

In order to make sure the translog does not grow too large, Elasticsearch automatically performs a Lucene commit and creates a new empty translog file. This process is called a flush in Elasticsearch terminology and is performed in the background.

What changes in stateless?
In the previous sections we described the logic of indexing documents in stateful Elasticsearch. This logic remains almost the same in stateless, with the difference that the durability guarantee provided by persisting files on disk has been replaced by uploading files to the object store.
Lucene commit files
For Lucene, indexing documents and refreshing indices continue to produces segments files on the local disk. When the shard is flushed, the Lucene commit files (ie, all the segments files included in the commit plus the additional commit point file) are uploaded to the object store by the thin indexing shard. In order to reduce the number of writes to the object store, which are much more costly than reads, Lucene commit files are concatenated together into a single blob during upload. This blob object is composed of a header that contains information about the shard and the commit, along with the full list of files that are included in the commit. This list references the name, size and location where each file can be found. This location is important, as some file can have been created by a previous commit and therefore is located in a different blob on the object store. After the header, the new files added by the commit are simply appended to the blob.
Packing multiple files in the same blob helps reducing the cost induced by PUT requests, but it also helps reducing the time required to upload a commit: requests to object stores usually have a high latency (in the range of 130 milliseconds for the 99th percentile) but can deliver a high read/write throughput. By concatenating files in the same blob object, we pay latency only once for multiple files and we can to upload or download them fast enough. Note that in order to reduce the cost of refreshes, we are also uploading more than one commit into a single blob. If you're interested to know more about this topic we recently wrote an article on this.
Once uploaded, Lucene commit files can be deleted from the local disk. If we compare the total size of a shard (uploaded in the object store) with the size it really takes on the local disk, we can see that only a portion of the shard is necessary for indexing. And once indexing is reduced or stopped, this size drops to zero:
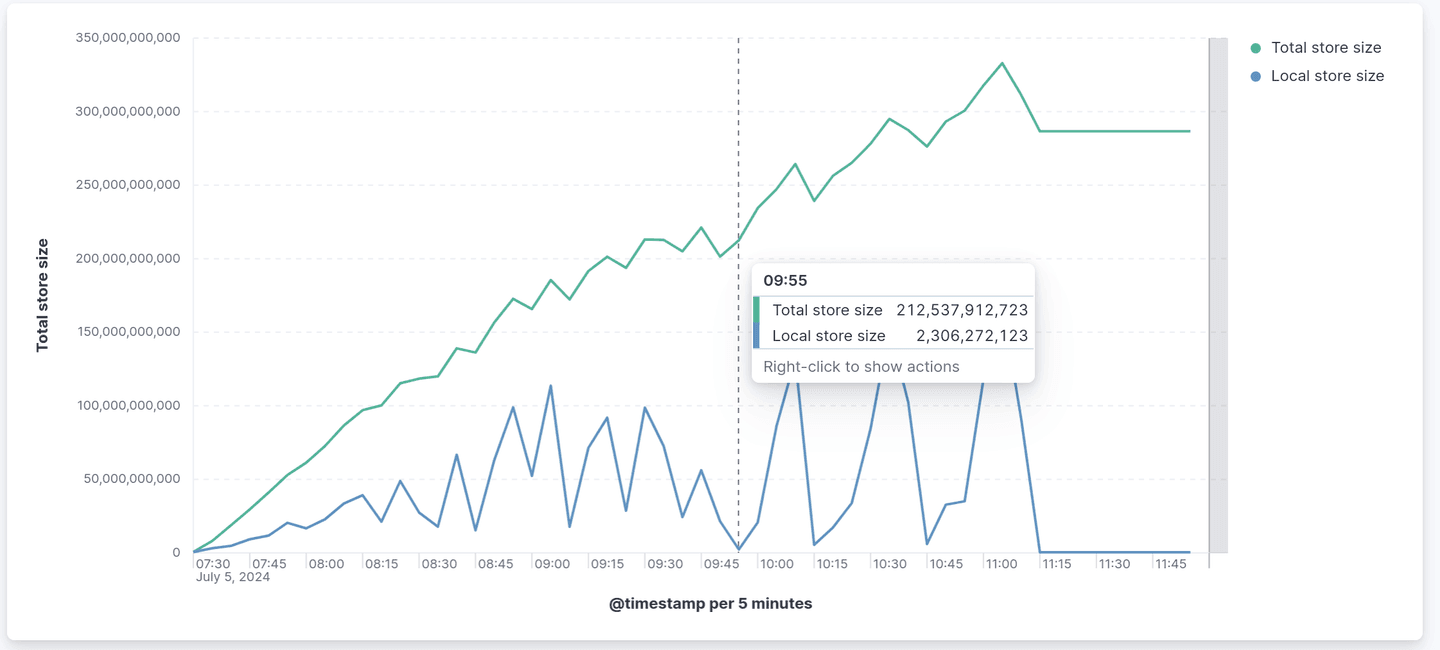
Translog uploaded every 200ms
For the translog, it's a different story. It is not possible to upload the translog file after every operation of every shard: the cost of the upload requests would be prohibitive and the high latency incurred by using an object store would dramatically degrade the indexing performance. Instead in stateless we decided to upload the translog every 200 milliseconds or once it reaches 16MiB, whichever comes first, and we also decided to concatenate translog files of all shards on the same node into a single node translog file.

Blob Cache: Accessing files after upload
Once Lucene and translog files have been uploaded they are deleted from disk. But indexing documents may require reading some files again: to look up a document id, the value of a field in a document, or to load the existing source to apply an update script. In such cases, the thin indexing shard would need to fetch the required files (or a portion of them) from the object store. But the high latency and the cost of object store API requests prevent Elasticsearch to read the necessary bytes from the object store every time. Instead, we implemented a block-based cache in front of the object store to cache blob chunks. This way, when Lucene needs to read some bytes from a file the cache fetches the corresponding chunk of data from the object store (usually a 16MiB chunk) and stores it locally on disk for future reads. For better performance, thin indexing shards prewarm the cache when uploading blobs so that relevant parts of the commit files are already cached at the time the shard transition from local files to the corresponding uploaded blob.
This blob cache has been inspired by Searchable Snapshots and uses a LFU algorithm to evict less frequently used blob chunks. It can store around 50 GiB of data on smallest serverless nodes.
Faster shards recoveries
A shard recovery is the process of rebuilding a shard on an Elasticsearch node. This recovery is executed when an empty shard is created for a new index, when a shard needs to be relocated from a node to another node or when a shard need to recover from object store. On stateless, relocating a shard does not require to fully copy all segments files between nodes. Instead, Elasticsearch fetches the only necessary blob chunks from the object store, using the cache, to allow the shard to be started. It usually represents a fraction of the total size of the shard and allows shard to start faster.
Conclusion and future improvements
In this article we have presented how we change the primary storage from local disk to the object store. We utilize thin indexing shards, partially caching data locally to save local storage costs without impact on throughput. We saw all the gains in terms of hardware resources and overall cost this brings to our users.
While we drastically reduced the disk space required for indexing documents, we are now looking at improving the memory used by thin indexing shards. Today each indexing shard requires a few MiB of memory to store index settings, mappings and Lucene data structures. In a short future, we’d like thin indexing shards to require almost no memory when no active indexing is being executed, and rehydrate objects on demand once indexing is needed. We are also thinking about improving the blob cache. The algorithm we use works well for most use cases, but we are thinking of exploring alternatives. Finally, we are making contributions to Lucene to allow more parallelization when fetching bytes from the object store.
Frequently Asked Questions
What is thin indexing shards in Elasticsearch?
Elasticsearch's thin indexing shards is a type of shard we developed for Elastic Cloud Serverless that allows storing Elasticsearch indices in a cloud object store.
Related Content
June 11, 2026
Replica management: Inside the system that keeps Elasticsearch Serverless searches fast at scale
A technical walkthrough of how two replica systems (one for failover, one for load balancing) combine every five minutes into a single cache-aware recommendation per index in Elasticsearch Serverless.
June 5, 2026
Your Elastic agent, Google's ADK, and zero custom APIs: building “Lucky Planet” over A2A
Elastic Agent Builder's native A2A endpoint lets Google's ADK orchestrate a remote agent, with no custom REST API. Watch it work in 'Lucky Planet,' a random-exoplanet game built end-to-end.

June 2, 2026
Elasticsearch reindex now relocates across nodes automatically: zero user intervention, no lost progress
Elasticsearch reindex now survives node shutdowns, uses Point in Time for more efficient source iteration, and ships with dedicated management APIs. Reindex-from-remote is GA in Serverless.
May 18, 2026
One query, multiple Elasticsearch Serverless projects: introducing cross-project search
Cross-project search in Elastic Cloud Serverless lets you query data across isolated projects in a single Elasticsearch or ES|QL request: no duplication, no network peering, and no egress costs from copying logs.

May 15, 2026
Faster cross-project search in Elasticsearch Serverless with project tags and routing
Scope cross-project search in Elasticsearch Serverless with project routing to skip non-matching projects entirely, or with project tag fields to filter, aggregate, and sort by tag inside the query.