Kubernetes-Observability-Tutorial: Überwachen und Analysieren von Logdaten
Kubernetes hat sich zum De-facto-Standard auf dem Gebiet der Containerorchestrierung entwickelt und ist für die Cloud-Native-Bewegung nicht mehr wegzudenken. Cloud Native sorgt für Tempo, Elastizität und Agilität in der Softwareentwicklung, erhöht aber auch die Komplexität – Hunderte von Microservices auf Tausenden (oder Millionen) von Containern, die in kurzlebigen und nur für den einmaligen Einsatz bestimmten Pods laufen. Das Monitoring eines so komplexen, verteilten und transienten Systems ist alles andere als einfach, aber auch absolut notwendig. Zum Glück ist es mit Elastic ganz einfach, Ihre Kubernetes-Umgebung mit Observability-Funktionen auszustatten.
In dieser Observability-Tutorial-Reihe für Kubernetes zeigen wir Ihnen, wie Sie alle Aspekte der in Kubernetes laufenden Anwendungen überwachen können. Sie besteht aus den folgenden drei Teilen:
- Ingestieren und Analysieren von Logdaten
- Erfassen von Performance- und Zustandsmetriken
- Monitoring der Anwendungsperformance mit Elastic APM
Am Ende dieses Tutorials steht ein Arbeitsbeispiel einer Anwendung, die alle ihre Observability-Daten zur Überwachung und Analyse an den Elastic Stack sendet.
Was spricht dafür, Elastic Observability für Kubernetes einzusetzen?
Observability ruht auf drei Datensäulen: Logdaten, Metriken und APM-Traces. Es gibt eine Menge an Artikeln, in denen beschrieben wird, wie sich durch Kombinieren von drei bis sechs unterschiedlichen Tools, Anbietern und Technologien in Frankenstein-Manier eine „Best-of-breed“-Monitoring-Lösung für Kubernetes zusammenbasteln lässt …
Keine Angst – es geht auch anders. Elastic Observability kombiniert Ihre Logdaten, Metriken und APM-Traces mit nur einem Tool so, dass sie für das Aufrufen und Analysieren an einem zentralen Ort bereitstehen. Auf diese Weise können Sie Fehler beheben, die sich in nutzerseitigen Latenzanomalien in APM-Daten zeigen (entdeckt durch Machine Learning), Metriken für einen konkreten Kubernetes-Pod aufrufen, sich die von diesem Pod generierten Logdaten anschauen und sie mit Metriken und Logdaten in Beziehung setzen, die die Ereignisse auf dem Host und im Netzwerk beschreiben – alles über dieselbe Benutzeroberfläche. So geht Observability!
Und während das Ganze für den Nutzer so einfach aussieht, passiert im Hintergrund jede Menge, denn …
Kubernetes-Logdateien sind sich bewegende Ziele
Kubernetes sorgt für Orchestrierung, indem Container in verfügbaren Hosts bereitgestellt werden. Auf diese Weise werden die Anwendungskomponenten nativ über verschiedene Hosts verteilt, sodass man vorab nie weiß, wo die Komponente landen wird.
Container in Kubernetes-Pods geben Logdaten als stdout (Standardausgabe) oder stderr (Standardfehler) aus. Diese Logdaten werden in einem sogenannten „Kubelet“ unter einem Dateinamen gespeichert, der sich nach der Pod-ID richtet. Damit diese Logdaten mit der Komponente oder dem Pod verknüpft werden, die bzw. der sie produziert hat, muss der Nutzer herausfinden, welche Komponenten-Pods auf dem aktuellen Host ausgeführt werden und wie deren IDs lauten.
Hinzu kommt, dass Kubernetes in der Lage ist, die Anwendung nach eigenem Ermessen zu skalieren, sodass sich die Zahl der Pods ändern kann, die die Anwendungskomponente repräsentieren.
Filebeat mag zum Glück sich bewegende Ziele
Alles, was wir zum Erfassen von Pod-Logdaten benötigen, ist Filebeat, ausgeführt als DaemonSet in unserem Kubernetes-Cluster. Filebeat kann so konfiguriert werden, dass es mit der lokalen Kubelet-API kommuniziert, die Liste der auf dem aktuellen Host ausgeführten Pods abruft und die Logdaten erfasst, die von den Pods ausgegeben werden. Diese Logdaten werden mit allen relevanten Kubernetes-Metadaten angereichert, wie der Pod-ID, dem Containernamen, Container-Labels, Annotationen usw.
Anhand dieser Informationen ermittelt Filebeat, was für Komponenten im Pod laufen. Es kann dann entscheiden, welches Logging-Modul für die zu verarbeitenden Logdaten verwendet werden soll. Guck mal, Mama, ganz ohne Hände! Das Ingestieren von Kubernetes-Logdaten mit Filebeat ist ein Kinderspiel. Wir legen auch gleich los, aber vorher gibt es hier noch einen wichtigen Hinweis:
| Bevor es losgeht: Das folgende Tutorial setzt das Vorhandensein einer bestimmten Kubernetes-Umgebung voraus. Lesen Sie dazu unseren ergänzenden Blogpost, in dem wir die Schritte zur Einrichtung einer Einzelknoten-Minikube-Umgebung mit einer Demo-Anwendung beschreiben. Diese Umgebung benötigen Sie, um die weiteren Aktivitäten nachvollziehen zu können. |
Erfassen von Kubernetes-Logdaten mit Filebeat
Wir verwenden hier Elasticsearch Service auf Elastic Cloud. Aber alles, was hier beschrieben wird, geht auch mit Elastic-Clustern, die Sie auf Ihrer eigenen Infrastruktur bereitgestellt haben, gleich, ob Sie sie selbst verwalten oder Orchestrierungssysteme wie Elastic Cloud Enterprise (ECE) oder Elastic Cloud auf Kubernetes (ECK) verwenden. Der in diesem Tutorial verwendete Code steht im folgenden GitHub-Repo bereit: http://github.com/michaelhyatt/k8s-o11y-workshop.
Bereitstellen von Filebeat als DaemonSet
Pro Kubernetes-Host sollte nur eine Instanz bereitgestellt werden. Nach der Bereitstellung kommuniziert Filebeat mit dem Host über die Kubelet-API, um Informationen über die auf dem Host ausgeführten Pods, sämtliche Metadaten-Annotationen sowie den Speicherort der Logdateien abzurufen.
Die Deployment-Konfiguration des DaemonSet ist in der Datei $HOME/k8s-o11y-workshop/filebeat/filebeat.yml definiert. Sehen wir uns einmal den Deployment-Descriptor-Teil, der die Filebeat-Konfiguration repräsentiert, etwas näher an.
Dieser Teil erhöht die Gesamtzahl der möglichen Felder von den standardmäßig zur Verfügung stehenden 1000 auf 5000. Kubernetes-Deployments können mit einer großen Zahl von Labels und Annotationen verknüpft sein, sodass die standardmäßigen 1000 Felder möglicherweise nicht ausreichen.
setup.template.settings:
index.mapping.total_fields.limit: 5000
Die Einstellungen für den Autodiscovery-Mechanismus weisen Filebeat an, die Kubernetes-Autodiscovery zu verwenden und auf die Hint-gestützte Autodiscovery für Annotationen zurückzugreifen:
filebeat.autodiscover:
providers:
- type: kubernetes
host: ${NODE_NAME}
hints.enabled: true
Die nächste Sitzung definiert die Prozessorkette, die für alle Logdaten gelten soll, die von dieser Filebeat-Instanz erfasst werden. Zunächst wird das Ereignis mit den aus Docker, aus Kubernetes, vom Host und von den Cloudanbietern stammenden Metadaten angereichert. Dann gibt es einen Abschnitt namens drop_event, der Meldungen anhand ihres Inhalts und einiger der von den vorangegangenen Prozessoren erstellten Metadatenfelder filtert. Dies ist hilfreich, wenn die Logdaten anhaltend von einem Ereignistyp mit starkem Rauschen dominiert werden. Zur Definition der Filterbedingung kommen die logischen Operatoren and und or zum Einsatz.
processors:
- add_cloud_metadata:
- add_host_metadata:
- add_docker_metadata:
- add_kubernetes_metadata:
- drop_event:
when:
or:
- contains:
message: "OpenAPI AggregationController: Processing item k8s_internal_local_delegation_chain"
- and:
- equals:
kubernetes.container.name: "metricbeat"
- contains:
message: "INFO"
- contains:
message: "Non-zero metrics in the last"
- and:
- equals:
kubernetes.container.name: "packetbeat"
- contains:
message: "INFO"
- contains:
message: "Non-zero metrics in the last"
- contains:
message: "get services heapster"
- contains:
kubernetes.container.name: "kube-addon-manager"
- contains:
kubernetes.container.name: "dashboard-metrics-scraper"
Filebeat-Module und Autodiscovery mit Annotationen
Wir haben oben gesehen, wie Autodiscovery dafür sorgt, dass das passende Modul auf stdout/stderr angewendet wird, um das Parsen als modulspezifisches Format zu ermöglichen. Wenn Sie mehr über Autodiscovery erfahren möchten, lesen Sie den entsprechenden Abschnitt in der Filebeat-Dokumentation.
Jetzt sehen wir uns, wie die unterschiedlichen Komponenten in unserer Beispielanwendung so konfiguriert werden können, dass sie mit der Hint-gestützten Autodiscovery in Kubernetes zusammenarbeiten.
NGINX-Beispiel
Das folgende Code-Snippet aus $HOME/k8s-o11y-workshop/nginx/nginx.yml weist Filebeat an, die Logdaten aus diesem Pod als NGINX-Logdaten zu behandeln, wobei stdout für das Zugriffslog und stderr für das Fehlerlog steht:
annotations:
co.elastic.logs/module: nginx
co.elastic.logs/fileset.stdout: access
co.elastic.logs/fileset.stderr: error
Verarbeitung mehrzeiliger Anwendungslogdaten
Als ein weiteres Beispiel für eine Hint-gestützte Autodiscovery kann Filebeat so konfiguriert werden, dass es mehrzeilige Petclinic-Logeinträge als jeweils ein Logereignis behandelt. Das ist dann hilfreich, wenn Komponenten mehrzeilige Meldungen hinterlassen, wie das zum Beispiel bei Java-Stack-Traces der Fall ist, die ein einzelnes Ereignis repräsentieren, standardmäßig aber als ein Ereignis pro Zeile mit dem Zeilenendezeichen als Trennzeichen behandelt werden.
Das folgende Snippet aus $HOME/k8s-o11y-workshop/petclinic/petclinic.yml steht für eine Konfiguration mit Behandlung mehrzeiliger Ereignisse, die dank Hint-gestützter Autodiscovery von Filebeat erkannt wird:
annotations:
co.elastic.logs/multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
co.elastic.logs/multiline.negate: "true"
co.elastic.logs/multiline.match: "after"
Weitere Informationen zur Verarbeitung von mehrzeiligen Logereignissen
Analysieren von Kubernetes-Logdaten im Elastic Stack
Nachdem die Logdaten in Elasticsearch ingestiert wurden, ist es jetzt an der Zeit, sie sinnvoll zu nutzen.
Verwenden der App Logs in Kibana
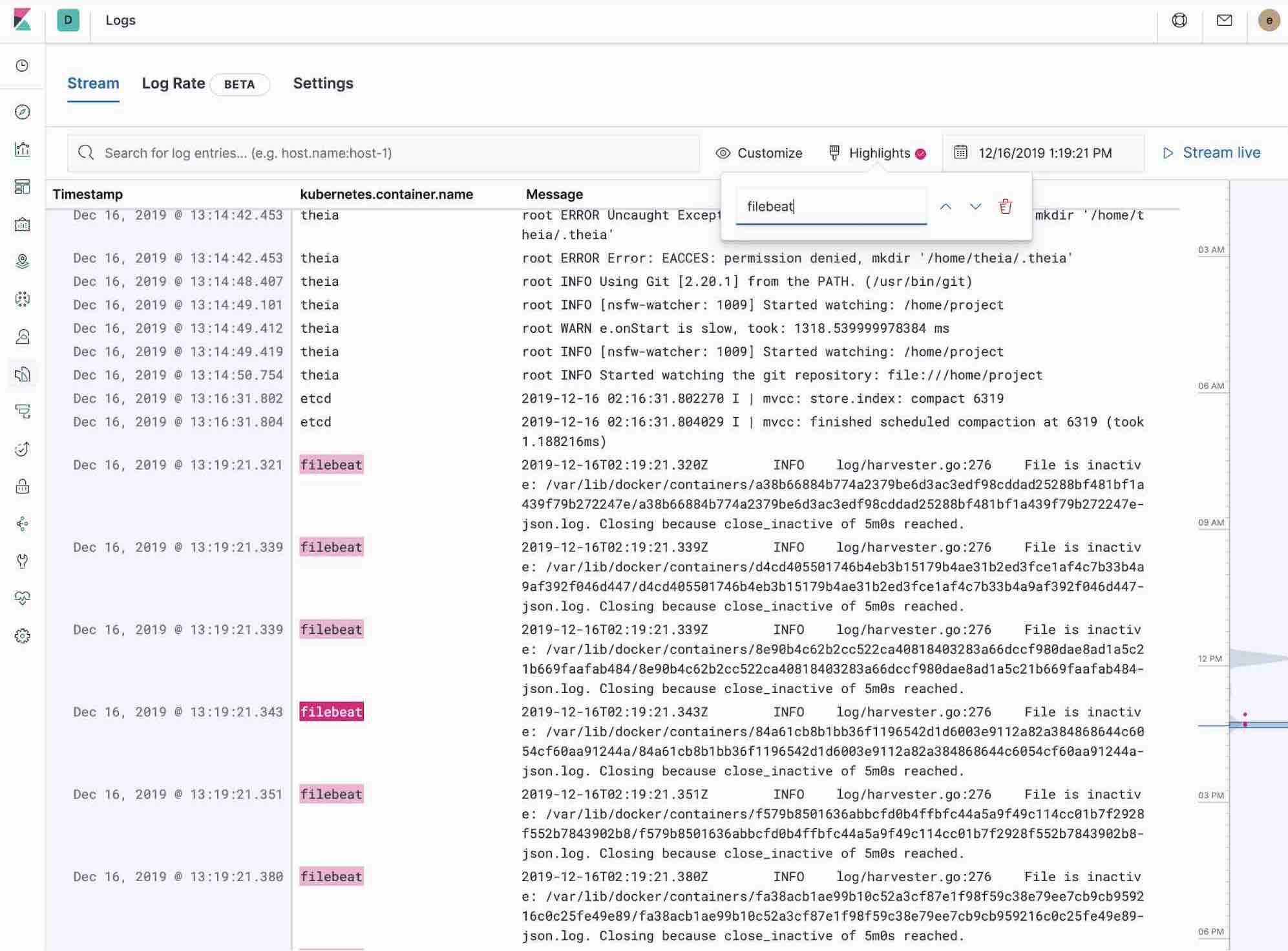
Die App Logs in Kibana ermöglicht das Durchsuchen, Filtern und Tailen der im Elastic Stack zusammengefassten Logdaten. Statt sich mit SSH bei verschiedenen Servern anmelden, per „cd“ ins entsprechende Verzeichnis wechseln und die Dateien einzeln tailen zu müssen, stehen dem Nutzer alle Logdaten in einem Tool zur Verfügung – der App Logs.
- Nutzen Sie die Möglichkeiten zum Filtern von Logdaten mithilfe der Keyword- oder Nur-Text-Suche.
- Mit dem Zeitfilter oder der Zeitstempelansicht links können Sie ganz einfach auswählen, welche Logdaten Sie sehen möchten.
- Wenn Sie nur die aktuellen Logdatenaktualisierungen à la tail -f beobachten möchten, klicken Sie auf die Schaltfläche Streaming und heben Sie mithilfe der Funktion „Highlights“ den Teil der Informationen hervor, den Sie sehen möchten.
Integrierte Kibana-Visualisierungen
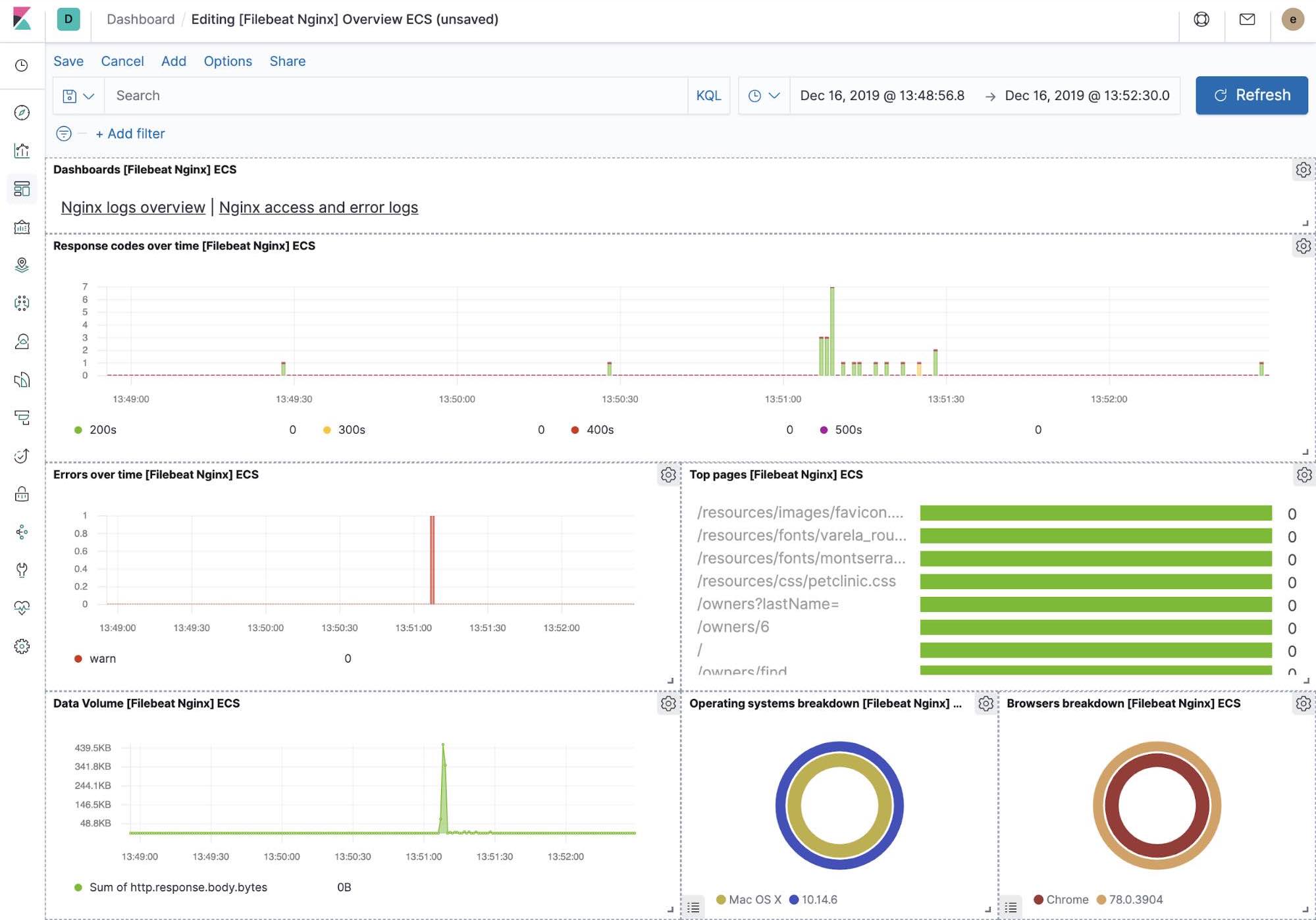
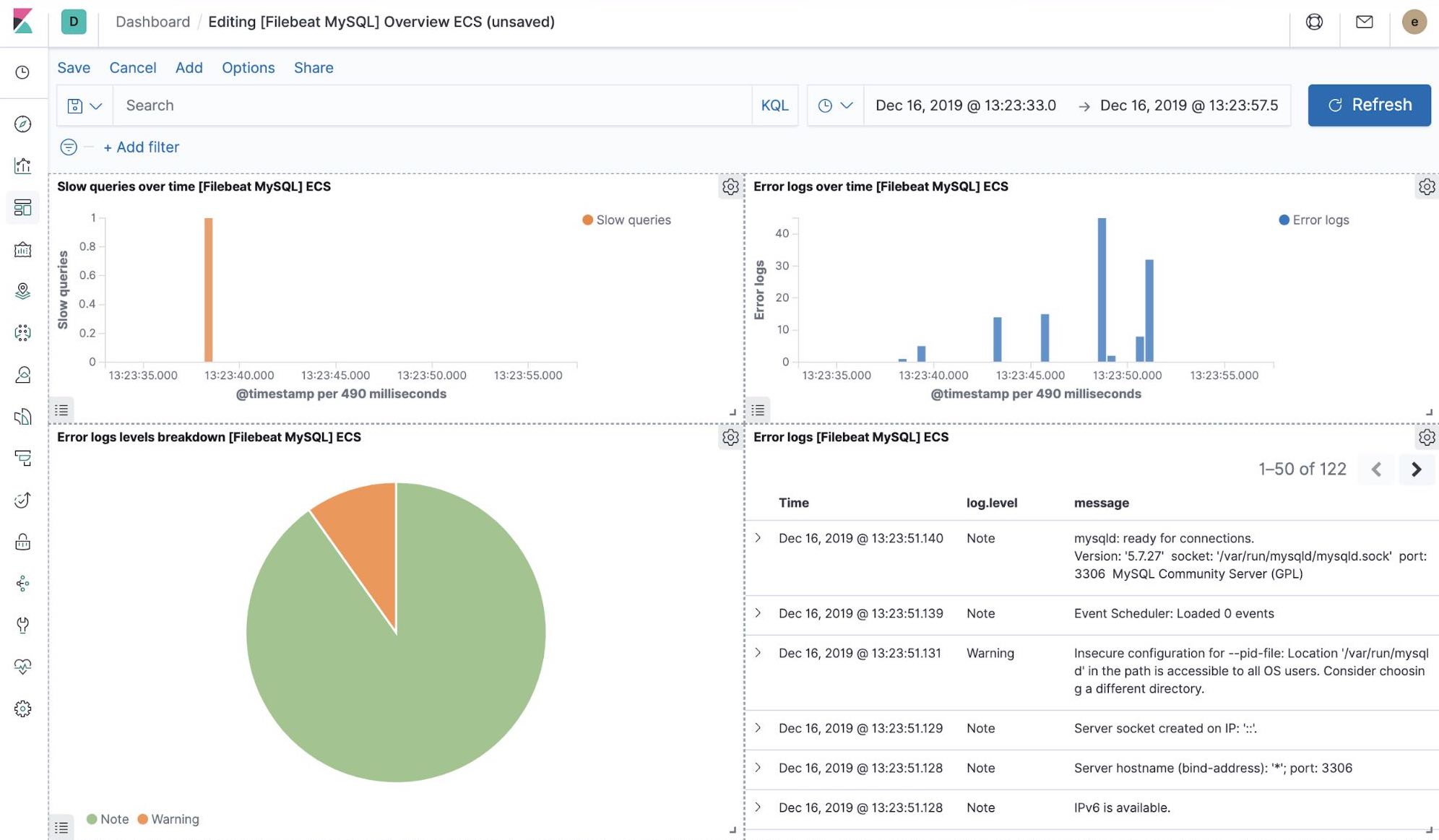
Beim Einrichten von Filebeat wurde unter anderem auch ein Satz integrierter Dashboards in Kibana erstellt. Nachdem wir nun unsere Petclinic-Beispielanwendung bereitgestellt haben, können wir zu den vordefinierten Filebeat-Dashboards für MySQL und NGINX navigieren, wo wir sehen, dass Filebeat-Module nicht nur Logdaten, sondern auch Metriken erfassen können, die die Komponenten in den Logs aufzeichnen. Zur Aktivierung dieser Visualisierungen müssen wir die MySQL- und die NGINX-Komponente der Beispielanwendung ausführen.
Machine Learning und Erkennen von Logging-Anomalien
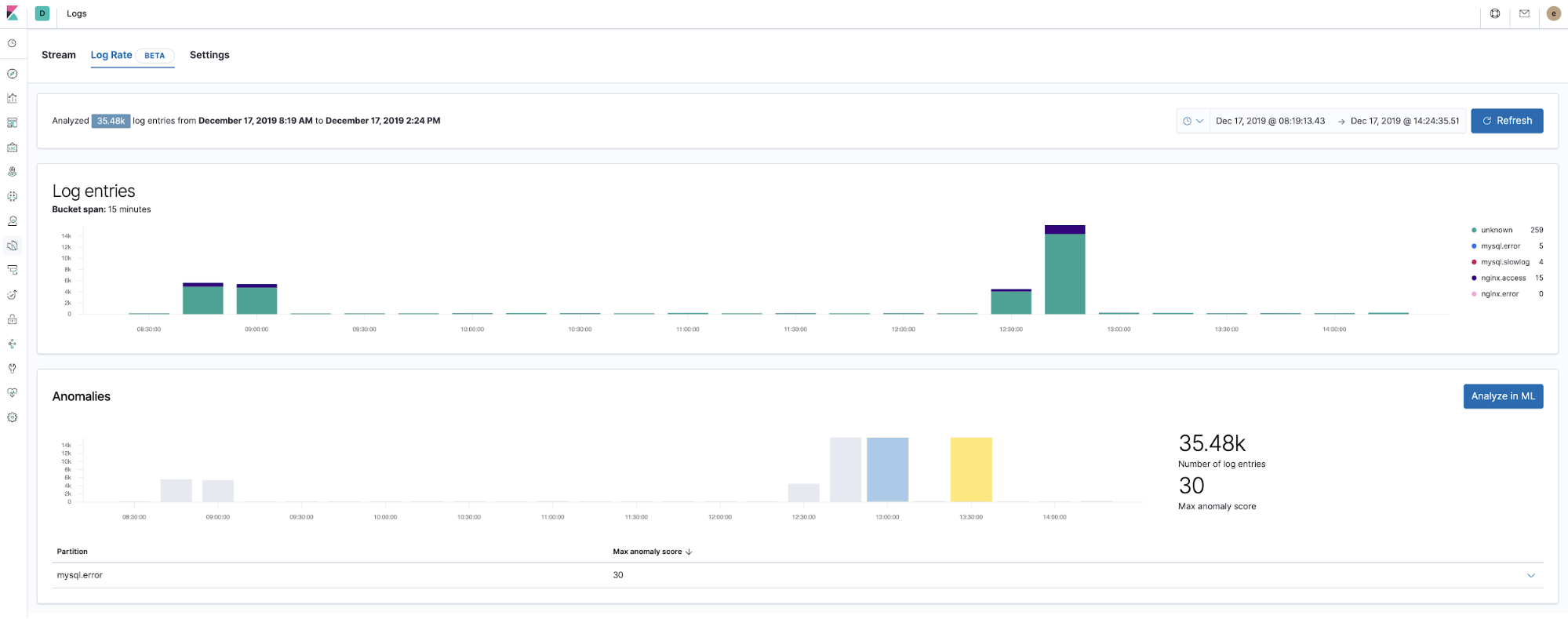
Seit Version 7.5 kann der Elastic Stack Anomalien bei der Logging-Geschwindigkeit von Anwendungskomponenten erkennen. Dies kann verwendet werden, um Dinge zu erkennen wie:
- Hinzukommen einer neuen Anwendung oder Logdatenquelle
- plötzlicher Anstieg der Logging-Aktivität wegen einer Promotion (oder eines Angriffs!)
- plötzlicher Stopp der Logdatenübermittlung, möglicherweise verursacht durch eine Fehlfunktion eines Agents oder einer Ingestionspipeline
Sofortige Antworten auf die oben gestellten Fragen liefert die direkt in der App Logs implementierte Funktion zur Erkennung von Anomalien bei der Logging-Geschwindigkeit. Diese kann mit einem einzigen Klick in der App Logs aktiviert werden.
Erkennung bislang unbekannter Logdatentypen durch Klassifizierung von Logeinträgen
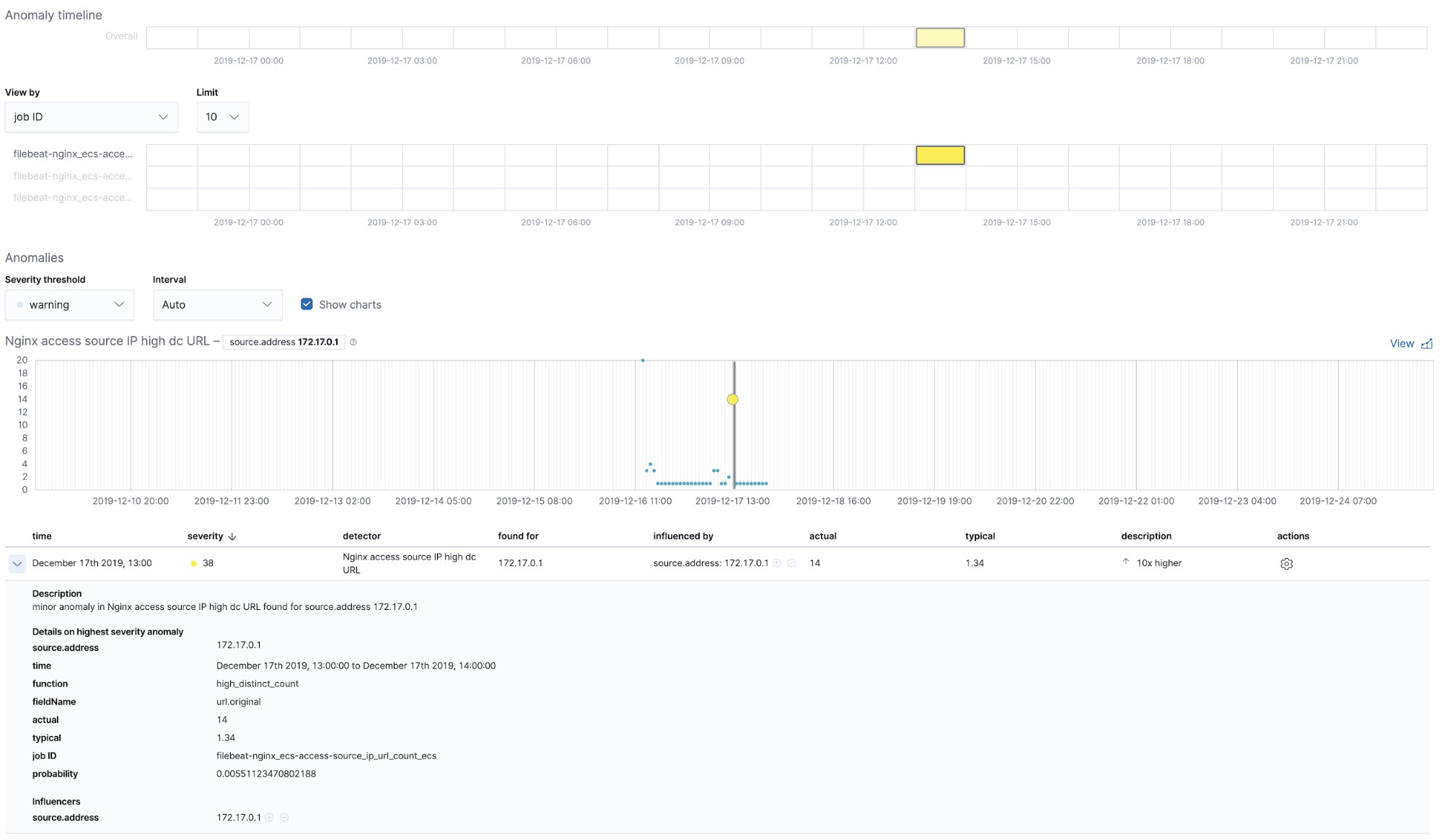
Eine weitere nützliche Möglichkeit, Machine Learning im Zusammenhang mit Logdaten einzusetzen, ist die Erkennung neuer Logdatentypen, die bisher unbekannt waren. Sehr vereinfacht gesagt, werden beim Machine Learning die numerischen und variablen Teile der Logdaten, wie Zeitstempel, Zahlenwerte usw., entfernt, und das, was an festen Teilen übrigbleibt, wird erfasst und kategorisiert. Wenn jetzt Informationen auftauchen, die zu keiner der bestehenden Kategorien passen, werden diese als Anomalien gekennzeichnet und gemeldet.

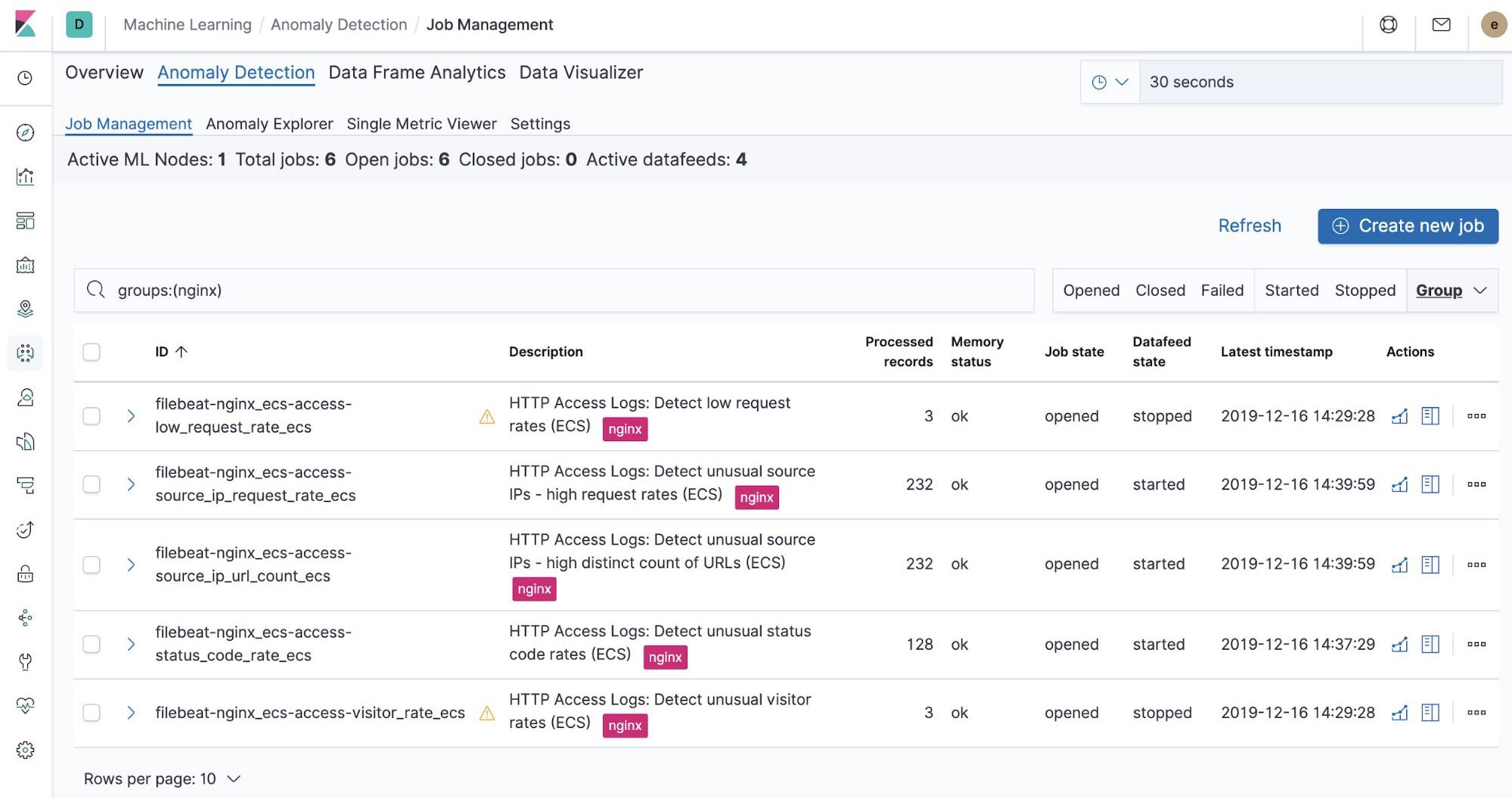
Integrierte Machine-Learning-Jobs – NGINX
Beim Einrichten von Filebeat wurden integrierte Machine-Learning-Jobs erstellt. Sobald diese aktiviert werden, können sie Anomalien in den aus Filebeat ingestierten NGINX-stdout- und ‑stderr-Daten erkennen.
Zusammenfassung
In diesem Teil haben wir mithilfe von Filebeat und seinen Modulen Kubernetes-Logdaten in Elastic Stack ingestiert. Für einen schnellen Einstieg in die Überwachung Ihrer Systeme und Infrastruktur haben Sie zwei Möglichkeiten: Entweder Sie melden sich an, um den Elasticsearch Service auf Elastic Cloud kostenlos auszuprobieren, oder Sie laden den Elastic Stack herunter und hosten ihn lokal. Nachdem alles eingerichtet ist, können Sie mit Elastic Uptime die Verfügbarkeit Ihrer Hosts überwachen und mit Elastic APM die Anwendungen instrumentieren, die auf Ihren Hosts ausgeführt werden. Auf diese Weise sorgen Sie für komplette Observability in Ihrem System, vollständig in Ihren neuen Metriken-Cluster integriert. Wenn Sie auf Probleme stoßen oder Fragen haben, wird Ihnen in unseren Discuss-Foren sicher schnell weitergeholfen.
Als Nächstes behandeln wir das Thema „Erfassen von Performance- und Zustandsmetriken“.