As partes 1 a 7 desta série descreveram um plano de controle governado para buscas em e-commerce. Um usuário digita uma consulta. O plano de controle classifica a intenção, aplica restrições de negócios, resolve conflitos de políticas e direciona para a estratégia de recuperação apropriada, tudo isso antes mesmo de o catálogo de produtos ser consultado. Toda a arquitetura pressupõe que a entrada seja uma string de busca digitada por um comprador humano.
Esta postagem final pergunta: O que muda quando a entrada vem de um agente de IA?
A resposta é que a arquitetura não muda, mas o que está em jogo, sim. Todas as propriedades do plano de controle governado que importam para consultas criadas por humanos tornam-se ainda mais importantes quando o tomador de decisão é um modelo de linguagem de grande porte (LLM). Determinismo, auditabilidade, resolução de conflitos e aplicação de restrições tornam-se proteções fundamentais em vez de conveniências operacionais, porque o sistema que produz os dados de entrada é probabilístico por natureza.
O problema de busca agêntica
A abordagem mais comum para a busca impulsionada por IA é direta: forneça ao LLM o esquema do banco de dados, insira as regras de negócio no prompt e permita que o agente gere a consulta diretamente.
Para um chatbot de e-commerce, isso significa injetar o mapeamento de índice do Elasticsearch, os tipos de campo, as taxonomias de categorias, a lógica de preços e as restrições de negócio na janela de contexto do agente e pedir ao LLM que traduza a linguagem natural para um DSL válido de consulta Elasticsearch. O LLM se torna o autor da consulta.
Essa abordagem funciona em demonstrações. Ela falha na produção por quatro motivos.
Excesso de contexto
Um mapeamento de índice de e-commerce empresarial não é um documento trivial. Definições de campos, objetos aninhados, configurações de múltiplos campos e configurações de analisador podem conter milhares de tokens antes que qualquer lógica de negócio seja adicionada. Além do mapeamento, o agente precisa de taxonomias de categorias (que, no e-commerce empresarial, podem conter dezenas de milhares de valores), regras de preços, hierarquias de marcas, restrições de elegibilidade e lógica de campanhas.
O resultado é uma janela de contexto dominada por metadados estruturais em vez da real intenção do usuário. Isso aumenta a latência, aumenta o custo do token e degrada a capacidade do LLM de seguir instruções à medida que o contexto cresce. Este é um fenômeno bem documentado, às vezes chamado decomposição de contexto: conforme o prompt fica mais longo, a atenção do modelo a qualquer instrução específica enfraquece.
Alucinação probabilística
Os LLMs geram consultas com base em padrões em dados de treinamento e no contexto fornecido. Quando recebe a solicitação de produzir Elasticsearch Query DSL, o modelo pode alucinar nomes de campos que não existem, criar cláusulas de consulta sintaticamente inválidas, aplicar incorretamente tipos de filtro aos tipos de campo errados ou produzir consultas que são sintaticamente válidas, mas semanticamente erradas, retornando resultados que não correspondem à intenção do usuário.
O benchmark BIRD do Google Cloud para Text-to-SQL ilustra o limite dessa abordagem. O resultado de última geração do Google, baseado em um único modelo, alcançou uma precisão entre 70% e 80%, o que significa que quase uma em cada quatro consultas geradas estava incorreta. Isso é para SQL, que é muito mais padronizado do que o DSL de Consulta Elasticsearch. A taxa de erro para consultas do Elasticsearch geradas pelo LLM em um ambiente de produção real, com mapeamentos complexos e semântica específica do negócio, provavelmente seria maior.
Para um sistema de e-commerce crítico para a receita, uma taxa de erro de um para quatro consultas não é um problema de ajuste a ser resolvido iterativamente. É uma limitação arquitetônica da abordagem.
A lacuna de segurança
Quando o LLM tem acesso ao esquema do banco de dados e age como o autor da consulta, o sistema fica vulnerável à injeção indireta de prompt. Um usuário interagindo com um chatbot de e-commerce pode criar entradas projetadas para manipular o agente a gerar consultas não intencionais.
Isso não é um risco teórico. Injeção de prompt é uma das superfícies de ataque mais ativamente pesquisadas em sistemas LLM implantados. A questão fundamental é que, quando o agente cria a consulta, não há uma fronteira estrutural entre a intenção do usuário e a execução da consulta. O LLM interpreta simultaneamente a solicitação do usuário e constrói a operação do banco de dados. Qualquer manipulação do primeiro afeta diretamente o segundo.
Falha de redimensionamento em alta cardinalidade
Certos campos de e-commerce têm cardinalidade extrema. Um catálogo de produtos pode ter 17.000 valores de categoria, milhares de marcas e centenas de combinações de atributos. Fluxos de trabalho agênticos padrão exigem a injeção desses valores no contexto para que o LLM possa selecionar o correto ao construir uma consulta.
Isso cria um trade-off impossível: ou se injetam todos os valores possíveis (consumindo um contexto enorme e degradando o desempenho), se injeta um subconjunto (e se aceita que o agente não pode referenciar valores fora desse subconjunto) ou se recorre à busca não governada. Isso se conecta diretamente ao problema central da Parte 1: se o LLM pesquisar por “laranjas” e o Elasticsearch retornar refrigerante de laranja, a experiência do chat se degrada da mesma forma que uma experiência de busca. A ausência de governança significa que o sistema não consegue aplicar a resolução pretendida pelo consumidor.
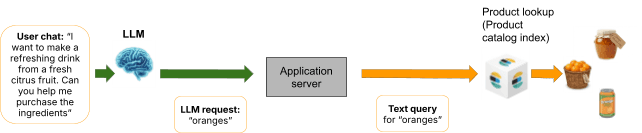
Recuperar valores relevantes de forma dinâmica com base na consulta é uma alternativa conhecida, mas introduz uma etapa adicional não determinística onde a própria recuperação pode perder valores relevantes. Além disso, adiciona latência e complexidade a cada consulta.
A alternativa arquitetônica: desacoplar intenção da execução
O plano de controle governado descrito nas Partes 1 a 7 oferece uma abordagem fundamentalmente diferente. Em vez de o LLM criar a consulta final, a função do LLM é reduzida a uma tarefa única e bem delimitada: extrair uma string de intenção de busca da entrada de linguagem natural do usuário.
O usuário diz: "Estou procurando sapatos marrons baratos." O trabalho do agente não é gerar uma consulta Elasticsearch. É extrair e repassar a intenção de busca (neste caso, algo como "sapatos marrons baratos") para o plano de controle. O plano de controle então faz o que sempre fez: permeia a string de intenção contra políticas armazenadas, compõe políticas correspondentes por meio de transformações em cascata, resolve conflitos deterministicamente e produz uma consulta Elasticsearch governada.
O LLM nunca vê o mapeamento do índice. Ele nunca sabe sobre tipos de campo, taxonomias de categorias ou limites de preço. Ele nunca cria uma cláusula de consulta. Ele opera no lado da linguagem natural de uma fronteira arquitetônica que chamamos de lacuna de metadados, uma separação estrita entre o componente probabilístico (o LLM) e a camada de dados estruturados (esquema, políticas e construção de consultas).
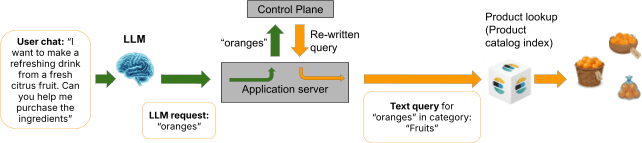
O que a separação de metadados oferece
- Cegueira ao esquema. O LLM não tem acesso ao esquema do banco de dados e, portanto, não pode gerar consultas inválidas, inventar nomes de campos ou ser manipulado para expor informações estruturais. O esquema existe apenas no lado determinístico do air gap.
- Contexto mínimo. Em vez de milhares de tokens de dados de mapeamento, regras de negócios e taxonomias de categorias, o prompt do LLM contém apenas instruções para extração de persona e intenção. Isso reduz drasticamente o custo do token, a latência e a deterioração do contexto.
- Execução determinística. Toda consulta que chega ao Elasticsearch é construída pelo plano de controle usando modelos de políticas avaliados por humanos, e não gerada probabilisticamente por um LLM. A validade sintática é garantida. A correção semântica é imposta pelo mesmo framework de políticas que as Partes 1 a 6 descreveram.
- Segurança pela arquitetura. A injeção rápida se torna estruturalmente ineficaz. Mesmo que um usuário manipule o agente para produzir uma string de intenção incomum, essa string é permeada contra políticas armazenadas. Se nenhuma política corresponde, nenhuma consulta é gerada. O usuário não pode instruir o agente a construir uma consulta porque o agente não cria consultas. O plano de controle sim, e o plano de controle é determinístico.
Como as peças se conectam
O guia a seguir mostra como o plano de controle governado lida com uma consulta mediada por agente.
Passo 1: O usuário fala com o agente
Um comprador interagindo com um chatbot de e-commerce diz: "Estou procurando chocolate barato, sem amendoim."
Etapa 2: O agente extrai a intenção
O papel do LLM é extração de intenções, não geração de consultas. Com uma solicitação mínima que o instrui a identificar a intenção do produto, o agente produz uma string de intenção de buscar: "chocolate barato sem amendoim".
Esta é uma tarefa de classificação leve. O LLM não precisa do mapeamento de índice, taxonomia de categorias ou regras de precificação para realizá-lo. Ele precisa entender linguagem natural, que é exatamente no que os LLMs são bons.
Etapa 3: O plano de controle governa a consulta
A string de intenção "chocolate barato sem amendoim" é passada para o plano de controle, que a filtra contra o índice de política. Três políticas coincidem:
- A política "barato" (extrai "barato", aplica um filtro de preço com base na categoria do produto).
- A política de "chocolate" (restringe os resultados a categorias de chocolate).
- A política de negação "sem" (extrai o alvo de exclusão e aplica um filtro
must_not)
O plano de controle aplica essas políticas por meio da mesma transformação em cascata descrita nas Partes 3 e 4: ordenação de prioridade, resolução de conflitos por campo e rastreamento de frases consumidas. Se uma política de "campanha de Natal" também estiver ativa, ela se compõe com as políticas de produto exatamente como descrito na Parte 3, o envolvimento do agente não altera em nada o modelo de governança.
Etapa 4: A consulta controlada é executada
O plano de controle gera uma consulta Elasticsearch totalmente governada: uma busca por "chocolate", restrita às categorias apropriadas, com um limite de preço derivado da política de "barato", um filtro de exclusão para produtos que contenham amendoim e quaisquer impulsionamentos de campanha ativos aplicados. Se a política de “chocolate” também incluir pesos de otimização econômica (Parte 7), estes também serão aplicados. O aumento de margem está definido em 3,0x porque "chocolate" é uma consulta de navegação em que o varejista se beneficia ao promover produtos com margens mais altas. Se o comprador tiver um histórico de compras(Parte 6), os sinais de personalização serão colocados em camadas. Essa consulta é sintaticamente válida por construção e semanticamente correta de acordo com a política de projeto.
Etapa 5: Retorno dos resultados pelo agente
Os resultados do produto são retornados ao agente, que os apresenta de forma conversacional ao usuário. O papel do agente no caminho de retorno é a apresentação: formatar resultados, responder perguntas de acompanhamento e fornecer detalhes do produto. A própria recuperação era governada, determinística e explicável.
No que o agente é bom (e no que não é)
Essa arquitetura aproveita o LLM para o que ele faz bem e protege o sistema do que ele faz mal.
Os LLMs se destacam em compreender a intenção da linguagem natural. "Estou procurando chocolate barato, sem amendoim" é uma tarefa de compreensão de linguagem natural, analisando a intenção, identificando referências de produtos e reconhecendo a negação. Os LLMs lidam com isso de forma confiável porque é um problema de classificação, não de geração. A saída é uma string curta de intenção, não uma consulta complexa e estruturada.
Os LLMs enfrentam dificuldades para gerar resultados estruturados precisos sob restrições complexas. A geração de DSL válida do Elasticsearch Query exige nomes de campo exatos, aninhamento correto de cláusulas, tipos de filtro apropriados para cada campo e aplicação consistente de regras de negócios em milhares de casos extremos. Essas são exatamente as propriedades que um sistema determinístico impõe trivialmente e que um sistema probabilístico aplica de forma pouco confiável.
O plano de controle governado coloca cada componente onde ele pertence: o LLM no lado da linguagem natural, o mecanismo de política determinística no lado da construção de consultas e um limite arquitetônico entre eles.
A governança restringe o raio da explosão
Essa é a mesma percepção da Parte 3, ampliada ao contexto agêntico. Na Parte 3, observamos que a governança torna a recuperação semântica mais segura ao restringir o conjunto de candidatos antes do início da recuperação. Uma busca semântica sobre 500 produtos em uma categoria governada é uma proposta fundamentalmente diferente de uma busca semântica sobre 500.000 SKUs.
O mesmo princípio se aplica a consultas mediadas por agentes. Sem governança, um agente que interprete mal "chocolate barato" poderia gerar uma consulta que buscasse todo o catálogo sem restrição de preço, sem filtro de categoria e sem exclusões. Com governança, mesmo que o agente produza uma string de intenção imperfeita, o plano de controle restringe a consulta às políticas que correspondem. O pior cenário é que menos políticas sejam ativadas, não que uma consulta ilimitada entre no catálogo de produtos.
A governança reduz o raio de explosão de erros probabilísticos. Isso é verdade tanto para o componente probabilístico quanto para um modelo semântico de recuperação ou um agente de LLM.
Políticas sugeridas pelo LLM: ampliar a cobertura
A Parte 2 introduziu a ideia de que um LLM pode sugerir novas políticas que entram no mesmo pipeline Author → Test → Promote que as criadas por humanos. No contexto agente, isso se torna um poderoso ciclo de retroalimentação.
Um LLM pode analisar os logs de consulta, identificar padrões em que o plano de controle não tem uma política correspondente (consultas que passam por uma recuperação não modificada) e sugerir novas políticas para cobrir essas lacunas. Um comerciante analisa cada sugestão, testa e a promove se ela produzir o comportamento esperado. O modelo de governança garante que nenhuma política sugerida pelo LLM chegue à produção sem validação humana.
Com o tempo, isso cria um ciclo virtuoso: a abrangência das políticas do plano de controle se expande, a proporção de consultas que exigem recuperação sem modificações diminui e o sistema se torna progressivamente mais governado, com cada política auditável, versionada e reversível individualmente.
O padrão mais amplo: proteções determinísticas para sistemas probabilísticos
A arquitetura descrita nesta série, um plano de controle determinístico que se situa entre uma fonte de entrada probabilística e um sistema de recuperação de dados, não é específica para busca em e-commerce. O mesmo padrão se aplica sempre que um agente de IA precisa interagir com dados estruturados.
Um agente que consulta um banco de dados SQL enfrenta os mesmos desafios: excesso de contexto devido à injeção de esquema, nomes de colunas alucinados, riscos de injeção imediata e seleção de valores de alta cardinalidade. Um agente interagindo com um sistema de emissão de tíquetes como o Jira, um sistema de gerenciamento de relacionamento com o cliente (CRM) como o Salesforce ou um repositório de código como o GitHub enfrenta problemas análogos. Em todos os casos, a questão arquitetônica do núcleo é a mesma: o LLM deve criar a consulta ou o LLM deve extrair a intenção e passá-la para uma camada determinística que cria a consulta?
O plano de controle governado fornece uma resposta repetível para essa pergunta. As políticas são dados. A extração de intenções é tarefa do LLM. A construção de consultas é tarefa do plano de controle. O espaço de metadados os mantém separados. E o framework de governança (ordenação de prioridades, resolução de conflitos, transformações em cascata, auditabilidade) garante que a camada determinística seja operacionalmente gerenciável à medida que o número de políticas cresce.
Conclusão
Os padrões de governança de pesquisa de e-commerce descritos nesta série (políticas como dados, fluxo de trabalho Autor → Teste → Promover, transformações em cascata, resolução de conflitos por campo, correspondência reversa baseada em permeações e fallback de várias camadas) foram projetados para um mundo em que um comerciante cria políticas e um comprador digita consultas. Mas a arquitetura pode permitir muito mais do que seu caso de uso inicial.
Quando a fonte de entrada é um agente de IA em vez de um comprador humano, o plano de controle governado torna-se a camada de segurança crítica entre um sistema probabilístico e um armazenar de dados de produção. Ele oferece as garantias determinísticas (validade sintática, correção semântica, auditabilidade e segurança) que os sistemas corporativos exigem e que os LLMs não podem fornecer sozinhos.
O plano de controle determinístico não substitui o agente de IA. Isso torna o agente de IA seguro para implantação.
Coloque em prática o buscar governado de comércio eletrônico
A arquitetura do plano de controle governado descrita nesta série, desde o paradigma de política como dados até a busca baseada em permeação, passando pela personalização, otimização econômica e o espaço aéreo agente, foi projetada e construída pela Elastic Services Engineering. Cada padrão descrito nesta série provém de um sistema funcional construído e validado em catálogos de produtos de escala empresarial.
Se sua equipe está desenvolvendo experiências de busca com inteligência artificial e precisa de diretrizes determinísticas para consultas mediadas por agentes, ou se deseja implementar uma arquitetura de busca governada e editável pela empresa no Elasticsearch, o Elastic Professional Services pode acelerar a implementação. Entre em contato com o Elastic Professional Services.
Participe da discussão
Tem dúvidas sobre governança de buscar, estratégias de recuperação ou arquitetura de buscar para e-commerce? Participe da conversa mais ampla da comunidade Elastic.
Conteúdo relacionado

11 de maio de 2026
Personalizando a busca de e-commerce: integrando o histórico de compras e de grupos de usuários
Aprenda a criar uma experiência personalizada de busca em e-commerce no Elasticsearch sem comprometer a governança. Este post explica como destacar produtos que um cliente já comprou antes e como ativar políticas específicas de grupo com base nos perfis dos usuários.

4 de maio de 2026
Percolador do Elasticsearch para governança de busca em comércio eletrônico: traduzindo consultas ambíguas em estratégias de recuperação controladas
Aprenda como usar o percolador do Elasticsearch para implementar a governança de busca. Neste blog, delineamos os padrões necessários para criar um motor de políticas governado em produção e criar uma estratégia de recuperação controlada.

1 de maio de 2026
Construindo um plano de controle para gerenciar a busca de comércio eletrônico
Como criar um plano de controle com governança para e-commerce que integra políticas de busca conflitantes em um único plano de execução (sem alterações de código).

24 de abril de 2026
Reindexação de fluxos de dados por causa de conflitos de mapeamento
Aprenda como corrigir conflitos de mapeamento do Elasticsearch reindexando fluxos de dados. Este blog explica o processo de reindexação e como garantir que os novos dados sejam mapeados corretamente.

9 de abril de 2026
Por que a busca para e-commerce precisa de governança
Descubra por que a busca para e-commerce falha sem governança e como uma camada de controle garante resultados previsíveis e orientados pela intenção, melhorando a recuperação.