Les parties 1 à 7 de cette série décrivent un plan de contrôle gouverné pour la recherche e-commerce. Un utilisateur saisit une requête. Le plan de contrôle classe l'intention, applique les contraintes métier, résout les conflits de politiques et oriente vers la stratégie de récupération appropriée, le tout avant même que le catalogue produit ne soit interrogé. Toute l'architecture part du principe que l'entrée est une chaîne de recherche saisie par un acheteur humain.
Ce dernier article pose la question suivante : qu'est-ce qui change lorsque l'entrée provient d'un agent IA ?
La réponse est que l'architecture ne change pas, mais les enjeux, oui. Toutes les propriétés du plan de contrôle gouverné qui sont importantes pour les requêtes rédigées par des humains sont encore plus importantes lorsque le décideur en amont est un grand modèle de langage (LLM). Le déterminisme, l'auditabilité, la résolution des conflits et l'application des contraintes deviennent des garde-fous critiques plutôt que des commodités opérationnelles, car le système qui produit l'entrée est par nature probabiliste.
Le problème de la recherche agentique
L'approche la plus courante de la recherche pilotée par l'IA est simple : donner au LLM le schéma de la base de données, fournir des règles métier dans le prompt et laisser l'agent générer la requête directement.
Pour un chatbot e-commerce, cela signifie injecter le mapping d'index Elasticsearch, les types de champs, les taxonomies de catégories, la logique de tarification et les contraintes métier dans la fenêtre de contexte de l'agent, puis demander au LLM de traduire le langage naturel en DSL de requêtes Elasticsearch valide. Le LLM devient ainsi l'auteur de la requête.
Cette approche fonctionne lors des démonstrations. Elle échoue en production pour quatre raisons.
Gonflement du contexte
Le mapping d'un système e-commerce d'entreprise est un document complexe. Les définitions de champs, les objets imbriqués, les configurations multichamps et les paramètres d'analyse peuvent représenter des milliers d'éléments avant même l'ajout de la logique métier. Outre ce mapping, l'agent a besoin des taxonomies de catégories (qui, dans le contexte de l'e-commerce d'entreprise, peuvent contenir des dizaines de milliers de valeurs), des règles de tarification, des hiérarchies de marques, des critères d'éligibilité et de la logique de campagne.
Le résultat est une fenêtre de contexte dominée par les métadonnées structurelles plutôt que par l'intention réelle de l'utilisateur. Cela augmente la latence, augmente le coût des tokens et dégrade la capacité du LLM à suivre les instructions à mesure que le contexte s'agrandit. Il s'agit d'un phénomène bien documenté, parfois appelé pourriture contextuelle : à mesure que le prompt s'allonge, l'attention portée par le modèle à une instruction particulière diminue.
Hallucination probabiliste
Les LLM génèrent des requêtes à partir de schémas présents dans leurs données d'entraînement et du contexte fourni. Lorsqu'on leur demande de produire du DSL de requêtes Elasticsearch, le modèle peut halluciner des noms de champs inexistants, construire des clauses de requête syntaxiquement invalides, appliquer incorrectement des types de filtres à des types de champs inappropriés, ou produire des requêtes syntaxiquement valides mais sémantiquement incorrectes, renvoyant des résultats qui ne correspondent pas à l'intention de l'utilisateur.
Le benchmark BIRD de conversion texte vers SQL de Google Cloud illustre les limites de cette approche. Le résultat de pointe de Google, basé sur un modèle unique, a atteint une précision de 70 à 80 %, c'est-à-dire que près d'une requête générée sur quatre était incorrecte. Ce résultat concerne le SQL, bien plus standardisé que le DSL de requêtes Elasticsearch. Le taux d'erreur des requêtes Elasticsearch générées par LLM dans un environnement de production réel, avec des mappings complexes et une sémantique spécifique au métier, serait probablement plus élevé.
Pour un système e-commerce critique en termes de revenus, un taux d'erreur de requête sur quatre n'est pas un problème de réglage à résoudre de façon itérative. C'est une limite architecturale de l'approche.
La faille de sécurité
Lorsque le LLM a accès au schéma de la base de données et agit en tant qu'auteur de la requête, le système est vulnérable à l'injection indirecte de prompts. Un utilisateur qui interagit avec un chatbot e-commerce peut créer des entrées conçues pour inciter l'agent à générer des requêtes involontaires.
Ce n'est pas un risque théorique. L'injection de prompts est l'une des surfaces d'attaque les plus activement étudiées dans les systèmes LLM déployés. Le problème fondamental est que lorsque l'agent rédige la requête, il n'y a pas de limite structurelle entre l'intention de l'utilisateur et l'exécution de la requête. Le LLM interprète simultanément la demande de l'utilisateur et construit l'opération de base de données. Toute manipulation du premier élément affecte directement le second.
Échec du scaling à haute cardinalité
Certains champs e-commerce présentent une cardinalité extrême. Un catalogue de produits peut comporter 17 000 valeurs de catégorie, des milliers de noms de marques et des centaines de combinaisons d'attributs. Les workflows agentiques standard nécessitent l'injection de ces valeurs dans le contexte afin que le LLM puisse sélectionner la valeur correcte lors de la construction d'une requête.
Cela crée un compromis impossible : soit injecter toutes les valeurs possibles (consommant un contexte énorme et dégradant les performances), injecter un sous-ensemble (et accepter que l'agent ne puisse pas référencer des valeurs en dehors de ce sous-ensemble), ou revenir à une recherche non gouvernée. Ceci est directement lié au problème central abordé dans la partie 1 : si le LLM recherche "oranges" et qu'Elasticsearch renvoie des sodas à l'orange, l'expérience du chat se dégrade de la même manière que l'expérience de la recherche. L'absence de gouvernance signifie que le système ne peut pas appliquer la résolution prévue par l'acheteur.
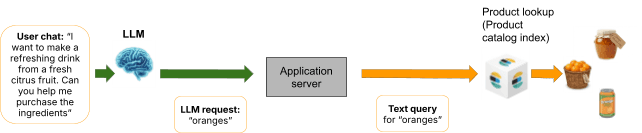
La récupération dynamique de valeurs pertinentes en fonction de la requête est une alternative connue, mais elle introduit une étape supplémentaire non déterministe où la récupération elle-même peut passer à côté de valeurs pertinentes. De plus, cela ajoute de la latence et de la complexité à chaque requête.
L'alternative architecturale : dissocier l'intention de l'exécution
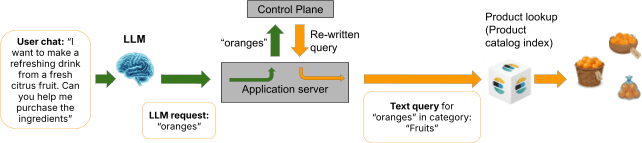
Le plan de contrôle gouverné décrit dans les parties 1 à 7 offre une approche fondamentalement différente. Au lieu que le LLM soit l'auteur de la requête finale, son rôle est réduit à une seule tâche bien délimitée : extraire une chaîne d'intention de recherche à partir de l'entrée en langage naturel de l'utilisateur.
L'utilisateur indique : "Je cherche des chaussures marron bon marché." Le rôle de l'agent n'est pas de générer une requête Elasticsearch, mais d'extraire et de transmettre l'intention de recherche (dans ce cas, quelque chose comme "chaussures marron bon marché") au plan de contrôle. Le plan de contrôle suit alors sa procédure habituelle : il filtre la chaîne d'intention par rapport aux politiques stockées, compose les politiques correspondantes par le biais de transformations en cascade, résout les conflits de manière déterministe et produit une requête Elasticsearch gouvernée.
Le LLM ne voit jamais le mapping des index. Il ne connaît jamais les types de champs, les taxonomies de catégories ou les seuils de tarification. Il ne crée jamais de clause de requête. Il agit du côté du langage naturel d'une frontière architecturale que nous appelons isolation des métadonnées (metadata air gap), une séparation stricte entre la composante probabiliste (le LLM) et la couche de données structurées (schéma, politiques et construction de requêtes).
Ce que l'espace isolé des métadonnées fournit
- Insensibilité au schéma. Le LLM n'a pas accès au schéma de la base de données et ne peut donc pas générer de requêtes invalides, halluciner les noms de champs ni être manipulé pour révéler des informations structurelles. Le schéma existe uniquement du côté déterministe de la séparation physique.
- Contexte minimal. Au lieu de milliers de tokens de données de mapping, de règles métier et de taxonomies de catégories, le prompt du LLM ne contient qu'une persona et des instructions d'extraction d'intent. Cela réduit considérablement le coût des tokens, la latence et la dégradation du contexte.
- Exécution déterministe. Chaque requête qui parvient à Elasticsearch est créée par le plan de contrôle à l'aide de modèles de règles validées par des humains, et non générés de manière probabiliste par un LLM. La validité syntaxique est garantie. La correction sémantique est garantie par le même framework de politiques que celui décrit dans les parties 1 à 6.
- Sécurité par architecture. L'injection de prompt devient structurellement inefficace. Même si un utilisateur manipule l'agent pour produire une chaîne d'intention inhabituelle, cette chaîne est filtrée par rapport aux politiques stockées. Si aucune politique ne correspond, aucune requête n'est générée. L'utilisateur ne peut pas demander à l'agent de construire une requête, car l'agent ne construit pas de requêtes. Le plan de contrôle le fait, et le plan de contrôle est déterministe.
Comment les pièces s'assemblent
La procédure suivante explique comment le plan de contrôle gouverné traite une requête transmise par un agent.
Étape 1 : L'utilisateur parle à l'agent
Un client interagissant avec un chatbot e-commerce déclare : "Je cherche du chocolat pas cher, sans arachide."
Étape 2 : L'agent extrait l'intention
Le rôle du LLM est d'extraire les intentions, et non de générer des requêtes. À partir d'un simple prompt lui demandant d'identifier l'intention de la recherche du produit, l'agent produit une chaîne de caractères : "chocolat bon marché sans arachide".
Il s'agit d'une tâche de classement simple. Le LLM n'a pas besoin du mapping d'index, de la taxonomie par catégories ou des règles de tarification pour la réaliser. Il doit comprendre le langage naturel, et c'est exactement ce que font les LLM.
Étape 3 : Le plan de contrôle gère la requête
La chaîne d'intention "chocolat bon marché sans arachide" est transmise au plan de contrôle, qui la compare à l'index des politiques. Trois politiques correspondent :
- La politique "bon marché" (extrait "bon marché", applique un filtre de prix basé sur la catégorie de produit).
- La politique "chocolat" (limite les résultats aux catégories de chocolat).
- La politique de négation "sans" (extrait la cible d'exclusion et applique un filtre
must_not)
Le plan de contrôle applique ces politiques par le biais de la même transformation en cascade décrite dans la partie 3 et 4 : ordre de priorité, résolution des conflits par champ, suivi des expressions consommées. Si une politique "campagne de Noël" est également active, elle se combine avec les politiques de produits exactement comme décrit dans la partie 3 ; l'implication de l'agent ne change absolument rien au modèle de gouvernance.
Étape 4 : La requête gouvernée s'exécute
Le plan de contrôle produit une requête Elasticsearch entièrement gouvernée : une recherche sur "chocolat", limitée aux catégories appropriées, avec un prix plafond dérivé de la politique "bon marché", un filtre d'exclusion pour les produits contenant de l'arachide et toutes les améliorations de campagne actives appliquées. Si la politique "chocolat" comprend également des pondérations d'optimisation économique (Partie 7), celles-ci sont également appliquées. La valeur du boosting de marge est fixée à 3x, car "chocolat" est une requête de navigation où le détaillant bénéficie de la promotion de produits à marge plus élevée. Si l'acheteur a un historique d'achat(Partie 6), les signaux de personnalisation sont superposés. Cette requête est syntaxiquement valide par construction et sémantiquement correcte par conception de la politique.
Étape 5 : Les résultats sont renvoyés par l'intermédiaire de l'agent
Les résultats des produits sont renvoyés à l'agent, qui les présente à l'utilisateur sous forme de conversation. Le rôle de l'agent dans le chemin de retour est la présentation : mettre en forme les résultats, répondre aux questions de suivi, fournir des détails sur les produits. La récupération elle-même était gouvernée, déterministe et explicable.
Ce que l'agent sait faire (et ce qu'il ne sait pas faire)
Cette architecture tire parti des points forts du LLM et protège le système de ses points faibles.
Les LLM excellent dans la compréhension de l'intention en langage naturel. "Je cherche du chocolat pas cher, sans arachide" est une tâche de compréhension du langage naturel qui consiste à analyser l'intention, identifier les références aux produits et reconnaître la négation. Les LLM gèrent cela efficacement, car il s'agit d'un problème de classification, et non de génération. Le résultat est une courte chaîne de caractères exprimant l'intention, et non une requête structurée complexe.
Les LLM peinent à produire des résultats structurés et précis sous des contraintes complexes. Générer du DSL de requêtes Elasticsearch valide exige des noms de champs exacts, une imbrication correcte des clauses, des types de filtres appropriés pour chaque champ et une application cohérente des règles métier à travers des milliers de cas particuliers. Ce sont précisément les propriétés qu'un système déterministe garantit sans difficulté, contrairement à un système probabiliste.
Le plan de contrôle gouverné place chaque composant à sa place : le LLM côté langage naturel, le moteur de politique déterministe côté construction de requêtes, et une frontière architecturale entre eux.
La gouvernance limite le rayon d'action
C'est la même idée que dans la partie 3, étendue au contexte agentique. Dans la partie 3, nous avons observé que la gouvernance rend la recherche sémantique plus sûre en réduisant le nombre de candidats avant le début de la recherche. Une recherche sémantique sur plus de 500 produits dans une catégorie gouvernée est fondamentalement différente d'une recherche sémantique sur plus de 500 000 références.
Le même principe s'applique aux requêtes effectuées par l'intermédiaire d'un agent. Sans gouvernance, un agent qui interprète mal l'expression "chocolat bon marché" pourrait générer une requête qui parcourt l'ensemble du catalogue sans contrainte de prix, sans filtre de catégorie, sans exclusions. Avec la gouvernance, même si l'agent produit une chaîne d'intention imparfaite, le plan de contrôle limite la requête aux politiques qui correspondent. Le pire scénario est la réduction du nombre de politiques déclenchées, et non l'exécution d'une requête illimitée sur le catalogue de produits.
La gouvernance réduit le rayon d'action des erreurs probabilistes. Cela reste vrai, que le composant probabiliste soit un modèle de récupération sémantique ou un agent LLM.
Politiques suggérées par LLM : élargissement de la couverture
La partie 2 a introduit l'idée qu'un LLM peut suggérer de nouvelles politiques qui entrent dans le même pipeline Auteur → Test → Promotion que les politiques rédigées par des humains. Dans le contexte agentique, cela devient une puissante boucle de feedback.
Un LLM peut analyser les logs de requêtes, identifier les modèles où le plan de contrôle n'a pas de politique correspondante (requêtes qui aboutissent à une récupération sans modification) et suggérer de nouvelles politiques pour combler ces lacunes. Un responsable merchandising examine chaque suggestion, la teste et la déploie si elle produit le comportement attendu. Le modèle de gouvernance garantit qu'aucune politique suggérée par le LLM n'est mise en production sans validation humaine.
Au fil du temps, cela crée un cercle vertueux : la couverture des politiques du plan de contrôle s'étend, la proportion de requêtes nécessitant une récupération non modifiée diminue et le système devient progressivement plus régulé, chaque politique étant auditable, versionnée et réversible individuellement.
Le schéma le plus large : garde-fous déterministes pour les systèmes probabilistes
L'architecture décrite dans cette série, un plan de contrôle déterministe qui se situe entre une source d'entrée probabiliste et un système de recherche de données, n'est pas spécifique à la recherche e-commerce. Le même schéma s'applique partout où un agent IA doit interagir avec des données structurées.
Un agent interrogeant une base de données SQL fait face aux mêmes défis : gonflement du contexte dû à l'injection de schéma, noms de colonnes hallucinés, risques d'injection de prompt et sélection de valeurs à haute cardinalité. Un agent interagissant avec un système de billetterie comme Jira, un système de gestion de la relation client (CRM) comme Salesforce ou un dépôt de code comme GitHub est confronté à des problèmes analogues. Dans tous les cas, la question architecturale centrale est la même : le LLM doit-il rédiger la requête, ou doit-il extraire l'intention et la transmettre à une couche déterministe qui rédige la requête ?
Le plan de contrôle gouverné fournit une réponse répétable à cette question. Les politiques sont des données. L'extraction de l'intention est le travail du LLM. La construction de requêtes est le travail du plan de contrôle. L'espace entre les métadonnées permet de les séparer. Et le framework de gouvernance (ordre des priorités, résolution des conflits, transformations en cascade, auditabilité) garantit que la couche déterministe est gérable opérationnellement à mesure que le nombre de politiques augmente.
Conclusion
Les modèles de gouvernance de la recherche e-commerce décrits dans cette série (politiques en tant que données, workflow Auteur → Test → Promotion, transformations en cascade, résolution des conflits par champ, correspondance inversée basée sur un percolateur et repli multiniveau) ont été conçus pour un monde où un responsable merchandising rédige des politiques et un client saisit des requêtes. Mais cette architecture offre bien plus de possibilités que son cas d'utilisation initial.
Lorsque la source d'entrée est un agent IA plutôt qu'un consommateur humain, le plan de contrôle gouverné devient la couche de sécurité critique entre un système probabiliste et un système de stockage de données de production. Il fournit les garanties déterministes (validité syntaxique, exactitude sémantique, auditabilité et sécurité) requises par les systèmes d'entreprise que les LLM ne peuvent assurer seuls.
Le plan de contrôle déterministe ne remplace pas l'agent IA. Il permet simplement de déployer l'agent IA en toute sécurité.
Mettre en pratique la recherche e-commerce réglementée
L'architecture de plan de contrôle gouverné décrite dans cette série, depuis le paradigme des politiques en tant que données jusqu'à la recherche par percolateur, en passant par la personnalisation, l'optimisation économique et l'isolation des agents, a été conçue et réalisée par Elastic Services Engineering. Chaque modèle présenté dans cette série provient d'un système opérationnel construit et validé à l'aide de catalogues de produits à l'échelle de l'entreprise.
Si votre équipe développe des expériences de recherche optimisées par l'IA et a besoin de garde-fous déterministes pour les requêtes gérées par des agents, ou si vous souhaitez implémenter une architecture de recherche gouvernée et modifiable par l'entreprise sur Elasticsearch, les services professionnels d'Elastic peuvent accélérer votre mise en œuvre. Contactez Elastic Professional Services.
Rejoignez la discussion
Avez-vous des questions sur la gouvernance de la recherche, les stratégies de récupération ou l'architecture de recherche e-commerce ? Participez à la discussion élargie de la communauté Elastic.
Pour aller plus loin

11 mai 2026
Personnaliser la recherche e-commerce : intégrer l’historique d’achat et les cohortes d’utilisateurs
Découvrez comment créer une expérience de recherche e-commerce personnalisée dans Elasticsearch sans compromettre la gouvernance. Cet article explique comment mettre en avant les produits déjà achetés par un client et comment activer des politiques spécifiques à certaines cohortes selon les profils utilisateurs.

4 mai 2026
Percolateur Elasticsearch pour la gouvernance de la recherche e-commerce : traduire les requêtes ambiguës en stratégies de récupération contrôlée
Découvrez comment utiliser le percolateur Elasticsearch pour mettre en œuvre la gouvernance de la recherche. Dans cet article, nous présentons les modèles nécessaires à la création d'un moteur de politiques gouverné en production et à l'élaboration d'une stratégie de récupération contrôlée.

1 mai 2026
Élaboration d'un plan de contrôle pour gérer la recherche dans le commerce électronique
Comment mettre en place un plan de contrôle géré pour le commerce électronique qui intègre des politiques de recherche conflictuelles en un seul plan d'exécution (sans modification du code).

24 avril 2026
Réindexation des flux de données en raison de conflits de mapping
Découvrez comment résoudre les conflits de mapping Elasticsearch en réindexant les flux de données. Cet article explique le processus de réindexation et comment garantir un mapping correct des nouvelles données.

9 avril 2026
Pourquoi la recherche en e-commerce nécessite une gouvernance
Découvrez pourquoi la recherche e-commerce échoue sans gouvernance et comment une couche de contrôle garantit des résultats prévisibles et axés sur l’intention, améliorant ainsi la récupération des données.