En las partes 1 a 7 de esta serie se describió un plano de control regulado para la búsqueda en el comercio electrónico. Un usuario introduce una consulta. El plano de control clasifica la intención, impone restricciones de negocio, resuelve conflictos de políticas y enruta a la estrategia de recuperación apropiada, todo antes de que se consulte el catálogo de productos. Toda la arquitectura asume que la entrada es un texto de búsqueda que ha escrito un comprador humano.
En esta última publicación nos preguntamos: ¿Qué cambia cuando la entrada proviene de un agente de IA?
La respuesta es que la arquitectura no cambia, pero las implicancias sí. Cada propiedad del plano de control regulada que es relevante para las consultas de autor humano es más importante cuando quien toma decisiones en sentido ascendente es un modelo de lenguaje grande (LLM). El determinismo, la auditabilidad, la resolución de conflictos y la aplicación de restricciones se convierten en medidas de seguridad fundamentales, en vez de simples comodidades operativas, ya que el sistema que genera los datos de entrada es de naturaleza probabilística.
El problema de la búsqueda con agentes
El enfoque más común para la búsqueda impulsada por IA es sencillo: proporciona al LLM el esquema de base de datos y las reglas de negocio en la indicación, y deja que el agente genere la consulta directamente.
Para un chatbot de comercio electrónico, esto significa inyectar el mapeo del índice, los tipos de campos, las taxonomías de categorías, la lógica de precios y las restricciones de negocio de Elasticsearch en la ventana de contexto del agente, y luego pedir al LLM que traduzca el lenguaje natural a un DSL de búsqueda de Elasticsearch válido. El LLM se convierte en el autor de la consulta.
Este enfoque funciona en demostraciones. Sin embargo, falla en producción por cuatro razones.
Exceso de contexto
El mapeo de índices de comercio electrónico empresarial no es un documento trivial. Las definiciones de campo, los objetos anidados, las configuraciones de varios campos y la configuración del analizador pueden ejecutarse en miles de tokens antes de que se agregue cualquier lógica de negocio. Además del mapeo, el agente necesita taxonomías de categorías (que en el comercio electrónico empresarial pueden contener decenas de miles de valores), reglas de precios, jerarquías de marcas, restricciones de elegibilidad y lógica de campañas.
El resultado es una ventana de contexto en la que predominan los metadatos estructurales en vez de la intención real del usuario. Esto aumenta la latencia, incrementa el costo de los tokens y reduce la capacidad del LLM para seguir instrucciones a medida que aumenta el contexto. Este es un fenómeno bien documentado, a veces llamado descomposición de contexto: a medida que el mensaje se hace más largo, la atención del modelo a cualquier instrucción particular se debilita.
Alucinación probabilística
Los LLM generan consultas basadas en patrones en sus datos de entrenamiento y el contexto proporcionado. Cuando se le solicita al modelo que genere un DSL de consulta de Elasticsearch, este puede inventar nombres de campos inexistentes, elaborar cláusulas de consulta sintácticamente inválidas, aplicar de forma errónea tipos de filtro a campos equivocados o generar consultas que son sintácticamente válidas pero semánticamente incorrectas, por lo cual arroja resultados que no coinciden con la intención del usuario.
La prueba de rendimiento BIRD de Google Cloud para la conversión de texto a SQL muestra los límites de este enfoque. El resultado de vanguardia de un solo modelo de Google alcanzó entre un 70% y un 80% de precisión, lo que significa que casi una de cada cuatro consultas generadas era incorrecta. Esto es para SQL, que está mucho más estandarizado que Elasticsearch Query DSL. La tasa de error para consultas de Elasticsearch generadas por LLM en un entorno de producción real, con mapeos complejos y semántica específica del negocio, probablemente sería mayor.
Una tasa de error de una de cada cuatro consultas en un sistema de comercio electrónico que es fundamental para los ingresos no es un problema de ajuste que deba resolverse de forma iterativa. Es una limitación arquitectónica del enfoque.
La brecha de seguridad
Cuando el LLM tiene acceso al esquema de la base de datos y actúa como el autor de la consulta, el sistema es vulnerable a la inyección indirecta de indicaciones. Un usuario que interactúa con un chatbot de comercio electrónico puede crear entradas diseñadas para manipular al agente y que genere consultas no intencionadas.
No se trata de un riesgo teórico. La inyección de indicaciones es una de las superficies de ataque que más se investiga de forma activa en sistemas de MLM desplegados. El problema fundamental es que, cuando el agente crea la consulta, no hay una separación clara entre la intención del usuario y la ejecución de la consulta. El LLM interpreta la solicitud del usuario y, al mismo tiempo, crea la operación de la base de datos. Cualquier manipulación de la primera afecta directamente a la segunda.
Fallo de escalado de alta cardinalidad
Ciertos campos del comercio electrónico tienen una cardinalidad extrema. Un catálogo de productos puede tener 17 000 valores de categoría, miles de marcas y cientos de combinaciones de atributos. Los flujos de trabajo estándar de los agentes requieren inyectar estos valores en el contexto para que el LLM pueda seleccionar el correcto al construir una consulta.
Esto crea un dilema imposible: se inyectan todos los valores posibles (consumiendo un contexto enorme y degradando el rendimiento), se inyecta un subconjunto (y se acepta que el agente no puede hacer referencia a valores fuera de ese subconjunto) o se recurre a una búsqueda no regulada. Esto se conecta directamente con el problema principal de la Parte 1: si el LLM busca “naranjas” y Elasticsearch devuelve refresco de naranja, la experiencia de chat se degrada de la misma manera que lo hace una experiencia de búsqueda.| La ausencia de gobernanza significa que el sistema no puede aplicar la resolución prevista por el comprador.
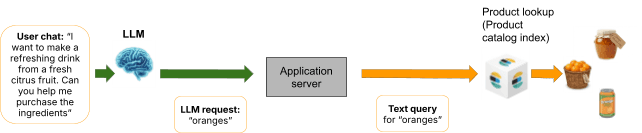
Recuperar valores relevantes que estén dinámicamente basados en la consulta es una alternativa conocida, pero introduce un paso adicional no determinista donde la recuperación en sí puede omitir valores relevantes. Además, esto agrega latencia y complejidad a cada consulta.
La alternativa arquitectónica: desacoplar la intención de la ejecución
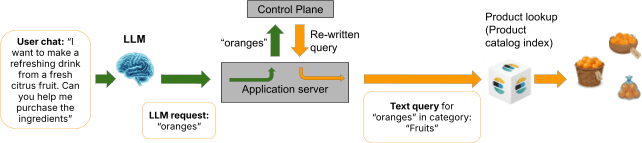
El plano de control regulado descrito en las Partes 1 a 7 ofrece un enfoque totalmente diferente. En vez de que el LLM elabore la consulta final, su papel se reduce a una sola tarea bien delimitada: extraer un texto de intención de búsqueda de la entrada de lenguaje natural del usuario.
El usuario dice: "Estoy buscando zapatos marrones baratos". La función del agente no es generar una consulta de Elasticsearch. Su función es extraer y transmitir la intención de búsqueda (en este caso, algo como "zapatos marrones baratos") al plano de control. Entonces, el plano de control hace lo de siempre: filtra la intención de texto por las políticas almacenadas, compone las políticas coincidentes mediante transformaciones en cascada, resuelve los conflictos de forma determinista y produce una consulta de Elasticsearch controlada.
El LLM nunca ve el mapeo de índice. Nunca sabe sobre tipos de campos, taxonomías de categorías o umbrales de precios. Nunca construye una cláusula de consulta. Opera en el lado del lenguaje natural de un límite arquitectónico que llamamos el espacio aéreo de metadatos, una separación estricta entre el componente probabilístico (el LLM) y la capa de datos estructurados (esquema, políticas y construcción de consultas).
Lo que proporciona el aislamiento de metadatos
- Ceguera de esquema. El LLM no tiene acceso al esquema de la base de datos y, por lo tanto, no puede generar consultas inválidas, alucinar nombres de campo ni ser manipulado para exponer información estructural. El esquema existe solo en el lado determinista del aislamiento.
- Contexto mínimo. En vez de miles de tokens de datos de mapeo, reglas de negocio y taxonomías de categorías, la indicación del LLM contiene solo instrucciones de extracción de persona e intención. Esto reduce drásticamente el costo de tokens, la latencia y la degradación del contexto.
- Ejecución determinista. Cada consulta que llega a Elasticsearch está construida por el plano de control usando plantillas de políticas controladas por humanos, no generadas probabilísticamente por un LLM. La validez sintáctica está garantizada. La corrección semántica se aplica mediante el mismo marco de políticas descrito en las Partes 1 a 6.
- Seguridad por arquitectura. La inyección inmediata deja de ser eficaz desde el punto de vista estructural. Incluso si un usuario manipula al agente para que produzca un texto de intención inusual, ese texto se filtrará por las políticas almacenadas. Si ninguna política coincide, no se genera ninguna consulta. El usuario no puede pedirle al agente que cree una consulta porque el agente no crea consultas. El plano de control lo hace, y el plano de control es determinista.
Cómo se conectan las piezas
El siguiente recorrido muestra cómo el plano de control regulado maneja una consulta mediada por agente.
Paso 1: El usuario habla con el agente
Un comprador que interactúa con un chatbot de comercio electrónico dice: "Estoy buscando chocolate barato, nada con maní."
Paso 2: El agente extrae la intención
La función del LLM es extraer intenciones, no generar consultas. Con un prompt mínimo que le indica identificar la intención del producto, el agente produce un texto de intención de búsqueda: "chocolate barato sin maní".
Esta es una tarea de clasificación sencilla. El LLM no necesita el mapeo de índice, la taxonomía de categorías ni las reglas de precios para realizarlo. Necesita entender el lenguaje natural, que es precisamente la fortaleza de los LLM.
Paso 3: El plano de control regula la consulta
El texto de intención "chocolate barato sin maní" se pasa al plano de control, que lo filtra por el índice de políticas. Tres políticas coinciden:
- La política de "barato" (extrae "barato", aplica un filtro de precio basado en la categoría del producto).
- La política de "chocolate" (limita los resultados a categorías de chocolate).
- La política de negación "sin" (extrae el objetivo de exclusión y aplica un filtro
must_not)
El plano de control aplica estas políticas mediante la misma transformación en cascada descrita en la Parte 3 y la Parte 4: orden de prioridad, resolución de conflictos por campo, seguimiento de frases consumidas. Si una política de “campaña navideña” también está activa, se compone con las políticas del producto exactamente como se describe en Parte 3, la participación del agente no cambia el modelo de gobernanza en absoluto.
Paso 4: Se ejecuta la consulta regulada
El plano de control produce una consulta de Elasticsearch completamente regulada: una búsqueda de “chocolate”, limitada a las categorías adecuadas, con un límite de precio derivado de la política “barato”, un filtro de exclusión para productos que contienen maní y cualquier impulso activo de campaña aplicado. Si la política de “chocolate” también incluye pesos de optimización económica (Parte 7), estos también se aplican. El aumento de margen está establecido en 3.0x porque “chocolate” es una consulta de navegación donde el minorista se beneficia de promover productos de mayor margen. Si el comprador tiene historial de compras (Parte 6), las señales de personalización se superponen. Esta consulta es sintácticamente válida por construcción y semánticamente correcta por diseño de políticas.
Paso 5: Los resultados se envían a través del agente
Los resultados del producto se arrojan al agente, que los presenta de forma conversacional al usuario. El papel del agente en la ruta de retorno es la presentación: formatear resultados, responder preguntas de seguimiento, proporcionar detalles del producto. La recuperación en sí fue regulada, determinista y explicable.
En qué es bueno el agente (y en qué no lo es)
Esta arquitectura aprovecha las fortalezas del LLM y protege al sistema de sus debilidades.
Los LLM sobresalen en la comprensión de la intención del lenguaje natural. “Estoy buscando chocolate barato, nada con maní” es una tarea de comprensión del lenguaje natural, análisis de intención, identificación de referencias de productos, reconocimiento de negación. Los LLM gestionan esto de forma fiable porque es un problema de clasificación, no de generación. La salida es un texto corto de intenciones, no una consulta estructurada y compleja.
A los modelos de lenguaje grande (LLM) les cuesta generar salidas estructuradas con precisión bajo restricciones complejas. La generación de una DSL de consulta de Elasticsearch válida requiere nombres de campo exactos, anidación correcta de cláusulas, tipos de filtro adecuados para cada campo y una aplicación coherente de reglas de negocio en miles de casos límite. Estas son exactamente las propiedades que un sistema determinista impone de forma trivial y que un sistema probabilístico impone de forma poco fiable.
El plano de control regulado coloca cada componente donde corresponde: el LLM en el lado del lenguaje natural, el motor de políticas deterministas en el lado de construcción de consultas, y un límite arquitectónico entre ellos.
La gobernanza limita el alcance del impacto
Esta es la misma información de la Parte 3, extendida al contexto agente. En la Parte 3, observamos que la gobernanza hace que la recuperación semántica sea más segura, ya que reduce el conjunto de candidatos antes de que comience la recuperación. Una búsqueda semántica sobre 500 productos en una categoría regulada es una propuesta muy diferente a una búsqueda semántica sobre 500 000 SKU.
El mismo principio se aplica a las consultas mediadas por agentes. Sin gobernanza, un agente que malinterprete "chocolate barato" podría generar una consulta que realice una búsqueda en todo el catálogo sin restricciones de precio, sin filtro de categoría y sin exclusiones. Con gobernanza, incluso si el agente produce un texto de intención imperfecto, el plano de control restringe la consulta a las políticas que coinciden. El peor caso es que se activen menos políticas, no que una consulta sin límite acceda al catálogo de productos.
La gobernanza reduce el alcance de los errores probabilísticos. Esto es cierto tanto si el componente probabilístico es un modelo de recuperación semántica como un agente LLM.
Políticas sugeridas por LLM: ampliar la cobertura
La Parte 2 presentó la idea de que un LLM puede sugerir nuevas políticas que ingresen en el mismo pipeline Author → Test → Promote que las de autoría humana. En el contexto de agentes, esto se convierte en un ciclo de retroalimentación poderoso.
Un LLM puede analizar registros de consultas, identificar patrones donde el plano de control no tiene una política coincidente (consultas que llegan a la recuperación sin modificaciones) y sugerir nuevas políticas para cubrir esas brechas. Un comerciante revisa cada sugerencia, la prueba y la promueve si produce el comportamiento esperado. El modelo de gobernanza asegura que ninguna política sugerida por LLM llegue a producción sin validación humana.
Con el tiempo, esto crea un ciclo virtuoso: la cobertura de políticas del plano de control se expande, la proporción de consultas que requieren una recuperación sin modificar se reduce, y el sistema se vuelve cada vez más regulado, con cada política auditable, versionada e individualmente reversible.
El patrón general: barreras de seguridad deterministas para sistemas probabilísticos
La arquitectura descrita en este serial, un plano de control determinista situado entre una fuente de entrada probabilística y un sistema de recuperación de datos, no es específica de la búsqueda en el comercio electrónico. El mismo patrón se aplica siempre que un agente de IA necesite interactuar con datos estructurados.
Un agente que consulta una base de datos SQL se enfrenta a los mismos desafíos: exceso de contexto por inyección de esquemas, nombres de columnas alucinados, riesgos de inyección inmediata y selección de valores de alta cardinalidad. Un agente que trabaja con un sistema de gestión de incidencias como Jira, un sistema de gestión de relaciones con los clientes (CRM) como Salesforce o un repositorio de código como GitHub se enfrenta a problemas similares. En todos los casos, la pregunta arquitectónica del núcleo es la misma: ¿Debe el LLM crear la consulta, o debe el LLM extraer la intención y pasarla a una capa determinista que crea la consulta?
El plano de control regulado proporciona una respuesta repetible a esa pregunta. Las políticas son datos. La función del LLM es extraer intenciones. El plano de control se ocupa de desarrollar consultas. El espacio de metadatos los mantiene separados. Y el marco de trabajo (orden de prioridad, resolución de conflictos, transformaciones en cascada, auditabilidad) asegura que la capa determinista sea operacionalmente manejable a medida que aumenta el número de políticas.
Conclusión
Los patrones de gobernanza de búsqueda en comercio electrónico descritos en este serial (políticas como datos, el flujo de trabajo Author → Test → Ascender flujo de trabajo, transformaciones en cascada, resolución de conflictos por campo, coincidencia inversa basada en filtro y respaldo multinivel) se diseñaron para un mundo donde el comerciante redacta políticas y el cliente tipifica consultas. Pero la arquitectura tiene más potencial que su caso de uso inicial.
Cuando la fuente de entrada es un agente de IA en vez de un comprador humano, el plano de control regulado se convierte en la capa de seguridad fundamental entre un sistema probabilístico y un almacén de datos de producción. Ofrece las garantías determinísticas (validez sintáctica, corrección semántica, auditabilidad y seguridad) que necesitan los sistemas empresariales y que los modelos de lenguaje grande (LLM) no pueden ofrecer por sí solos.
El plano de control determinista no reemplaza al agente de IA. Hace que el agente de IA sea seguro para desplegar.
Pon en práctica la búsqueda gobernada de comercio electrónico
La arquitectura del plano de control regulado descrita en este serial, desde el paradigma de política como datos hasta la búsqueda basada en filtro, personalización, optimización económica y el aislamiento de agente, fue diseñada y desarrollada por Elastic Services Engineering. Todos los patrones que se describen en esta serie provienen de un sistema operativo creado y validado con catálogos de productos a escala empresarial.
Si tu equipo está desarrollando experiencias de búsqueda impulsadas por IA y necesita límites deterministas para consultas mediadas por agentes, o si quieres implementar una arquitectura de búsqueda regulada y editable por el negocio en Elasticsearch, Elastic Professional Services puede acelerar tu implementación. Ponte en contacto con Elastic Professional Services.
Únete a la discusión
¿Tienes preguntas sobre la gestión de búsquedas, las estrategias de recuperación o la arquitectura de búsqueda en el comercio electrónico? Únete a la conversación general de la comunidad de Elastic.
Contenido relacionado

11 de mayo de 2026
Personalización de la búsqueda en comercio electrónico: integración del historial de compras y cohortes de usuarios
Aprende a crear una experiencia de búsqueda personalizada en Elasticsearch sin infringir la gobernanza. En esta publicación se explica cómo destacar los productos que un comprador ha adquirido previamente y cómo activar políticas específicas de cohortes basadas en perfiles de usuario.

4 de mayo de 2026
Percolador de Elasticsearch para la gobernanza de búsquedas en comercio electrónico: traducir búsquedas ambiguas en estrategias de recuperación controladas
Aprende a usar el percolador de Elasticsearch para implementar la gobernanza de búsquedas. En este blog, describimos los patrones necesarios para crear un motor de políticas regulado en producción y establecer una estrategia de recuperación controlada.

1 de mayo de 2026
Creación de un plano de control para gestionar las búsquedas en el comercio electrónico
Cómo construir un plano de control gobernado para el comercio electrónico que integre políticas de búsqueda conflictivas en un solo plan de ejecución (sin cambios de código).

24 de abril de 2026
Reindexación de flujos de datos debido a conflictos de mapping
Descubre cómo solucionar los conflictos de mapeo de Elasticsearch reindexando los flujos de datos. Este blog explica el proceso de reindexación y la verificación del mapeo correcto.

9 de abril de 2026
Por qué la búsqueda en el comercio electrónico necesita gobernanza
Conoce por qué la búsqueda de ecommerce queda corta sin gobernanza, y cómo una capa de control garantiza resultados predecibles e impulsados por la intención, a la vez que mejora la recuperación.