Teile 1 bis 7 dieser Serie beschrieben eine gesteuerte Steuerungsebene für E-Commerce-Suchen. Ein Nutzer tippt eine Abfrage ein. Die Steuerungsebene klassifiziert die Absicht, setzt geschäftliche Einschränkungen durch, löst Vorgabenkonflikte und leitet zur entsprechenden Abrufstrategie weiter, und das alles, bevor der Produktkatalog überhaupt abgefragt wird. Die gesamte Architektur geht davon aus, dass die Eingabe eine von einem menschlichen Käufer eingegebene Suchzeichenfolge ist.
Dieser letzte Beitrag fragt: Was ändert sich, wenn die Eingabe stattdessen von einem KI-Agenten kommt?
Die Antwort ist, dass sich die Architektur nicht ändert, aber die Einsätze schon. Jede Eigenschaft der beherrschten Kontrollebene, die für von Menschen verfasste Abfragen von Bedeutung ist, ist umso wichtiger, wenn der vorgelagerte Entscheidungsträger ein großes Sprachmodell (LLM) ist. Determinismus, Überprüfbarkeit, Konfliktlösung und Zwangsdurchsetzung werden zu kritischen Leitplanken anstatt zu betrieblichen Annehmlichkeiten, da das System, das die Eingabe produziert, von Natur aus probabilistisch ist.
Das agentische Suchproblem
Der gängigste Ansatz für KI-gesteuerte Suche ist unkompliziert: Man gibt dem LLM das Datenbankschema, stellt Geschäftsregeln in der Eingabeaufforderung bereit und lässt den Agenten die Abfrage direkt generieren.
Für einen E-Commerce-Chatbot bedeutet dies, die Elasticsearch-Index-Mapping, Feldtypen, Kategorietaxonomien, Preislogik und Geschäftsbeschränkungen in das Kontextfenster des Agenten zu injizieren und dann das LLM zu bitten, natürliche Sprache in gültige Elasticsearch Query DSL zu übersetzen. Das LLM wird zum Abfrageautor.
Dieser Ansatz funktioniert in Demos. Es scheitert aus vier Gründen in der Produktion.
Kontextaufblähung
Ein Enterprise-E-Commerce-Index-Mapping ist kein triviales Dokument. Felddefinitionen, verschachtelte Objekte, Mehrfeldkonfigurationen und Analysatoreinstellungen können auf Tausende von Token ausgeführt werden, bevor Geschäftslogik hinzugefügt wird. Zusätzlich zum Mapping benötigt der Agent Kategorientaxonomien (die im Enterprise-E-Commerce Zehntausende von Werten enthalten können), Preisregeln, Markenhierarchien, Zulassungsbeschränkungen und Kampagnenlogik.
Das Ergebnis ist ein Kontextfenster, das von strukturellen Metadaten dominiert wird, anstatt von der eigentlichen Absicht des Nutzers. Dies erhöht die Latenzzeit, steigert die Token-Kosten und verschlechtert die Fähigkeit des LLM, Anweisungen zu befolgen, wenn der Kontext wächst. Dies ist ein gut dokumentiertes Phänomen, das manchmal als Kontextverfall bezeichnet wird: Je länger der Prompt wird, desto schwächer wird die Aufmerksamkeit des Modells für eine bestimmte Anweisung.
Probabilistische Halluzination
LLMs generieren Abfragen basierend auf Mustern in ihren Trainingsdaten und dem bereitgestellten Kontext. Wenn das Modell aufgefordert wird, Elasticsearch Query DSL zu generieren, kann es Feldnamen erzeugen, die nicht existieren, syntaktisch ungültige Abfrageklauseln erstellen, Filtertypen auf die falschen Feldtypen anwenden oder Abfragen erzeugen, die zwar syntaktisch gültig, aber semantisch falsch sind und Ergebnisse liefern, die nicht der Absicht des Nutzers entsprechen.
Der BIRD-Benchmark für Text-to-SQL von Google Cloud veranschaulicht die Grenzen dieses Ansatzes. Googles hochmodernes Single-Model-Ergebnis erreichte eine Genauigkeit zwischen 70 % und 80 %, was bedeutet, dass fast jede vierte generierte Abfrage falsch war. Dies gilt für SQL, das weitaus stärker standardisiert ist als die Elasticsearch Query DSL. Die Fehlerquote für LLM-generierte Elasticsearch-Abfragen in einer echten Produktionsumgebung mit komplexen Mappings und geschäftsspezifischer Semantik wäre wahrscheinlich höher.
Bei einem umsatzkritischen E-Commerce-System ist eine Fehlerrate von einem Viertel der Abfragen kein Optimierungsproblem, das iterativ gelöst werden kann. Es ist eine architektonische Einschränkung des Ansatzes.
Die Sicherheitslücke
Wenn das LLM Zugriff auf das Datenbankschema hat und als Abfrageautor fungiert, ist das System anfällig für indirekte Prompt-Injektion. Ein Nutzer, der mit einem E-Commerce-Chatbot interagiert, kann Eingaben erstellen, um den Agenten so zu manipulieren, dass er unbeabsichtigte Abfragen generiert.
Dies ist kein theoretisches Risiko. Prompt-Injektion ist eine der am aktivsten erforschten Angriffsflächen in eingesetzten LLM-Systemen. Das grundlegende Problem ist, dass es beim Erstellen der Abfrage durch den Agent keine strukturelle Grenze zwischen Nutzerintention und Abfrageausführung gibt. Das LLM interpretiert gleichzeitig die Nutzerabfrage und erstellt die Datenbankoperation. Jede Manipulation der ersten wirkt sich direkt auf die zweite aus.
Fehler beim Skalieren mit hoher Kardinalität
Bestimmte E-Commerce-Felder haben extreme Kardinalität. Ein Produktkatalog kann 17.000 Kategoriewerte, Tausende von Markennamen und Hunderte von Attributkombinationen enthalten. Standardmäßige agentische Workflows erfordern, diese Werte in den Kontext einzufügen, damit das LLM beim Erstellen einer Abfrage den richtigen auswählen kann.
Dies führt zu einem unmöglichen Kompromiss: Entweder werden alle möglichen Werte eingefügt (was enorm viel Kontext verbraucht und die Leistung mindert), es wird nur eine Teilmenge eingefügt (und man muss in Kauf nehmen, dass der Agent nicht auf Werte außerhalb dieser Teilmenge zugreifen kann), oder es wird auf eine unkontrollierte Suche zurückgegriffen. Dies knüpft direkt an das Kernproblem aus Teil 1 an: Wenn das LLM nach „Orangen“ sucht und Elasticsearch Orangenlimonade zurückgibt, verschlechtert sich das Chat-Erlebnis auf die gleiche Weise wie das Sucherlebnis. Das Fehlen von Governance bedeutet, dass das System die beabsichtigte Lösung des Käufers nicht durchsetzen kann.
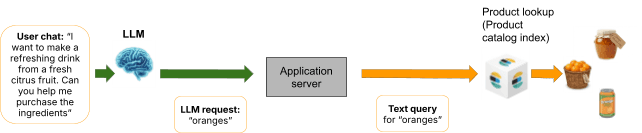
Das dynamische Abrufen relevanter Werte auf der Grundlage der Abfrage ist eine bekannte Alternative, die jedoch einen zusätzlichen, nicht-deterministischen Schritt einführt, bei dem die Abfrage selbst relevante Werte verfehlen kann. Zusätzlich erhöht dies die Latenz und Komplexität jeder Abfrage.
Die architektonische Alternative: Entkopplung von Absicht und Ausführung
Die in den Teilen 1 bis 7 beschriebene gesteuerte Kontrollebene bietet einen grundlegend anderen Ansatz. Anstatt dass das LLM die endgültige Abfrage erstellt, wird die Rolle des LLM auf eine einzige, klar abgegrenzte Aufgabe reduziert: das Extrahieren einer Suchabsichts-Zeichenfolge aus der natürlichen Spracheingabe des Nutzers.
Der Nutzer sagt: „Ich suche günstige braune Schuhe.“ Die Aufgabe des Agenten besteht nicht darin, eine Elasticsearch-Abfrage zu generieren. Er soll die Suchabsicht (in diesem Fall etwa „billige braune Schuhe“) extrahieren und an die Steuerungsebene weiterleiten. Die Steuerebene tut dann das, was sie immer getan hat: Sie perkoliert die Absichtszeichenkette gegen gespeicherte Richtlinien, erstellt passende Richtlinien durch kaskadierende Transformationen, löst Konflikte deterministisch und erzeugt eine gesteuerte Elasticsearch-Abfrage.
Das LLM sieht das Index-Mapping nie. Es weiß nie etwas über Feldtypen, Kategorientaxonomien oder Preisschwellenwerte. Es konstruiert niemals eine Abfrageklausel. Es läuft auf der natürlichen Sprachseite einer architektonischen Grenze, die wir als Metadaten-Luftlücke bezeichnen, eine strikte Trennung zwischen der probabilistischen Komponente (dem LLM) und der strukturierten Datenschicht (Schema, Richtlinien und Abfragekonstruktion).
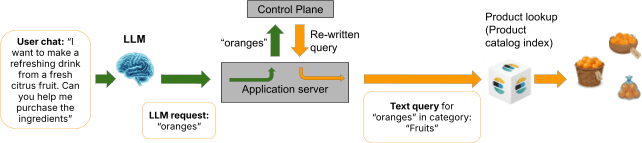
Was der Metadaten-Air-Gap bietet
- Schemablindheit. Das LLM hat keinen Zugriff auf das Datenbankschema und kann daher weder ungültige Abfragen generieren, Feldnamen erfinden noch so manipuliert werden, dass strukturelle Informationen offengelegt werden. Das Schema existiert nur auf der deterministischen Seite der Luftlücke.
- Minimaler Kontext. Anstatt Tausender Token von Mapping-Daten, Geschäftsregeln und Kategorie-Taxonomien enthält der Prompt des LLM nur eine Persona und Anweisungen zur Intent-Extraktion. Dadurch werden die Token-Kosten, die Latenzzeit und der Kontextwechsel drastisch reduziert.
- Deterministische Ausführung. Jede Abfrage, die Elasticsearch erreicht, wird von der Kontrollebene mit menschengeprüften Vorgabenvorlagen erstellt und nicht probabilistisch von einem LLM generiert. Syntaktische Gültigkeit ist garantiert. Die semantische Korrektheit wird durch dasselbe Vorgaben-Framework sichergestellt, das in den Teilen 1 bis 6 beschrieben wurde.
- Sicherheit durch Architektur. Prompt-Injektion wird strukturell unwirksam. Selbst wenn ein Nutzer den Agenten dazu manipuliert, eine ungewöhnliche Intent-Zeichenfolge zu erzeugen, wird diese Zeichenfolge gegen gespeicherte Richtlinien perkoliert. Wenn keine Vorgabe übereinstimmt, wird keine Abfrage generiert. Der Nutzer kann den Agenten nicht anweisen, eine Abfrage zu erstellen, da der Agent keine Abfragen erstellt. Die Steuerungsebene tut dies, und die Steuerungsebene ist deterministisch.
Wie die einzelnen Teile zusammenpassen
Die folgende exemplarische Vorgehensweise zeigt, wie die kontrollierte Steuerungsebene eine agentenvermittelte Abfrage handhabt.
Schritt 1: Der Nutzer spricht mit dem Agenten
Ein Kunde, der mit einem E-Commerce-Chatbot interagiert, sagt: „Ich suche günstige Schokolade, aber ohne Erdnüsse.“
Schritt 2: Der Agent extrahiert die Absicht
Die Rolle des LLM besteht in der Absichtsextraktion, nicht in der Abfragegenerierung. Auf Basis eines minimalen Prompts, der den Agenten anweist, die Produktabsicht zu ermitteln, erzeugt er eine Suchabfrage: „billige Schokolade ohne Erdnüsse“.
Dies ist eine einfache Klassifizierungsaufgabe. Das LLM braucht nicht das Index-Mapping, die Kategorie-Taxonomie oder die Preisregeln, um es auszuführen. Es muss die natürliche Sprache verstehen, und genau darin sind LLMs gut.
Schritt 3: Die Kontrollebene steuert die Abfrage
Die Absichtszeichenfolge „billige Schokolade ohne Erdnüsse“ wird an die Steuerungsebene weitergeleitet, die sie mit dem Vorgaben-Index perkolieren. Drei Vorgaben stimmen überein:
- Die Vorgabe „billig“ (extrahiert „billig“ und wendet einen Preisfilter basierend auf der Produktkategorie an).
- Die Vorgabe „Schokolade“ (beschränkt die Ergebnisse auf Schokoladenkategorien).
- Die Vorgabe „ohne“ (Negation; extrahiert das Ausschlussziel und wendet einen
must_not-Filter an)
Die Steuerungsebene wendet diese Vorgaben durch dieselbe kaskadierende Transformation an, die in Teil 3 und Teil 4 beschrieben ist: Prioritätsreihenfolge, Konfliktlösung pro Feld, Verfolgung verbrauchter Phrasen. Wenn auch eine „Weihnachtskampagne“-Vorgabe aktiv ist, setzt sie sich mit den Produktvorgaben genau so zusammen, wie in Teil 3 beschrieben. Die Beteiligung des Agenten ändert das Governance-Modell überhaupt nicht.
Schritt 4: Die gesteuerte Abfrage wird ausgeführt
Die Steuerungsebene erzeugt eine vollständig gesteuerte Elasticsearch-Abfrage: eine Suche nach „Schokolade“, beschränkt auf die entsprechenden Kategorien, mit einer Preisobergrenze, die sich aus der Vorgabe „billig“ ergibt, einem Ausschlussfilter für erdnusshaltige Produkte und der Anwendung etwaiger aktiver Kampagnen-Boosts. Wenn die Vorgabe „Schokolade“ auch wirtschaftliche Optimierungsgewichte (Teil 7) einschließt, werden diese ebenfalls angewendet. Der Margenaufschlag ist auf 3,0x gesetzt, da „Schokolade“ eine Browsing-Abfrage ist, bei der der Einzelhändler von der Förderung von Produkten mit höherer Marge profitiert. Wenn der Käufer eine Kaufhistorie (Teil 6) hat, werden Personalisierungssignale darüber geschichtet. Diese Abfrage ist syntaktisch gültig durch Konstruktion und semantisch korrekt durch Vorgabendesign.
Schritt 5: Rückgabe der Ergebnisse durch den Agenten
Die Produktergebnisse werden an den Agenten zurückgegeben, der sie dem Nutzer im Dialog präsentiert. Die Rolle des Agenten auf dem Rückgabepfad ist die Präsentation: Formatierung der Ergebnisse, Beantwortung von Folgefragen, Bereitstellung von Produktdetails. Der Abruf selbst war geregelt, deterministisch und erklärbar.
Wozu der Agent gut ist (und wozu nicht)
Diese Architektur nutzt die Stärken des LLM und schützt das System vor seinen Schwächen.
LLMs sind hervorragend darin, die Absicht der natürlichen Sprache zu verstehen. „Ich suche nach billiger Schokolade, nichts mit Erdnüssen“ ist eine Aufgabe des natürlichen Sprachverständnisses, bei der die Absicht analysiert, Produktreferenzen identifiziert und Negation erkannt wird. LLMs handhaben dies zuverlässig, da es sich um ein Klassifizierungsproblem handelt, nicht um ein Generierungsproblem. Die Ausgabe ist eine kurze Absichtszeichenfolge, keine komplexe strukturierte Abfrage.
LLMs haben Schwierigkeiten, unter komplexen Rahmenbedingungen präzise strukturierten Ausgang zu erzielen. Die Erstellung gültiger Elasticsearch-Abfrage-DSL erfordert exakte Feldnamen, korrekte Klauselverschachtelung, geeignete Filtertypen für jedes Feld und eine konsistente Anwendung von Geschäftsregeln über Tausende von Randfällen. Dies sind genau die Eigenschaften, die ein deterministisches System trivialerweise erzwingt und die ein probabilistisches System unzuverlässig erzwingt.
Die gesteuerte Steuerungsebene platziert jede Komponente an ihrem Platz: das LLM auf der Seite der natürlichen Sprache, die deterministische Vorgaben-Engine auf der Seite der Abfragekonstruktion, und eine architektonische Grenze zwischen ihnen.
Die Governance begrenzt den Explosionsradius.
Dies ist derselbe Einblick aus Teil 3, erweitert auf den agentischen Kontext. In Teil 3 haben wir festgestellt, dass Governance die semantische Suche sicherer macht, indem sie die Kandidatenmenge vor Beginn der Suche eingrenzt. Eine semantische Suche über 500 Produkte in einer regulierten Kategorie ist eine ganz andere Sache als eine semantische Suche über 500.000 SKUs.
Das gleiche Prinzip gilt für agentenvermittelte Abfragen. Ohne entsprechende Steuerung könnte ein Agent, der „billige Schokolade“ falsch interpretiert, eine Abfrage generieren, die den gesamten Katalog ohne Preisbeschränkung, ohne Kategoriefilter und ohne Ausschlüsse durchsucht. Selbst wenn der Agent eine unvollständige Absichtszeichenfolge abgibt, schränkt die Kontrollebene die Abfrage auf die Richtlinien ein, die übereinstimmen. Im schlimmsten Fall werden weniger Richtlinien ausgelöst, nicht dass eine unbegrenzte Abfrage den Produktkatalog trifft.
Governance engt den Explosionsradius von probabilistischen Fehlern ein. Dies gilt unabhängig davon, ob es sich bei der probabilistischen Komponente um ein semantisches Retrieval-Modell oder einen LLM-Agenten handelt.
LLM-vorgeschlagene Richtlinien: Erweiterung der Abdeckung
In Teil 2 wurde die Idee eingeführt, dass ein LLM neue Richtlinien vorschlagen kann, die in dieselbe Author → Test → Promote-Pipeline aufgenommen werden wie von Menschen verfasste. Im Agentenkontext wird das zu einer starken Feedback-Schleife.
Ein LLM kann Abfrageprotokolle analysieren, Muster identifizieren, bei denen die Kontrollebene keine Matching-Vorgabe hat (Abfragen, die nicht zur unveränderten Abruf gelangen), und neue Vorgaben vorschlagen, um diese Lücken zu schließen. Ein Merchandiser prüft jeden Vorschlag, testet ihn und fördert ihn, wenn er das erwartete Verhalten hervorruft. Das Governance-Modell stellt sicher, dass keine von LLM vorgeschlagene Vorgabe ohne menschliche Validierung in die Produktion gelangt.
Im Laufe der Zeit entsteht dadurch ein positiver Kreislauf: Die Vorgabenabdeckung der Steuerungsebene erweitert sich, der Anteil der Abfragen, die eine unveränderte Abrufung erfordern, schrumpft, und das System wird zunehmend geregelt, wobei jede Vorgabe überprüfbar, versioniert und individuell umkehrbar ist.
Das breitere Muster: Deterministische Leitplanken für probabilistische Systeme
Die in dieser Serie beschriebene Architektur, eine deterministische Kontrollebene, die zwischen einer probabilistischen Eingangsquelle und einem Datenabrufsystem angesiedelt ist, ist nicht spezifisch für die E-Commerce-Suche. Das gleiche Muster gilt überall dort, wo ein KI-Agent mit strukturierten Daten interagieren muss.
Ein Agent, der eine SQL-Datenbank abfragt, steht vor denselben Herausforderungen: Kontextaufblähung durch Schema-Injektion, halluzinierte Spaltennamen, Risiken der Prompt-Injektion und Auswahl von Werten mit hoher Kardinalität. Ein Agent, der mit einem Ticketsystem wie Jira, einem Customer-Relationship-Management-System (CRM) wie Salesforce oder einem Code-Repository wie GitHub interagiert, steht vor ähnlichen Problemen. In jedem Fall ist die Kernarchitekturfrage dieselbe: Sollte das LLM die Abfrage erstellen, oder sollte das LLM die Absicht extrahieren und an eine deterministische Schicht weitergeben, die die Abfrage erstellt?
Die geregelte Kontrollebene bietet eine wiederholbare Antwort auf diese Frage. Richtlinien sind Daten. Die Extraktion von Absichten ist die Aufgabe des LLM. Die Abfragekonstruktion ist die Aufgabe der Steuerungsebene. Die Metadaten-Luftlücke hält sie getrennt. Und das Governance-Framework (Priorisierungsreihenfolge, Konfliktlösung, kaskadierende Transformationen, Überprüfbarkeit) stellt sicher, dass die deterministische Schicht bei wachsender Anzahl von Richtlinien operationell handhabbar bleibt.
Fazit
Die in dieser Reihe beschriebenen E-Commerce-Suchsteuerungsmuster (Richtlinien als Daten, Autor → Test → Workflow-Förderung, kaskadierende Transformationen, Konfliktlösung pro Feld, Percolator-basiertes Reverse Matching und mehrstufiges Fallback) wurden für eine Welt entwickelt, in der ein Händler Richtlinien erstellt und ein Käufer Abfragen eingibt. Aber die Architektur kann viel mehr ermöglichen als ihr ursprünglicher Anwendungsfall.
Wenn die Eingabequelle ein KI-Agent anstelle eines menschlichen Käufers ist, wird die gesteuerte Kontrollebene zur kritischen Sicherheitsschicht zwischen einem probabilistischen System und einem Produktionsdatenspeicher. Es bietet die deterministischen Garantien (syntaktische Gültigkeit, semantische Korrektheit, Überprüfbarkeit und Sicherheit), die Unternehmenssysteme benötigen und die LLMs allein nicht bieten können.
Die deterministische Steuerungsebene ersetzt den KI-Agenten nicht. Dadurch kann der KI-Agent sicher eingesetzt werden.
Setzen Sie die reglementierte E-Commerce-Suche in die Praxis um
Die in dieser Serie beschriebene Architektur der Steuerebene, vom Paradigma der Vorgaben als Daten über die perkolatorbasierte Suche bis hin zu Personalisierung, wirtschaftlicher Optimierung und dem agentenbasierten Luftraum, wurde von Elastic Services Engineering entwickelt und gebaut. Jedes in dieser Serie beschriebene Muster stammt aus einem funktionierenden System, das anhand von Produktkatalogen auf Unternehmensebene erstellt und validiert wurde.
Wenn Ihr Team KI-gestützte Sucherlebnisse entwickelt und deterministische Leitplanken für agentenvermittelte Abfragen benötigt, oder wenn Sie eine kontrollierte, vom Unternehmen editierbare Sucharchitektur auf Elasticsearch implementieren möchten, können die Elastic Professional Services Ihre Implementierung beschleunigen. Wenden Sie sich an Elastic Professional Services.
Nehmen Sie an der Diskussion teil
Haben Sie Fragen zur Suchsteuerung, zu Abrufstrategien oder zur Sucharchitektur im E-Commerce? Nehmen Sie an der Diskussion der Elastic-Community teil.
Zugehörige Inhalte

11. Mai 2026
Personalisierung der E-Commerce-Suche: Integration von Kaufverlauf und Nutzerkohorten
Erfahren Sie, wie Sie in Elasticsearch ein personalisiertes E-Commerce-Sucherlebnis schaffen, ohne gegen die Governance-Richtlinien zu verstoßen. In diesem Beitrag erfahren Sie, wie Sie Produkte hervorheben können, die ein Kunde bereits gekauft hat, und wie Sie kohortenspezifische Richtlinien auf der Grundlage von Nutzerprofilen aktivieren können.

4. Mai 2026
Elasticsearch-Perkolator zur Steuerung der Suche im E-Commerce: Übersetzung mehrdeutiger Anfragen in kontrollierte Abrufstrategien
Erfahren Sie, wie Sie den Elasticsearch-Perkolator zur Implementierung der Suchsteuerung verwenden. In diesem Blog skizzieren wir die Muster, die erforderlich sind, um eine geregelte Policy-Engine in der Produktion zu erstellen und eine kontrollierte Abrufstrategie zu entwickeln.

1. Mai 2026
Aufbau einer Steuerungsebene zur Kontrolle der E-Commerce-Suche
Wie Sie eine kontrollierte Steuerungsebene für den elektronischen Handel aufbauen, die widersprüchliche Suchrichtlinien in einem einzigen Ausführungsplan zusammenfasst (ohne Codeänderungen).

24. April 2026
Neuindizierung von Datenströmen aufgrund von Mapping-Konflikten
Erfahren Sie, wie Sie Elasticsearch-Mapping-Konflikte durch Neuindizierung von Datenströmen beheben können. Dieser Blog erklärt den Neuindizierungsprozess und wie Sie sicherstellen, dass neue Daten korrekt zugeordnet werden.

9. April 2026
Warum die E-Commerce-Suche Governance benötigt
Erfahren Sie, warum E-Commerce-Suche ohne Governance unzureichend ist und wie eine Kontrollschicht vorhersehbare und absichtsgesteuerte Ergebnisse gewährleistet und damit die Suche verbessert.