In Teil 1 und Teil 2 dieser Serie wurde dargelegt, warum die E-Commerce-Suche eine Steuerungsebene benötigt, eine Entscheidungsebene zwischen der Abfrage des Benutzers und der Suchmaschine, die die Absicht klassifiziert, Einschränkungen durchsetzt und zur richtigen Suchstrategie weiterleitet (z. B. BM25, semantisch, hybrid). In diesem Beitrag wird gezeigt, wie diese Ebene mit Hilfe eines einfachen architektonischen Primitivs aufgebaut werden kann, bei dem die Richtlinien für die Abfrageinterpretation als Dokumente gespeichert und zur Abfragezeit über ein schnelles Reverse Matching abgerufen werden. Da neue Abrufrichtlinien (z. B. „Marke X fördern“ oder „nur Kategorie Y anzeigen“) keine Codeänderungen erfordern, ist das Ergebnis eine Routing-Schicht, die stabil bleibt, während sich die Richtlinien weiterentwickeln, und die die Abrufmaschinen in Umgebungen mit hohem Risiko sicher macht. Wenn Sie das Endergebnis dieser Architektur sehen möchten, bevor Sie weiterlesen, sehen Sie sich dieses Video an: Fixing Search Relevance in Seconds: Introducing PRISM.
Warum die Interpretation von Abfragen oft zur Herausforderung wird
Die Speicherung von Richtlinien als Code (if/else-Blöcke in der Anwendungsschicht) erzeugt zehntausende Zeilen fehleranfälliger Logik, die kein Indexieren für einen effizienten Richtlinienabruf zur Abfragezeit bietet. Die Iteration ist langsam (eine einzelne Änderung des Verhaltens von Abfragen kann einen sechswöchigen Deployment-Zyklus erfordern), die Verantwortlichkeit ist unklar (warum haben sich die Ergebnisse geändert?), und Geschäftsnutzer können das Suchverhalten ohne technische Einbindung nicht ändern. Dies wird auf der linken Seite des folgenden Bildes gezeigt::

Das Speichern von Richtlinien als Daten in einem Elasticsearch-Index ist auf der rechten Seite des obigen Bildes dargestellt. Dieser Ansatz löst alle Probleme, die mit der fest codierten Abfrage-Auflösungslogik verbunden sind. Allerdings benötigen Sie dafür eine Möglichkeit, schnell zu ermitteln, welche Richtlinien mit der Nutzerabfrage übereinstimmen und wie Konflikte gelöst werden sollten. Hier kommt die kontrollierte Steuerungsebene ins Spiel.
Muster der Steuerungsebene
Eine kontrollierte Steuerungsebene befindet sich zwischen der rohen Nutzerabfrage und dem Elasticsearch-Abruf. Sie empfängt den Nutzertext als Eingabe und gibt einen Ausführungsplan aus, der Filter, Boosts und Entscheidungen zur Weiterleitung der Suchergebnisse enthält.
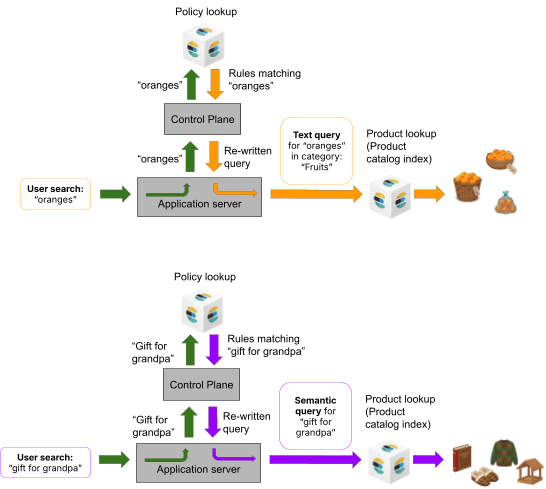
Eine Pipeline für die Steuerungsebene besteht aus:
- Nutzerabfrage: Ein Nutzer gibt eine Zeichenfolge ein, wonach er sucht, zum Beispiel „Orangen“ oder „Geschenk für Opa“.
- Richtliniensuche: Ordnen Sie die Nutzerabfrage dem Richtlinienindex zu.
- Übereinstimmende Richtlinien zurückgeben: Richtlinien, die der Nutzerabfrage entsprechen, werden aus dem Richtlinienindex zurückgegeben.
- Richtlinienanwendung: Die Steuerungsebene analysiert diese zurückgegebenen Richtlinien und fügt übereinstimmende Richtlinien zu einem einzigen kohärenten Ausführungsplan zusammen, der Filter, Boosts, Überschreibungen und Leitplanken umfasst und die geeignete Abrufmethode anwendet (z. B. lexikalisches Abrufen, semantisches Abrufen oder einen hybriden Ansatz).
- Ausführung: Die modifizierte intent-bewusste Elasticsearch-Abfrage wird an die Anwendung weitergegeben, um sie gegen einen Produktkatalogindex auszuführen.
- Erklärung (optional): Zusätzlich zur Erstellung einer Abfrage, die geschäfts- und absichtsorientierte Ergebnisse liefert, bietet die Steuerungsebene eine optionale Nutzlast zur Erklärbarkeit, um zu zeigen, welche Richtlinien ausgelöst und wie sie kombiniert wurden.
Um herauszufinden, welche Richtlinien für die Suchzeichenkette eines Nutzers angewendet werden sollten, ist ein schnelles, rückwärts abgestimmtes Primitiv erforderlich, das wir mit der Perkolator-Abfrage lösen. Nach dem Abrufen relevanter Richtlinien erfordert die Kombination mehrerer übereinstimmender Richtlinien zu einem einheitlichen Ausführungsplan ein Framework zur Beurteilung: Prioritäten, Konfliktstrategien, die Verfolgung verbrauchter Phrasen und kaskadierende Transformationen, die Richtlinien in einer Sequenz anstatt unabhängig voneinander anwenden. Darüber hinaus muss die am besten geeignete Abruftechnologie ausgewählt werden (zum Beispiel BM25 für „Orangen“ versus semantische Suche für „Geschenk für Opa“).
Richtliniensuche: Überprüfung der Abfrage vor der Produktsuche
Wenn ein Kunde eine Abfrage eingibt, sendet ein Suchsystem mit einer kontrollierten Steuerungsebene diese Abfrage nicht direkt, um sie gegen den Produktkatalog auszuführen. Zunächst wird die Abfrage gegen eine Reihe gespeicherter Richtlinien geprüft und modifiziert, um die Absicht der Abfrage und die Geschäftsprioritäten widerzuspiegeln.
Richtlinienstruktur
Jede Richtlinie ist ein einfaches Dokument, das zwei Dinge definiert:
- Übereinstimmungskriterien: Welcher Abfragetext dazu führen sollte, dass diese Richtlinie ausgelöst wird. Dies kann eine exakte Phrase, ein einzelnes Wort, ein Muster oder eine Kombination sein.
- Aktion: Was tun, wenn die Richtlinie ausgelöst wird. Dies könnte das Anwenden eines Kategorienfilters, das Ausschließen von Produkten, das Extrahieren einer Preisbeschränkung oder die Änderung der Abrufstrategie sein.
Das System findet alle passenden Richtlinien, setzt sie zu einem Ausführungsplan zusammen und führt erst dann die Produktsuche durch. Zusammengenommen wirken die Richtlinien wie ein sachkundiger Verkäufer, der versteht, was Sie suchen, und Sie zum richtigen Regal führt.
Das Richtlinienmuster
In den ersten Artikeln dieser Reihe wurden Beispiele für Richtlinien in Aktion vorgestellt: „Orangen" werden auf die Kategorie Obst und Gemüse beschränkt, „ohne Erdnüsse" als Ausschluss behandelt und „Geschenk für Opa" an die semantische Suche weitergeleitet. Der architektonische Kernpunkt ist, dass in jedem Fall die Abfrage anhand gespeicherter Richtlinien überprüft wird, bevor die Produktsuche beginnt. Die Richtlinien bestimmen, welche Einschränkungen angewendet werden, welcher Text geändert und welche Abrufstrategie verwendet werden soll. Die Abfrage gegen den Produktkatalog erfolgt, nachdem die Richtlinien angewendet wurden und eine neu geschriebene Abfrage erstellt wurde.
Warum dies schnell ist
Ein E-Commerce-System für Unternehmen kann Millionen von Produkten enthalten, aber nur Hunderte oder Tausende von Richtlinien. Der Suchschritt nach Richtlinien durchsucht einen kleinen kuratierten Index, nicht den vollständigen Produktkatalog, und erfolgt daher schnell. Da Richtlinien als Daten in einem eigenen Index gespeichert werden, müssen Händler, die eine neue Richtlinie hinzufügen, gar nicht erst den Anwendungscode berühren, und Techniker, die für die Optimierung der Produktsuche zuständig sind, kommen nicht mit dem Richtlinienindex in Berührung. Beide Probleme entwickeln sich unabhängig voneinander.
Die obigen Beispiele beschreiben, was konzeptionell geschieht. Unter der Haube wird die Richtliniensuche mit dem Elasticsearch-Perkolator-Abfragetyp implementiert, der speziell für dieses Muster entwickelt wurde: das Abgleichen eingehender Texte mit einer Reihe gespeicherter Abfragen. Teil 4 dieser Reihe bietet einen praktischen eingehenden Einblick in die Perkolator-Implementierung, einschließlich Index-Mappings, Grenzmarkern und von Highlights gesteuerter Phrasenverfolgung. Nachdem wir uns in Teil 4 eingehend mit dem Lookup-Mechanismus befasst haben, wollen wir uns nun der Frage zuwenden, was ein Richtliniendokument eigentlich enthält und wie die Steuerungsebene mehrere Richtlinien zu einem einzigen Ausführungsplan zusammensetzt.
Beispielrichtlinien
Nachdem wir nun erfahren haben, was Richtlinien konzeptionell bewirken, schauen wir uns an, was sie tatsächlich enthalten. Die beiden nachfolgenden Richtlinien wurden so gestaltet, dass sie absichtlich in Konflikt zueinander stehen. Dies soll das in den darauffolgenden Abschnitten beschriebene Konfliktlösungssystem veranschaulichen.
Günstige Schokolade
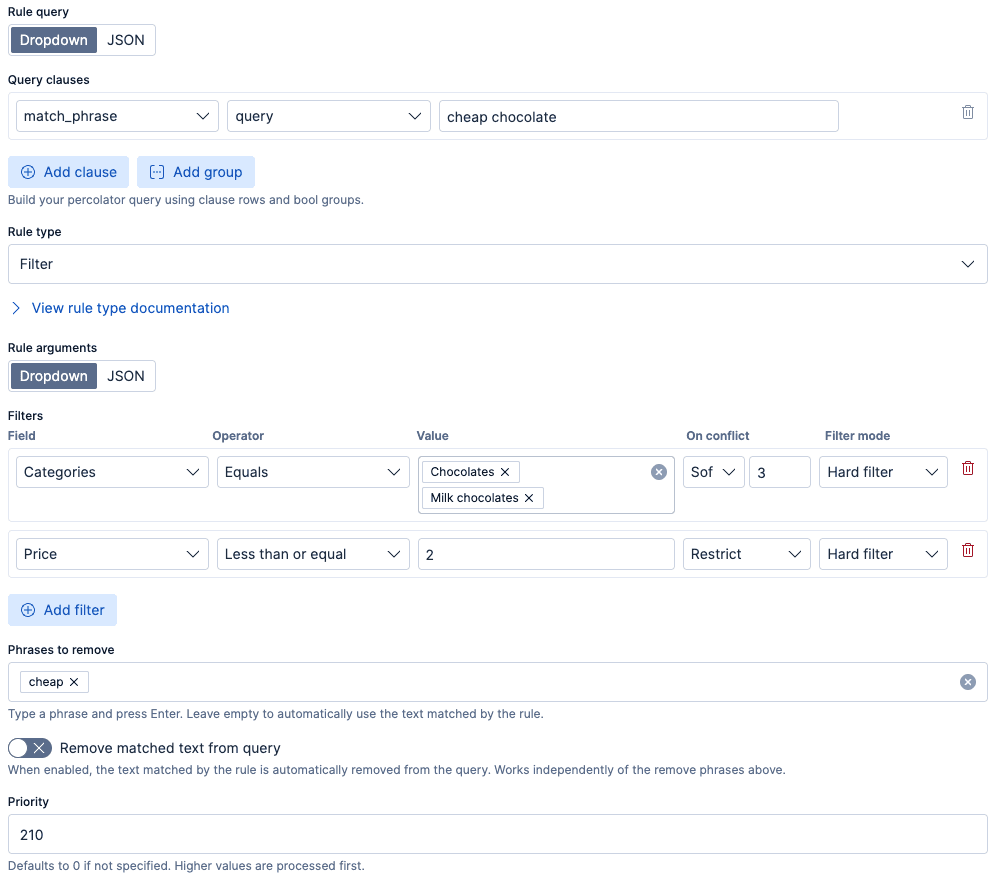
Die unten dargestellte Richtlinie erkennt, ob ein Nutzer eine Suchabfrage mit dem Begriff „günstige Schokolade“ gestellt hat. In diesem Fall beschränken sich die Ergebnisse auf die Kategorien „Schokolade“ und „Vollmilchschokolade“. Diese Richtlinie wendet auch einen Preisfilter von 2 $ an. Beachten Sie außerdem, dass diese Richtlinie eine Priorität von 210 hat. Darauf werden wir zurückkommen, wenn wir die Konfliktlösung genauer besprechen.
Die hier gezeigten Einstellungen für den Filtermodus und die Konfliktstrategie (hard_filter, soft_boost, restrict, override) werden im Abschnitt zur Konfliktlösung weiter unten ausführlich erläutert.
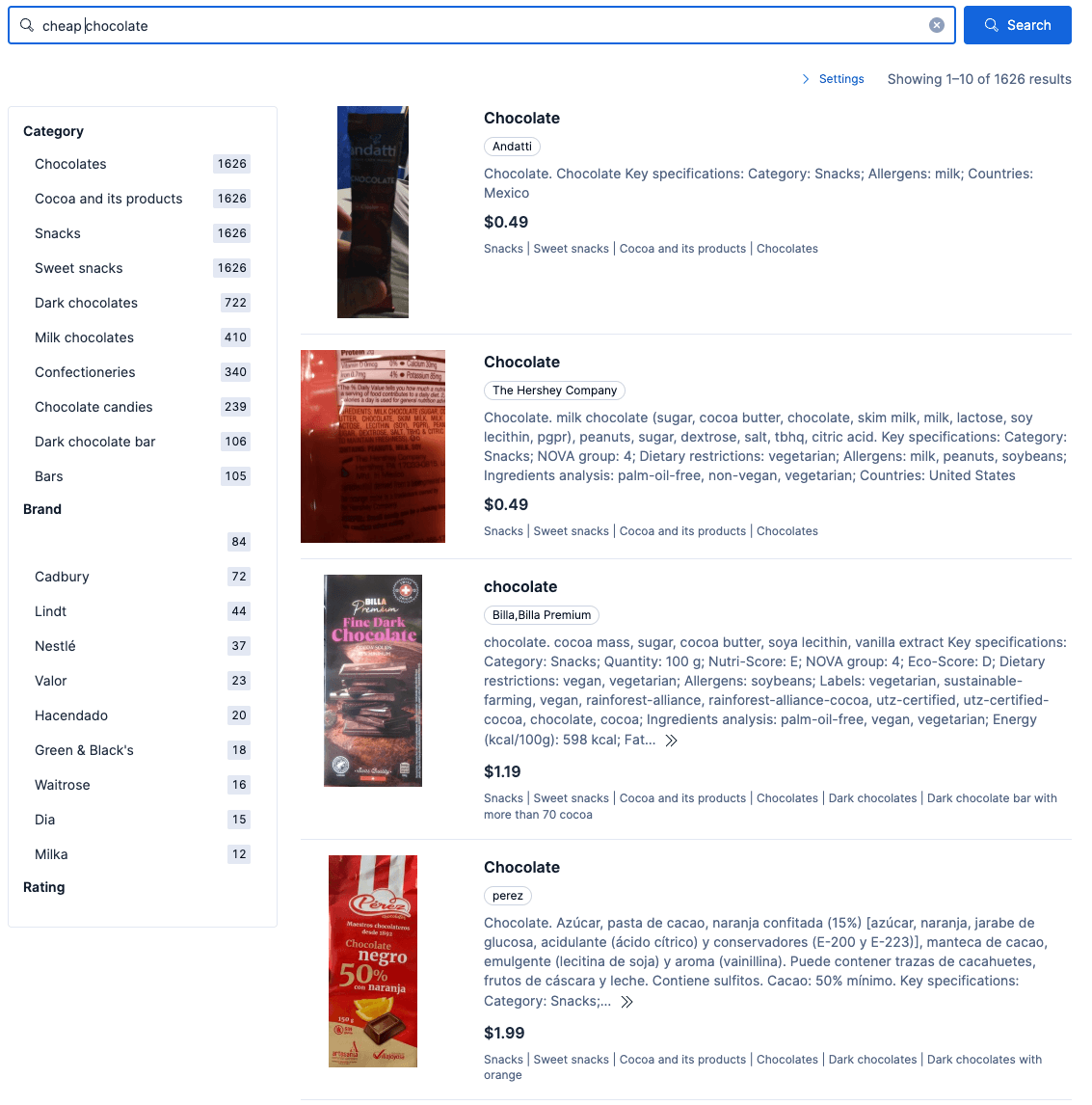
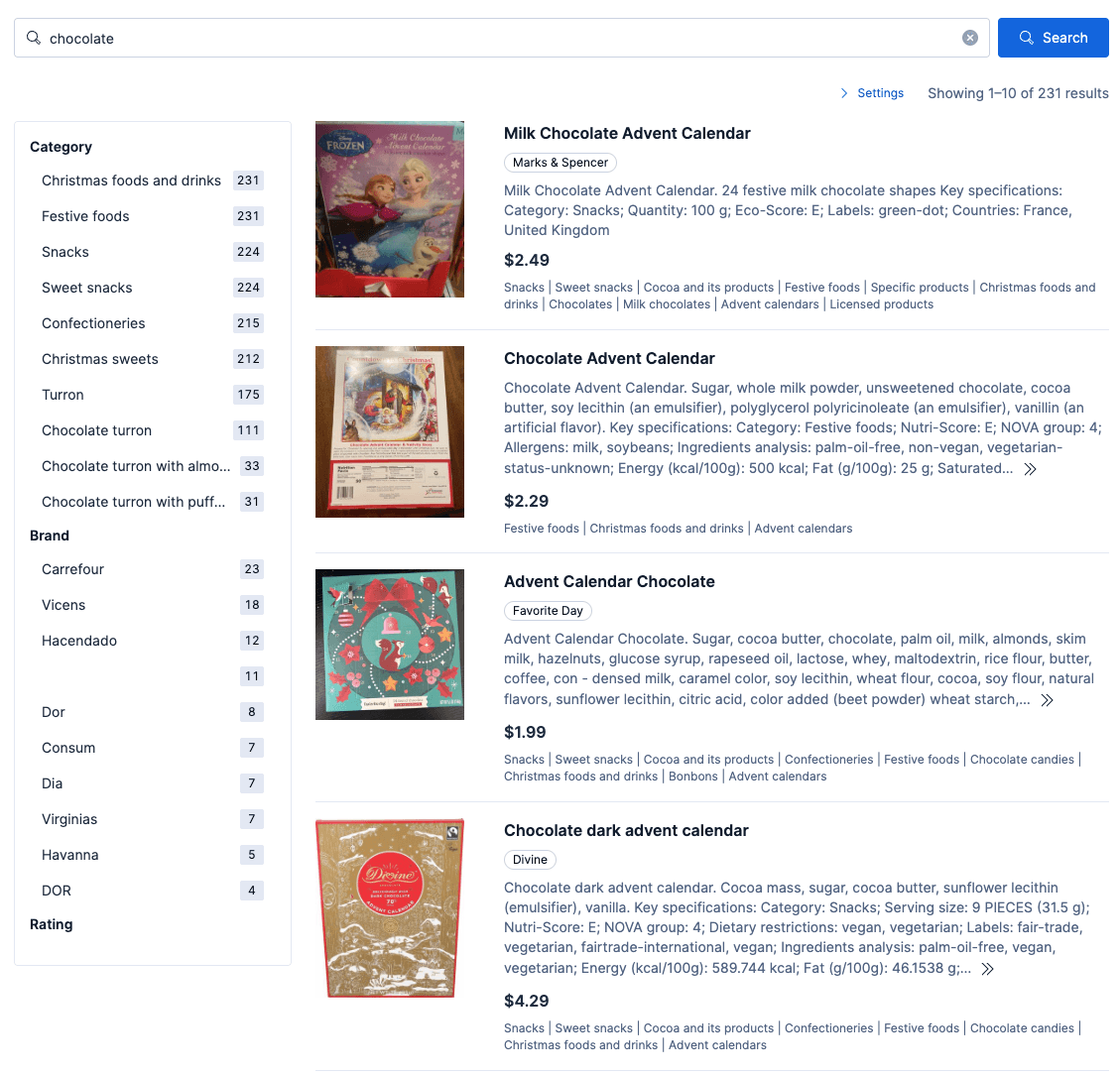
Wenn die obige Richtlinie aktiviert ist, berücksichtigt eine Suche nach „günstige Schokolade“ den Preisfilter von 2 $ und beschränkt die Ergebnisse auf die Kategorien „Schokolade“ und „Milchschokolade“. Ein Beispiel für die Ergebnisse finden Sie weiter unten:
Weihnachtsschokolade
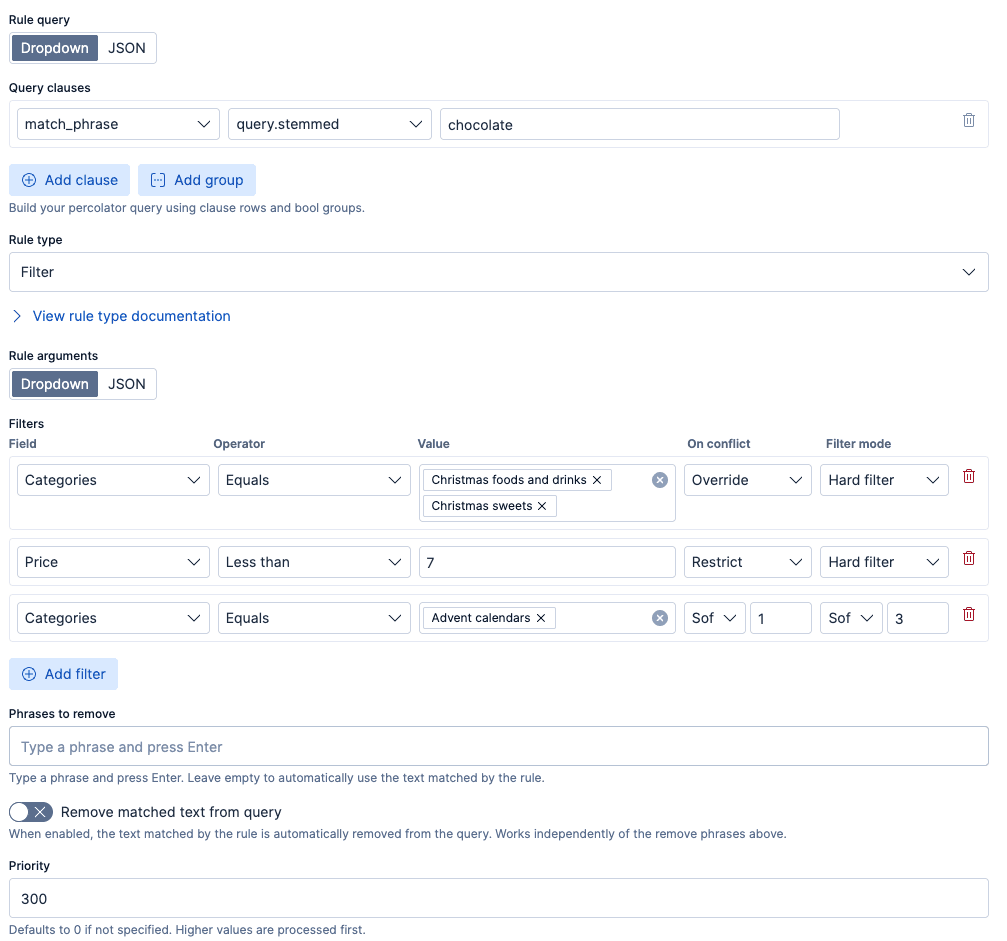
Die unten gezeigte Richtlinie ist ein Beispiel für eine Richtlinie, die zur Weihnachtszeit angewendet werden könnte. Dieses Beispiel beschränkt die Ergebnisse auf „Weihnachtslebensmittel und -getränke“ und „Weihnachtssüßigkeiten“, hebt Produkte hervor, die auch in der Kategorie „Adventskalender“ enthalten sind, und wendet einen Preisfilter von weniger als 7 $ an, um sich auf erschwingliche saisonale Artikel zu konzentrieren. Beachten Sie außerdem, dass diese Richtlinie eine Priorität von 300 hat. Wir werden darauf zurückkommen, wenn wir die Konfliktlösung detaillierter besprechen.
Wenn die oben genannte Richtlinie ohne widersprüchliche Richtlinien aktiviert ist, berücksichtigt eine Suche nach „Schokolade“ den Preisfilter von 7 $, beschränkt die Ergebnisse auf die Kategorien „Weihnachtslebensmittel und -getränke“ und „Weihnachtssüßigkeiten“ und hebt alle Produkte hervor, die mit „Adventskalender“ gekennzeichnet sind. Ein Beispiel für die Ergebnisse finden Sie weiter unten:
Kombination übereinstimmender Richtlinien
Die oben beschriebene Richtliniensuche ist nur die halbe Wahrheit. Die andere Hälfte ist das, was passiert, wenn mehrere Richtlinien derselben Abfrage entsprechen.
In jeder nichttrivialen Deployment wird eine einzelne Abfrage routinemäßig mehrere Richtlinien gleichzeitig auslösen. „Günstige Schokolade“ passt zu beiden oben dargestellten Richtlinien. Jede Richtlinie ist für sich genommen richtig. Die Herausforderung besteht darin, sie zu einem einzigen, kohärenten Ausführungsplan zusammenzustellen, ohne Widersprüche, ohne Doppelzählungen und ohne dass eine Richtlinie die Arbeit einer anderen stillschweigend rückgängig macht.
Dies ist kein Nachschlageproblem; es ist ein Beurteilungsproblem. Das System muss entscheiden:
- Reihenfolge der Anwendung: Wenn eine Negationsrichtlinie „ohne Erdnüsse“ aus der Abfrage entfernt, sieht die Preisrichtlinie dann noch den Originaltext oder den geänderten Text?
- Filterkonflikte: Wenn zwei Richtlinien unterschiedliche Preisobergrenzen festlegen, welche zählt dann? Wird der Verlierer stillschweigend fallen gelassen oder degradiert er sich sanft zu einem soft Boost?
- Phrasenbesitz: Wenn zwei Richtlinien auf dasselbe Wort zutreffen und die erste es bereits belegt hat, sollte die zweite dann trotzdem greifen?
Eine naive Implementierung (Anwendung aller übereinstimmenden Richtlinien unabhängig voneinander und Zusammenführung von Ergebnissen) führt zu Fehlern, sobald Richtlinien interagieren. Die Architektur benötigt ein explizites Modell dafür, wie sich Richtlinien zusammensetzen. In den nächsten beiden Abschnitten wird dieses Modell beschrieben: ein Framework zur Prioritätensetzung und Konfliktlösung sowie ein kaskadierendes Transformationsmodell, das die Interaktion zwischen Richtlinien deterministisch gestaltet.
Die zentrale Erkenntnis ist, dass die Anwendung von Richtlinien keine Reihe unabhängiger Abläufe darstellt, sondern eine kaskadierende Transformation. Jede Richtlinie erhält den von allen Richtlinien mit höherer Priorität erzeugten Rewrite-Zustand und transformiert ihn weiter:
Anfangszustand → [Richtlinie A] → Zustand' → [Richtlinie B] → Zustand'' → ... → Ausführungsplan
Der Zustand enthält den umgeschriebenen Abfragetext, akkumulierte Filter, die aktuelle Absicht und alle Synonym-Erweiterungen. Eine hochprioritäre Richtlinie kann Text aus der Abfrage entfernen, und jede nachfolgende Richtlinie sieht die geänderte Abfrage, nicht die ursprüngliche. Kontext wird akkumuliert. Die Reihenfolge ist wichtig.
Priorität und Konfliktlösung: Der Determinismus zählt
Die konkreten Konfliktstrategien sind eine bewusste Gestaltungsentscheidung. Einzelne Unternehmen können Konflikte unterschiedlich lösen, abhängig von ihren geschäftlichen Anforderungen. Der folgende Ansatz veranschaulicht die Art des Beurteilungs-Frameworks, die eine Steuerungsebene benötigt. Wichtig sind nicht diese spezifischen Strategien, sondern dass das System explizite, deterministische Strategien enthält, anstatt Konflikte durch unvorhersehbare Interaktionen lösen zu lassen.
Prioritätsreihenfolge
Die Richtlinien sind nach Priorität sortiert (höchste zuerst). Wenn mehrere Richtlinien mit derselben Abfrage übereinstimmen, werden sie in Prioritätsreihenfolge angewendet. Wenn zwei Richtlinien versuchen, dasselbe Filterfeld festzulegen, hat die deklarierte Strategie der Richtlinie mit höherer Priorität für dieses Feld Vorrang. Wenn mehrere Richtlinien ausgelöst werden, die dieselbe Priorität haben, erhält die Richtlinie mit der höchsten ID Vorrang (als ob ihr eine höhere Priorität zugewiesen wäre); diese Wahl sorgt für deterministisches Verhalten, wenn Konflikte auftreten.
Auflösung pro Feld, nicht pro Richtlinie
Ein kritisches Designprinzip: Die Konfliktlösung erfolgt pro Feld (zum Beispiel Marke, Kategorie oder Beschreibung), nicht pro Richtlinie. Wenn zwei Richtlinien Filter erzeugen, die sich bei bestimmten Feldern überschneiden, sind nur diese spezifischen Felder von der Konfliktlösungsstrategie betroffen, und die Auflösungsstrategie wird durch die übereinstimmende Richtlinie mit der höchsten Priorität bestimmt. Nicht kollidierende Felder aus beiden Richtlinien bleiben erhalten.
Dies ist wichtig, weil die Alternative eines richtlinienbasierten Ansatzes das System dazu zwingen würde, eine gesamte Richtlinie entweder zu akzeptieren oder abzulehnen, wenn nur ein Konflikt zwischen den Feldern besteht.
Bei der Auflösung pro Feld bleibt die maximale Menge an nützlichen Einschränkungsinformationen erhalten.
Drei Einstellungen pro Filterfeld
Jedes Filterfeld in einer Richtlinie hat drei unabhängige Einstellungen:
Filtermodus: Wie der Filter angewendet wird, wenn es keinen Konflikt gibt.
hard_filter(Standard): Wird als Elasticsearchbool.filterKlausel angewendet. Dies ist nützlich, um nicht verwandte Produkte vollständig auszuschließen. Wenn man beispielsweise die Suche nach „Orangen“ auf die Kategorie Obst und Gemüse beschränkt, werden Treffer wie Orangensaft und Orangenmarmelade ausgeschlossen. Nicht übereinstimmende Dokumente werden vollständig aus den Ergebnissen ausgeschlossen.soft_boost: Wird als Elasticsearchfunction_score-Gewichtung mit einer konfigurierbarenboost_weightangewendet. Übereinstimmende Dokumente erhalten einen Ranking-Boost, aber nicht übereinstimmende Dokumente werden nicht ausgeschlossen. Das ist nützlich, um zum Beispiel eine Marke zu stärken, ohne andere Marken auszuschließen.
Konfliktstrategie
Was passiert, wenn eine Richtlinie mit niedrigerer Priorität dasselbe Feld festlegt:
override: Der Wert dieser Richtlinie mit hoher Priorität gewinnt; der Wert mit niedrigerer Priorität wird vollständig ignoriert. Gültig für alle Feldtypen.restrict: Nehmen Sie den restriktiveren numerischen Wert (zum Beispiel die niedrigere Obergrenze für Preis__max, the higher floor for price__min). Gilt nur für numerische Bereichsfelder.merge: Kombinieren Sie beide Werte in eine Vereinigung. Gültig nur für nicht-numerische Felder.soft_boost: Konvertieren Sie den konfliktierenden Filter in einfunction_score-Gewicht mit einer konfigurierbarenboost_weightanstelle eines festen Filters. Weitere Details zum Function_score-Boosting finden Sie unter „Beeinflussung des BM25-Rankings mit multiplikativem Boosting in Elasticsearch“. Dies gilt nur für Nicht-Negationsfelder.
Wert: Der tatsächliche Filterwert (z. B. eine Kategorienliste, ein Preisschwellenwert).
Strategien nach Feldtyp: Nicht alle Strategien sind für alle Feldtypen sinnvoll. Zum Beispiel ist eine Ausschlussregel von Natur aus binär, daher kann sie keinen soft Boost erhalten. Die folgende Tabelle zeigt, welche Strategien für einzelne Feldtypen verfügbar sind:
| Feldtyp | Verfügbare Strategien | Standard |
|---|---|---|
| Negationsfelder (__not, __match__not) | überschreiben, zusammenführen | Überschreiben |
| Numerische Bereichsfelder (__max, __min., __gt, __lt.) | einschränken, überschreiben, Soft-Boost | einschränken |
| Alle anderen Felder (Schlüsselwort, Text) | soft_boost, override, merge | soft_boost |
Negationsfelder können nicht soft-geboostet werden, da die Ausschlüsse binär sind. Die Umwandlung von „zeige niemals Konserven“ in „ziehe Nicht-Konserven vor“ ändert die Semantik grundlegend. Ein Produkt aus „Konserven“ würde immer noch erscheinen, nur etwas niedriger eingestuft, was den Zweck des Ausschlusses unterläuft.
Ein konkretes Beispiel: Die Suche nach „günstiger Schokolade“ während einer Weihnachtskampagne
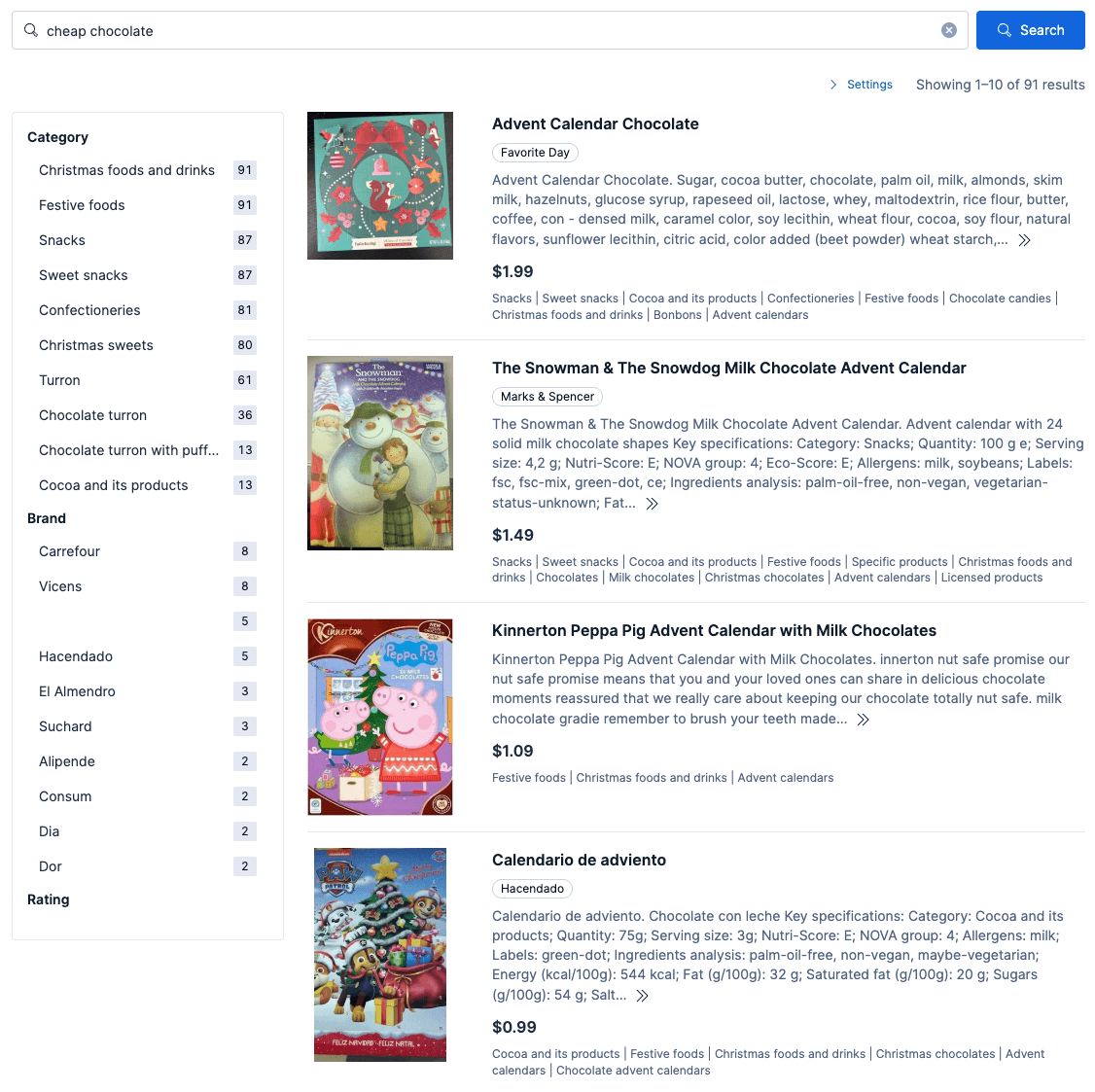
Angenommen, ein Händler hat die beiden zuvor demonstrierten Richtlinien für Schokolade erstellt, eine mit niedrigerer Priorität für günstige Schokolade und eine andere, höher priorisierte schokoladenbezogene Richtlinie, die während der Weihnachtszeit aktiviert wird. Wenn beide dieser Richtlinien aktiviert sind, hängt ihre Kombination vom Filtermodus und der Konfliktstrategie der Richtlinie mit höherer Priorität ab. Wenn beide zuvor besprochenen Richtlinien aktiviert sind, werden sie wie folgt kombiniert:

Dies zeigt zwei Konflikte, eine bei den Kategorien und eine beim Preis. Es sollte erwähnt werden, dass die Abfrage, die nach dieser Transformation ausgeführt wird, folgende Eigenschaften aufweist:
- Es werden nur Produkte aus den Kategorien „Weihnachtslebensmittel und -getränke“ und „Weihnachtssüßigkeiten“ angezeigt.
- Innerhalb dieser Kategorien werden Produkte, die auch mit der Kategorie „Adventskalender“ gekennzeichnet sind, um das Dreifache aufgewertet.
- Ein Preisfilter für 2 $ wird angewendet. Er stammt aus der Richtlinie mit niedrigerer Priorität (weil die Richtlinie mit höherer Priorität bei Konflikten „Restrict“ festlegt).
- Das Wort „günstig“ wird entfernt und es werden nur Produkte zurückgegeben, die „Schokolade“ entsprechen.
Wenn diese beiden Richtlinien aktiviert sind, gibt „billige Schokolade“ Ergebnisse zurück, die der Abbildung unten ähneln:
Einschränkungen lockern
Vielleicht möchte der Einzelhändler keine Produkte in den Kategorien „Schokolade“ und „Milchschokolade“ während der Weihnachtszeit ausschließen. Die Einstellungen der Weihnachtsrichtlinie könnten zu weit gefasst sein und versehentlich Kategorien entfernt haben, die von der Richtlinie für „günstige Schokolade“ abgedeckt werden. Dies ist ein Beispiel, das zeigt, warum es unter Umständen wünschenswerter sein kann, Richtlinien mit niedrigerer Priorität mit sich widersprechenden Richtlinien mit höherer Priorität zu kombinieren. Wir könnten beispielsweise die Weihnachtsschokoladen-Aktion so modifizieren, dass wir bei Konflikten nicht „Überschreiben“, sondern einen soft Boost durchführen. Die Änderung dieser Richtlinie würde wie folgt aussehen:

Nach dieser Modifikation sieht die Ausführung der Transformationspipeline zur Abfrageumschreibung für „günstige Schokolade“ wie folgt aus:

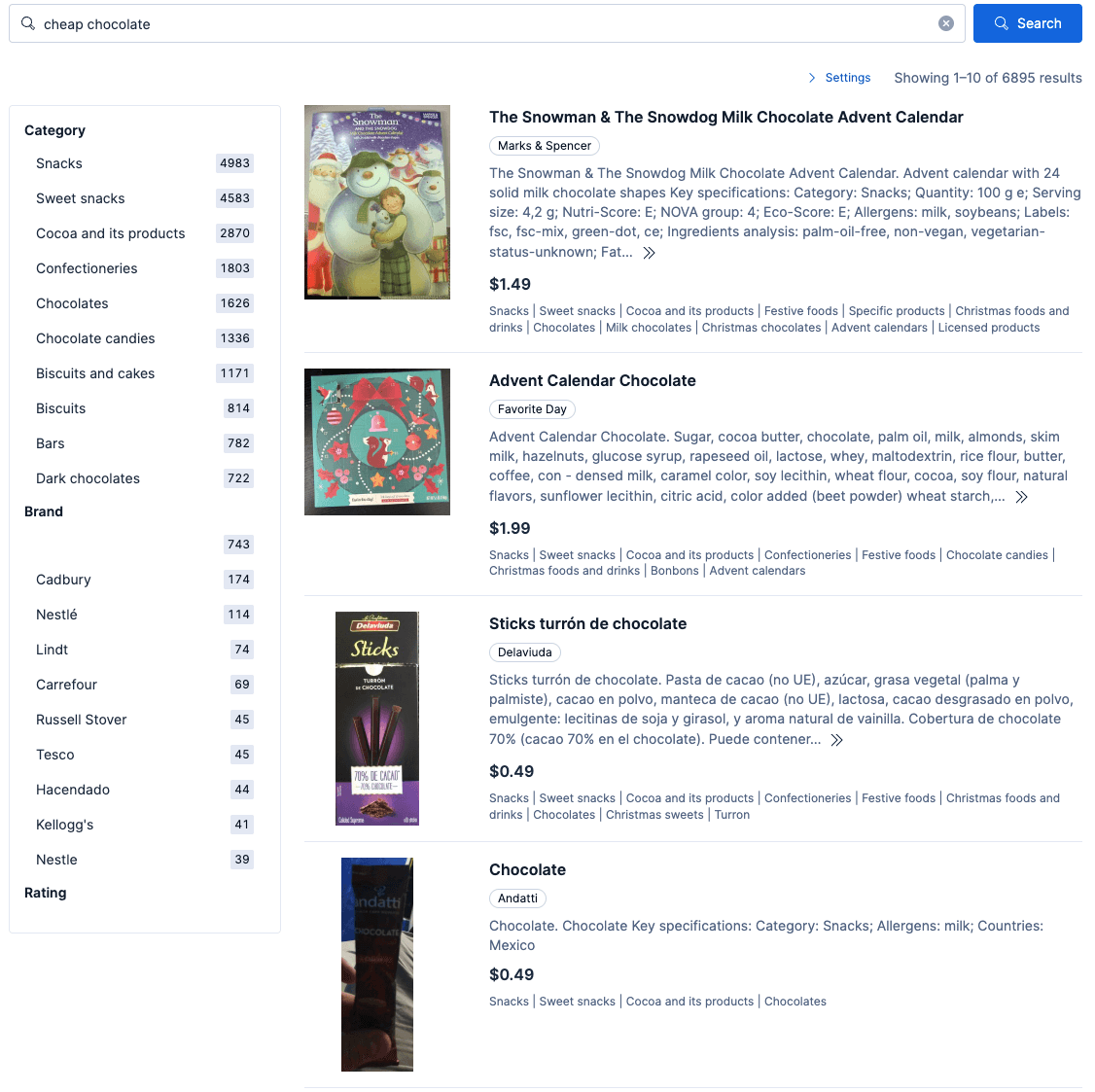
Mit dem soft Boost bei Konflikten werden die miteinander in Konflikt stehenden Filter in softe Boosts umgewandelt, anstatt weggelassen zu werden. Die Abfrage, die nach dieser Umwandlung im Produktkatalog ausgeführt wird, hat die folgenden Eigenschaften:
- Weil „Bei Konflikt“ als „soft Boost“ in der höher priorisierten Richtlinie angegeben ist, werden die Konflikte wie folgt in Boosts umgewandelt:
- Produkte aus den Kategorien „Weihnachtslebensmittel und -getränke“ und „Weihnachtssüßigkeiten“ erhalten einen einfachen Boost.
- Produkte aus den Kategorien „Schokolade“ und „Milchschokolade“ erhalten einen dreifachen Boost.
- Wie im vorherigen Beispiel, bei dem die Produkte auch als zur Kategorie „Adventskalender“ gehörig markiert sind, erhalten sie einen dreifachen Boost.
- Wie im vorherigen Beispiel wird ein Preisfilter für 2 $ angewendet.
- Das Wort „günstig“ wird entfernt und es werden nur Produkte zurückgegeben, die „Schokolade“ entsprechen.
Bei weniger strenger Filterung sehen die Ergebnisse wie folgt aus:
Preisüberschreibung einer Richtlinie mit hoher Priorität
Vielleicht möchte der Händler zu Weihnachten auch etwas teurere Schokoladenprodukte anzeigen, indem der Preis auf 7 $ erhöht wird. Um sicherzustellen, dass der Maximalpreis aus der Weihnachtsschokoladen-Richtlinie nicht überschrieben wird, wenn jemand nach „günstiger Schokolade“ sucht, können wir den Konfliktmodus des Preises folgendermaßen auf „überschreiben“ statt auf „einschränken“ setzen:

Mit dieser Überschreibung ignoriert die Abfrage für „billige Schokolade“ den in der „billigen Schokoladenrichtlinie“ definierten Höchstpreis und wendet nur den in der „Weihnachtsschokoladenrichtlinie“ festgelegten Preis an, wie folgt:
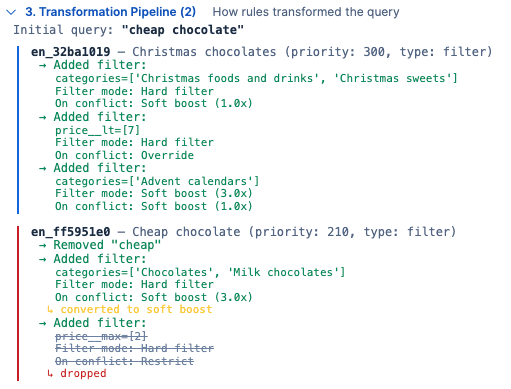
Dies ähnelt dem vorherigen Beispiel, mit dem Unterschied, dass der Höchstpreis auf den Wert von 7 $ aus der Richtlinie mit höherer Priorität festgelegt ist, weil in dieser Richtlinie „Überschreiben“ bei Konflikt angegeben wurde. Wenn der Weihnachtspreisfilter Vorrang hat, sehen die Ergebnisse wie folgt aus:
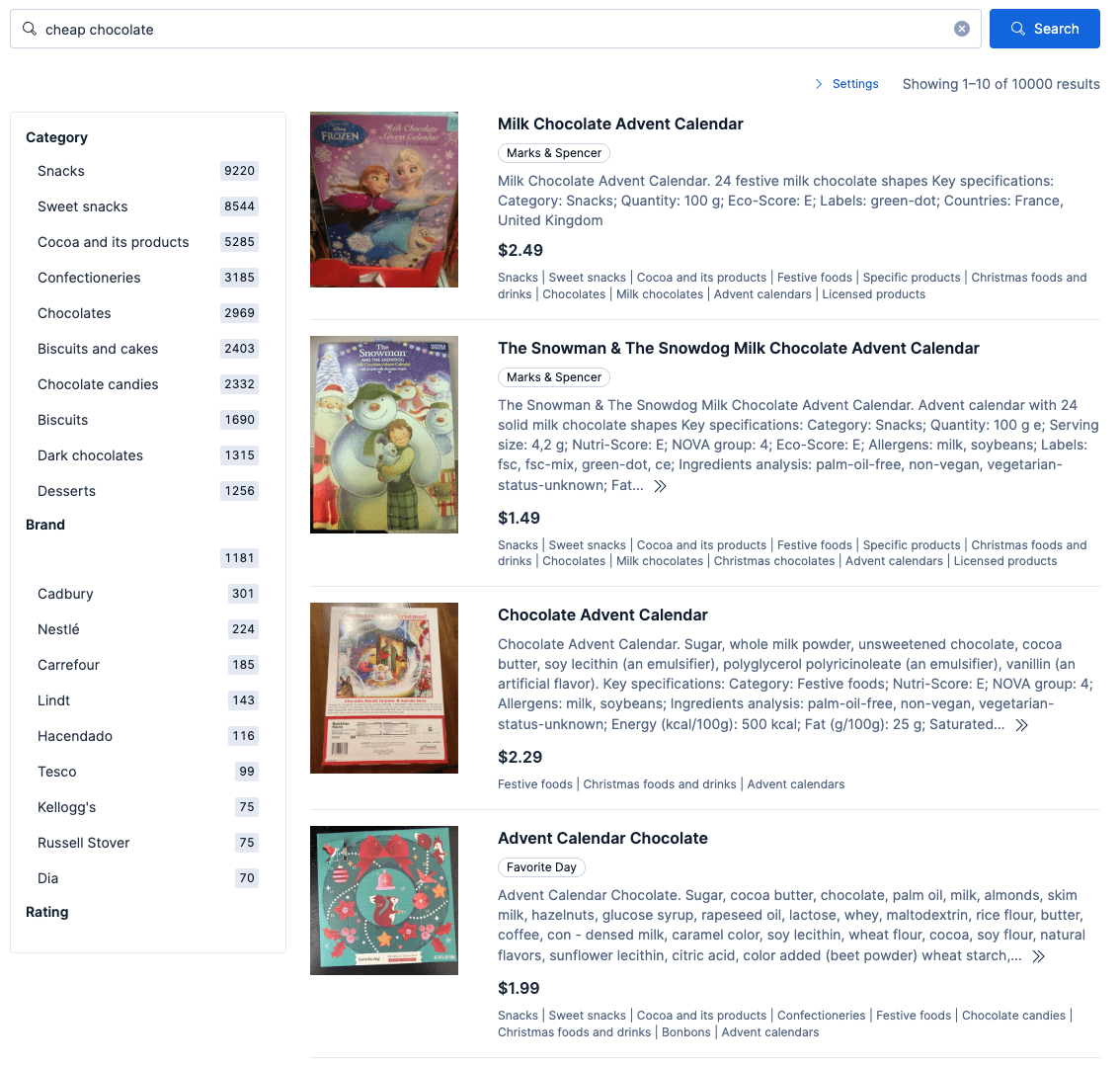
Diese drei Varianten (override, soft_boost und override on price) zeigen eine zentrale Eigenschaft des Systems: Ein Merchandiser kann die Interaktion zweier Richtlinien ändern, indem er eine Einstellung in einem einzelnen Feld innerhalb einer einzelnen Richtlinie ändert, ohne Code bereitzustellen. Die Konfliktstrategie ist der Hebel, der das Geschäftsverhalten steuert.
Verfolgung verwendeter Phrasen
Es gibt eine subtilere Form des Konflikts: zwei Richtlinien, die auf dieselbe Phrase zutreffen. Wenn eine Richtlinie mit höherer Priorität „ohne Erdnüsse“ aus der Abfrage entfernt, hat eine Richtlinie mit niedrigerer Priorität, die ebenfalls auf „ohne“ zutrifft, nichts mehr, worauf sie wirken kann. Das System erkennt, ob die übereinstimmende Phrase nicht mehr in der umgeschriebenen Abfrage vorhanden ist, und überspringt die Richtlinie mit niedrigerer Priorität.
Intent-Richtlinien sind von der Verfolgung verbrauchter Phrasen ausgenommen: Sie legen die Abrufstrategie basierend auf der ursprünglichen Abfrageübereinstimmung fest, unabhängig davon, welcher Text durch Richtlinien mit höherer Priorität entfernt wurde.
Gemeinsam verleihen Prioritätsordnung, feldbasierte Konfliktlösung und die Verfolgung verbrauchter Phrasen der Steuerungsebene ein deterministisches Kompositionsmodell. Auf dieser Grundlage kann das System eine Routing-Entscheidung treffen, die ohne sie riskant wäre.
Governance macht die Abrufstrategie sicher
Eine wichtige Erkenntnis bezüglich des Routings zur richtigen Abrufmethode (textuell, semantisch oder hybrid) ist, dass sie nach der Governance ausführen wird. Wenn Ihre Richtlinien bereits die „Produktkategorie“ durchgesetzt haben, ist der semantische Abruf wesentlich weniger riskant, da die Kandidatenmenge eingeschränkt ist. Eine semantische Suche mit über 500 Produktartikeln ist eine ganz andere Sache als eine semantische Suche über 500.000 SKUs. Die Governance schränkt den Explosionsradius ein, bevor der Abruf beginnt.
Ohne entsprechende Steuerung könnte beispielsweise eine semantische Abfrage nach „Obst mit hohem Vitamin-C-Gehalt unter 4 $“ neben Obst auch Vitaminpräparate, Karotten und grüne Paprika zurückgeben. Die Steuerungsebene stellt sicher, dass diese unerwünschten Ergebnisse nicht einmal als Teil der semantischen Erweiterung in Betracht gezogen werden.
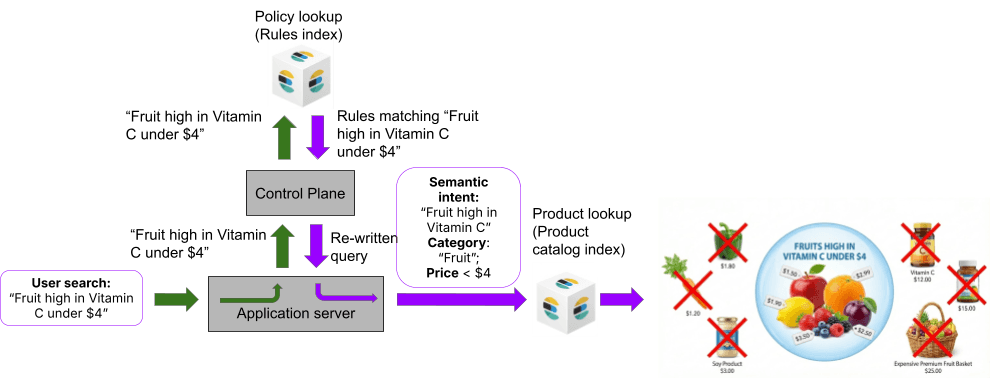
Mit dieser Einschränkung wendet die Steuerungsebene pragmatische Routing-Logik an:
- Lexikalisch für Navigations- und Hauptabfragen, bei denen deterministische Präzision zählt.
- Semantisch für beschreibende Discovery-Abfragen, bei denen ein Konzeptabgleich hilft.
- Selektiv hybrid, wenn Beschränkungen bereits durchgesetzt wurden und das Unternehmen einen umfassenderen Abruf akzeptiert.
Von der Architektur bis zur Implementierung
Die kontrollierte Steuerungsebene übersetzt die Geschäftsabsicht in deterministische, zusammensetzbare Ausführungspläne, ohne diese Logik in den Anwendungscode einzubetten. Richtlinien sind Daten: Sie werden zur Abfragezeit abgeglichen, durch explizite Konfliktstrategien pro Feld aufgelöst und als kaskadierende Transformationen angewendet, die erklärbare Ergebnisse liefern. Elastic Services Engineering hat diese Architektur für E-Commerce-Teams in Unternehmen entwickelt und implementiert, wobei wiederholbare Muster und Beschleuniger verwendet wurden, die den Weg vom Konzept zur Produktion komprimieren. Eine Demo unserer Implementierung einer Steuerungsebene können Sie auf YouTube unter folgendem Link ansehen: Fixing Search Relevance in Seconds: Introducing PRISM.
Wie geht es weiter in dieser Serie?
Der nächste Beitrag geht praktisch auf die Implementierung ein: wie der Elasticsearch-Perkolator die Richtliniensuche beschleunigt, einschließlich Index-Mappings, Grenzmarkern, von Highlights gesteuerter Phrasenverfolgung und konkreter Abfragebeispiele.
Setzen Sie die reglementierte E-Commerce-Suche in die Praxis um
Die in diesem Beitrag beschriebene Architektur der Steuerungsebene (Konfliktlösung pro Feld, kaskadierende Richtlinien-Transformationen und durch Governance beschränktes Retrieval-Routing) wurde von Elastic Services Engineering entworfen und entwickelt. Jedes Muster, jeder Screenshot und jede Transformationspipeline, die in dieser Serie gezeigt wird, stammt aus einem funktionierenden System, das von Elastic Services Engineering entwickelt und anhand von Produktkatalogen im Unternehmensmaßstab validiert wurde.
Wenn Sie eine kontrollierte, richtliniengesteuerte Steuerungsebene in Elasticsearch implementieren möchten, kann Elastic Services Sie schneller dorthin bringen.
Nehmen Sie an der Diskussion teil
Haben Sie Fragen zur Suchsteuerung, zu Abrufstrategien oder zur Sucharchitektur im E-Commerce? Nehmen Sie an der Diskussion der Elastic-Community teil.
Zugehörige Inhalte

18. Mai 2026
Agentische KI-Suche mit deterministischen Leitplanken in Elasticsearch zur sicheren Ausführung von Abfragen
Agentische KI-Suchsysteme versagen häufig, wenn LLMs Abfragen direkt generieren. Erfahren Sie, wie deterministische Leitplanken und eine Steuerungsebenenarchitektur eine sichere, zuverlässige und kontrollierte Abfrageausführung mit Elasticsearch ermöglichen.

11. Mai 2026
Personalisierung der E-Commerce-Suche: Integration von Kaufverlauf und Nutzerkohorten
Erfahren Sie, wie Sie in Elasticsearch ein personalisiertes E-Commerce-Sucherlebnis schaffen, ohne gegen die Governance-Richtlinien zu verstoßen. In diesem Beitrag erfahren Sie, wie Sie Produkte hervorheben können, die ein Kunde bereits gekauft hat, und wie Sie kohortenspezifische Richtlinien auf der Grundlage von Nutzerprofilen aktivieren können.

4. Mai 2026
Elasticsearch-Perkolator zur Steuerung der Suche im E-Commerce: Übersetzung mehrdeutiger Anfragen in kontrollierte Abrufstrategien
Erfahren Sie, wie Sie den Elasticsearch-Perkolator zur Implementierung der Suchsteuerung verwenden. In diesem Blog skizzieren wir die Muster, die erforderlich sind, um eine geregelte Policy-Engine in der Produktion zu erstellen und eine kontrollierte Abrufstrategie zu entwickeln.

24. April 2026
Neuindizierung von Datenströmen aufgrund von Mapping-Konflikten
Erfahren Sie, wie Sie Elasticsearch-Mapping-Konflikte durch Neuindizierung von Datenströmen beheben können. Dieser Blog erklärt den Neuindizierungsprozess und wie Sie sicherstellen, dass neue Daten korrekt zugeordnet werden.

9. April 2026
Warum die E-Commerce-Suche Governance benötigt
Erfahren Sie, warum E-Commerce-Suche ohne Governance unzureichend ist und wie eine Kontrollschicht vorhersehbare und absichtsgesteuerte Ergebnisse gewährleistet und damit die Suche verbessert.