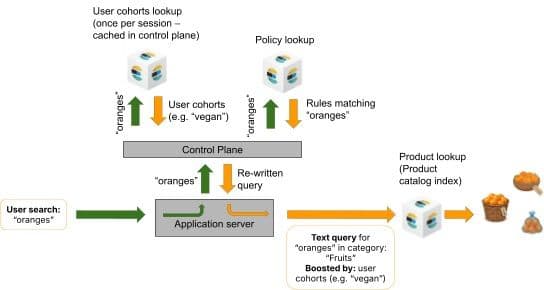
As partes 1 a 5 desta série descrevem um plano de controle governado que classifica a intenção, impõe restrições, resolve conflitos de políticas e direciona para a estratégia de recuperação apropriada, tudo isso antes que o catálogo de produtos seja consultado. Todos os mecanismos descritos até agora tratam todos os compradores de forma idêntica. Uma busca por "chocolate" produz o mesmo conjunto de resultados, independentemente de o comprador ser vegano, um pai comprando chocolate para o aniversário de um filho ou um consumidor que segue os princípios halal.
Este post apresenta dois mecanismos de personalização que ampliam o plano de controle governado sem alterar a arquitetura. Ambos os mecanismos se acumulam multiplicativamente com a camada de governança das Partes 1 a 5: as políticas ainda são acionadas, as restrições ainda são aplicadas, os conflitos ainda são resolvidos e os sinais de personalização são compostos na mesma consulta governada, garantindo que os resultados retornados pelo Elasticsearch já estejam personalizados.
O primeiro mecanismo impulsiona produtos que o cliente individual já comprou antes. O segundo ativa políticas específicas de grupo com base no perfil do cliente. Juntos, eles demonstram que a personalização não é um sistema separado acoplado à busca ou aplicado como processamento pós-recuperação; é uma extensão natural do plano de controle orientado por políticas.
Para uma análise aprofundada da matemática por trás das técnicas de personalização usadas nesta postagem, veja Busca personalizada no Elasticsearch sem pós-processamento de ML e Classificação com reconhecimento de agrupamento no Elasticsearch.
Para ver uma demonstração em tempo real de como o histórico de compras pode ser usado para melhorar os resultados de busca para clientes recorrentes, assista ao vídeo: Personalização explicável: melhora na busca com o histórico de compras.
Impulsionamento do histórico de compras individual
A forma mais simples de personalização também é uma das mais eficazes: se um cliente já comprou um produto antes, valorize-o quando ele buscar algo relacionado ao produto. Um comprador que compra regularmente uma marca específica de cookies com gotas de chocolate deve ver esses biscoitos listados primeiro ao buscar por "cookies", não porque um modelo previu uma preferência, mas porque há evidências comportamentais diretas.
Como funciona
Quando uma solicitação de pesquisa inclui um identificador de usuário, como seria o caso de um usuário que tem uma sessão aberta, o plano de controle executa duas consultas Elasticsearch em paralelo usando um thread pool:
- A consulta percolador no índice de políticas (a mesma pesquisa de governança descrita nas Partes 3 e 4).
- Uma consulta de histórico de compras em um índice
user_purchases, filtrada para o usuário específico porterm(user_id)e comparação da string de pesquisa atual com os títulos de produtos desse usuário.
Essas operações executam de forma concomitante (nenhuma espera pela outra), então a busca de personalização não adiciona latência significativa ao pipeline de governança.
A consulta do histórico de compras usa a análise de texto do Elasticsearch (stemming, tokenização) ao comparar a string de busca atual com os títulos de produtos armazenados. Isso significa que ao buscar por "cookies" corresponderá a uma compra anterior de "cookies de brownie" por meio da análise de texto padrão, sem exigir a correspondência exata de string.
Cálculo dos pesos de impulso
Nem todas as compras passadas merecem o mesmo impulso. O peso é responsável por dois fatores intuitivos: a frequência com que o comprador comprou o produto e há quanto tempo. Um produto comprado 15 vezes na semana passada é um sinal muito mais forte do que um produto comprado uma vez há seis meses. A ponderação usa redimensionamento logarítmico na frequência (para que um único item muito comprado não sobrecarregue todos os outros) e decaimento exponencial na atualidade (para que compras antigas desapareçam naturalmente com o tempo).
Para saber os detalhes matemáticos da fórmula de impulso, veja Busca personalizada no Elasticsearch sem pós-processamento de ML.
Como isso se torna uma consulta
Os impulsos do histórico de compras são incorporados à consulta como a camada de pontuação mais externa, envolvendo os filtros de política de governança e os impulsos das Partes 3 e 4, além de quaisquer impulsos de sinais de negócios, como margem e popularidade (que exploraremos na Parte 7). Isso significa que um produto removido por uma política de governança não reaparecerá devido a um impulso no histórico de compras. A governança controla o conjunto de resultados; a personalização ajusta a ordenação dentro dele. Produtos sem histórico de compras não são penalizados. A classificação que possuíam é mantida, embora produtos com histórico de compras relevante fiquem acima deles, considerando todos os outros fatores iguais.
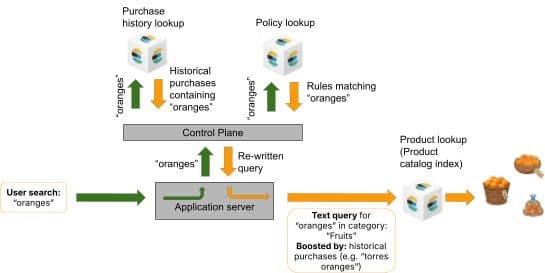
Por que consultar o Elasticsearch em cada busca?
O histórico de compras é consultado no Elasticsearch a cada busca, em vez de ficar em cache na camada de aplicação. Esta é uma escolha de design deliberada. Como a consulta faz a correspondência da string de busca atual com os títulos dos produtos usando o pipeline de análise de texto do Elasticsearch, o sistema se beneficia da mesma stemização, da tokenização e do tratamento de idioma que melhoram a própria busca de produtos. Uma consulta em cache na memória exigiria reimplementar essa análise ou aceitar uma correspondência menos precisa.
Para ver por que essa ordenação importa, considere um comprador que já comprou suco de laranja e agora busca por "laranjas". A consulta do histórico de compras faz a correspondência de "suco de laranja" com o termo de busca "laranjas" por meio da análise de texto e calcula um impulso para esse produto. Mas a camada de governança já restringiu "laranjas" à categoria de hortifruti, excluindo por completo o suco de laranja. O impulso do histórico de compras para suco de laranja está presente na consulta, mas não tem efeito porque não há nenhum documento correspondente, no conjunto de resultados governado, sobre o qual ele possa atuar. O comprador vê laranjas frescas, ranqueadas por relevância e personalização. A proteção de governança continua valendo.
O custo de desempenho é mínimo: o índice do histórico de compras é pequeno (o histórico de compras de um usuário normalmente tem de dezenas a centenas de documentos, não milhões), e a consulta é executada em paralelo à busca pelo percolador, portanto não estende o caminho importante.
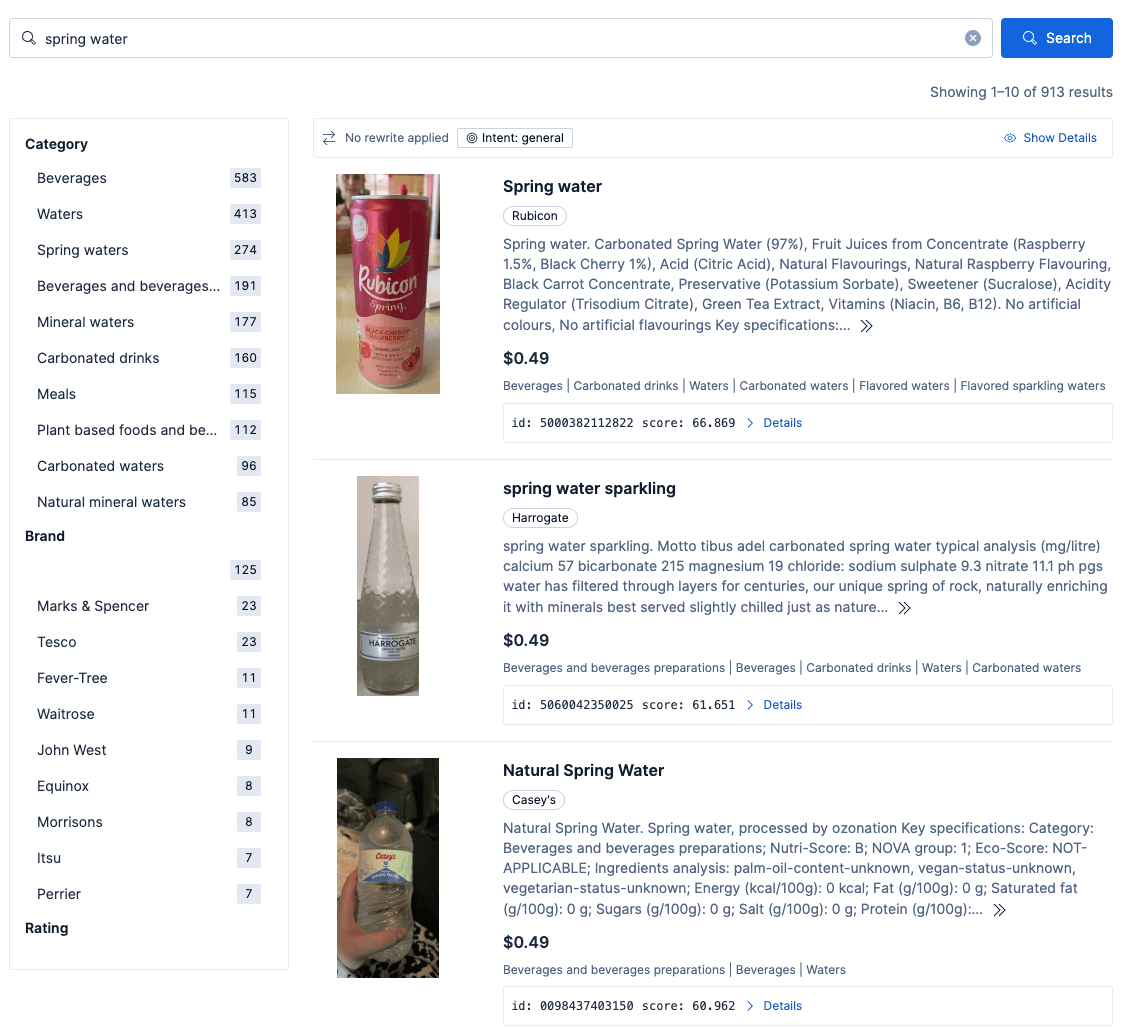
Exemplo de consulta para “água mineral” sem histórico do usuário
Se um usuário não logado ou um usuário que nunca comprou "água mineral" pesquisar, pode encontrar resultados semelhantes aos seguintes:
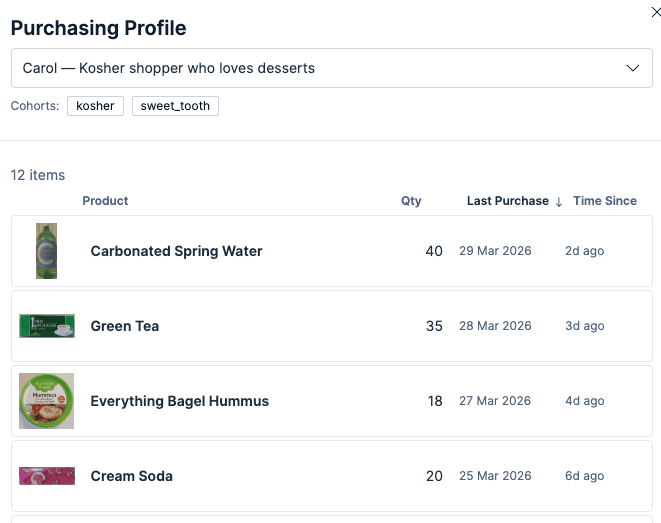
Exemplo de histórico de compras do usuário
Por outro lado, uma usuária chamada Carol tem um histórico de compras que contém os seguintes produtos:
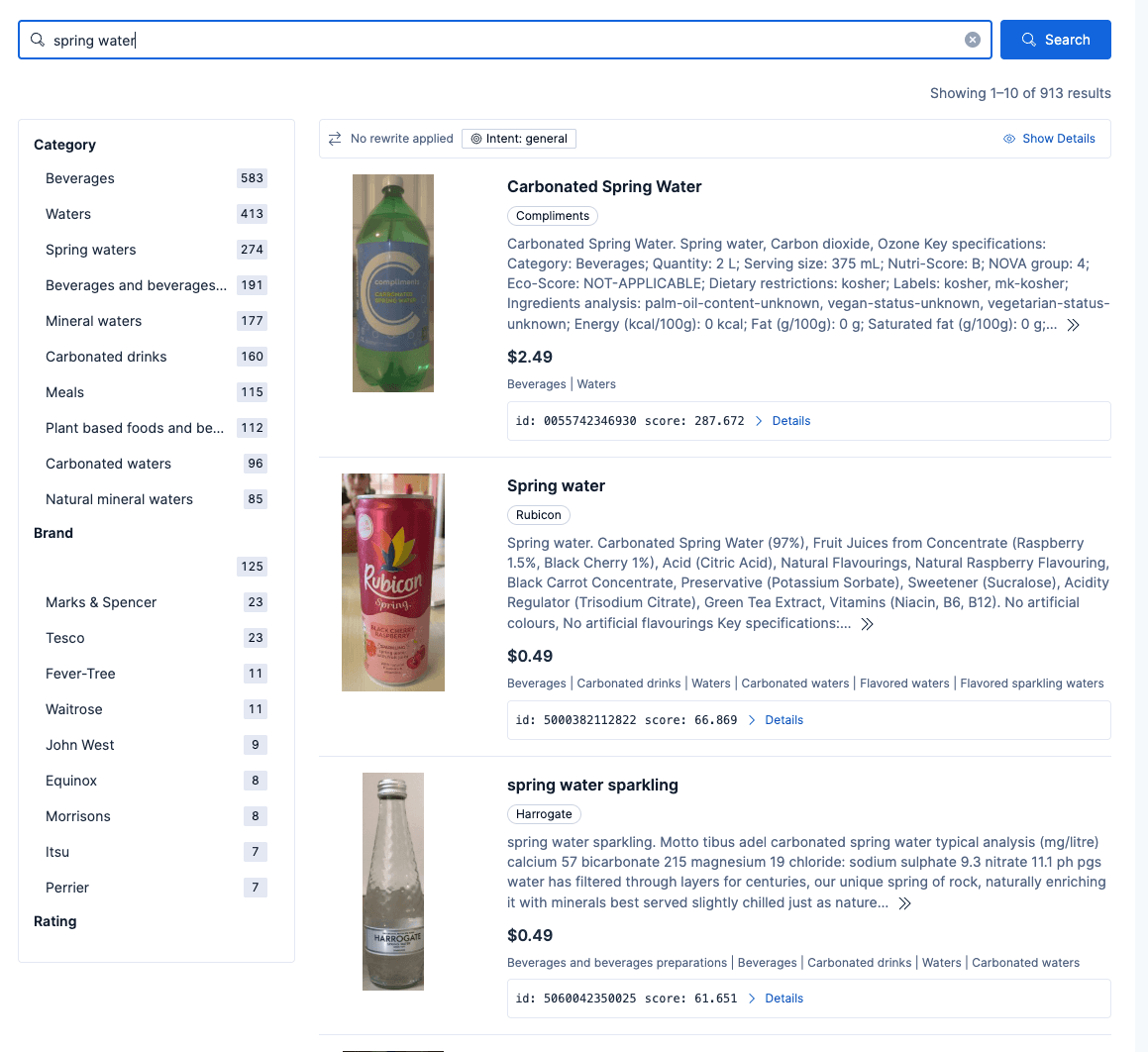
Exemplo de busca por "água mineral" com o histórico de compras acima
Se Carol buscar por “água mineral”, verá resultados personalizados que refletem o que ela comprou no passado. Olhando o histórico de compras acima, ela comprou "água mineral" (a garrafa verde) cerca de 40 vezes, e a compra mais recente foi há dois dias. Se ela buscar por "água mineral", esse produto é potencializado, pois sabemos que ela gosta disso. Note que, nos resultados não personalizados, a água mineral Rubicon foi o primeiro resultado.
Ativação de políticas sensível à coorte
O histórico de compras individual funciona bem para clientes recorrentes com comportamento definido. Mas muitos compradores são novos, anônimos ou estão navegando fora dos padrões habituais. Para esses compradores, a participação no grupo oferece um tipo diferente de personalização, uma personalização baseada em quem o comprador é, não no que ele fez.
Um comprador vegano que procura por "chocolate" deve ver o chocolate vegano listado nas primeiras posições. Um comprador que segue as práticas halal e busca por "snacks" deve ver opções certificadas halal em destaque. Um consumidor preocupado com a saúde que busca por "iogurte" deve ver as opções probióticas em destaque.
Agrupamentos como políticas, não como tags de produto
Os produtos já possuem atributos normais, incluindo campos como dietary_restrictions: ["vegan"] ou dietary_restrictions: ["halal"]. A questão é onde reside a lógica que conecta o grupo de compradores a esses atributos do produto.
A abordagem mais ingênua seria codificar esse mapeamento na camada da aplicação ou no modelo de busca: se o usuário for vegano, adicione um impulso à dietary_restrictions: "vegan". Mas este é o mesmo emaranhado de código na camada de aplicação descrito na Parte 1, e cria o mesmo atrito operacional: adicionar um novo grupo ou alterar o que um agrupamento significa exige uma alteração no código.
O plano de controle governado mantém a lógica de agrupamento no mecanismo de políticas. Uma política de agrupamento faz a ponte entre duas coisas: a associação de um comprador a agrupamento (por exemplo, "vegano") e um atributo de produto (por exemplo, dietary_restrictions: “vegan”). A política define a conexão: quando um comprador do grupo vegano pesquisa, priorize produtos onde dietary_restrictions incluir "vegano".
Como a lógica de coorte está no motor de políticas e não no código do aplicativo, isso significa:
- Adicionar um novo grupo é algo que pode ser feito criando uma nova política; não é necessário reindexar produtos.
- As políticas de agrupamento usam o mecanismo de regras completo: elas podem adicionar filtros, aplicar reforços flexíveis, expandir sinônimos, alterar a estratégia de recuperação ou qualquer outra ação que uma política possa realizar.
- O comportamento da agrupamento é gerenciado por meio da mesma admin UI de todas as outras políticas: um comerciante pode criar, testar e promover políticas de agrupamento por meio do fluxo de trabalho Autor → Testar → Promover descrito na Parte 2.
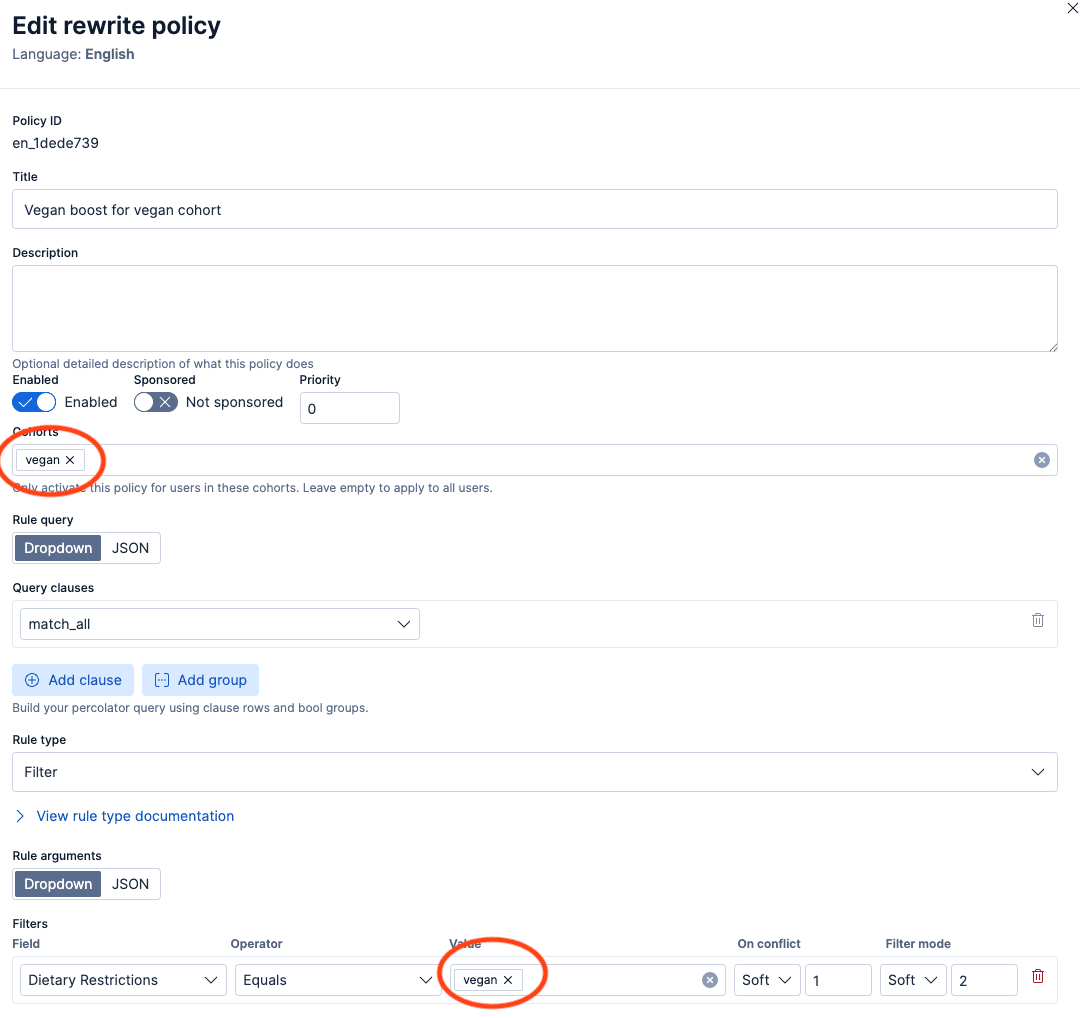
Exemplo de política de coorte vegana
Um merchandiser cria uma política de coorte com as seguintes características:
- Agrupamentos:
["vegan"]. - Critérios de correspondência: corresponde a qualquer consulta (ou a uma categoria de produto específica).
Ação: Impulso suave no dietary_restrictions: "vegan" com um peso de impulso de 2.
Como funciona a ativação por coorte
Cada documento de política tem um campo cohorts. Políticas universais que se aplicam a todos os compradores, independentemente do grupo, podem deixar este campo em branco, e estes serão internamente atribuídos um valor de "_all" pelo plano de controle. Políticas específicas de agrupamento armazenam os nomes de agrupamento-alvo, como ["vegan", "kosher", “sweet_tooth”].
Quando uma solicitação de busca inclui um perfil de usuário, o plano de controle cria um filtro simples de terms para a consulta do percolador:
Esse filtro único inclui todas as políticas universais mais as políticas específicas de agrupamento do usuário. O sentinela _all limpa esse filtro de inclusão: não são necessárias consultas must_not ou exists para lidar com o caso em que uma política não possui restrição de agrupamento.
O percolador então avalia as correspondências de política normalmente. A única diferença é que o conjunto de políticas do candidato foi restringido àquelas relevantes para os grupos desse cliente. Tudo o que vem depois (transformações em cascata, resolução de conflitos por campo, rastreamento de frases consumidas) funciona de forma idêntica ao fluxo não personalizado descrito nas Partes 3 e 4.
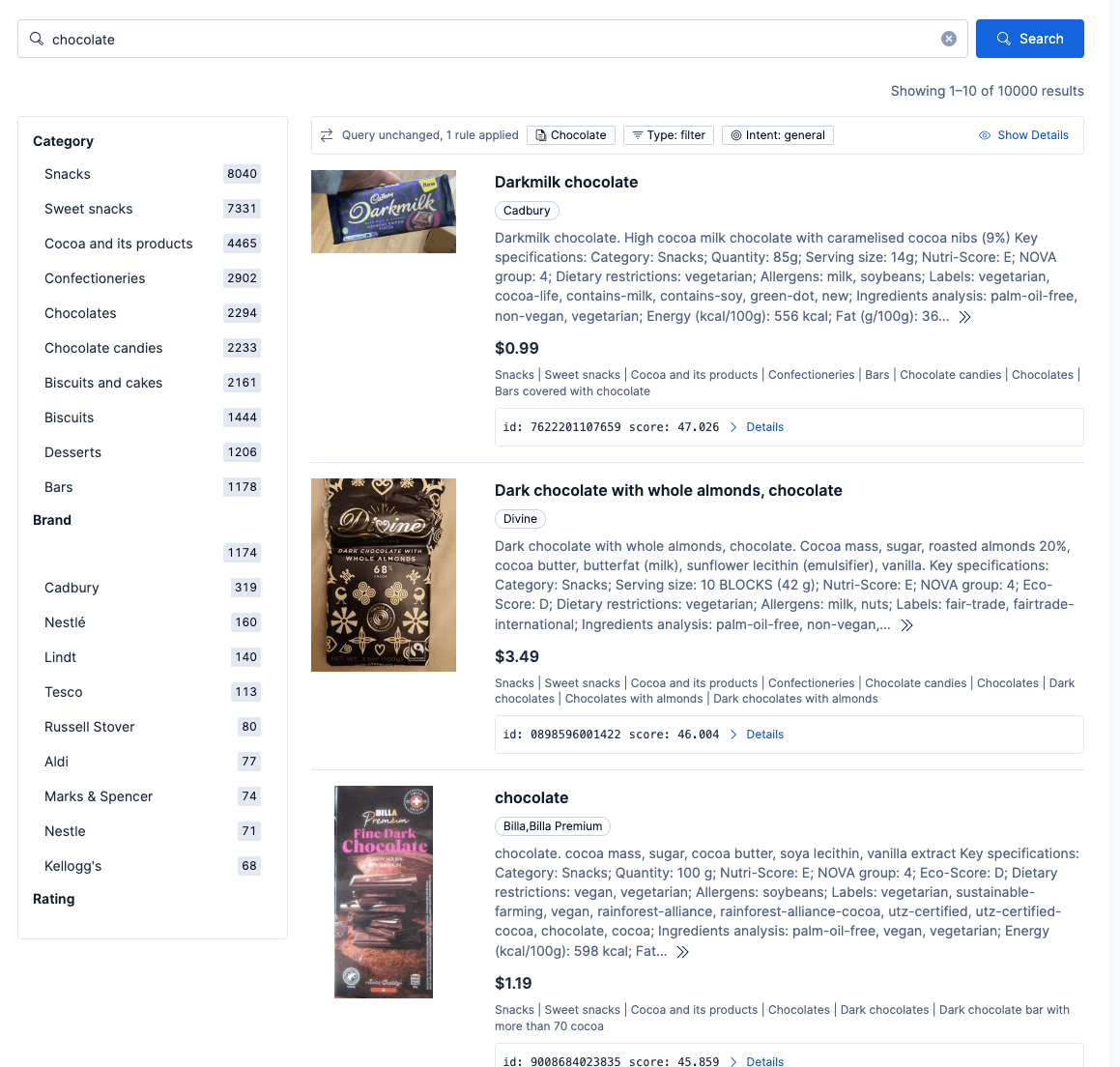
Resultados de usuários não veganos (padrão) ao buscar por "chocolate"
Quando um usuário não vegano pesquisa por chocolate, não há um aumento de agrupamento vegano aplicado aos seus resultados. Eles viam chocolates não veganos entre os principais resultados, conforme segue:
Resultados da política de agrupamento vegana ao buscar por "chocolate"
Quando um comprador vegano busca por "chocolate", essa política está incluída no conjunto de candidatos a percolador. Há correspondência e o plano de controle aplica um leve impulso aos chocolates certificados veganos. O aumento é multiplicativo: chocolates veganos têm uma classificação mais alta, mas chocolates não veganos não são totalmente excluídos porque o filtro acima é definido como leve impulso, que descrevemos em detalhes na Parte 3 desta série.
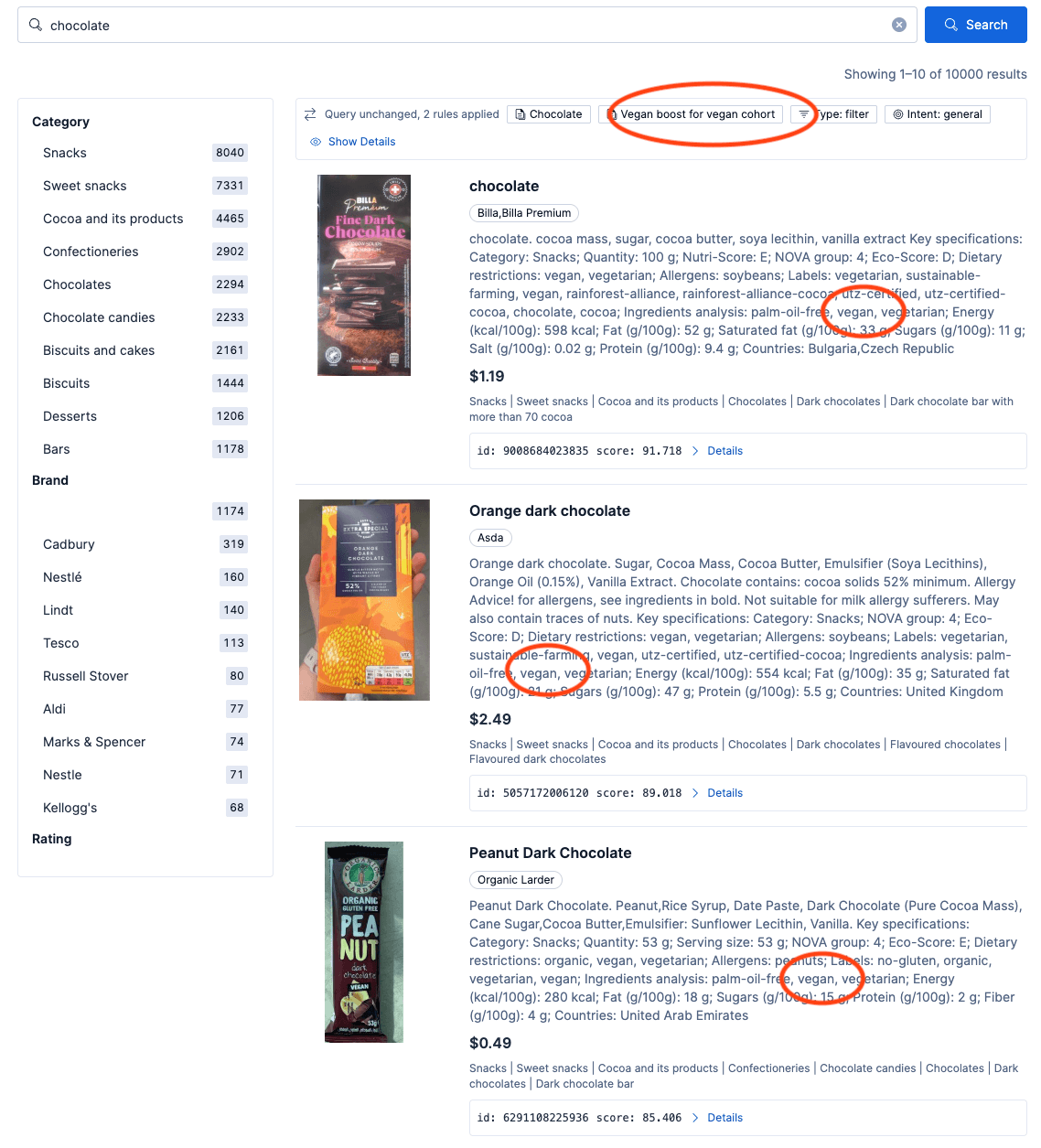
No entanto, se o comprador buscar explicitamente por "chocolate ao leite Hershey", o impulso para produtos veganos ainda se aplica, mas pode ser superado pela relevância textual mais forte dos produtos de chocolate ao leite Hershey.
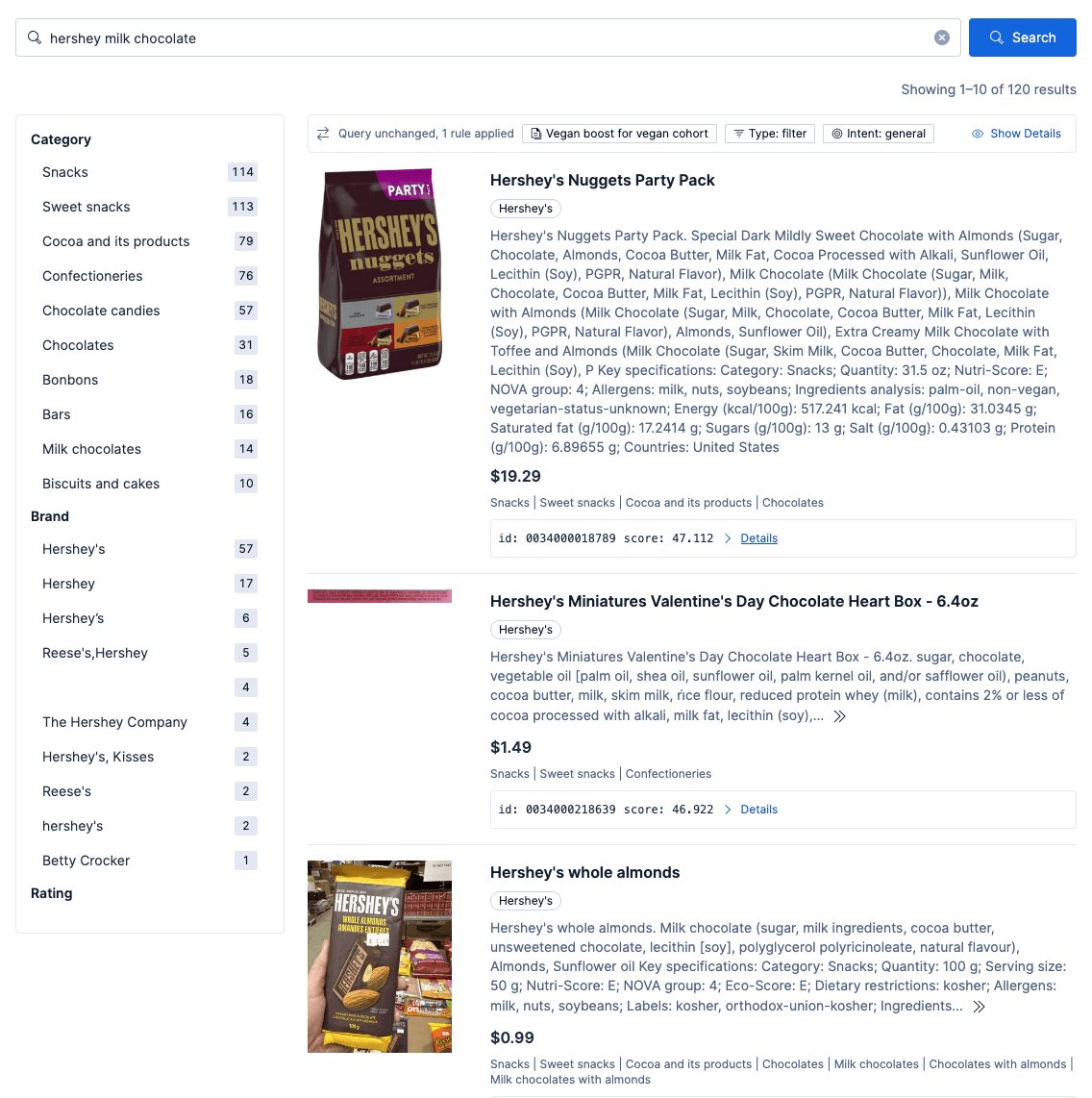
Um consumidor que não faz parte do grupo vegano e busca pela mesma consulta nunca vê a política de "grupo vegano"; ela não está no conjunto de resultados possíveis. A camada de governança é idêntica; somente o conjunto de políticas ativo é diferente.
Agrupamentos com histórico de compras
Um consumidor vegano com um extenso histórico de compras recebe ativação de políticas específicas para o grupo de clientes veganos, além de impulso no histórico de compras. Para compradores novos ou anônimos, a simples associação implícita a um grupo proporciona uma personalização significativa sem exigir quaisquer dados comportamentais (por exemplo, talvez um usuário anônimo tenha pesquisado apenas produtos veganos e, portanto, o classificamos como membro do grupo vegano). Um comprador que se identifica como halal durante a criação da conta recebe imediatamente resultados personalizados halal na primeira busca.
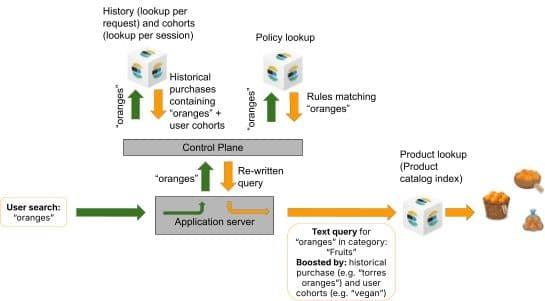
Como as camadas de personalização são compostas
A ordem de nidificação das function_score camadas importa. Do mais interno ao mais externo:
- Consulta básica: a palavra-chave ou a correspondência semântica com consultas nomeadas (
fulltext_match,title_phrase_match). - Camada de política de governança: Filtros rígidos como cláusulas
bool.filter, reforços suaves como funçõesfunction_score(Partes 3 e 4). - Impulsionamentos de sinal de negócio: aumento de margem e popularidade (que exploraremos na Parte 7).
- O histórico de compras aumenta: a camada mais externa
function_score.
Essa ordenação garante que a governança controle o conjunto de resultados (o que aparece), os sinais de negócios ajustam a classificação dentro desse conjunto (o que aparece primeiro da perspectiva do varejista) e o histórico de compras ajusta ainda mais a classificação com base no comportamento individual (o que aparece primeiro da perspectiva do comprador). Cada camada envolve a camada anterior multiplicativamente, de modo que os efeitos se acumulam em vez de entrarem em conflito.
O que isso significa operacionalmente
A personalização por meio do plano de controle governado preserva todas as propriedades operacionais descritas nas Partes 1 e 2:
- Mudanças de implantação zero. As políticas de agrupamento são criadas, testadas e promovidas através da UI. Adicionar um novo agrupamento alimentar ou ajustar um impulso de peso não requer alterações no código nem envolvimento de engenharia.
- Auditabilidade. Cada política de agrupamento é um documento discreto e com uma versão. Quando um comerciante pergunta: "Por que os produtos veganos estão classificados mais alto para esse usuário?", a resposta é uma política específica com prioridade específica, visível no painel de fazer debug junto com todas as outras políticas que foram acionadas por aquela consulta.
- Resolução de conflitos. As políticas de agrupamento participam da mesma resolução de conflitos por campo descrita na Parte 3. Se o impulso de categoria de uma política de agrupamento entrar em conflito com a substituição de categoria de uma política de campanha, o conflito será resolvido deterministicamente pela mesma estrutura de prioridade e estratégia, sem necessidade de tratamento especial.
- Mensurabilidade. Como as políticas de coorte são discretas e podem ser alternadas individualmente, seu impacto nas taxas de conversão, cliques e adição ao carrinho pode ser medido de forma independente, assim como qualquer outra política do sistema.
O que vem a seguir nesta série
O próximo post explora outra dimensão do plano de controle governado: como o aumento de margem e popularidade pode ser ajustado por consulta por meio de políticas, transformando a otimização econômica em uma decisão de governança, em vez de uma configuração estática.
Veja a Parte 7: otimização econômica governada por consulta: impulso de margem e popularidade por consulta
Coloque em prática o buscar governado de comércio eletrônico
Os padrões de personalização descritos neste post (impulsionamento do histórico de compras individual e ativação de políticas com reconhecimento de agrupamento) foram projetados e desenvolvidos pela Elastic Services Engineering como parte de nosso acelerador de busca de e-commerce reutilizável. Ambos os mecanismos se integram à arquitetura do plano de controle governado descrita ao longo desta série. Entre em contato com o Elastic Professional Services.
Participe da discussão
Tem dúvidas sobre governança de buscar, estratégias de recuperação ou arquitetura de buscar para e-commerce? Participe da conversa mais ampla da comunidade Elastic.
Conteúdo relacionado

18 de maio de 2026
Busca por IA agêntica com proteções determinísticas no Elasticsearch para execução segura de consultas
Sistemas de busca por IA agêntica falham quando LLMs geram consultas diretamente. Aprenda como as proteções determinísticas e uma arquitetura de plano de controle permitem a execução de consultas seguras, confiáveis e governadas com o Elasticsearch.

4 de maio de 2026
Percolador do Elasticsearch para governança de busca em comércio eletrônico: traduzindo consultas ambíguas em estratégias de recuperação controladas
Aprenda como usar o percolador do Elasticsearch para implementar a governança de busca. Neste blog, delineamos os padrões necessários para criar um motor de políticas governado em produção e criar uma estratégia de recuperação controlada.

1 de maio de 2026
Construindo um plano de controle para gerenciar a busca de comércio eletrônico
Como criar um plano de controle com governança para e-commerce que integra políticas de busca conflitantes em um único plano de execução (sem alterações de código).

24 de abril de 2026
Reindexação de fluxos de dados por causa de conflitos de mapeamento
Aprenda como corrigir conflitos de mapeamento do Elasticsearch reindexando fluxos de dados. Este blog explica o processo de reindexação e como garantir que os novos dados sejam mapeados corretamente.

9 de abril de 2026
Por que a busca para e-commerce precisa de governança
Descubra por que a busca para e-commerce falha sem governança e como uma camada de controle garante resultados previsíveis e orientados pela intenção, melhorando a recuperação.