Elasticsearch is packed with new features to help you build the best search solutions for your use case. Learn how to put them into action in our hands-on webinar on building a modern Search AI experience. You can also start a free cloud trial or try Elastic on your local machine now.
Overview
In this article, we explore how to make Elasticsearch search results more relevant for different e-commerce user segments using an explainable, multiplicative boosting strategy — without any machine learning post-processing.
Introduction: Why personalization matters
Elasticsearch is very good at ranking results by textual relevance (BM25) and by semantic relevance (vectors). In e-commerce, that is necessary but not sufficient. Two people can type the same query and reasonably expect different results:
- A luxury shopper searching for “red lipstick” expects prestige brands near the top.
- A budget shopper wants affordable options promoted.
- A gift buyer may prefer popular bundles.
The goal is to adjust ranking so that, for a given query, products that align with the user’s segment rise modestly in the list, without destroying the underlying relevance. This article shows how to add cohort-aware personalization on top of Elasticsearch’s relevance using only function_score, a keyword field, and small multiplicative boosts.
Multiplicative boosting for cohort personalization
The core challenge in cohort personalization is stability. You want a product that is relevant to the query to remain relevant, with a controlled, explainable uplift when it matches the user’s segment. What often goes wrong is that personalization signals are added to the score in a way that either:
- overwhelms BM25 on some queries, or
- has almost no effect on others.
This happens because most boosting approaches use additive scoring. However, BM25 scales can vary dramatically across queries and datasets, so a fixed additive adjustment (e.g., “add +2.0 for a cohort match”) is sometimes a massive change to the BM25 score, and other times is negligible. Instead, what we want is a guarantee that if a product is a good match for the query, and it aligns with the user’s cohort, then its score is increased by a controlled percentage regardless of the absolute BM25 scale. We can achieve this with a multiplicative pattern:
This article shows how to implement this pattern using Elasticsearch’s function_score query, a cohorts field on the product, and a list of user cohorts passed at query time.
Modeling cohorts in your product catalog
The simplest way to enable cohort-aware ranking is to treat cohorts as tags. For example, a product might carry tags such as:
- Lipstick: ["female", "beauty", "luxury"]
- Men’s deodorant: ["male", "personal_care", "sport"]
- Glitter gloss: ["female", "beauty", "youth", "party"].
A user or session carries a set of tags inferred from behavior and profile:
- High-income female luxury shopper: ["female", "beauty", "luxury"]
- Budget-oriented female shopper: ["female", "beauty", "budget"]
Cohort overlap is the count of shared cohort tags between the user/session and the product. No weighting, no semantic similarity — just a simple intersection. For example, if the user cohorts are [“female”, “beauty”, “budget”] and a lipstick has [“female”, “beauty”, “luxury”], the overlap is 2. If a men’s deodorant has [“male”, “personal_care”, “sport”], the overlap with that same user is 0.
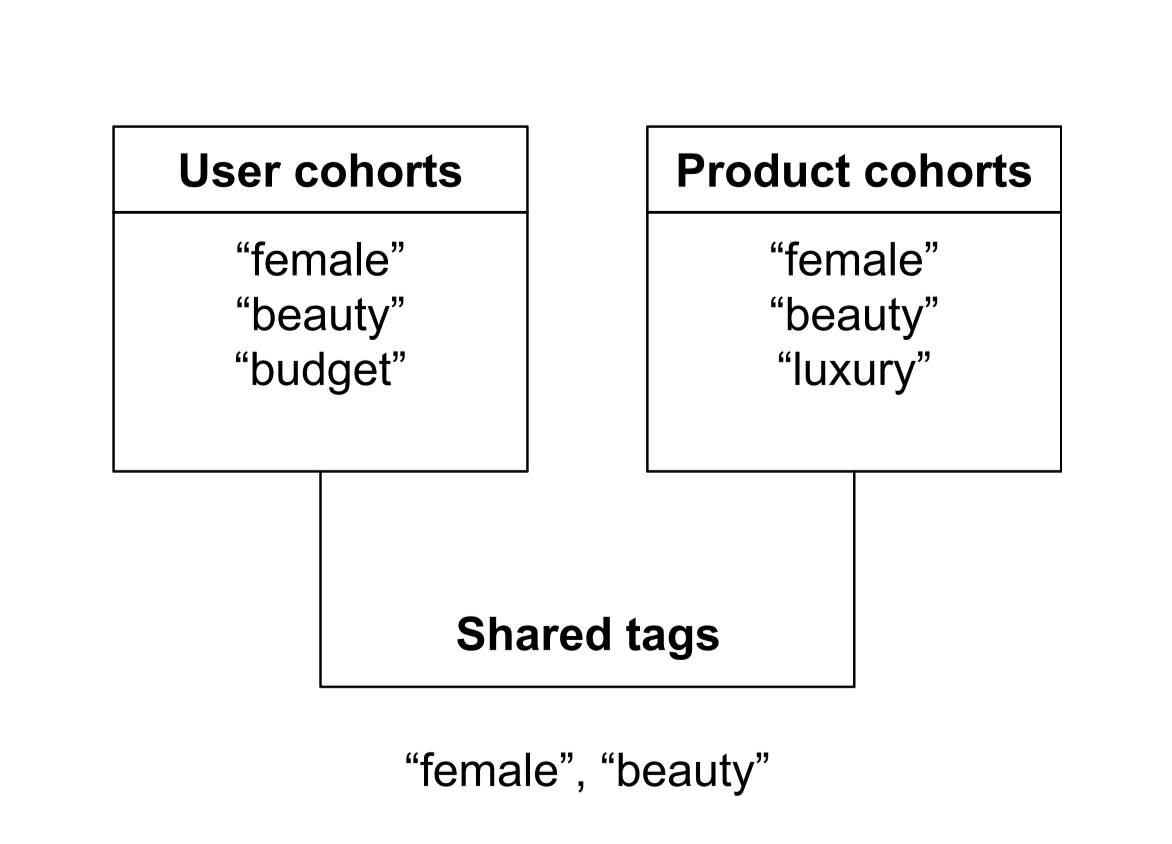
The intuition is that (a) BM25 ranks documents depending on how relevant they are to the user’s query, and (b) cohort overlap boosts products based on how well each product aligns with the user's segment. To accomplish this, we transform the cohort overlap between the user cohorts and the product cohorts into a multiplicative boost that scales BM25.
To avoid field explosion, we keep all cohort tags in a single keyword field, such as follows:
This is easy for merchandisers to understand, avoids hundreds of boolean fields like is_female or is_luxury, and works efficiently with term filters.
Why additive boosts don’t work
One subtle but important point is that even a standard boolean query is additive. When Elasticsearch scores a document, the base BM25 score from the main query (typically in a must) and every matching should clause contributes an additive score. This means “additive boosting” is not just about boosts, it’s fundamental to how boolean scoring works.
Personalization built on additive logic behaves inconsistently because BM25 scales differ per query and dataset. For example the base BM25 scores for three products might be 12, 8, 4 in one instance, and might be 0.12, 0.08, 0.04 after updating your dataset or modifying your query. In this case an additive boost (e.g., +2.0) becomes a dominating force when the base BM25 scores are small (a +2.0 boost on a score of 0.12 is about 18× higher) or a rounding error when the base BM25 scores are large (+2.0 boost on a score of 12 is only about 1.17× higher). This creates inconsistent, unpredictable ranking behavior.
Why multiplicative boosting is the right shape
If we apply a multiplicative boost, the shape is consistent:
With weight_per_cohort = 0.1, an overlap of 2 gives a boost of 1.2 (20% increase), an overlap of 1 gives a boost of 1.1 (10% increase), and an overlap of 0 gives a boost of 1.0 (no change). This means that a product that is more aligned with the user cohort gets a predictable percentage uplift, regardless of whether its BM25 score is 0.01 or 10.0. BM25 remains the primary signal; cohort alignment gently reshapes the ranking.
How function_score gives us multiplicative behavior
To convert cohort overlap into a controlled percentage boost, we need a way to take the normal BM25 score and scale it up by a factor such as 1.1, 1.2, or 1.3. Elasticsearch does not support multiplying a score directly inside a standard query, but function_score provides exactly this capability: it lets us compute an additional score component and combine it with the base score using a chosen strategy, which is "multiply" for this use case.
Elasticsearch’s function_score lets us implement multiplicative cohort boosting in three steps. First, each cohort match contributes a small weight (e.g., 0.1). Second, we include a baseline weight of 1.0 so that the final multiplier never drops below 1. Third, we sum all cohort contributions using score_mode: "sum" to produce a boost factor that represents (1 + overlap × weight). Finally, we combine this boost factor with the BM25 score using boost_mode: "multiply", which gives us the exact multiplicative behavior we want.
The calculation below shows how the final score is calculated, where BM25 is the base relevance; n is the number of matched cohorts; w is weight_per_cohort (e.g., 0.1); and additive baseline = 1.0:
So, with 2 overlapping cohorts and w = 0.1:
This is exactly the multiplicative behavior we want.
Putting it together: index, data, and baseline ranking
Create a simple index:
Index a few products:
A baseline query for “red lipstick” might look like:
This returns a pure BM25 ranking (without any cohort boosting). In this example, the scores of LIP-001 and LIP-002 will be very close (or identical), because they match the same query terms with similar frequencies and have comparable lengths.
The relative ranking is what matters; the exact numeric scores may differ depending on shard configuration, analyzer differences, or Elasticsearch version.
| Product ID | Description | BM25 score |
|---|---|---|
| LIP-001 | Premium cherry red lipstick with velvet finish | 0.603535 |
| LIP-002 | Affordable matte red lipstick for everyday wear | 0.603535 |
| LIP-003 | Glitter red gloss for parties and festivals | 0.13353139 |

Persona A: high-income luxury shopper
Suppose we know that Persona A fits into the following cohorts:
We translate that into a set of cohort filters, each with a small weight, plus a baseline factor:
For this persona LIP-001 (“Premium cherry red lipstick with velvet finish”) matches “female”, “beauty”, and “luxury” which means that the cohort overlap is 3 and therefore the boost factor is 1.3. On the other hand, LIP-002 and LIP-003 match “female” and “beauty” which results in a boost factor of 1.2.
| Product ID | Description | Base BM25 score | Boost factor | New score |
|---|---|---|---|---|
| LIP-001 | Premium cherry red lipstick with velvet finish | 0.603535 | 1.3x (30%) | 0.7845955 |
| LIP-002 | Affordable matte red lipstick for everyday wear | 0.603535 | 1.2x (20%) | 0.724242 |
| LIP-003 | Glitter red gloss for parties and festivals | 0.13353139 | 1.2x (20%) | 0.16023767 |
As desired for this luxury user, the luxury lipstick (LIP-001) receives the strongest uplift and will tend to rise above similar alternatives in the results.
Persona B: budget-oriented shopper
A budget-conscious shopper might belong to the following cohorts:
["female", "beauty", "budget"]
The query for this user is nearly identical to the previous query, except for the cohort values which now reflect “budget” rather than “luxury”:
For this persona LIP-002 (“Affordable matte red lipstick for everyday wear”) matches “female”, “beauty”, and “budget” which means that the cohort overlap is 3 and therefore the boost factor is 1.3. On the other hand, LIP-001 and LIP-003 match “female” and “beauty” which results in a boost factor of 1.2.
| Product ID | Description | Base BM25 score | Boost factor | New score |
|---|---|---|---|---|
| LIP-002 | Affordable matte red lipstick for everyday wear | 0.603535 | 1.3x (30%) | 0.7845955 |
| LIP-001 | Premium cherry red lipstick with velvet finish | 0.603535 | 1.2x (20%) | 0.724242 |
| LIP-003 | Glitter red gloss for parties and festivals | 0.13353139 | 1.2x (20%) | 0.16023767 |
As desired for this budget user, the budget lipstick (LIP-002) receives the strongest uplift and will tend to rise above similar alternatives in the results.
How to build the cohort filter dynamically (Python example)
You will normally inject the cohort filters at query time based on the user/session profile. For example:
Using term filters on a keyword field is fast, shard-cache friendly, and fully visible in the _explain API, which shows exactly which filters fired and which weights were applied.
How cohort assignment works
Cohort assignment is intentionally left outside Elasticsearch, and is outside the scope of this article. However, sources could include:
- browsing events (“has viewed lipstick” → beauty)
- gender inference (from preferences or marketing profile)
- device characteristics (mobile shopper)
- location (“urban buyer”)
- historical purchases
- marketing segments
- personalization cookies
All of these are input signals, but the scoring mechanism in Elasticsearch remains the same. Elasticsearch does not need to know how you inferred the segments. This separation of concerns keeps Elasticsearch focused on ranking, while your application or data science layer owns the logic for inferring segments.
How to choose the right boost weight
In our examples, we used 0.1 per cohort. This value is tunable. Staying between 0.05 and 0.20 will likely provide good results. You should A/B test weights based on:
- catalog diversity
- number of cohort tags per product
- variability in BM25
- business goals (revenue vs. discovery vs. personalization)
Limit the number of cohorts assigned to each product
Giving a product 20 cohort tags leads to:
- Noise in the signals
- Gaming by merchandisers (“tag everything as luxury”)
- Loss of explainability
- Over-boosting
As a starting point (to be confirmed by your own testing), we recommend:
- Approximately 5 cohorts per product.
- Optionally, an offline validation step (ingest pipeline, CI script, or index-time check) that warns or blocks when more than 5 tags are assigned.
Customized cohort boosting per user
So far, our examples assume every cohort contributes equally. In reality, some users strongly prefer certain segments. In some cases, you might know that certain cohorts are especially important for an individual user. For example:
- A user who almost always buys luxury brands.
- A user who consistently picks budget options.
You can encode this by assigning different weights per cohort instead of a flat 0.1. For example, if your application has detected a “super-luxury” shopper, then you could modify the function scoring as follows:
In the above example matching “female” or “beauty” each add +0.1 while matching luxury adds +0.2. In this example, a product matching all three cohorts would get:
This remains fully explainable, and you can document the configuration (“luxury is 2× as important as other cohorts for this user”). Additionally, the explain API will show exactly how those numbers contributed to the final score.
Conclusion:
This Elasticsearch-native approach to cohort personalization uses only lightweight metadata and standard query constructs, while preserving explainability, stability, and business control over the relevance model. This delivers precise, predictable relevance that ensures the business goals never sacrifice the quality of the search results.
Implementation summary
If you want to adopt this pattern in production, the high-level steps are:
- Add a single keyword field (cohorts) to each product containing 3–5 cohort tags.
- Compute user/session cohorts in your application logic (from browsing, purchase history, CRM, etc.) and pass them with the query.
- Inject dynamic function_score filters into your query with one per user cohort, and each with a small weight (e.g., 0.1), plus a baseline weight (1.0).
- Wrap your existing BM25 query in function_score with score_mode: "sum" and boost_mode: "multiply" to apply multiplicative boosting.
- Tune per-cohort weights (typically 0.05–0.20) based on A/B experiments, ensuring BM25 remains the dominant signal.
These steps let you layer cohort personalization cleanly on top of your existing search relevance, without scripts, ML models, or major architecture changes.
What’s next?
This pattern is a powerful example of how to build sophisticated relevance rules directly into your queries, ensuring speed and reliability.
- Implement custom personalization faster: If you're ready to deploy and optimize this advanced cohort personalization strategy, or to tackle other complex relevance challenges, our team can help you build, tune, and operationalize your Elasticsearch solution quickly. Contact Elastic Services for help implementing this and other advanced search techniques.
- Join the discussion: For general questions about advanced relevance techniques and implementation, join the broader Elastic Stack community for search discussions.
Related Content
July 20, 2026
AI shopping agents: Why context comes before the query
AI shopping agents that guess at your vocabulary make expensive mistakes. Pre-computed catalog context stops the guessing before the first tool call.

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

How to build search analytics on Elastic using OpenTelemetry, no extra pipeline required
How to instrument your search application to use modern Open Telemetry standard to drive insights in to your search and users.
March 31, 2026
From judgment lists to trained Learning to Rank (LTR) models
Learn how to transform judgment lists into training data for Learning To Rank (LTR), design effective features, and interpret what your model learned.

March 5, 2026
Does MCP make search obsolete? Not even close
Explore why search engines and indexed search remain the foundation for scalable, accurate, enterprise-grade AI, even in the age of MCP, federated search, and large context windows.