이제 Elastic Cloud Serverless에서 프로젝트 간 검색(CPS)을 사용할 수 있습니다. FROM logs*같은 단 한 번의 쿼리로 격리된 여러 프로젝트의 데이터를 검색할 수 있습니다. 네트워크 피어링도, 인증서 관리도, 데이터 중복도 필요 없습니다. 프로젝트는 각자의 리전과 클라우드에 그대로 유지되며, 오직 결과만 사용자에게 반환됩니다. 데이터 레지던시 요건, 테넌트 격리, 또는 로그 복사로 인한 높은 전송 비용 문제를 겪고 있는 팀에게 CPS는 데이터가 본래 있어야 할 위치에 정확히 유지되면서도 하나로 쿼리될 수 있음을 의미합니다.
Elastic Cloud Serverless는 이미 인프라 관리 및 버전 업그레이드의 번거로움을 없애고 있습니다. CPS는 여기서 한 걸음 더 나아갑니다. 복잡한 네트워크 피어링과 수동 인증서 관리 방식을 간편한 연결 모델로 대체했습니다. 이제 Elastic Cloud Serverless 프로젝트를 데이터를 위한 단순한 네임스페이스처럼 취급하면 됩니다. 엄격한 데이터 레지던시 법률을 준수해야 하거나 테넌트 데이터를 격리해야 하거나 로그 중복으로 인한 막대한 네트워크 전송 비용을 피해야 하는 경우, CPS를 사용하면 한 번의 쿼리로 데이터가 있는 위치를 정확하게 검색할 수 있습니다.
이 글에서는 CPS의 작동 방식, 프로젝트 태그를 사용하여 검색을 제어하는 방법, 이 새로운 모델이 기존의 클러스터 간 검색(CCS)과 어떻게 다른지 자세히 살펴보겠습니다.
프로젝트 간 검색을 위한 프로젝트 연결 방법
프로젝트 간 검색을 시작하려면 Elastic Cloud 콘솔 또는 API에서 프로젝트를 연결하세요. 연결 방식은 간단하며 단방향으로 이루어집니다. 원본 프로젝트를 선택한 다음, 그 프로젝트가 검색해야 할 프로젝트를 연결합니다. 이러한 연결은 리전, 클라우드 서비스 제공자, 프로젝트 유형에 걸쳐 사용할 수 있으므로 통합된 검색 환경을 유지하면서도, 데이터가 원래 위치에 남아 있을 수 있습니다.
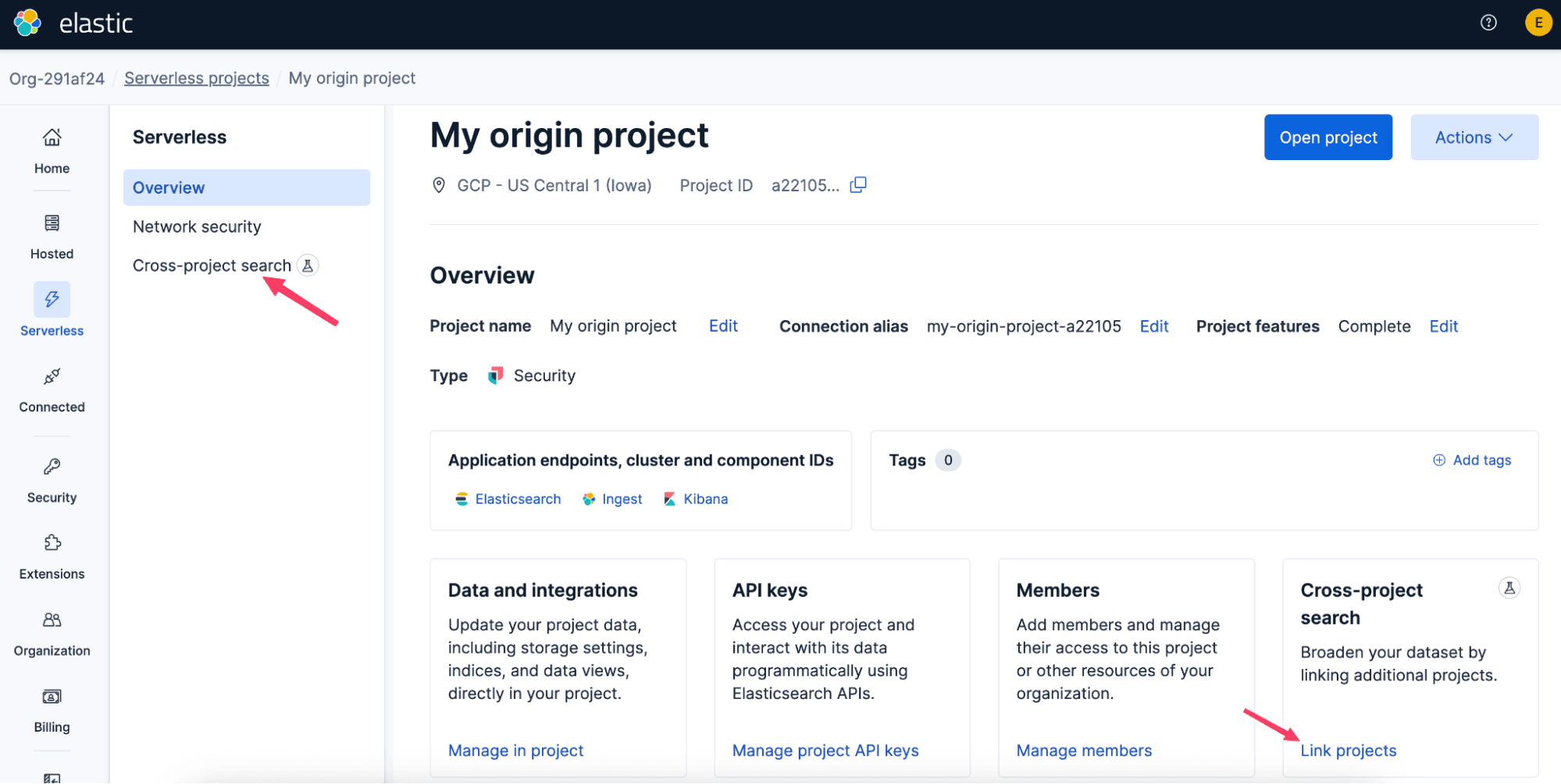
연결이 생성되면 보통 1분 이내에 반영됩니다. 이미 Kibana가 열려 있다면 새로 고침하여 새로운 프로젝트 간 검색 기능을 확인하세요.
프로젝트 간 검색이 연결된 모든 프로젝트를 기본적으로 쿼리하는 방법
프로젝트 연결되면, 프로젝트 간 검색은 분리된 프로젝트 하나의 논리적인 검색 화면으로 전환합니다. 로그가 여러 프로젝트에 걸쳐 분산되어 있더라도, FROM logs* 같은 쿼리는 원본 프로젝트 및 일치하는 데이터가 연결된 모든 프로젝트를 검색합니다. 각 원격 대상을 미리 지정할 필요가 없습니다.
이는 기존의 클러스터 간 검색에 비해 크게 개선된 점입니다. CCS에서 로컬 데이터와 원격 데이터에 모두 접근하려면 보통 FROM logs*,*:logs* 같은 방식으로 작성해야 합니다. 사용자에게는 쿼리의 복잡성이 줄어든다는 것을 의미합니다. 팀에게는 분산된 데이터 전체를 아우르는 진정한 단일 제어 화면에 한 걸음 더 가까워짐을 의미합니다.
이에 대한 자세한 내용은 CPS 검색 모델 문서를 참조하세요.
이를 어떻게 구축했는지 기술적인 세부 사항을 알아보고 싶으시다면, Elasticsearch Serverless의 프로젝트 간 검색(CPS) 작동 방식을 참조하세요.
프로젝트 라우팅을 통한 검색 제어
기본적으로 연결된 모든 프로젝트를 검색하는 방식은 많은 워크플로우에서 편리하고 유용하지만, 모든 검색을 모든 위치에서 수행해야 하는 것은 아닙니다. 프로젝트 간 검색은 쿼리를 특정 프로젝트 서브셋으로 제한할 수 있는 방법인 프로젝트 라우팅을 도입했습니다.
이는 Elastic Cloud에 정의된 프로젝트 태그를 통해 작동합니다. 모든 프로젝트에는 별칭, 클라우드 서비스 제공자, 리전과 같은 기본 제공 속성이 포함되어 있습니다. 또한 조직의 자산 관리 방식에 맞춰 environment:prod, environment:test나 비즈니스 부서, 또는 고객 이름과 같이 고유 태그를 직접 추가할 수도 있습니다. 그러면 Elasticsearch는 해당 메타데이터를 사용하여 어떤 연결된 프로젝트를 검색에 참여시킬지 결정할 수 있습니다.
프로젝트 간 검색을 지원하는 모든 Elasticsearch 엔드포인트는 project_routing 매개변수를 허용합니다. 기술 미리보기에서 라우팅은 프로젝트 별명 사용으로 제한됩니다. 예를 들어, project_routing을 _alias:my-linked-project(으)로 설정하면 쿼리가 해당 연결된 프로젝트로만 전송되며, _alias:_origin(으)로 설정하면 쿼리가 원본 프로젝트에만 머무르게 됩니다. 시간이 흐름에 따라 이 모델은 훨씬 더 풍부한 라우팅의 가능성을 열어 줄 것입니다. 이를 통해 검색 범위가 인프라의 물리적 배치 대신 조직의 논리적 구조를 따르도록 할 수 있습니다.
어떻게 작동하는지 다양한 예시와 자세한 내용이 궁금하시다면 프로젝트 라우팅 문서를 참조하세요.
Kibana Space 수준의 기본 프로젝트 라우팅
검색 라우팅에 더 정밀한 제어가 필요한 대표적인 예로, 연결된 모든 프로젝트를 검색할 경우 Kibana 규칙에서 오탐이 대량으로 발생하거나 기존 대시보드에 혼란스러운 결과가 표시될 수 있습니다. 이를 해결하기 위해 Kibana에서 Space 수준의 기본 프로젝트 범위를 설정할 수 있습니다. 이는 해당 특정 Space를 위한 안전한 사전 설정 역할을 하며, 이에 따라 모든 대시보드, Discover 세션, 알림 규칙이 이 설정을 자동으로 따르게 됩니다. 다만, 분석가는 조사 과정에서 더 넓은 범위의 데이터 확인이 필요한 경우, 범위를 수동으로 재정의할 수 있습니다.
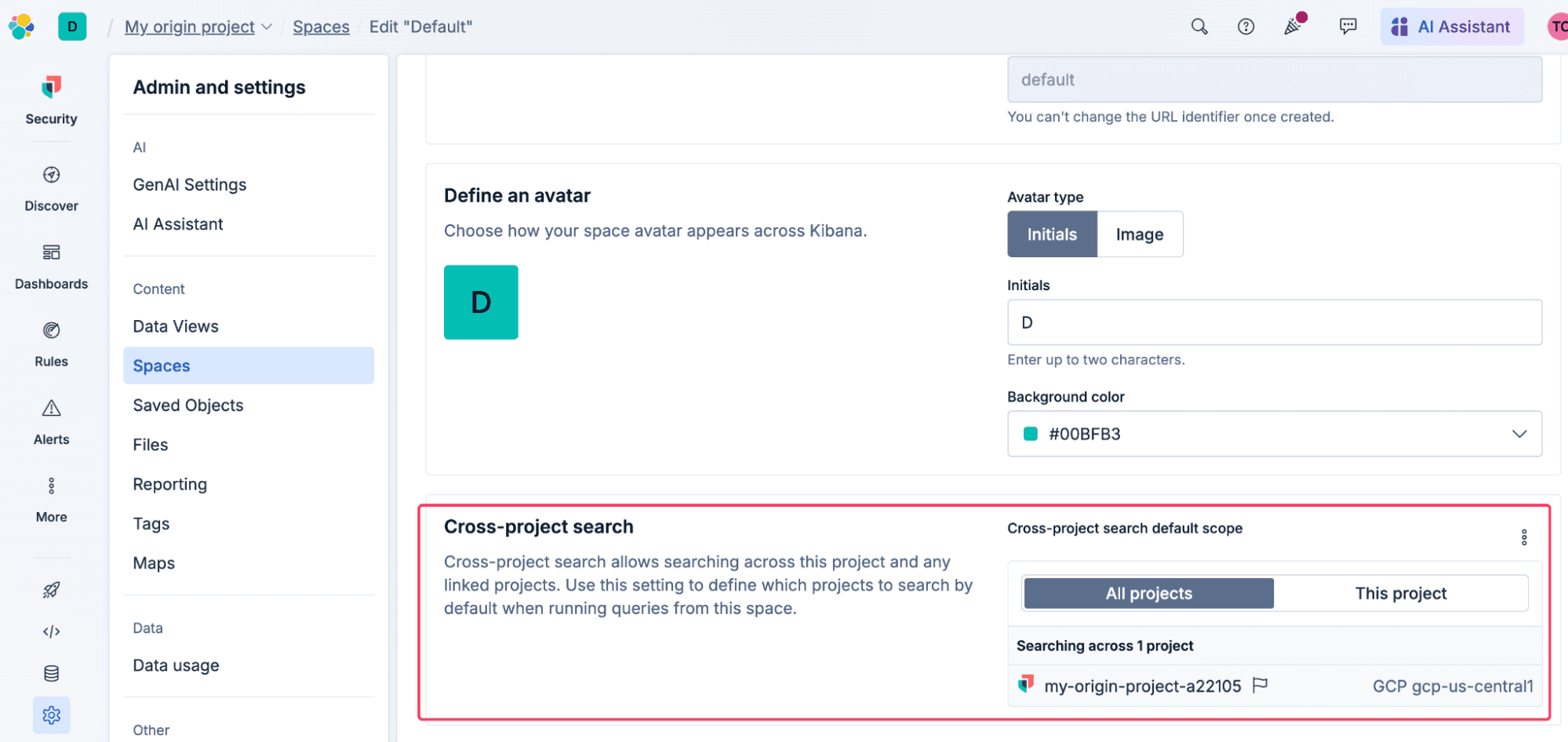
이는 MSP, MSSP, 최고 전문가 조직처럼 중앙 프로젝트를 공유하여 사용하는 팀에게 특히 유용한 기능입니다. 팀별로 전용 Kibana 스페이스를 할당하고 특정 고객 프로젝트만 쿼리하도록 제한함으로써, 테넌트별 맞춤형 경험을 보장할 수 있습니다. 다만, 분석가는 조사 과정에서 더 넓은 범위의 데이터 확인이 필요한 경우, 범위를 수동으로 재정의할 수 있습니다.
클라우드 UI에서 프로젝트를 실제로 연결하기 전이나 후에 이 Space 기본값을 구성할 수 있습니다. 하지만 프로젝트 간 검색(CPS)은 링크가 연결되는 즉시 '전체 검색' 동작이 활성화되므로, Kibana 기본값을 먼저 설정해 두어야 기존 탐지 규칙이 갑자기 방대한 글로벌 데이터셋을 대상으로 실행되어 팀에 과부하가 걸리는 상황을 방지할 수 있습니다.
검색에서 태그 사용
프로젝트 라우팅에 태그를 사용하는 것 외에도 ES|QL 및 _search 쿼리에도 태그를 사용할 수 있습니다. 이는 결과 집합에서 각 레코드나 행의 출처를 식별하거나 해당 태그를 기준으로 정렬, 필터링 또는 집계하는 데 유용할 수 있습니다.
예를 들어, ES|QL 응답의 각 행이 어떤 프로젝트에서 가져온 것인지 확인하고 싶다면 ES|QL 쿼리에 _project._alias 태그를 추가하면 됩니다.
또한 이를 통해 KEEP 절을 포함한 쿼리의 다른 부분에서 _project._alias를 사용할 수 있어 최종 결과에서 이를 확인할 수 있습니다.
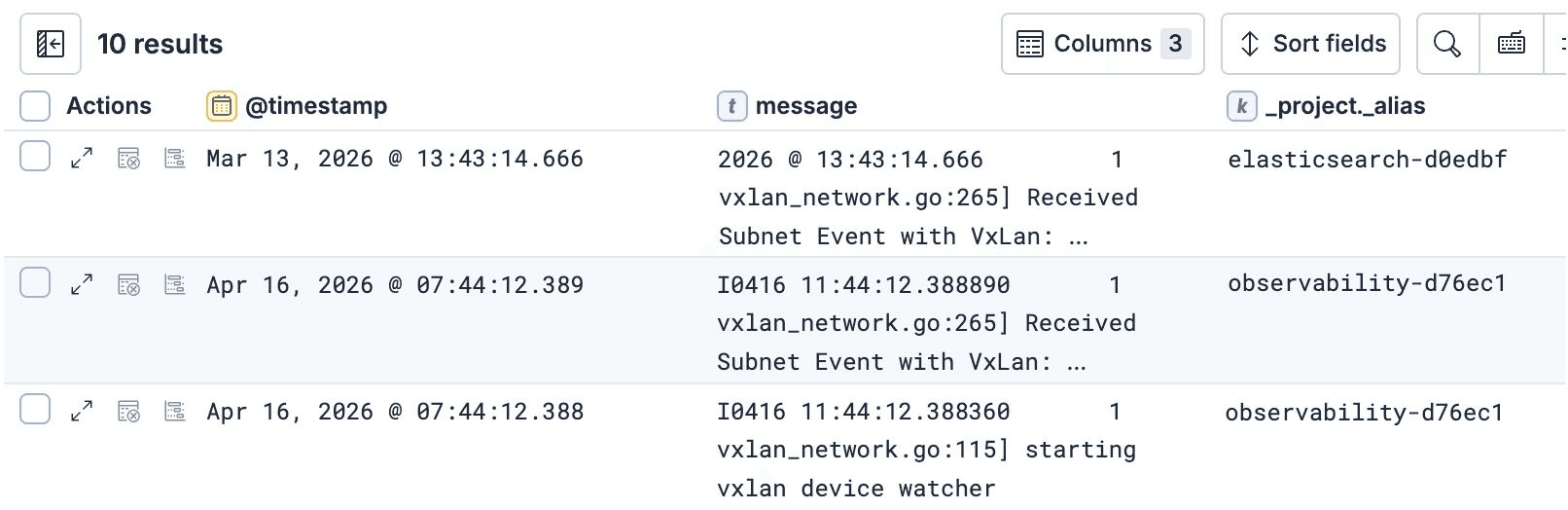
쿼리에서 태그를 사용하는 더 많은 예시는 Search API와 ES|QL 모두에서 태그를 사용하는 방법을 설명하는 이 문서를 참조하세요.
Search와 ES|QL 쿼리에 태그를 어떻게 추가했는지 기술적인 세부 사항이 궁금하시다면 프로젝트 태그 및 라우팅을 이용한 Elasticsearch Serverless의 더 빠른 프로젝트 간 검색을 참조하세요.
프로젝트 간 검색 시 원본 프로젝트와 연결된 프로젝트를 동일하게 처리하는 방법
기존에 클러스터 간 검색(CCS)을 사용해 보셨다면, 로컬 클러스터와 원격 클러스터가 몇 가지 측면에서 서로 다르게 처리된다는 점을 알고 계실 것입니다.
- 로컬 클러스터의 오류는 원격 클러스터에서 발생하는 오류와는 다르게 처리됩니다. 특히, CCS는 원격 클러스터의 오류가 어떻게 작동할지 제어하기 위해 skip_unavailable 설정을 사용하지만, 이 설정은 로컬 클러스터에는 존재하지 않습니다.
- 로컬 클러스터에는 '클러스터 별칭'이 없기 때문에, 인덱스 표현식
*:logs*은(는) 모든 원격 프로젝트를 검색하지만, 로컬 클러스터는 건너뛸 수 있습니다. 둘 다 검색하려면 인덱스 표현식logs*,*:logs*을(를) 사용해야 합니다.
하지만 CPS에서는 이 두 가지 동작을 모두 변경하여, 원본 프로젝트와 연결된 프로젝트가 훨씬 더 동등한 위치에서 처리되도록 했습니다.
먼저, skip_unavailable 설정은 Elastic Cloud Serverless에서 사용되지 않습니다. 대신, _search나 _async_search에서는 allow_partial_search_results 매개변수를, ES|QL에서는 allow_partial_results 매개변수를 사용하여 검색 시 부분 결과를 허용할지 여부를 제어합니다.
둘째, Elastic Cloud Serverless에서는 원본 프로젝트도 프로젝트 별칭이 있습니다. 별칭은 모든 프로젝트 태그와 마찬가지로 Elastic Cloud에서 정의됩니다. 따라서 CPS에서는 아래의 모든 쿼리가 동일하게 처리되며, 'logs' 인덱스를 가진 모든 프로젝트를 대상으로 합니다.
주의: 누락된 인덱스에 대한 오류 처리가 작동하는 방식과 관련하여, 정규화된 인덱스 표현식*:logs와(과) 비정규화된 표현식 logs 사이에는 중요한 차이점이 있습니다. 자세한 내용은 공개 문서의 비정규화 및 정규화된 검색 표현식을 참조하세요.
프로젝트 간 검색을 위한 액세스 제어 및 보안 모델
Elastic은 프로젝트 간 검색의 핵심 원칙을 가능하게 하는 새로운 클라우드 기반 보안 모델인 보편적 신원 및 액세스 관리(UIAM)를 구축했습니다. 핵심은 액세스할 수 있는 프로젝트와 데이터는 접근하는 위치에 영향을 받지 않는다는 것입니다.
기본 통합 가시성 프로젝트에서 검색을 시작하든, 혹은 임시 분석 프로젝트에서 시작하든 상관없이 액세스 권한이 중앙 위치에서 정의되었기 때문에 연결된 데이터에 대한 액세스 권한은 일관되게 유지됩니다. 클라우드 기반 인증 및 권한 부여 모델은 클라우드 UIAM 서비스를 사용하여 원본 프로젝트와 관계없이 액세스 권한이 동일하게 유지되도록 보장합니다.
프로젝트 간 검색 사용해 보기
궁극적으로, Elastic Cloud Serverless와 CPS를 함께 사용하면 운영상의 마찰을 줄일 수 있으며, 물리적 또는 운영상의 고려 사항이 아닌 논리적인 고려 사항을 바탕으로 데이터를 구성할 수 있는 추가적인 선택지를 얻게 됩니다. 프로젝트 간 검색을 통해 사용자는 데이터의 논리적 구성에만 온전히 집중할 수 있으며, 과거의 물리적 복잡성에서 벗어나 통합된 검색 환경을 경험할 수 있습니다.
자주 묻는 질문
Elastic Serverless에서 프로젝트 간 검색이란 무엇인가요?
프로젝트 간 검색(CPS)은 단 한 번의 Elasticsearch 또는 ES|QL 요청으로 격리된 여러 서버리스 프로젝트의 데이터를 쿼리할 수 있는 Elastic Cloud Serverless의 기능입니다. 프로젝트는 Elastic Cloud 콘솔에서 연결되며, 한 번 연결되면 `FROM logs*`와 같은 쿼리가 별도의 추가 구성 없이 원본 프로젝트와 연결된 모든 프로젝트를 자동으로 쿼리합니다.
프로젝트 간 검색은 클러스터 간 검색(CCS)과 어떻게 다른가요?
클러스터 간 검색(CCS)은 자체 관리형 또는 스테이트풀 Elasticsearch 클러스터를 연결하며, 네트워크 피어링, 수동 인증서 관리, 그리고 명시적인 원격 클러스터 주소 지정(예: `*:logs*`)이 필요합니다. CPS는 Elastic Cloud Serverless에서 이를 간편한 프로젝트 연결 모델로 대체합니다. 이 모델에서는 원본 프로젝트와 연결된 프로젝트들이 동등하게 취급되며, 비정규화된 단일 인덱스 표현식으로 이 모든 프로젝트를 검색합니다.
프로젝트 간 검색을 사용하려면 데이터를 복사하거나 복제해야 하나요?
아닙니다. CPS는 검색 시점에 여러 프로젝트에 걸쳐 쿼리를 연합하여 실행합니다. 데이터는 각 프로젝트에 그대로 유지되며, 오직 쿼리 결과만 집계되어 반환되므로 데이터를 중복 저장할 때 발생하는 스토리지 및 네트워크 전송 비용을 방지할 수 있습니다.
프로젝트 간 검색을 특정 프로젝트로 제한하려면 어떻게 해야 하나요?
지원되는 모든 Elasticsearch 엔드포인트에서 `project_routing` 매개변수를 사용하세요. 특정 프로젝트로 쿼리를 제한하려면 프로젝트 별칭(예: `_alias:my-project`)으로 라우팅할 수 있으며, Kibana Space 수준에서 기본 프로젝트 범위를 설정하여 해당 Space의 모든 대시보드와 알림이 자동으로 올바른 프로젝트로 범위를 지정할 수 있습니다.
프로젝트 간 검색은 여러 리전 및 클라우드 서비스 제공자에서 작동하나요?
네. CPS는 서로 다른 리전 및 클라우드 서비스 제공자 간의 프로젝트 연결을 지원합니다. 데이터는 프로젝트 간에 이동하지 않으며 오직 검색 결과만 원본 프로젝트로 반환되므로, 데이터 레지던스 규정을 위반하지 않습니다.
CPS의 연결된 프로젝트에서 액세스 제어는 어떻게 작동하나요?
CPS는 중앙 집중식 클라우드 기반 모델인 보편적 신원 및 액세스 관리(UIAM)를 사용합니다 어떤 프로젝트에서 쿼리를 실행하든 관계없이 액세스 권한이 일관되게 적용되므로, 사용자는 연결된 모든 프로젝트에서 자신에게 액세스 권한이 있는 데이터만 볼 수 있습니다.
검색 중 연결된 프로젝트를 사용할 수 없게 되면 어떻게 되나요?
연결된 프로젝트를 사용할 수 없을 때 쿼리가 일부 결과만 반환할지 아니면 실패할지 제어하려면, `_search` 또는 `_async_search`에서 `allow_partial_search_results` 매개변수를 사용하거나 ES|QL에서 `allow_partial_results`를 사용하세요. CPS에는 CCS에 있는 것과 같은 `skip_unavailable` 설정이 없습니다.
관련 콘텐츠

2026년 4월 20일
Elastic Cloud Serverless 및 Elasticsearch용 통합 API 키 소개
Elastic이 글로벌 분산형 IAM 아키텍처를 통해 서버리스 환경에서 컨트롤 플레인과 데이터 플레인 인증을 어떻게 통합하는지 알아보세요. 클라우드 및 Elasticsearch API에 하나의 API 키를 사용하세요.

2026년 3월 24일
서버리스 환경 로드 밸런싱을 위한 Elasticsearch 복제본
Elastic Cloud Serverless가 검색 부하에 따라 인덱스 복제본을 자동으로 조정하여 수동 구성 없이도 최적의 쿼리 성능을 보장하는 방법을 확인해 보세요.
2026년 1월 22일
Agent Builder 정식 출시: 컨텍스트 기반 에이전트, 몇 분 만에 구축 가능
Agent Builder가 이제 정식 출시되었습니다. 컨텍스트 기반 AI 에이전트를 신속하게 개발할 수 있는 방법을 알아보세요.

2026년 1월 14일
더 높은 처리량과 낮은 지연 시간: 성능이 크게 향상된 AWS의 Elastic Cloud Serverless
Elasticsearch Serverless에 대한 AWS 인프라를 더 새롭고 빠른 하드웨어로 업그레이드했습니다. 획기적인 성능 향상이 어떻게 더 빠른 쿼리, 더 나은 확장, 더 저렴한 비용으로 이어지는지 확인해 보세요.

2025년 3월 4일
Elasticsearch 서버리스 프로젝트를 관리하기 위한 AI 에이전트
자연어 기반 AI 에이전트로, Elasticsearch 서버리스 프로젝트를 손쉽게 관리하여 프로젝트 생성, 삭제, 상태 확인을 지원합니다.