La recherche inter-projets (CPS) est désormais disponible dans Elastic Cloud Serverless. Avec une seule requête comme FROM logs*, vous pouvez rechercher des données sur plusieurs projets isolés : pas de peering réseau, pas de gestion de certificats, pas de duplication de données. Les projets restent dans leurs pays et clouds respectifs, seuls les résultats vous sont transmis. Pour les équipes confrontées à des exigences de résidence des données, à l’isolation des locataires ou à des coûts de sortie élevés liés à la copie des logs, CPS signifie que vos données peuvent rester exactement là où elles doivent être et être interrogées comme une seule entité.
Elastic Cloud Serverless vous permet déjà de gérer les mises à niveau de l’infrastructure et des versions. CPS va encore plus loin. Nous avons remplacé le peering réseau complexe et la gestion manuelle des certificats par un modèle simple de liaison. Désormais, vous pouvez considérer vos projets Elastic Cloud Serverless comme de simples espaces de noms pour vos données. Que vous soyez confronté à des lois strictes sur la résidence des données, à l’isolation des données des locataires ou que vous cherchiez simplement à éviter les frais de sortie réseau exorbitants liés à la duplication des logs, CPS vous permet de rechercher vos données exactement là où elles se trouvent en une seule requête.
Dans cet article, nous verrons comment fonctionne le CPS, comment contrôler les recherches à l’aide de balises de projet et en quoi ce nouveau modèle diffère de la recherche cross-cluster (CCS) traditionnelle.
Comment relier des projets pour une recherche inter-projets
Pour commencer à utiliser la recherche inter-projets, reliez les projets dans la console Elastic Cloud ou dans l’API. La liaison est simple et unidirectionnelle : choisissez un projet d’origine, puis connectez les projets dans laquelle la recherche doit s’effectuer. Ces liens peuvent porter sur plusieurs pays, fournisseurs cloud et types de projets, afin que vos données restent là où elles doivent être, sans pour autant renoncer à une expérience de recherche unifiée.
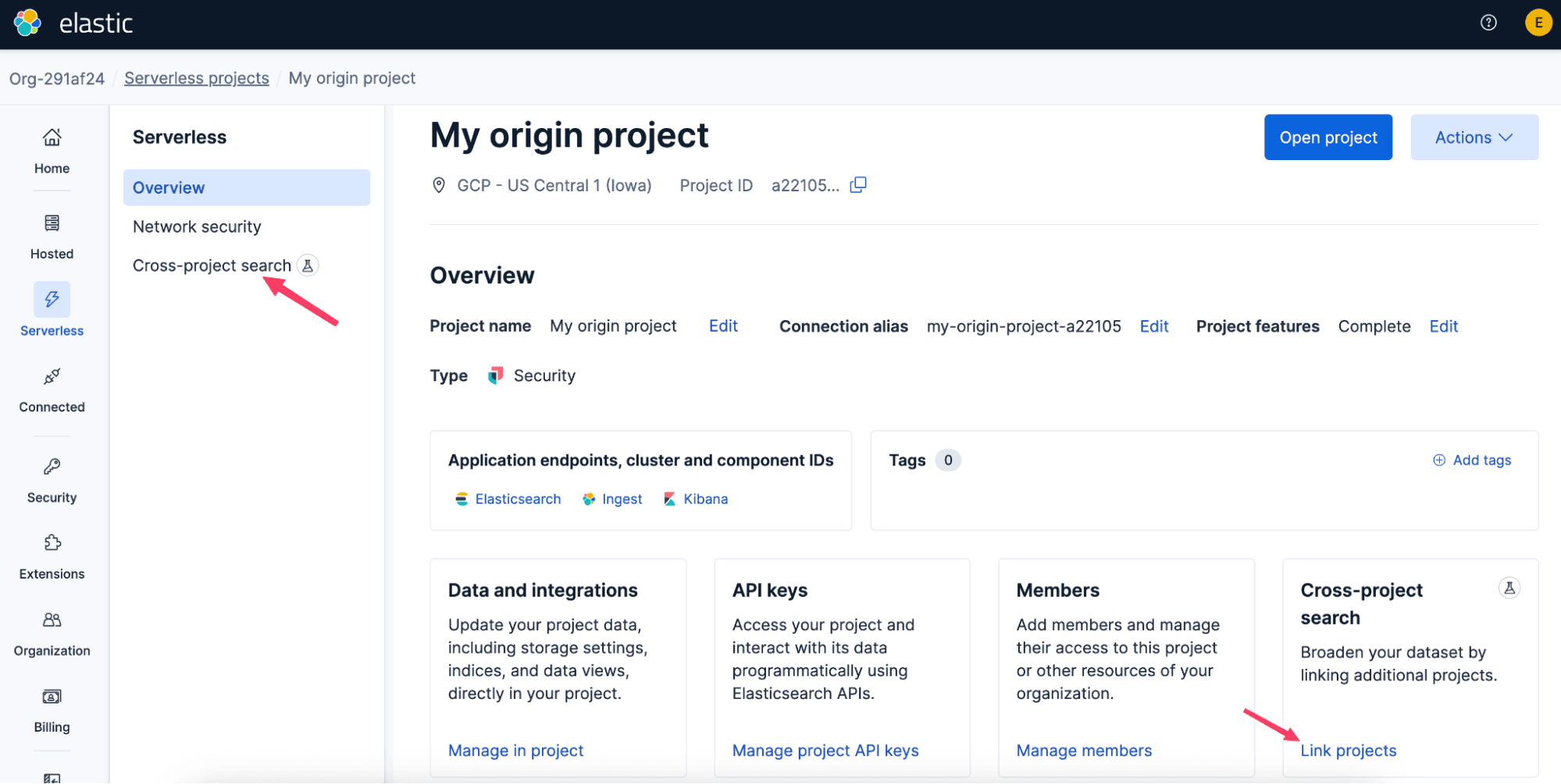
Une fois le lien créé, il prend généralement effet en une minute environ. Si vous avez déjà Kibana ouvert, actualisez pour voir les nouvelles fonctionnalités de recherche inter-projets.
Comment la recherche inter-projets interroge tous les projets liés par défaut
Une fois les projets liés, la recherche inter-projets transforme des projets séparés en une seule surface logique de recherche. Si vos logs concernent plusieurs projets, une requête comme FROM logs* permet de rechercher le projet d’origine et tout projet lié contenant des données correspondantes. Vous n’avez pas besoin de nommer chaque cible distante à l’avance.
C’est une amélioration majeure par rapport à la recherche inter-clusters. Dans CCS, pour accéder à des données locales et distantes, il faut souvent écrire ce type de code : FROM logs*,*:logs*. Pour les utilisateurs, cela signifie une moindre complexité des requêtes. Pour les équipes, cela nous rapproche d’un véritable tableau de bord unique à travers des données distribuées.
Pour plus d’informations concernant ce sujet, consultez la documentation du modèle de recherche CPS .
Si vous souhaitez obtenir des détails techniques sur la façon dont nous avons construit ce système, consultez Comment la recherche inter-projets (CPS) fonctionne dans Elasticsearch Serverless.
Contrôle des recherches via le routage de projet
La recherche par défaut dans tous les projets liés est pratique et utile pour de nombreux workflows, mais toutes les recherches ne doivent pas nécessairement s’étendre à l’ensemble. La recherche inter-projets introduit le routage de projets, qui permet de limiter une requête à un sous-ensemble spécifique de projets.
Il fonctionne grâce aux balises de projet définies dans Elastic Cloud. Chaque projet possède des attributs intégrés tels que son alias, son fournisseur cloud et sa région. Vous pouvez également ajouter vos propres tags pour refléter la façon dont votre organisation perçoit son domaine, comme environment:prod, environment:test, une unité commerciale ou un nom client. Elasticsearch peut alors utiliser ces métadonnées pour décider quels projets liés doivent participer à une rechercher.
Tous les endpoints Elasticsearch qui prennent en charge la recherche inter-projets acceptent un paramètre project_routing. Dans l’aperçu technique, le routage est limité à l’utilisation d’alias de projet. Par exemple, si vous attribuez à project_routing la valeur _alias:my-linked-project, la requête est envoyée uniquement au projet lié, tandis que _alias:_origin maintient la requête sur le projet d’origine. Au fil du temps, ce modèle ouvre la porte à un routage beaucoup plus riche, où la portée de la recherche peut suivre la structure logique de votre organisation au lieu de la disposition physique de votre infrastructure.
Consultez les documents de routage du projet pour obtenir des exemples et plus de détails sur leur fonctionnement.
Routage par défaut de projet au niveau spatial Kibana
Par exemple, lorsque vous avez besoin de plus de précision pour le routage de recherche, la recherche dans tous les projets liés peut déclencher une multitude de faux positifs dans vos règles Kibana ou des résultats déroutants dans vos tableaux de bord existants. Pour corriger cela, vous pouvez définir une portée de projet par défaut au niveau spatial dans Kibana. Il s’agit d’un préréglage sûr pour cet espace spécifique pour que tous les tableaux de bord, les sessions Discover et les règles d’alerting le respectent automatiquement. Les analystes peuvent toujours modifier manuellement la portée pendant une investigation s’ils ont besoin d’une vue plus large.
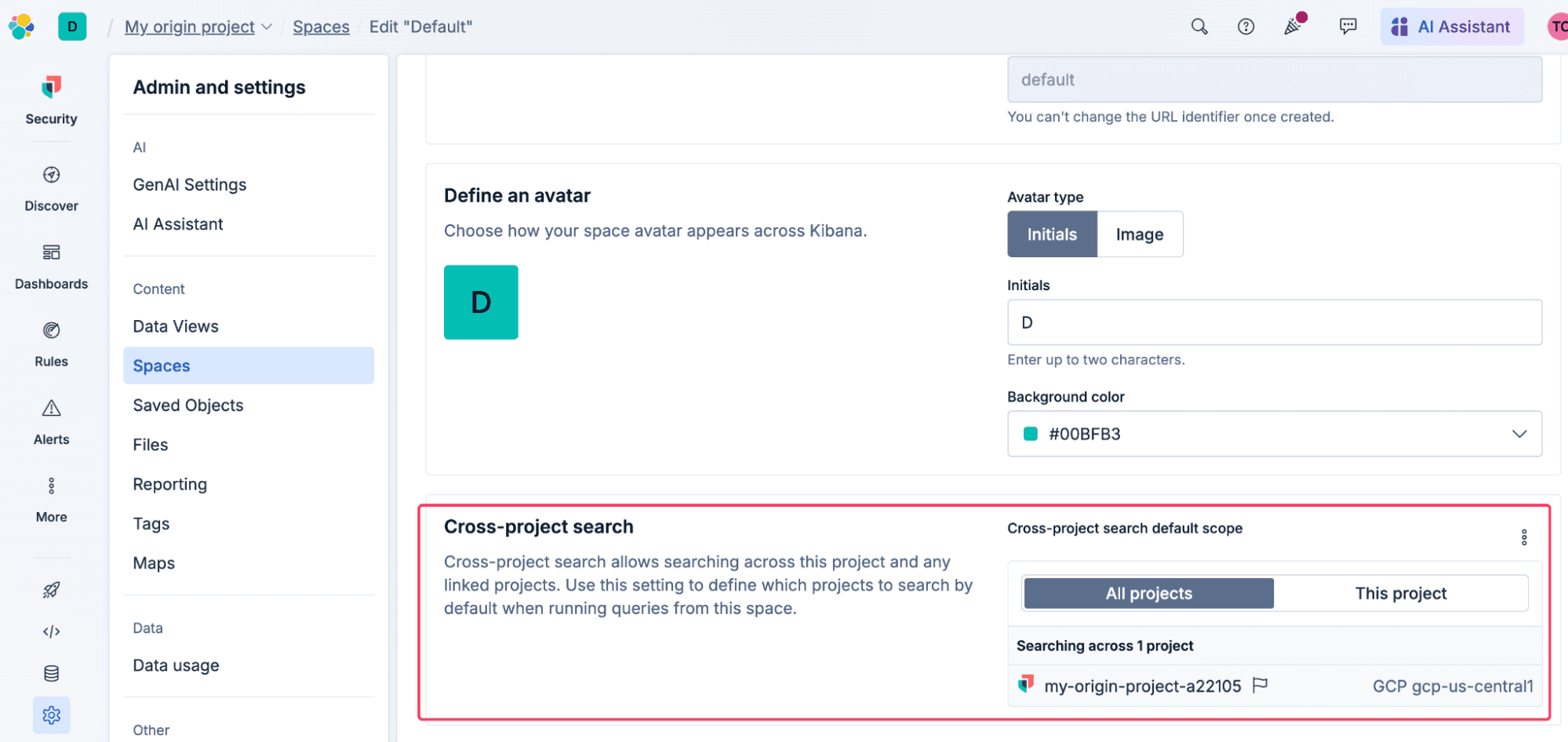
Cela est important pour les équipes partageant un projet central, telles que les MSP, les MSSP et les centres d’excellence : vous pouvez attribuer à chaque équipe son propre espace Kibana et le limiter à l’interrogation de leurs projets clients spécifiques, garantissant ainsi des expériences adaptées à chaque locataire. Les analystes peuvent toujours modifier manuellement la portée pendant une investigation s’ils ont besoin d’une vue plus large.
Vous pouvez configurer cet espace par défaut avant ou après avoir lié vos projets dans l’interface utilisateur du cloud. Mais comme CPS active immédiatement le comportement « rechercher tout » dès qu’un lien est créé, il est recommandé de définir d’abord les paramètres par défaut Kibana pour garantir que vos règles de détection existantes ne se retrouvent pas soudainement sur un immense ensemble de données globales et ne submergent pas votre équipe.
Utilisation des balises dans les recherches
En plus d’utiliser des balises pour le routage des projets, vous pouvez également utiliser des balises dans vos requêtes ES|QL et _search. Cela peut être utile pour identifier la provenance de chaque enregistrement ou ligne d’un ensemble de résultats, ou pour trier, filtrer ou agréger par ces balises.
Par exemple, si vous souhaitez savoir de quel projet provient chaque ligne d’une réponse ES|QL, vous pouvez ajouter la balise _project._alias à la requête ES|QL :
et cela vous permet d’utiliser _project._alias dans d’autres parties de la requête, y compris les clauses KEEP, afin de le voir dans le résultat final :
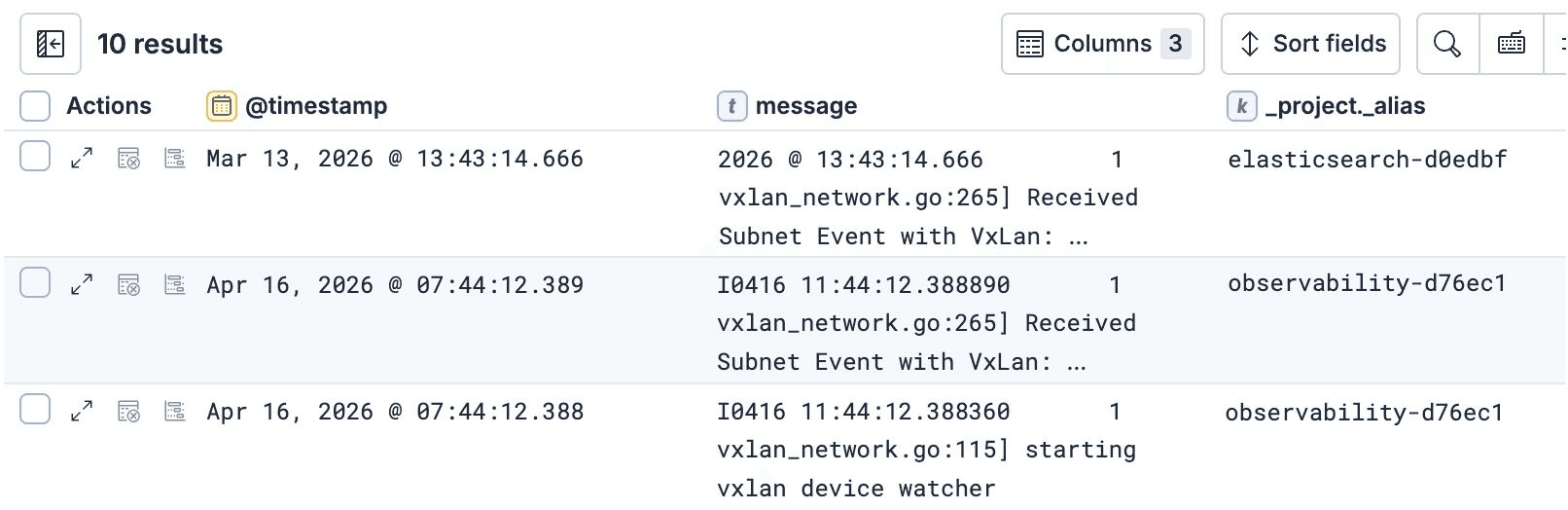
Pour plus d’exemples d’utilisation des balises dans les requêtes, consultez ce document qui décrit comment les utiliser à la fois dans les API de recherche et en ES|QL.
Si vous souhaitez en savoir plus sur les détails techniques concernant l’ajout de balises à Search et aux requêtes ES|QL, consultez Recherche inter-projets plus rapide dans Elasticsearch Serverless avec balises de projet et routage.
Comment la recherche inter-projets gère les projets d’origine et les projets liés de manière égale
Si vous avez utilisé CCS, vous savez peut-être que le cluster local est traité différemment des clusters distants à plusieurs égards.
- Les erreurs provenant du cluster local sont traitées différemment de celles provenant de clusters distants. En particulier, CCS utilise le paramètre skip_unavailable pour contrôler le comportement des erreurs provenant de clusters distants, mais ce paramètre n’existe pas pour le cluster local.
- Le cluster local n’a pas d’« alias de cluster », donc l’expression d’indice
*:logs*recherche tous les projets distants, mais saute le cluster local. Pour rechercher les deux, il faut utiliser l’expression d’indicelogs*,*:logs*.
Dans CPS, nous avons modifié ces deux comportements pour mettre le projet d’origine et les projets liés sur un pied d’égalité.
Premièrement, le paramètre skip_unavailable n’est pas utilisé dans Elastic Cloud Serverless. C’est vous qui décidez si vous souhaitez obtenir des résultats partiels lors d’une recherche via le paramètre allow_partial_search_results dans _search ou _async_search ou le paramètre allow_partial_results dans ES|QL.
Deuxièmement, dans Elastic Cloud Serverless, le projet d’origine a un alias de projet. Il est défini dans Elastic Cloud comme toutes les balises de projet. Ainsi, dans CPS, toutes les requêtes ci-dessous sont équivalentes, elles ciblent tous les projets avec un index « logs » :
Remarque : il existe une différence importante entre l’expression qualifiée *:logs et l’expression non qualifiée logs en ce qui concerne la gestion des erreurs liées aux indices manquants. Pour plus de détails, consultez la rubrique consacrée aux expressions de recherche non qualifiées et qualifiées dans la documentation publique.
Modèle de contrôle d’accès et de sécurité pour la recherche inter-projets
Elastic a créé un nouveau modèle de sécurité basé sur le cloud, Universal Identity and Access Management (UIAM), qui permet un principe clé pour la recherche inter-projets : les projets et les données auxquels vous pouvez accéder ne dépendent pas de l’endroit où vous y accédez.
Que vous lanciez une recherche à partir de votre projet principal d’observabilité ou d’un projet d’analyse ponctuel, votre accès aux données associées reste le même, puisque les droits d’accès ont été définis de manière centralisée. Le modèle d’authentification et d’autorisation basé sur le cloud utilise le service cloud UIAM pour garantir que vos autorisations d’accès sont uniformes, quel que soit le projet d’origine.
Essayez la recherche inter-projets
Finalement, Elastic Cloud Serverless et CPS permettent ensemble de réduire les difficultés opérationnelles et vous offrent des solutions supplémentaires pour organiser les données en fonction de critères logiques plutôt que physiques ou opérationnelles. La recherche inter-projets permet à vos utilisateurs de se concentrer uniquement sur l’organisation logique de leurs données, offrant ainsi une expérience de recherche unifiée sans les complexités physiques du passé.
Questions fréquentes
Qu'est-ce que la recherche inter-projets dans Elastic Serverless ?
Cross-Project Search (CPS), ou recherche inter-projets, est une fonctionnalité d’Elastic Cloud Serverless qui vous permet d’interroger les données de plusieurs projets sans serveur isolés à l’aide d’une seule requête Elasticsearch ou ES|QL. Les projets sont liés dans la console Elastic Cloud, et une fois liés, une requête telle que « FROM logs* » permet de rechercher automatiquement le projet d’origine et tous les projets liés sans aucune configuration supplémentaire.
En quoi la recherche inter-projets est-elle différente de la recherche inter-clusters (CCS) ?
CCS connecte des clusters Elasticsearch autogérés ou avec état et nécessite un peering réseau, une gestion manuelle des certificats et un adressage explicite de cluster distant (par exemple, « *:logs* »). CPS remplace cela par un simple modèle de liaison de projet dans Elastic Cloud Serverless, où les projets d’origine et liés sont traités de la même manière et où une seule expression d’index non qualifiée les recherche tous.
Dois-je copier ou dupliquer des données pour utiliser la recherche inter-projets ?
Non. CPS fédère les requêtes entre les projets au moment de la recherche. Vos données restent dans chaque projet, et seuls les résultats de la requête sont agrégés et retournés, évitant ainsi le coût de stockage et de sortie réseau lié à la duplication des données.
Comment limiter une recherche inter-projets à des projets spécifiques ?
Utilisez le paramètre « project_routing » sur tous les points de terminaison Elasticsearch compatibles. Vous pouvez utiliser un alias de projet (par exemple, « _alias:mon-projet ») pour limiter une requête à un seul projet, ou définir un périmètre de projet par défaut au niveau de l’espace Kibana afin que tous les tableaux de bord et les alertes de cet espace soient automatiquement liés aux bons projets.
La recherche inter-projets fonctionne-t-elle dans différents pays et avec différents fournisseurs cloud ?
Oui. CPS prend en charge les liens de projet entre les pays et les fournisseurs cloud. Les données ne circulent pas entre les projets. Seuls les résultats de recherche sont renvoyés à l’origine, ce qui permet de respecter les réglementations liées à la localisation des données.
Comment fonctionne le contrôle d’accès entre les projets liés dans les CPS ?
CPS utilise la gestion universelle des identités et des accès (UIAM), un modèle centralisé basé sur le cloud. Vos droits d’accès sont appliqués de manière cohérente, quel que soit le projet depuis lequel vous lancez une requête. Ainsi, un utilisateur ne peut voir que les données auxquelles il est autorisé à accéder sur tous les projets liés.
Que se passe-t-il si un projet lié n’est pas disponible pendant une recherche ?
Utilisez le paramètre « allow_partial_search_results » dans « _search » ou « _async_search », ou « allow_partial_results » dans ES|QL, pour vérifier si une requête retourne des résultats partiels ou échoue lorsqu’un projet lié n’est pas disponible. Il n’y a pas de paramètre « skip_unavailable » dans CPS comme il y en a dans CCS.
Pour aller plus loin

20 avril 2026
Présentation des clés API unifiées pour Elastic Cloud Serverless et Elasticsearch
Découvrez comment Elastic unifie l’authentification des plans de contrôle et des plans de données dans Serverless grâce à une architecture IAM distribuée à l’échelle mondiale. Utilisez une seule clé API pour les API Cloud et Elasticsearch.

24 mars 2026
Répliques Elasticsearch pour l'équilibrage de charge dans Serverless
Découvrez comment Elastic Cloud Serverless ajuste automatiquement les répliques d'index en fonction de la charge de recherche, garantissant une performance optimale des requêtes sans configuration manuelle.
22 janvier 2026
Agent Builder est maintenant en disponibilité générale : créez des agents contextuels en quelques minutes
Agent Builder est maintenant en disponibilité générale. Découvrez comment il vous permet de développer rapidement des agents d'IA contextuels.

14 janvier 2026
Débit plus élevé et latence plus faible : Elastic Cloud Serverless sur AWS bénéficie d'une amélioration significative des performances–
Nous avons mis à niveau l'infrastructure AWS pour Elasticsearch Serverless vers du matériel plus récent et plus performant. Découvrez comment cette amélioration considérable des performances permettent des requêtes plus rapides, une scalabilité plus réactive et des coûts réduits.

4 mars 2025
L'agent IA pour gérer les projets Elasticsearch Serverless
Un agent d'IA alimenté par le langage naturel qui gère sans effort les projets Elasticsearch Serverless, permettant la création, la suppression et la vérification de l'état des projets.