La búsqueda entre proyectos (CPS) ya está disponible en Elastic Cloud Serverless. Con una sola búsqueda, como FROM logs*, puedes buscar datos en varios proyectos aislados, sin peering de red, gestión de certificados ni duplicación de datos. Los proyectos permanecen en sus propias regiones y clouds; solo recibes los resultados. Para los equipos que se ocupan de requisitos de residencia de datos, aislamiento de usuarios o alto egreso de costos al copiar logs, CPS significa que tus datos pueden vivir exactamente en el lugar en el que pertenecen y, aun así, ser buscados como si fueran uno solo.
Elastic Cloud Serverless ya elimina los dolores de cabeza de administrar la infraestructura y las actualizaciones de versiones. CPS lleva eso un paso más allá. Hemos reemplazado el peering de red complejo y la gestión manual de certificados con un modelo de vinculación simple. Ahora puedes tratar tus proyectos Elastic Cloud Serverless como simples espacios de nombres para tus datos. Ya sea que tengas que cumplir con estrictas leyes de residencia de datos, aislar los datos de los usuarios o simplemente evitar los altos costos de tráfico saliente que genera la duplicación de logs, CPS te permite buscar tus datos exactamente donde se encuentran con una sola consulta.
En esta publicación, explicaremos cómo funciona CPS, cómo controlar las búsquedas mediante etiquetas de proyecto y en qué se diferencia este nuevo modelo de la búsqueda entre clústeres tradicional (CCS).
Cómo vincular proyectos para la búsqueda entre proyectos
Para empezar a usar la búsqueda entre proyectos, vincula los proyectos en la consola de Elastic Cloud o mediante la API. La vinculación es simple y unidireccional: eliges un proyecto de origen y luego conectas los proyectos en los que debería buscar. Esos enlaces pueden abarcar distintas regiones, proveedores cloud y tipos de proyectos, por lo que tus datos pueden permanecer donde deben estar sin que por ello renuncies a una experiencia de búsqueda unificada.
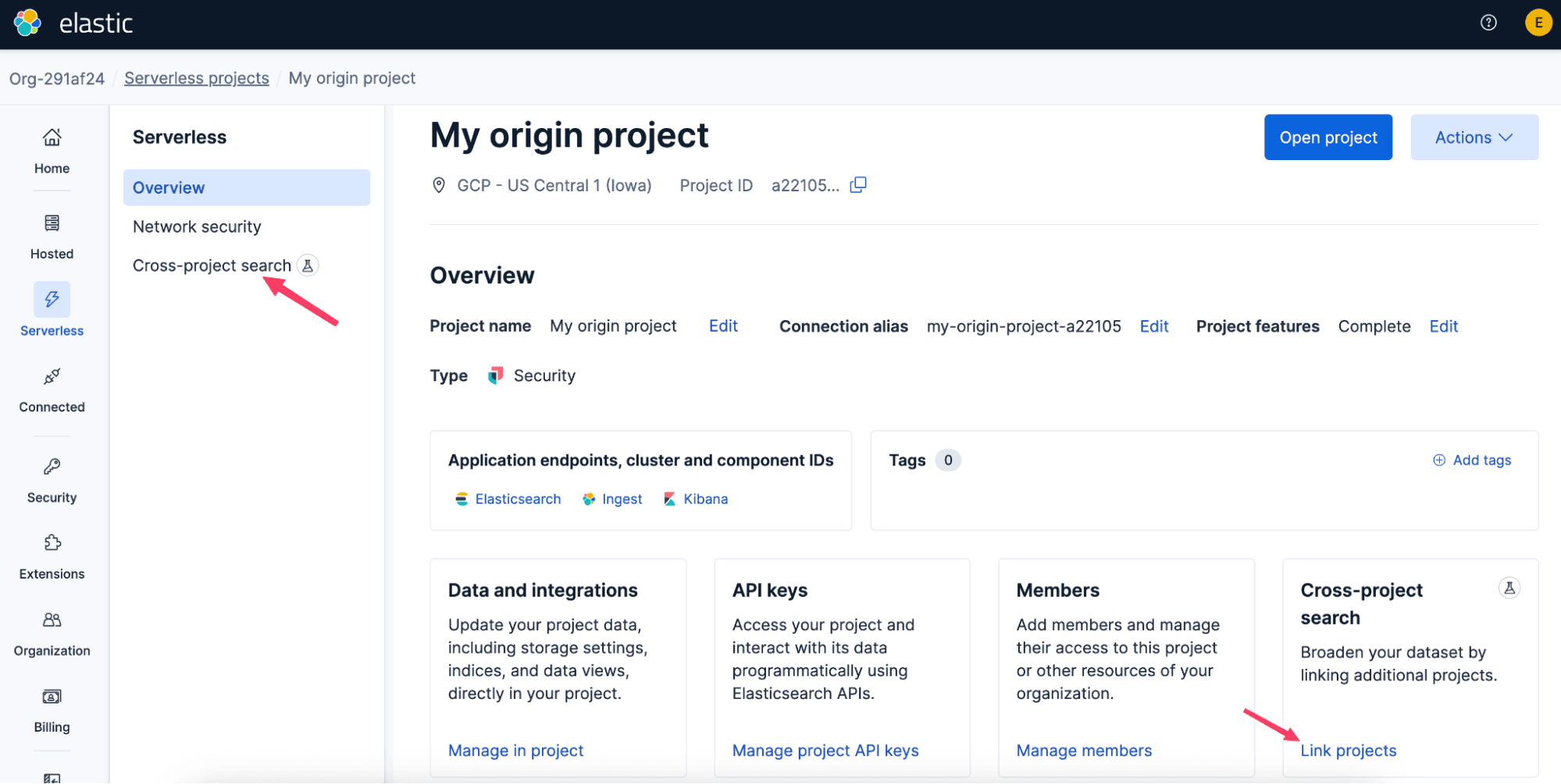
Una vez creado el enlace, suele estar vigente en un minuto, aproximadamente. Si ya tienes Kibana abierto, actualiza para ver las nuevas capacidades de búsqueda entre proyectos.
Cómo la búsqueda entre proyectos consulta todos los proyectos vinculados en forma predeterminada
Una vez vinculados los proyectos, la búsqueda entre proyectos convierte los proyectos independientes en una única superficie de búsqueda lógica. Si tus logs están en varios proyectos, una búsqueda como FROM logs* busca en el proyecto de origen y en cualquier proyecto vinculado que tenga datos coincidentes. No es necesario nombrar cada objetivo remoto por adelantado.
Eso es una gran mejora con respecto a la búsqueda entre clústeres. En CCS, llegar a datos locales y remotos suele indicar que hay que escribir algo así como FROM logs*,*:logs*. Para los usuarios, eso significa menos complejidad de búsqueda. Para los equipos, esto nos acerca a una verdadera vista unificada de los datos distribuidos.
Para obtener más información sobre este tema, consulta los documentos del modelo de búsqueda CPS.
Si te interesa conocer los detalles técnicos sobre cómo lo creamos, consulta Cómo funciona la búsqueda entre proyectos (CPS) en Elasticsearch Serverless.
Control de búsquedas mediante el enrutamiento de proyectos
La búsqueda en todos los proyectos vinculados de forma predeterminada es conveniente y útil para muchos flujos de trabajo, pero no todas las búsquedas deben ir a todas partes. La búsqueda entre proyectos presenta el enrutamiento de proyectos, una forma de limitar una búsqueda a un subconjunto específico de proyectos.
Funciona mediante etiquetas de proyecto definidas en Elastic Cloud. Cada proyecto tiene atributos integrados como su alias, el proveedor cloud y la región. También puedes agregar tus propias etiquetas para reflejar cómo tu organización piensa sobre su patrimonio, como environment:prod, environment:test, una unidad de negocio o el nombre de un cliente. Entonces, Elasticsearch puede usar esos metadatos para decidir qué proyectos vinculados deben participar en una búsqueda.
Todos los endpoints de Elasticsearch que admiten la búsqueda entre proyectos aceptan un parámetro project_routing . En la versión preliminar técnica, el enrutamiento se limita al uso de alias de proyecto. Por ejemplo, configurar project_routing en _alias:my-linked-project envía la búsqueda solo a ese proyecto vinculado, mientras que _alias:_origin mantiene la búsqueda en el proyecto de origen. Con el tiempo, este modelo abre la puerta a un enrutamiento mucho más completo, en el que el alcance de la búsqueda puede seguir la estructura lógica de tu organización, en lugar de la disposición física de tu infraestructura.
Consulta los documentos de enrutamiento del proyecto para ver ejemplos y más detalles sobre cómo funcionan.
Enrutamiento de proyecto predeterminado a nivel del espacio de Kibana
Por ejemplo, si necesitas más precisión en la configuración de tus rutas de búsqueda, buscar en todos los proyectos vinculados podría generar una avalancha de falsos positivos en tus reglas de Kibana o resultados confusos en tus dashboards actuales. Para solucionar esto, puedes establecer un alcance de proyecto predeterminado a nivel de espacio en Kibana. Esto actúa como un preset seguro para ese espacio específico, lo que significa que todos los dashboards, las sesiones de Discover y las reglas de alerta lo respetan automáticamente. Los analistas aún pueden modificar el alcance manualmente durante una investigación si necesitan tener una perspectiva más amplia.
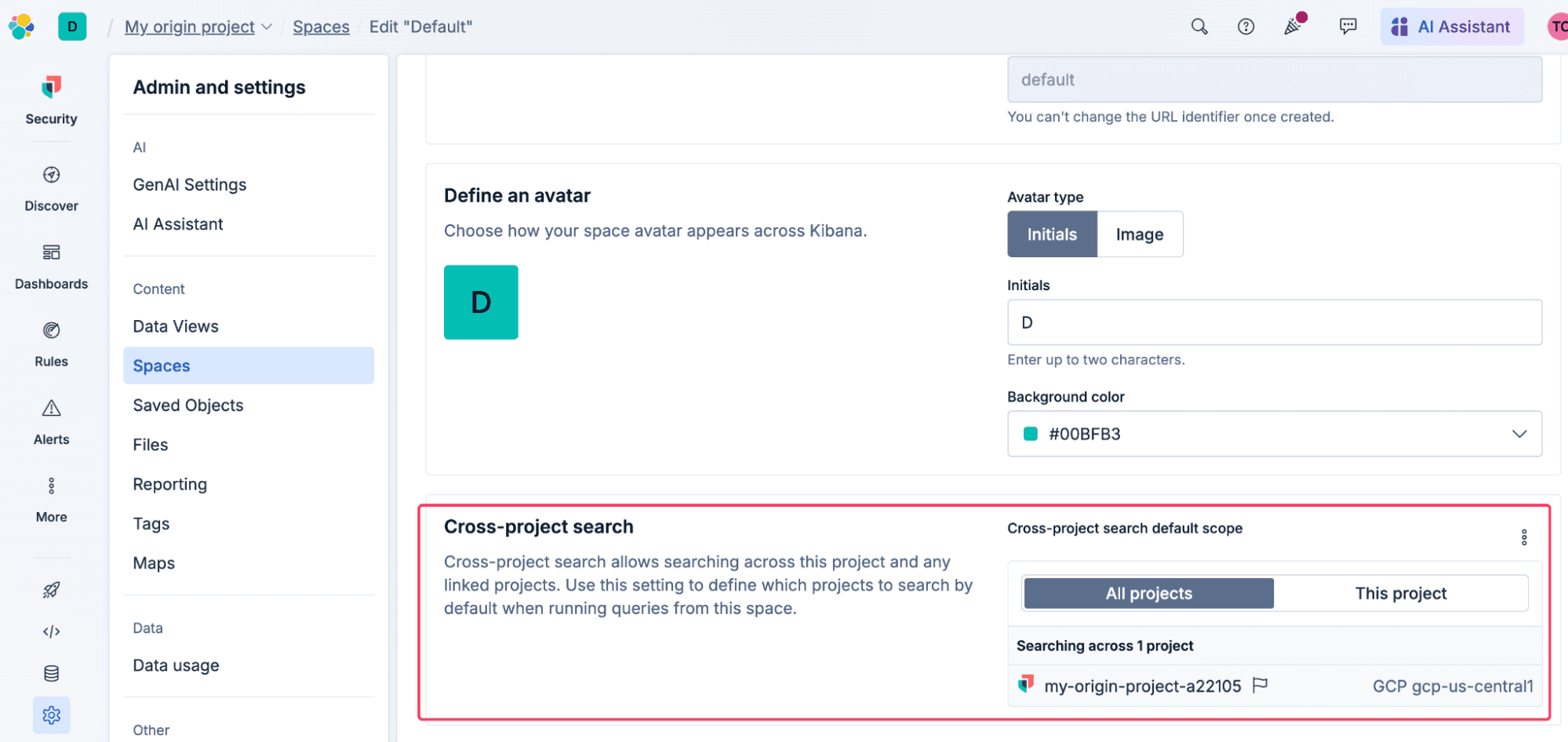
Esto es importante para los equipos que comparten un proyecto central, como los MSP, los MSSP y los centros de excelencia: puedes asignar a cada equipo su propio espacio de Kibana y restringirlo para que solo busquen los proyectos específicos de sus clientes, garantizando experiencias específicas para cada usuario. Los analistas aún pueden modificar el alcance manualmente durante una investigación si necesitan tener una perspectiva más amplia.
Puedes configurar este espacio predeterminado antes o después de vincular tus proyectos en la UI de cloud. Pero como CPS activa inmediatamente la función de "buscar todo" en cuanto se crea un enlace, configurar primero tus valores predeterminados de Kibana garantiza que las reglas de detección existentes no se ejecuten repentinamente contra un gran set de datos global y saturen a tu equipo.
Uso de etiquetas en búsquedas
Además de usar etiquetas para el enrutamiento de proyectos, también puedes usarlas en tus búsquedas ES|QL y _search. Esto puede ser útil para saber de dónde viene cada registro o fila de un conjunto de resultados o para ordenar, filtrar o agregar datos según esas etiquetas.
Por ejemplo, si quieres ver de qué proyecto proviene cada fila de una respuesta ES|QL, puedes agregar la etiqueta _project._alias a la búsqueda ES|QL:
y esto te permite usar _project._alias en otras partes de la búsqueda e incluir cláusulas KEEP para verlo en el resultado final:
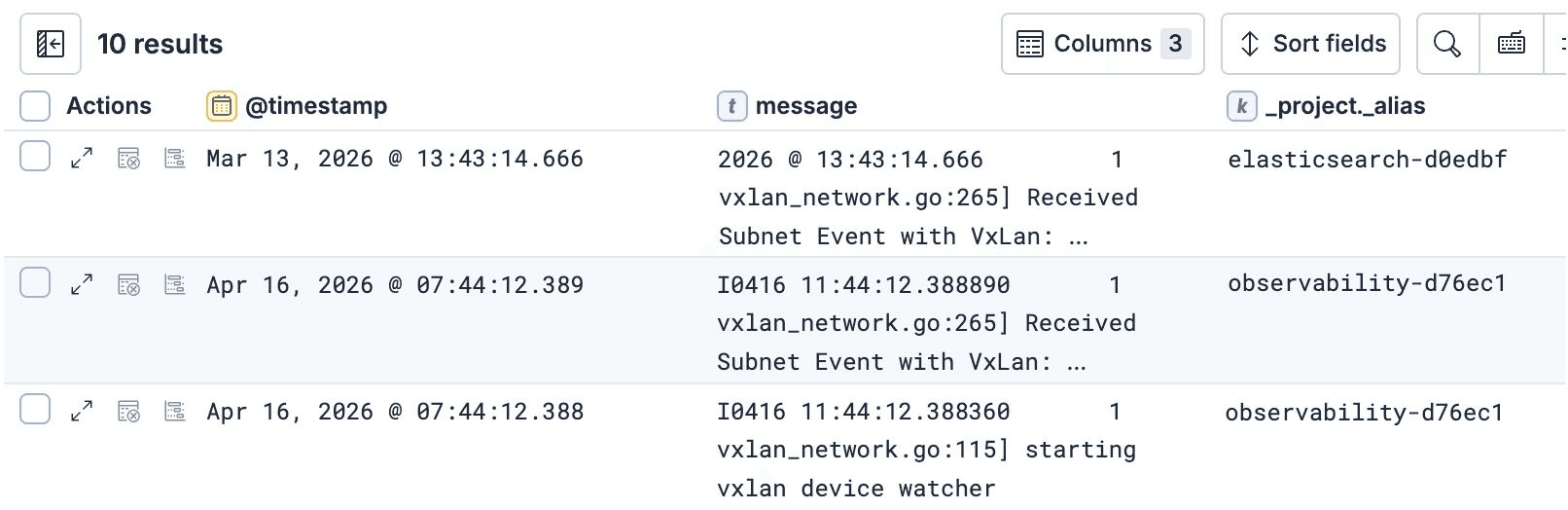
Para ver más ejemplos del uso de etiquetas en las búsquedas, consulta este documento que describe cómo usarlas tanto en las API de búsqueda como en ES|QL.
Si le interesa conocer los detalles técnicos sobre cómo agregamos etiquetas a las búsquedas en Search y en ES|QL, consulta Búsqueda entre proyectos más rápida en Elasticsearch Serverless con etiquetas de proyecto y enrutamiento.
Cómo la búsqueda entre proyectos trata por igual los proyectos de origen y los proyectos vinculados
Si usaste CCS, es posible que sepas que el cluster local se trata de forma diferente a los clústeres remotos en varios aspectos.
- Los errores del cluster local se manejan de manera diferente de los errores de los clústeres remotos. En concreto, CCS usa la configuración skip_unavailable para controlar cómo se gestionan los errores de los clústeres remotos, pero esa configuración no existe para el cluster local.
- El cluster local no tiene un "alias de cluster", por lo que la expresión índice
*:logs*busca en todos los proyectos remotos, pero omite el cluster local. Para buscar en ambos, tienes que usar la expresión índicelogs*,*:logs*.
En CPS, cambiamos ambos de estos comportamientos para igualar el proyecto de origen y los proyectos vinculados.
En primer lugar, la configuración skip_unavailable no se usa en Elastic Cloud Serverless. En cambio, tú controlas si quieres obtener resultados parciales en una búsqueda a través del parámetro allow_partial_search_results en _search o _async_search o del parámetro allow_partial_results en ES|QL.
En segundo lugar, en Elastic Cloud Serverless, el proyecto de origen tiene un alias de proyecto. Se define en Elastic Cloud como todas las etiquetas del proyecto. Por lo tanto, en CPS, todas las búsquedas que figuran a continuación son equivalentes, se dirigen a todos los proyectos con un índice de "logs":
Nota: Hay una diferencia importante entre la expresión índice calificada *:logs y la expresión no calificada logs en cuanto a cómo funciona el manejo de errores en torno a índices faltantes. Para obtener más detalles, consulta Expresiones de búsqueda calificadas y no calificadas en la documentación pública.
Modelo de control de acceso y seguridad para la búsqueda entre proyectos
Elastic ha creado un nuevo modelo de seguridad basado en el cloud, Universal Identity and Access Management (UIAM), que hace posible un principio clave para la búsqueda entre proyectos: los proyectos y los datos a los que puedes acceder no dependen del lugar desde donde lo hagas.
Ya sea que inicies una búsqueda desde tu proyecto principal de observabilidad o desde un proyecto de analítica ad hoc, tu acceso a los datos vinculados se mantiene constante, ya que los derechos de acceso se definieron en una ubicación centralizada. El modelo de autenticación y autorización basado en el cloud usa el servicio UIAM en el cloud para garantizar que tus permisos de acceso sean uniformes, independientemente del proyecto de origen.
Prueba la búsqueda entre proyectos
En definitiva, Elastic Cloud Serverless y CPS juntos reducen los problemas operativos y ofrecen opciones adicionales para organizar los datos sobre la base de consideraciones lógicas, en lugar de físicas u operativas. La búsqueda entre proyectos les permite a tus usuarios centrarse únicamente en la organización lógica de sus datos, lo que ofrece una experiencia de búsqueda unificada sin las complejidades físicas del pasado.
Preguntas frecuentes
¿Qué es la búsqueda entre proyectos en Elastic Serverless?
La búsqueda entre proyectos (CPS) es una característica de Elastic Cloud Serverless que te permite buscar datos en varios proyectos aislados sin servidor con una única solicitud de Elasticsearch o ES|QL. Los proyectos se vinculan en la consola de Elastic Cloud y, una vez vinculados, una consulta como "FROM logs*" busca automáticamente en el proyecto de origen y en todos los proyectos vinculados sin necesidad de usar ninguna configuración adicional.
¿En qué se diferencia la búsqueda entre proyectos de la búsqueda entre clústeres (CCS)?
CCS conecta clústeres de Elasticsearch autogestionados o con estado y requiere peering de red, gestión manual de certificados y direccionamiento explícito de clústeres remotos (por ejemplo, "*:logs*"). CPS reemplaza esto con un modelo simple de vinculación de proyectos en Elastic Cloud Serverless, donde el proyecto de origen y los proyectos vinculados se tratan por igual y una sola expresión de índice no calificada busca en todos ellos.
¿Necesito copiar o duplicar datos para usar Cross-Project Search?
No. CPS federa las búsquedas entre proyectos en el momento de la búsqueda. Tus datos permanecen en cada proyecto, y solo los resultados de las búsquedas se agregan y entregan, lo que evita el costo de almacenamiento y de tráfico saliente de duplicar datos.
¿Cómo puedo limitar una búsqueda entre proyectos a proyectos específicos?
Usa el parámetro "project_routing" en cualquier endpoint de Elasticsearch compatible. Puedes usar un alias de proyecto (por ejemplo, "_alias:my-project") para limitar una búsqueda a un solo proyecto, o establecer un ámbito de proyecto predeterminado a nivel del espacio de Kibana para que todos los dashboards y alertas de ese espacio se apliquen automáticamente a los proyectos correctos.
¿La búsqueda entre proyectos funciona en diferentes regiones y proveedores cloud?
Sí. CPS admite enlaces de proyectos entre regiones y proveedores cloud. Los datos no se mueven entre proyectos, solo se entregan los resultados de búsqueda al origen, por lo que no se violan las restricciones de residencia de datos.
¿Cómo funciona el control de acceso en proyectos vinculados en CPS?
CPS usa Universal Identity and Access Management (UIAM), un modelo centralizado basado en el cloud. Tus derechos de acceso se aplican de manera consistente, independientemente del proyecto desde el que ejecutes una búsqueda, por lo que un usuario solo puede ver los datos a los que está autorizado a acceder en todos los proyectos vinculados.
¿Qué sucede si un proyecto vinculado no está disponible durante una búsqueda?
Usa el parámetro "allow_partial_search_results" en "_search" o "_async_search", o "allow_partial_results" en ES|QL, para controlar si una búsqueda entrega resultados parciales o falla cuando un proyecto vinculado no está disponible. En CPS, no existe la opción "skip_unavailable" como sí está en CCS.
Contenido relacionado

20 de abril de 2026
Introducción de claves API unificadas para Elastic Cloud Serverless y Elasticsearch
Aprende cómo Elastic unificó la autenticación del plano de control y del plano de datos en Serverless con una arquitectura de IAM distribuida globalmente. Usa una sola clave de API para las API de Cloud y de Elasticsearch.

24 de marzo de 2026
Réplicas de Elasticsearch para balanceo de carga en Serverless
Aprende cómo Elastic Cloud Serverless ajusta automáticamente las réplicas del índice según la carga de búsqueda, lo que garantiza un rendimiento óptimo de búsqueda sin configuración manual.
22 de enero de 2026
Agent Builder ya está disponible para el público en general: envía agentes según el contexto en cuestión de minutos
Agent Builder ahora está disponible para el público en general. Aprende cómo te permite desarrollar rápidamente agentes de IA basados en el contexto.

14 de enero de 2026
Mayor rendimiento y menor latencia: Elastic Cloud Serverless en AWS recibe un aumento significativo del rendimiento
Hemos actualizado la infraestructura de AWS para Elasticsearch Serverless con hardware más nuevo y rápido. Descubre cómo este aumento masivo del rendimiento ofrece consultas más rápidas, mejor escalado y menores costos.

4 de marzo de 2025
El agente de IA para gestionar proyectos serverless de Elasticsearch
Un agente de IA impulsado por lenguaje natural que gestiona sin esfuerzo proyectos Serverless de Elasticsearch, permitiendo la creación, eliminación y comprobación de estado de proyectos.