Die projektübergreifende Suche (CPS) ist jetzt in Elastic Cloud Serverless verfügbar. Mit einer einzigen Abfrage wie FROM logs*kann man Daten über mehrere isolierte Projekte hinweg durchsuchen – kein Netzwerk-Peering, kein Zertifikatsmanagement, keine Datenduplikation. Projekte bleiben in ihren eigenen Regionen und Clouds; nur die Ergebnisse kommen zu Ihnen zurück. Für Teams, die mit Anforderungen an den Datenstandort, der Mandantenisolierung oder hohen Kosten für den Datenabfluss durch das Kopieren von Protokollen zu tun haben, bedeutet CPS, dass Ihre Daten genau dort gespeichert werden können, wo sie hingehören, und trotzdem als Einheit abgefragt werden können.
Elastic Cloud Serverless beseitigt bereits jetzt den Aufwand für die Verwaltung der Infrastruktur und Versionsaktualisierungen. CPS geht noch einen Schritt weiter. Wir haben komplexes Netzwerk-Peering und manuelle Zertifikatsverwaltung durch ein einfaches Verknüpfungsmodell ersetzt. Jetzt können Sie Ihre Elastic Cloud Serverless-Projekte einfach als einfache Namespaces für Ihre Daten behandeln. Ob Sie nun mit strengen Gesetzen zur Datenresidenz zu tun haben, Mandantendaten isolieren müssen oder einfach nur die massiven Netzwerk-Ausgangskosten vermeiden wollen, die durch die Duplizierung von Protokollen entstehen – mit CPS können Sie Ihre Daten genau dort suchen, wo sie sich befinden, und zwar mit einer einzigen Abfrage.
In diesem Beitrag erklären wir, wie CPS funktioniert, wie Sie Ihre Suchanfragen mit Projekt-Tags steuern können und wie sich dieses neue Modell von der herkömmlichen Cross-Cluster Search (CCS) unterscheidet.
So verknüpfen Sie Projekte für die projektübergreifende Suche
Um mit der projektübergreifenden Suche zu beginnen, verknüpfen Sie Projekte in der Elastic Cloud-Konsole oder API. Die Verknüpfung ist einfach und unidirektional: Sie wählen ein Ursprungsprojekt aus und verbinden dann die Projekte, in denen es suchen soll. Diese Verknüpfungen können sich über Regionen, Cloud-Anbieter und Projekttypen erstrecken, sodass Ihre Daten dort bleiben, wo sie hingehören, ohne dass Sie auf ein einheitliches Sucherlebnis verzichten müssen.
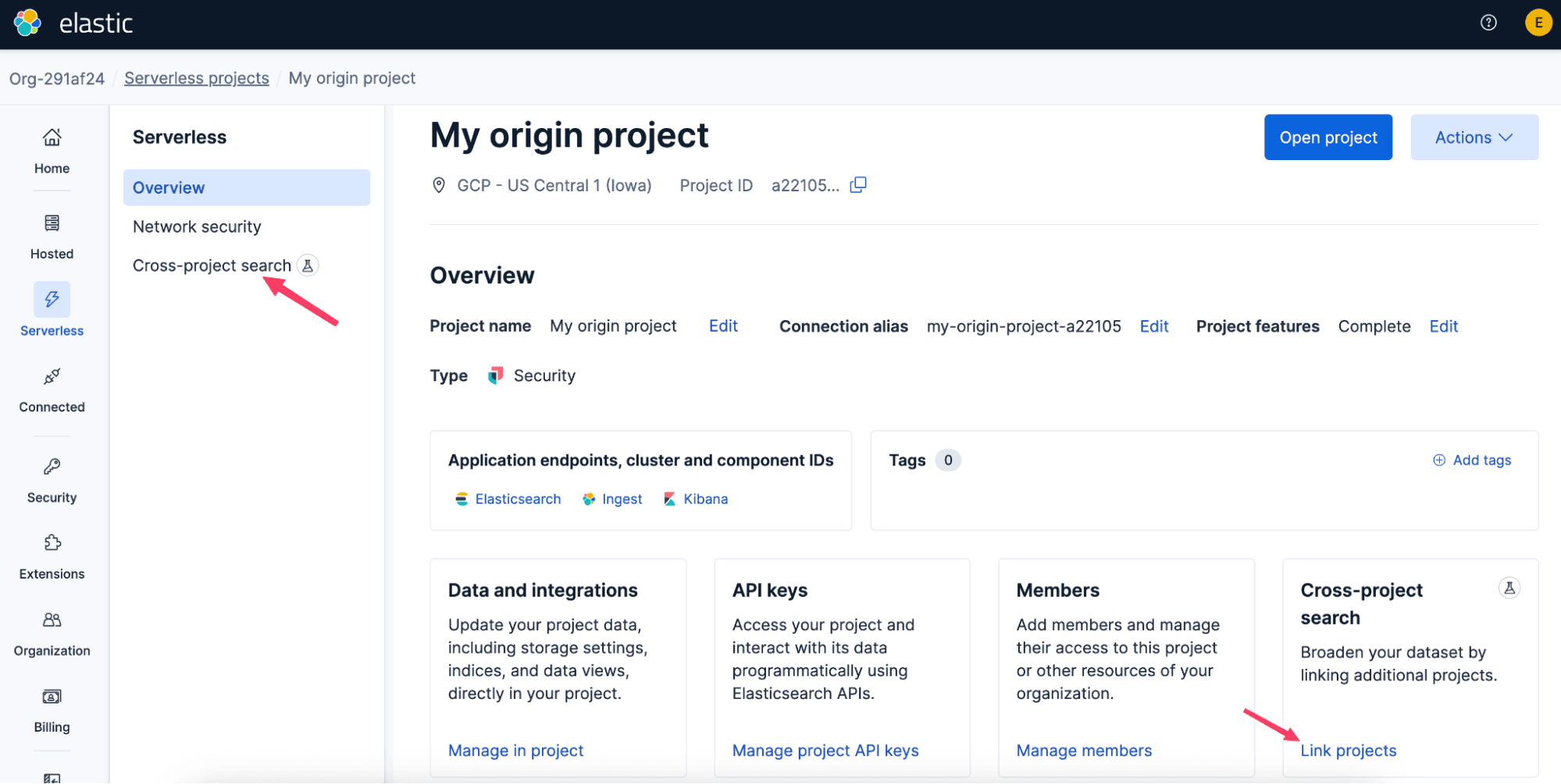
Sobald der Link hergestellt ist, tritt er normalerweise innerhalb von etwa einer Minute in Kraft. Wenn Sie Kibana bereits geöffnet haben, aktualisieren Sie die Seite, um die neuen projektübergreifenden Suchfunktionen zu sehen.
Wie die projektübergreifende Suche standardmäßig alle verknüpften Projekte abfragt
Sobald Projekte verknüpft sind, verwandelt die projektübergreifende Suche separate Projekte in eine einzige logische Suchoberfläche. Wenn Ihre Logs über mehrere Projekte verteilt sind, sucht eine Abfrage wie FROM logs* das Ursprungsprojekt und jedes verknüpfte Projekt, das passende Daten enthält. Sie müssen die einzelnen Remote-Ziele nicht im Voraus benennen.
Das ist eine deutliche Verbesserung gegenüber der clusterübergreifenden Suche (CCS). In CCS bedeutet das Erreichen sowohl lokaler als auch entfernter Daten oft, etwas wie FROM logs*,*:logs* zu schreiben. Für Nutzer bedeutet das weniger Abfragekomplexität. Für Teams bringt uns das einem echten zentralen Überblick über verteilte Daten näher.
Weitere Informationen dazu finden Sie in den CPS-Suchmodelldokumenten .
Wenn Sie daran interessiert sind, technische Details zu erfahren, wie wir das gebaut haben, sehen Sie sich So funktioniert die projektübergreifende Suche (CPS) in Elasticsearch Serverless an.
Steuerung von Suchvorgängen über Projekt-Routing
Die standardmäßige Suche in jedem verknüpften Projekt ist praktisch und nützlich für viele Workflows, aber nicht jede Suche sollte überall durchgeführt werden. Die projektübergreifende Suche führt Projektrouting ein, eine Möglichkeit, eine Abfrage auf eine bestimmte Teilmenge von Projekten zu beschränken.
Es funktioniert über die in Elastic Cloud definierten Projekt-Tags. Jedes Projekt hat integrierte Attribute wie seinen Alias, Cloudanbieter und Region. Sie können auch Ihre eigenen Tags hinzufügen, um zu zeigen, wie Ihr Unternehmen über seinen Bestand denkt, wie environment:prod, environment:test, eine Geschäftseinheit oder einen Kundennamen. Elasticsearch kann diese Metadaten dann verwenden, um zu entscheiden, welche verknüpften Projekte an einer Suche teilnehmen sollen.
Alle Elasticsearch Endpoints, die projektübergreifende Suche unterstützen, akzeptieren einen project_routing Parameter. In der technischen Vorschau ist das Routing auf die Verwendung von Projektalias beschränkt. Wenn Sie beispielsweise project_routing auf _alias:my-linked-project setzen, wird die Anfrage nur an das verknüpfte Projekt gesendet, während _alias:_origin die Anfrage im Ursprungsprojekt belässt. Im Laufe der Zeit eröffnet dieses Modell die Möglichkeit zu einer viel umfangreicheren Routing-Struktur, bei der der Suchbereich der logischen Struktur Ihrer Organisation folgen kann, anstatt dem physischen Layout Ihrer Infrastruktur.
Beispiele und weitere Details zu ihrer Funktionsweise finden Sie in den Dokumenten zum Projektrouting.
Standard-Projektrouting auf der Kibana-Space-Ebene
Ein Beispiel dafür, wo eine höhere Präzision beim Suchrouting erforderlich ist: Die Suche in allen verknüpften Projekten könnte eine Flut von Fehlalarmen in Ihren Kibana-Regeln oder verwirrende Ergebnisse in Ihren bestehenden Dashboards auslösen. Um dieses Problem zu beheben, können Sie in Kibana einen Standardprojektbereich auf Space-Ebene festlegen. Dies dient als sichere Voreinstellung für diesen spezifischen Space – das heißt, alle Dashboards, Discover-Sitzungen und Alerting-Regeln berücksichtigen diese automatisch. Analysten können den Umfang während einer Untersuchung immer noch manuell überschreiben, wenn sie eine breitere Sicht benötigen.
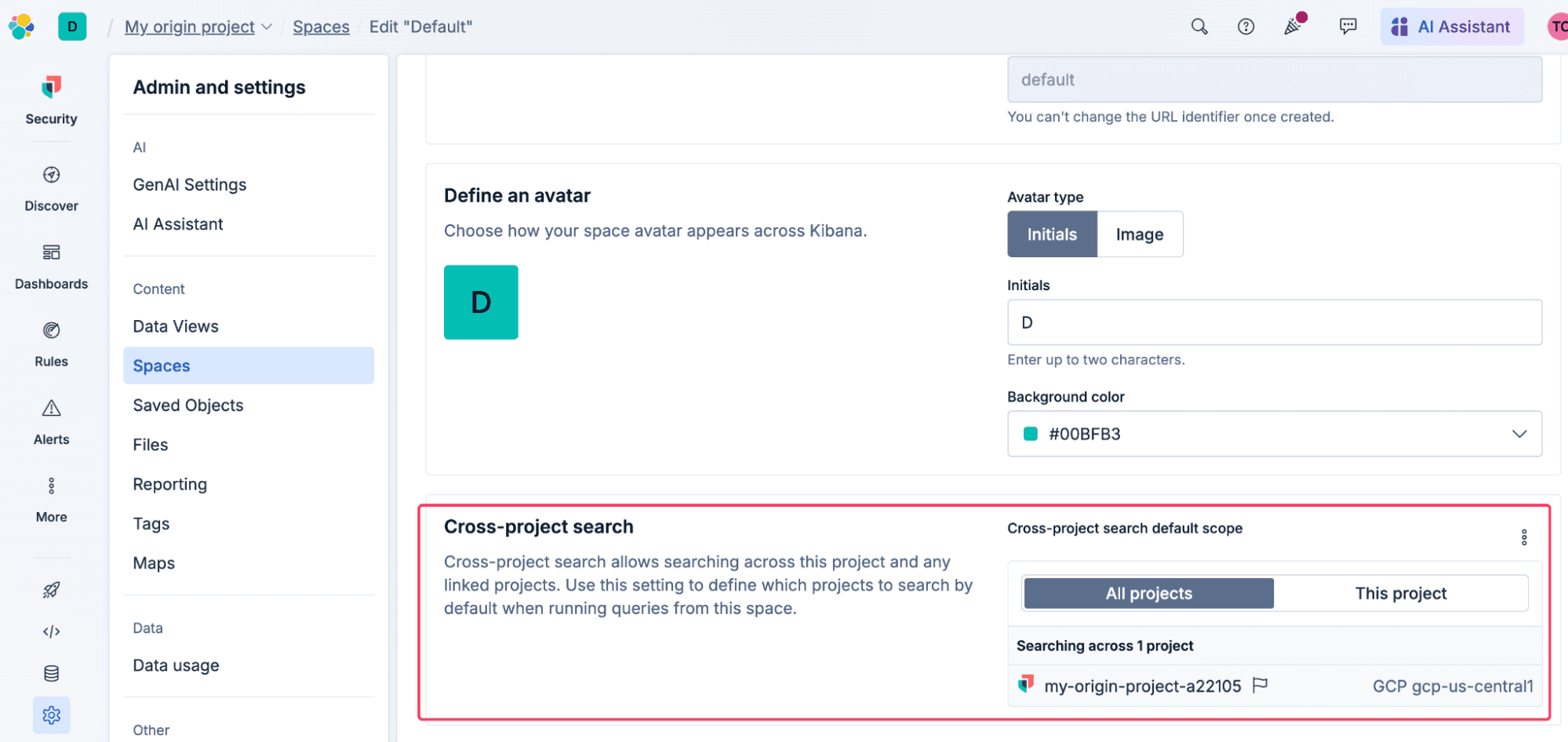
Dies ist wichtig für Teams, die an einem zentralen Projekt arbeiten, wie z. B. MSPs, MSSPs und Kompetenzzentren: Sie können jedem Team einen eigenen Kibana Space zuweisen und diesen so einschränken, dass nur die jeweiligen Kundenprojekte abgefragt werden können, wodurch mandantenspezifische Erfahrungen gewährleistet werden. Analysten können den Umfang während einer Untersuchung immer noch manuell überschreiben, wenn sie eine breitere Sicht benötigen.
Sie können diese Space-Voreinstellung konfigurieren, bevor oder nachdem Sie Ihre Projekte in der Cloud-Benutzeroberfläche verknüpfen. Da CPS jedoch sofort die Funktion „Alle durchsuchen“ aktiviert, sobald ein Link erstellt wird, stellt das vorherige Festlegen Ihrer Kibana-Standardeinstellungen sicher, dass Ihre bestehenden Erkennungsregeln nicht plötzlich auf einen riesigen globalen Datensatz angewendet werden und Ihr Team überfordern.
Verwendung von Tags in Suchanfragen
Zusätzlich zur Verwendung von Tags für das Projekt-Routing können Sie Tags auch in Ihren ES|QL- und _search-Abfragen verwenden. Dies kann nützlich sein, um festzustellen, woher jeder Datensatz oder jede Zeile in einem Ergebnissatz stammt, oder um nach diesen Tags zu sortieren, zu filtern oder zu aggregieren.
Wenn Sie zum Beispiel sehen möchten, von welchem Projekt jede Zeile in einer ES|QL-Antwort stammt, können Sie der ES|QL-Abfrage das Tag _project._alias hinzufügen:
und dies ermöglicht Ihnen die Verwendung von _project._alias in anderen Teilen der Abfrage einschließlich KEEP-Klauseln, um sie im Endergebnis zu sehen:
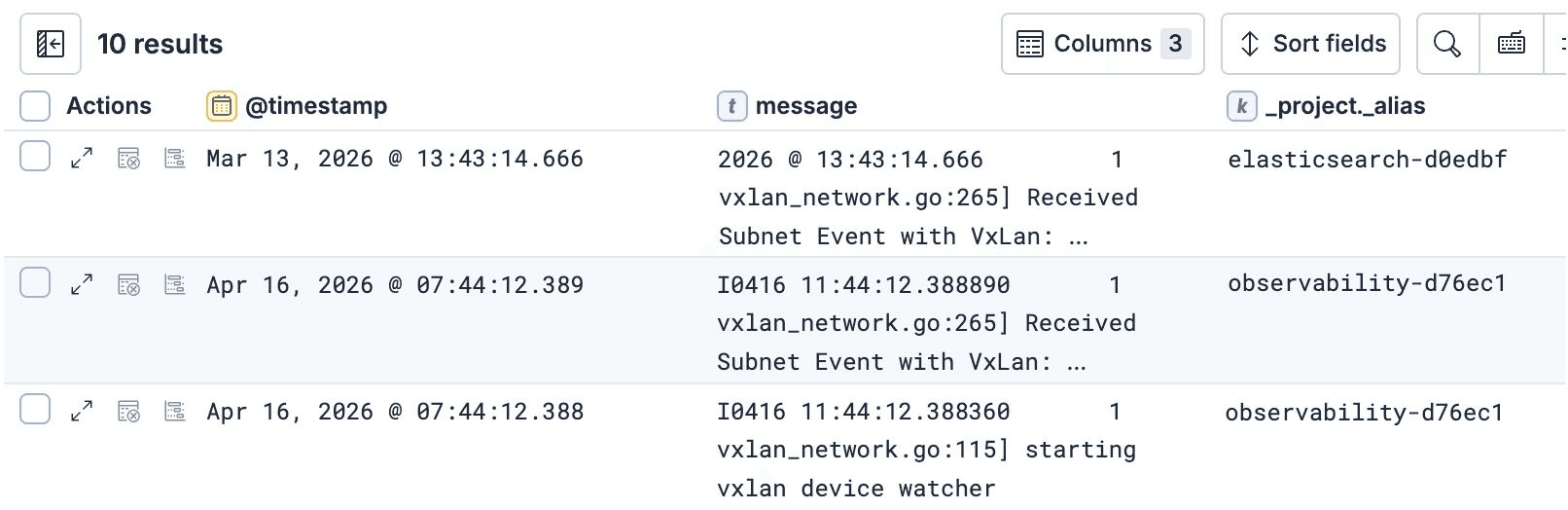
Weitere Beispiele für die Verwendung von Tags in Abfragen finden Sie in diesem Dokument, das beschreibt, wie Sie sie sowohl in Such-APIs als auch in ES|QL verwenden können.
Wenn Sie mehr über technische Details darüber erfahren möchten, wie wir Tags zu Such- und ES|QL-Abfragen hinzugefügt haben, lesen Sie Schnellere projektübergreifende Suche in Elasticsearch Serverless mit Projekt-Tags und Routing.
Wie die projektübergreifende Suche Ursprungs- und verknüpfte Projekte gleichermaßen behandelt
Wenn Sie CCS verwendet haben, sind Sie sich möglicherweise bewusst, dass der lokale Cluster in einigen Punkten anders behandelt wird als Remote-Cluster.
- Fehler aus dem lokalen Cluster werden anders behandelt als Fehler aus Remote-Clustern. Insbesondere verwendet CCS die skip_unavailable-Einstellung, um zu steuern, wie sich Fehler von entfernten Clustern verhalten, aber diese Einstellung existiert nicht für den lokalen Cluster.
- Der lokale Cluster hat keinen „Cluster-Alias“, sodass der Indexausdruck
*:logs*alle Remote-Projekte sucht, aber den lokalen Cluster überspringt. Um beides zu durchsuchen, müssen Sie den Indexausdrucklogs*,*:logs*verwenden.
In CPS haben wir diese beiden Verhaltensweisen geändert, um das Ursprungsprojekt und verknüpfte Projekte auf eine gleichmäßigere Grundlage zu stellen.
Erstens wird die skip_unavailable -Einstellung in Elastic Cloud Serverless nicht verwendet. Stattdessen steuern Sie, ob Sie Teilergebnisse einer Suche über den Parameter allow_partial_search_results in _search oder _async_search oder den Parameter allow_partial_results in ES|QL wünschen.
Zweitens verfügt in Elastic Cloud Serverless das Ursprungsprojekt über einen Projektalias. Es ist in Elastic Cloud wie alle Projekt-Tags definiert. Daher sind in CPS alle folgenden Abfragen gleichwertig – sie zielen auf alle Projekte mit einem „logs“-Index ab:
Hinweis: Es gibt einen wichtigen Unterschied zwischen dem qualifizierten Indexausdruck *:logs und dem unqualifizierten Ausdruck logs hinsichtlich der Fehlerbehandlung bei fehlenden Indizes. Für Details siehe Unqualifizierte und qualifizierte Suchausdrücke in der öffentlichen Dokumentation.
Zugriffskontroll- und Sicherheitsmodell für projektübergreifende Suche
Elastic hat ein neues cloudbasiertes Sicherheitsmodell entwickelt, Universal Identity and Access Management (UIAM), das ein zentrales Prinzip für projektübergreifende Suche ermöglicht: Die Projekte und Daten, auf die Sie zugreifen können, hängen nicht davon ab, von wo aus Sie darauf zugreifen.
Egal, ob Sie eine Suche von Ihrem primären Beobachtbarkeitsprojekt oder einem Ad-hoc-Analyseprojekt aus initiieren, bleibt Ihr Zugriff auf die verknüpften Daten konsistent, da die Zugriffsrechte an einem zentralen Ort definiert wurden. Das cloudbasierte Authentifizierungs- und Autorisierungsmodell nutzt den Cloud-UIAM-Dienst, um sicherzustellen, dass Ihre Zugriffsberechtigungen unabhängig vom Ursprungsprojekt einheitlich sind.
Projektübergreifende Suche ausprobieren
Letztlich verringern Elastic Cloud Serverless und CPS zusammen die operative Reibung und bieten Ihnen zusätzliche Möglichkeiten, Daten auf Basis logischer Überlegungen statt physischer oder betrieblicher Überlegungen zu organisieren. Die projektübergreifende Suche ermöglicht es Ihren Nutzern, sich rein auf die logische Organisation ihrer Daten zu konzentrieren und bietet ein einheitliches Sucherlebnis ohne die physischen Komplexitäten der Vergangenheit.
Häufige Fragen
Was ist Cross-Project Search in Elastic Serverless?
Cross-Project Search (CPS) ist ein Feature in Elastic Cloud Serverless, das es ermöglicht, Daten über mehrere isolierte serverlose Projekte mit einer einzigen Elasticsearch oder ES|QL-Anfrage abzufragen. Projekte werden in der Elastic Cloud-Konsole verknüpft, und sobald sie verknüpft sind, sucht eine Abfrage wie „FROM logs*“ automatisch das Ursprungsprojekt und alle verknüpften Projekte ohne zusätzliche Konfiguration.
Wie unterscheidet sich Cross-Project Search von Cross-Cluster Search (CCS)?
CCS verbindet selbstverwaltete oder zustandsbehaftete Elasticsearch-Cluster und erfordert Network Peering, manuelles Zertifikatsmanagement und explizite Remote-Cluster-Adressierung (z. B. „*:logs*“). CPS ersetzt dies durch ein einfaches Projektverknüpfungsmodell in Elastic Cloud Serverless, bei dem Ursprungs- und verknüpfte Projekte gleich behandelt werden und ein einzelner unqualifizierter Indexausdruck alle durchsucht.
Muss ich Daten kopieren oder duplizieren, um die projektübergreifende Suche zu verwenden?
Nein. CPS bündelt projektübergreifende Abfragen zur Suchzeit. Ihre Daten bleiben in jedem Projekt erhalten, und es werden nur die Abfrageergebnisse aggregiert und zurückgegeben, wodurch die Speicher- und Netzwerkausgabekosten für die Duplizierung von Daten vermieden werden.
Wie beschränke ich eine projektübergreifende Suche auf bestimmte Projekte?
Verwenden Sie den Parameter „project_routing“ für einen beliebigen unterstützten Elasticsearch-Endpoint. Man kann nach Projektalias (z. B. „_alias:my-project“) eine Abfrage auf ein Projekt beschränken, oder einen Standard-Projektumfang auf Kibana Space-Ebene festlegen, sodass alle Dashboards und Alerts in diesem Space automatisch auf die richtigen Projekte zugeschnitten sind.
Funktioniert Cross-Project Search über verschiedene Regionen und Cloudanbieter hinweg?
Ja. CPS unterstützt Projektverknüpfungen zwischen Regionen und Cloudanbietern. Daten werden nicht zwischen Projekten verschoben; nur Suchergebnisse werden an den Ursprung zurückgegeben, sodass die Einschränkungen der Datenresidenzbeschränkungen nicht verletzt werden.
Wie funktioniert die Zugangskontrolle über verknüpfte Projekte in CPS?
CPS nutzt Universal Identity and Access Management (UIAM), ein zentralisiertes, cloudbasiertes Modell. Ihre Zugriffsrechte werden konsistent durchgesetzt, unabhängig davon, von welchem Projekt aus Sie eine Abfrage ausführen, so dass ein Nutzer nur Daten sehen kann, für die er in allen verknüpften Projekten eine Zugriffsberechtigung hat.
Was passiert, wenn ein verknüpftes Projekt während einer Suche nicht verfügbar ist?
Verwenden Sie den Parameter „allow_partial_search_results“ in „_search“ oder „_async_search“ bzw. „allow_partial_results“ in ES|QL, um zu steuern, ob eine Abfrage Teilergebnisse zurückgibt oder fehlschlägt, wenn ein verknüpftes Projekt nicht verfügbar ist. Im Gegensatz zu CCS gibt es in CPS keine „skip_unavailable“-Einstellung.
Zugehörige Inhalte

20. April 2026
Einführung einheitlicher API-Schlüssel für Elastic Cloud Serverless und Elasticsearch
Erfahren Sie, wie Elastic die Authentifizierung von Steuerebenen und Datenebenen in Serverless mit einer global verteilten IAM-Architektur vereint. Verwenden Sie einen API-Schlüssel für Cloud- und Elasticsearch-APIs.

24. März 2026
Elasticsearch-Replikate für den Lastausgleich in Serverless
Erfahren Sie, wie Elastic Cloud Serverless die Indexreplikate automatisch an die Suchlast anpasst und so eine optimale Abfrageleistung ohne manuelle Konfiguration gewährleistet.
22. Januar 2026
Agent Builder jetzt GA: Versenden Sie kontextabhängige Agenten in wenigen Minuten
Agent Builder ist jetzt allgemein verfügbar (GA). Erfahren Sie, wie Sie damit schnell kontextgesteuerte KI-Agenten entwickeln können.

14. Januar 2026
Höherer Durchsatz und geringere Latenz: Elastic Cloud Serverless auf AWS erhält einen deutlichen Leistungsschub.
Wir haben die AWS-Infrastruktur für Elasticsearch Serverless auf neuere, schnellere Hardware upgegradet. Erfahren Sie, wie dieser enorme Leistungsschub schnellere Abfragen, besseres Skalieren und niedrigere Kosten liefert.

4. März 2025
Der KI-Agent zur Verwaltung von Elasticsearch Serverless-Projekten
Ein KI-Agent mit natürlicher Sprachverarbeitung, der Elasticsearch Serverless-Projekte mühelos verwaltet – er ermöglicht das Erstellen, Löschen und Überprüfen des Projektstatus.