Elastic Cloud Serverlessでプロジェクト横断検索(CPS)が利用可能になりました。FROM logs*のような単一のクエリで、ネットワークピアリング、証明書管理、データ重複なしに複数の独立したプロジェクトにわたってデータを検索できます。プロジェクトはそれぞれ独自のリージョンとクラウド内に保持され、結果のみが返されます。データレジデンシーの要件、テナントの分離、ログのコピーに伴う高額なデータ転送コストといった課題を抱えるチームにとって、CPSはデータが本来あるべき場所に正確に存在し、かつ全体としてクエリを実行できることを意味します。
Elastic Cloud Serverlessはインフラストラクチャの管理とバージョンアップグレードの煩わしさをすでに解消していますが、CPSはそれをさらに一歩進めます。複雑なネットワークピアリングと手動による証明書管理を、シンプルなリンクモデルに置き換え、Elastic Cloud Serverlessプロジェクトをデータの単純な名前空間として扱うことができます。厳格なデータレジデンシー法への対応、テナントデータの分離、あるいはログの重複によって発生する莫大なネットワーク送信料金の回避など、どのような場合でも、CPSを使えば、単一のクエリでデータが存在する場所で正確に検索できます。
この投稿では、CPSの仕組み、プロジェクトタグを使用して検索を制御する方法、そしてこの新しいモデルが従来のクラスター横断検索(CCS)とどのように異なるかを説明します。
プロジェクトをリンクしてプロジェクト横断検索を行う方法
プロジェクト横断検索を始めるには、Elastic CloudコンソールまたはAPIでプロジェクトをリンクします。リンクは簡単で一方向です。元となるプロジェクトを選択し、検索するプロジェクトを接続します。これらのリンクはリージョン、クラウドプロバイダー、プロジェクトの種類にまたがるため、統一された検索エクスペリエンスを損なうことなく、データを元の場所に保存できます。
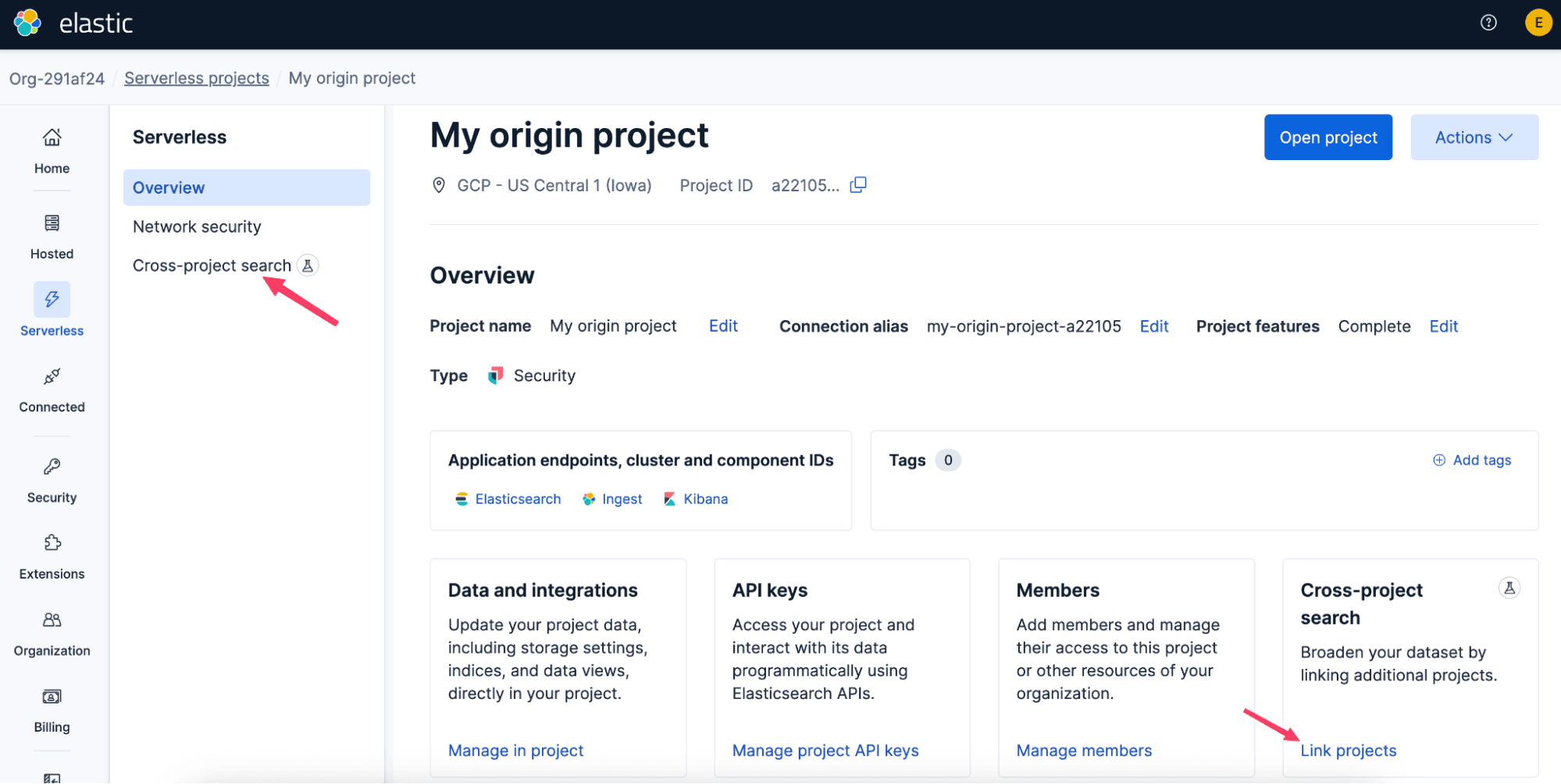
リンクが作成されると、通常約1分以内に有効になります。すでにKibanaを開いている場合は、更新して新しいプロジェクト横断検索機能を確認してください。
プロジェクト横断検索がデフォルトでリンクされたすべてのプロジェクトにクエリを適用する方法
プロジェクトがリンクされると、プロジェクト横断検索は別々のプロジェクトを1つの論理的な検索画面に変えます。ログが複数のプロジェクトにまたがっている場合、FROM logs* のようなクエリは、元のプロジェクトと一致するデータを持つリンクされたプロジェクトを検索します。事前に各リモートターゲットに名前を付ける必要はありません。
これはクラスター横断探索に比べて大きな進歩です。CCSでは、ローカルデータとリモートデータの両方にアクセスするには、 FROM logs*,*:logs*のような記述が必要になることがよくあります。ユーザーにとっては、クエリの複雑さが軽減されるということです。チームにとって、これは分散データ全体にわたる真の可視化の実現に近づくことを意味します。
詳細については、CPS検索モデルドキュメントをご覧ください。
この技術的な詳細については「Elasticsearch Serverlessにおけるプロジェクト横断検索(CPS)の仕組み」をご覧ください。
プロジェクトルーティングによる検索の制御
デフォルトでリンクされたすべてのプロジェクトを検索する機能は、多くのワークフローにとって便利で役立ちますが、すべての検索がすべてのプロジェクトを対象とするべきではありません。プロジェクト横断検索では、プロジェクトルーティングが導入され、クエリを特定のプロジェクト群に限定することが可能になります。
Elastic Cloudで定義されたプロジェクトタグを通じて動作します。すべてのプロジェクトには、そのエイリアス、クラウドプロバイダー、リージョンなどの組み込まれた属性があります。また、 environment:prod, environment:test 、事業部門、顧客名など、組織が資産をどのように考えているかを反映するために、独自のタグを追加することもできます。Elasticsearchはその後、そのメタデータを使用して、どのリンクされたプロジェクトが検索に参加すべきかを決定できます。
プロジェクト横断検索をサポートするすべてのElasticsearchエンドポイントは、project_routing パラメーターを受け付けます。テクニカルプレビューでは、ルーティングはプロジェクトエイリアスの使用に限定されています。例えば、project_routingを _alias:my-linked-project に設定すると、リンクされたプロジェクトにのみクエリが送信され、_alias:_origin は元のプロジェクトにクエリが保持されます。時間の経過とともに、このモデルはより高度なルーティングへの道を開き、検索範囲をインフラの物理的なレイアウトではなく、組織の論理的な構造に従わせることができるようになります。
プロジェクトルーティングに関するドキュメントには、例や仕組みの詳細が記載されていますので、そちらを参照してください。
Kibanaスペースレベルのデフォルトプロジェクトルーティング
検索ルーティングの精度を高める必要がある例として、リンクされたすべてのプロジェクトを検索すると、Kibanaルールで誤検知が殺到したり、既存のダッシュボードで混乱する結果になったりする可能性があります。これを解決するには、Kibanaでスペースレベルのデフォルトプロジェクトスコープを設定することができます。これは、その特定のスペースに対する安全設定として機能します。つまり、すべてのダッシュボード、Discoverセッション、アラートルールは、自動的にこの設定を尊重します。アナリストは、より広範なビューが必要な場合、調査中にスコープを手動で上書きすることができます。
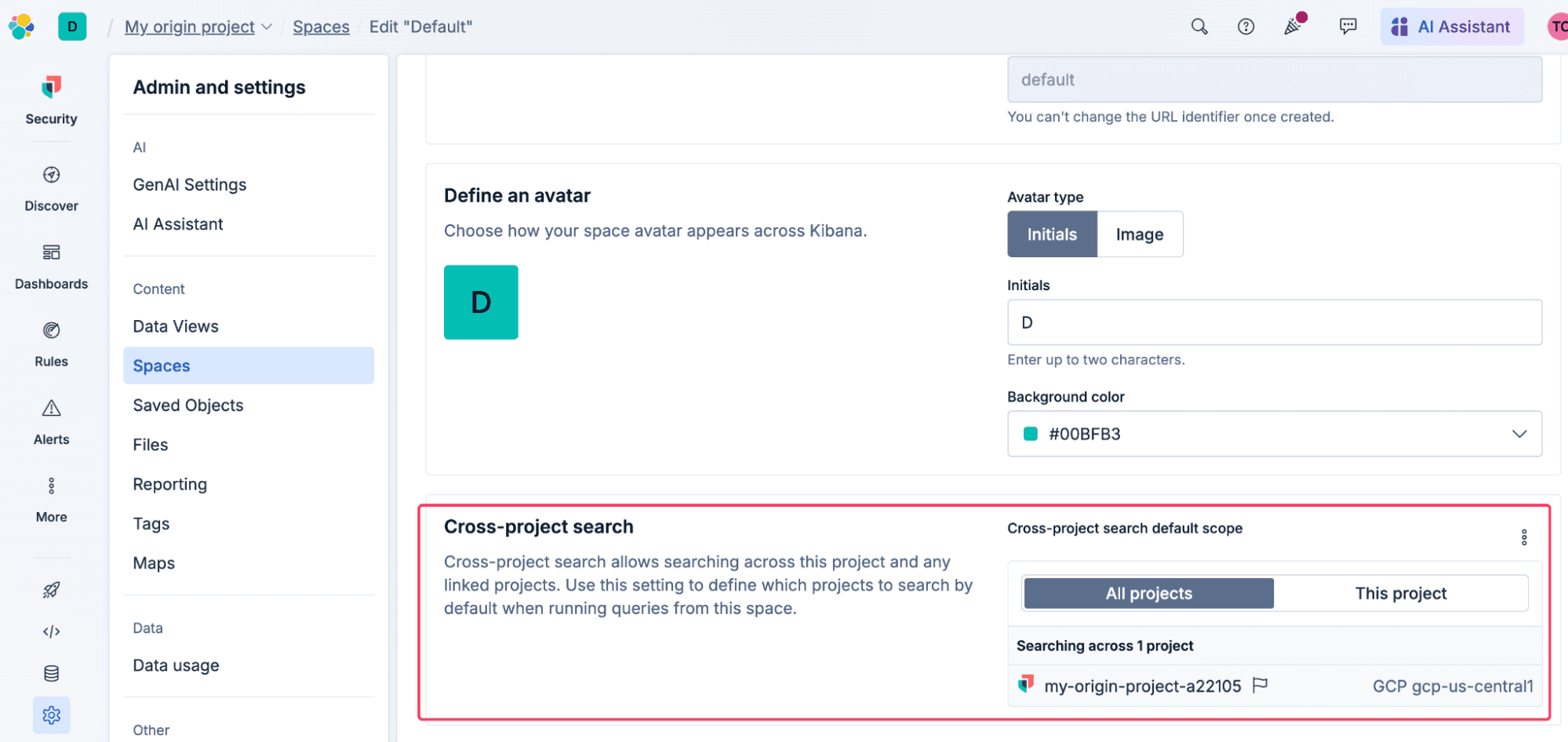
これは、MSP、MSSP、センター・オブ・エクセレンスなど、中心的なプロジェクトを共有するチームにとって重要です。各チームに独自の Kibana スペースを割り当て、特定の顧客プロジェクトのクエリのみに制限することで、テナント固有のエクスペリエンスを保証できます。アナリストは、より広範なビューが必要な場合、調査中にスコープを手動で上書きすることができます。
このスペースのデフォルトは、Cloud UIでプロジェクトを実際にリンクする前でも後でも設定できます。しかし、CPSはリンクが作成された瞬間に「すべて検索」動作を即座に有効にするため、Kibanaのデフォルト設定を先に行うことで、既存の検出ルールが突然膨大なグローバルデータセットに対して実行され、チームに過負荷がかかることを防ぐことができます。
検索でのタグの使用
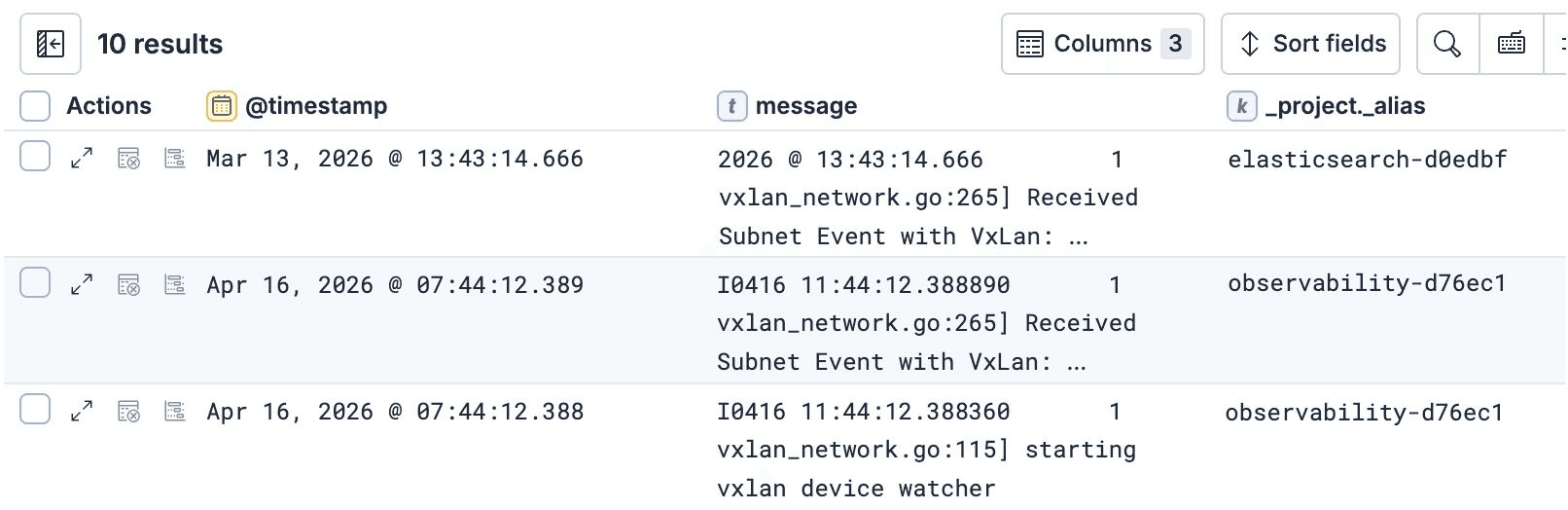
プロジェクトのルーティングにタグを使用するだけでなく、ES|QLと_searchのクエリでもタグを使用できます。これは、結果セット内の各レコードまたは行がどこから来たのかを特定したり、これらのタグに基づいて並べ替え、フィルタリング、集計したりするのに役立ちます。
例えば、ES|QLレスポンスの各行がどのプロジェクトから来たのかを確認したい場合は、ES|QLクエリに_project._aliasタグを追加できます。
これにより、_project._alias を KEEP 句を含むクエリの他の部分で使用して、最終結果に表示させることができます。
タグをクエリで使用するその他の例については、このドキュメントを参照してください。これには、Search APIとES|QLの両方での使用方法が説明されています。
SearchクエリとES|QLクエリにタグを追加する方法の技術的な詳細については、「プロジェクトタグとルーティングを使用したElasticsearch Serverlessでの高速なプロジェクト横断検索」を参照してください。
プロジェクト横断検索が元のプロジェクトとリンクされたプロジェクトを同等に扱う方法
CCSを使用したことがある方なら、ローカルクラスターはリモートクラスターとはいくつかの点で異なる扱いを受けることをご存知かもしれません。
- ローカルクラスターからのエラーは、リモートクラスターからのエラーとは異なる処理方法があります。特に、CCSはskip_unavailable設定を使用してリモートクラスターからのエラーの動作を制御しますが、その設定はローカルクラスターには存在しません。
- ローカルクラスターには「クラスターエイリアス」がないため、インデックス式
*:logs*はすべてのリモートプロジェクトを検索しますが、ローカルクラスターはスキップされます。両方を検索するには、インデックス式logs*,*:logs*を使用します。
CPSでは、元のプロジェクトとリンクされたプロジェクトをより均一な基盤に置くために、これらの動作の両方を変更しました。
まず、skip_unavailable設定はElastic Cloud Serverlessでは使われていません。代わりに、_search または _async_search のallow_partial_search_resultsパラメーターまたは ES|QL のallow_partial_resultsパラメーターを使用して、検索で部分的な結果を表示するかどうかを制御します。
次に、Elastic Cloud Serverlessでは、元のプロジェクトにプロジェクトエイリアスがあります。すべてのプロジェクトタグと同様に、Elastic Cloudで定義されています。したがって、CPSでは、以下のすべてのクエリは同等です。それらは「logs」インデックスを持つすべてのプロジェクトを対象としています。
注:修飾インデックス式*:logsと非修飾式logsでは、インデックスが欠落した場合のエラー処理の仕組みに重要な違いがあります。詳細については、公開ドキュメントの「非修飾検索式と修飾検索式」を参照してください。
プロジェクト横断検索のアクセス制御とセキュリティモデル
Elasticは、クラウドベースの新しいセキュリティモデル、ユニバーサルIDおよびアクセス管理(UIAM)を作成しました。これにより、プロジェクト横断検索の重要な原則である「アクセスできるプロジェクトとデータはアクセス元の場所に依存しない」ことが実現されます。
主要なオブザーバビリティプロジェクトから検索を開始する場合でも、アドホックな分析プロジェクトから検索を開始する場合でも、アクセス権限は一元的に定義されているため、リンクされたデータへのアクセスは一貫しています。クラウドベースの認証と承認モデルは、クラウドUIAMサービスを使用して、元のプロジェクトに関係なく、アクセス許可が統一されることを保証します。
プロジェクト横断検索を試す
最終的に、Elastic Cloud ServerlessとCPSを組み合わせることで、運用上の摩擦を軽減し、物理的または運用上の考慮事項ではなく、論理的な考慮事項に基づいてデータを整理するための追加の選択肢が得られます。プロジェクト横断型検索により、ユーザーはデータの論理的な整理にのみ集中でき、従来のような物理的な複雑さを伴わずに統一された検索エクスペリエンスを実現できます。
よくあるご質問
Elastic Serverlessにおけるプロジェクト横断検索とは?
プロジェクト横断検索(CPS)は、Elastic Cloud Serverlessの機能で、単一のElasticsearchまたはES|QLリクエストで複数の分離されたサーバーレスプロジェクト間でデータをクエリできます。Elastic Cloud Consoleでプロジェクトをリンクすると、一度リンクされると、「FROM logs*」のようなクエリを実行するだけで、追加設定なしに元のプロジェクトとリンクされたすべてのプロジェクトが自動的に検索されます。
プロジェクト横断検索はクラスター横断検索(CCS)とどう違うのですか?
CCSは自己管理型またはステートフルなElasticsearchクラスターを接続し、ネットワークピアリング、手動による証明書管理、明示的なリモートクラスターアドレス指定(例:`*:logs*`)を必要とします。CPSはこれをElastic Cloud Serverlessのシンプルなプロジェクトリンクモデルに置き換えます。ここでは、元のプロジェクトとリンクされたプロジェクトが同等に扱われ、単一の非修飾インデックス式でそれらすべてを検索します。
プロジェクト横断検索を使用するにはデータのコピーや複製が必要ですか?
いいえ。CPSは検索時にプロジェクトをまたいだクエリを統合します。データは各プロジェクト内に保持され、クエリ結果のみが集約されて返されるため、データの重複によるストレージコストやネットワーク送信コストを回避できます。
プロジェクト横断検索を特定のプロジェクトに制限する方法を教えてください。
サポートされているElasticsearchエンドポイントであれば、どのエンドポイントでも`project_routing`パラメーターを使用できます。プロジェクトエイリアス(例:`_alias:my-project`)を使用してクエリを1つのプロジェクトに限定したり、Kibanaスペースレベルでデフォルトのプロジェクトスコープを設定して、そのスペース内のすべてのダッシュボードとアラートが自動的に適切なプロジェクトにスコープされるようにしたりできます。
プロジェクト横断検索は異なるリージョンやクラウドプロバイダー間でも機能しますか?
はい。CPSはリージョンやクラウドプロバイダーにまたがるプロジェクトリンクをサポートしています。データはプロジェクト間で移動せず、検索結果のみが元のプロジェクトに返されるため、データレジデンシーの制約に違反することはありません。
CPSのリンクされたプロジェクト全体でアクセス制御はどのように機能しますか?
CPSは、一元化されたクラウドベースのモデルであるユニバーサルIDおよびアクセス管理(UIAM)を使用しています。クエリを実行するプロジェクトに関わらず、アクセス権限は一貫して適用されるため、ユーザーはリンクされたすべてのプロジェクトにおいてアクセス権限が付与されているデータのみを表示できます。
検索中にリンクされたプロジェクトが利用できない場合はどうなりますか?
`allow_partial_search_results` パラメーターを `_search` または `_async_search` で使用するか、ES|QL で `allow_partial_results` を使用して、リンクされたプロジェクトが利用できない場合にクエリが部分的な結果を返すか失敗するかを制御します。CPSにはCCSのような「skip_unavailable」設定はありません。
関連記事

2026年4月20日
Elastic Cloud ServerlessとElasticsearchの統合APIキーが登場
Elasticがグローバルに分散されたIAMアーキテクチャでServerlessのコントロールプレーンとデータプレーンの認証を統合した方法をご紹介します。Cloud APIとElasticsearch APIに1つのAPIキーを使用できます。

2026年3月24日
Serverlessにおける負荷分散のためのElasticsearchレプリカ
Elastic Cloud Serverlessが検索負荷に基づいてインデックスレプリカを自動的に調整し、手動設定なしで最適なクエリパフォーマンスを確保する方法をご覧ください。
2026年1月22日
Agent Builderが一般提供開始:コンテキスト駆動型エージェントを数分で出荷
Agent Builderが一般提供となりました。コンテキスト駆動型AIエージェントを迅速に開発する方法を学びましょう。

2026年1月14日
高いスループットと低いレイテンシ:AWS上のElastic Cloud Serverlessがパフォーマンスを大幅に向上
Elasticsearch ServerlessのAWSインフラを、より新しい、より高速なハードウェアにアップグレードしました。この大幅なパフォーマンス向上によって、クエリの高速化、スケーリングの向上、コストの削減がどのように実現されるかを学びます。

2025年3月4日
Elasticsearch Serverlessプロジェクトを管理するAIエージェント
Elasticsearch Serverless プロジェクトを簡単に管理し、プロジェクトの作成、削除、ステータス チェックを可能にする自然言語対応の AI エージェント。