De la recherche vectorielle aux API REST puissantes, Elasticsearch met à disposition des développeurs la boîte à outils de recherche la plus complète. Explorez nos notebooks d’exemple dans le dépôt Elasticsearch Labs pour tester de nouvelles approches. Vous pouvez également démarrer un essai gratuit ou exécuter Elasticsearch en local dès aujourd’hui.
Elastic est ravi d'annoncer que la base de données vectorielle Elasticsearch est désormais intégrée à la plateforme Vertex AI de Google Cloud en tant que moteur de recherche d'informations pris en charge en mode natif, ce qui permet aux utilisateurs d'exploiter les forces multimodales des modèles Gemini de Google avec les capacités de recherche sémantique et hybride d'Elasticsearch, alimentées par l'IA.
Les développeurs peuvent désormais créer leurs applications RAG dans le cadre d'un parcours unifié, en fondant leurs expériences de chat sur leurs données privées d'une manière flexible et à code bas. Que vous construisiez des agents d'IA pour vos clients et vos employés internes ou que vous exploitiez la génération de LLM dans votre logiciel, la plateforme Vertex AI met la pertinence d'Elasticsearch à votre portée avec une configuration minimale. Cette intégration permet une adoption plus facile et plus rapide des modèles Gemini dans les cas d'utilisation en production, faisant passer la GenAI des PoC aux scénarios de la vie réelle.
Dans ce blog, nous vous guiderons dans l'intégration d'Elasticsearch avec la plateforme Vertex AI de Google Cloud pour un ancrage transparent des données et la création d'applications GenAI entièrement personnalisables. Découvrons comment.
Les modèles Vertex AI et Gemini de Google Cloud sont ancrés dans vos données grâce à Elasticsearch
Les utilisateurs qui tirent parti des services et outils Vertex AI pour créer des applications GenAI peuvent désormais accéder à la nouvelle option "Grounding" qui leur permet d'intégrer automatiquement leurs données privées dans leurs interactions conversationnelles. Elasticsearch fait désormais partie de cette fonctionnalité et peut être utilisé via les deux :
- APIs Vertex AI LLM, qui enrichissent directement les modèles Gemini de Google au moment de la génération (de préférence) ;
- Grounded Generation API, utilisée plutôt dans l'écosystème Vertex AI Agent Builder pour construire des expériences agentiques.
Grâce à cette intégration, Elasticsearch, la base de données vectorielle la plus téléchargée et la plus déployée, apportera vos données d'entreprise pertinentes là où elles sont nécessaires dans vos chats internes et en contact avec les clients, ce qui est crucial pour l'adoption réelle de la GenAI dans les processus d'entreprise.
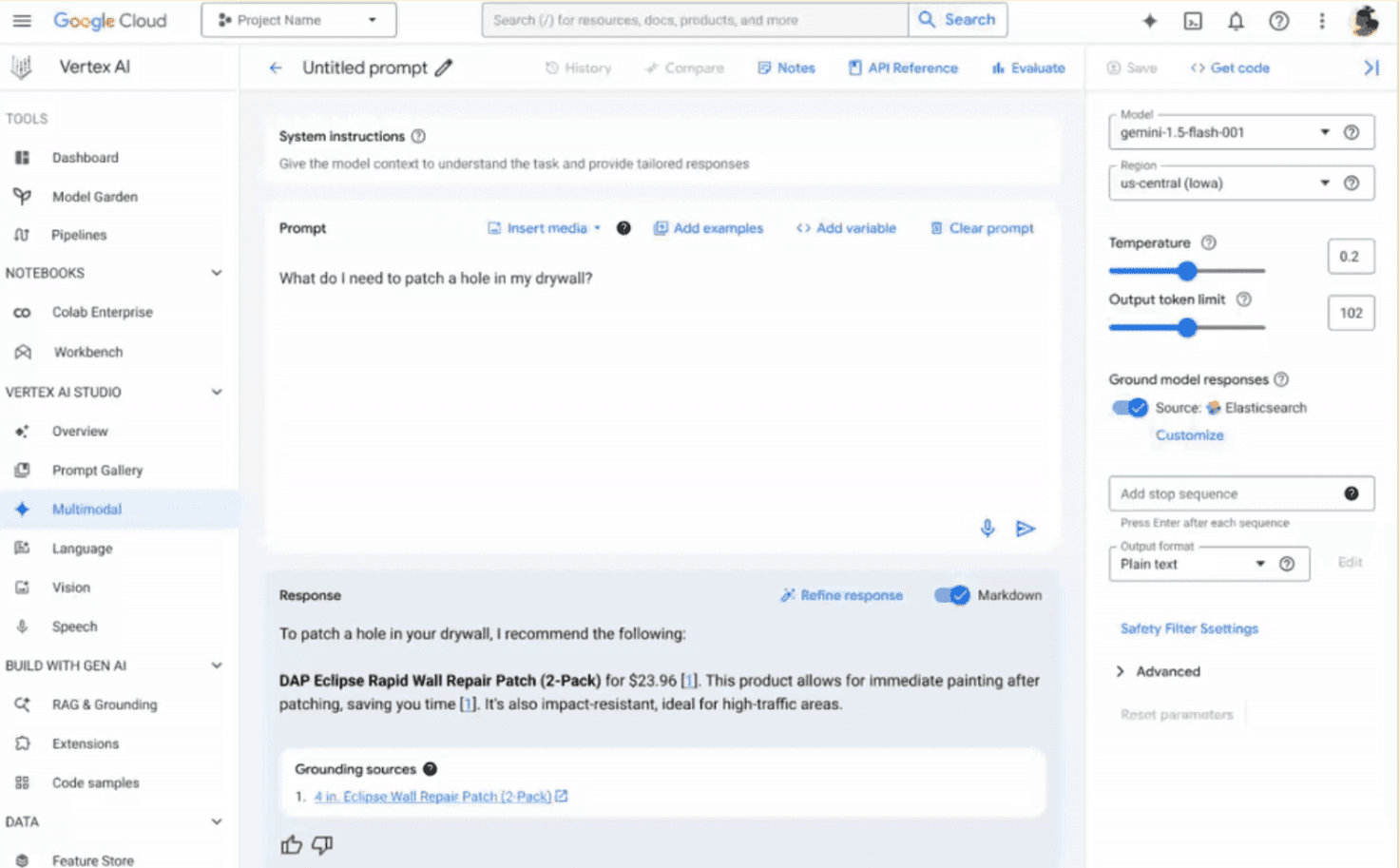
Les API susmentionnées permettront aux développeurs d'adopter cette nouvelle fonctionnalité dans leur code. Cependant, l'ingénierie et les tests rapides restent des étapes cruciales dans le développement de l'application et servent de terrain de jeu initial. Pour ce faire, Elasticsearch est conçu pour être facilement évalué par les utilisateurs dans l'outil de console Vertex AI Studio.
Il suffit de quelques étapes simples pour configurer les points de terminaison Elastic avec les paramètres souhaités (index à rechercher, nombre de documents à récupérer et modèle de recherche souhaité) dans l'onglet "Customize Grounding" de l'interface utilisateur, comme indiqué ci-dessous (notez que pour que cela fonctionne, vous devez saisir la clé API avec le mot "ApiKey" dans l'interface utilisateur et les exemples de code ci-dessous). Vous êtes maintenant prêt à générer vos propres connaissances !
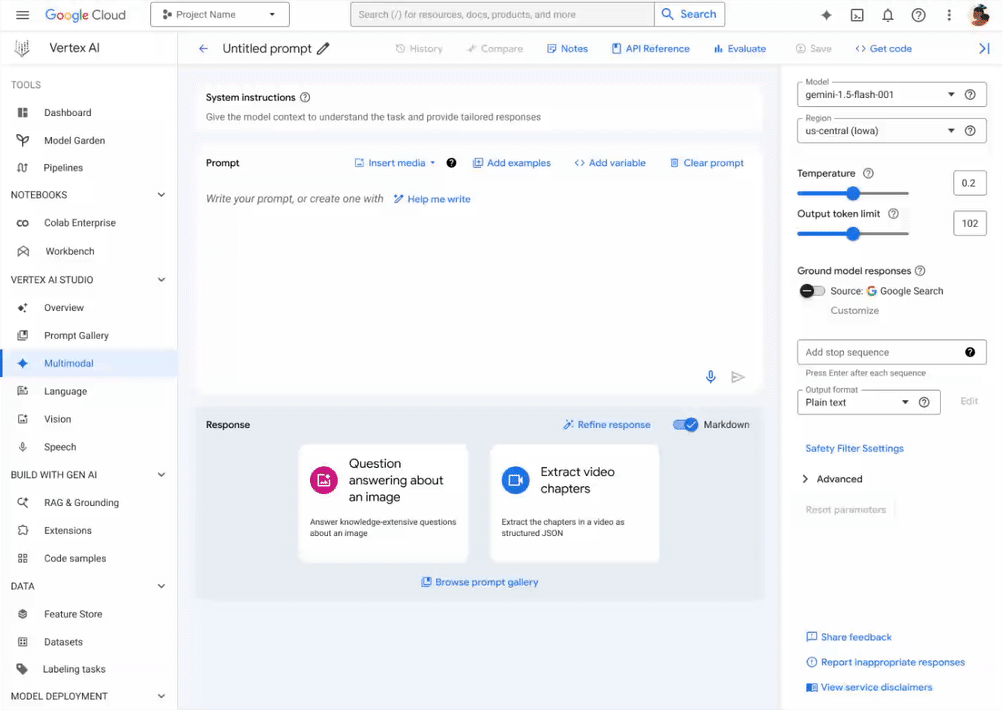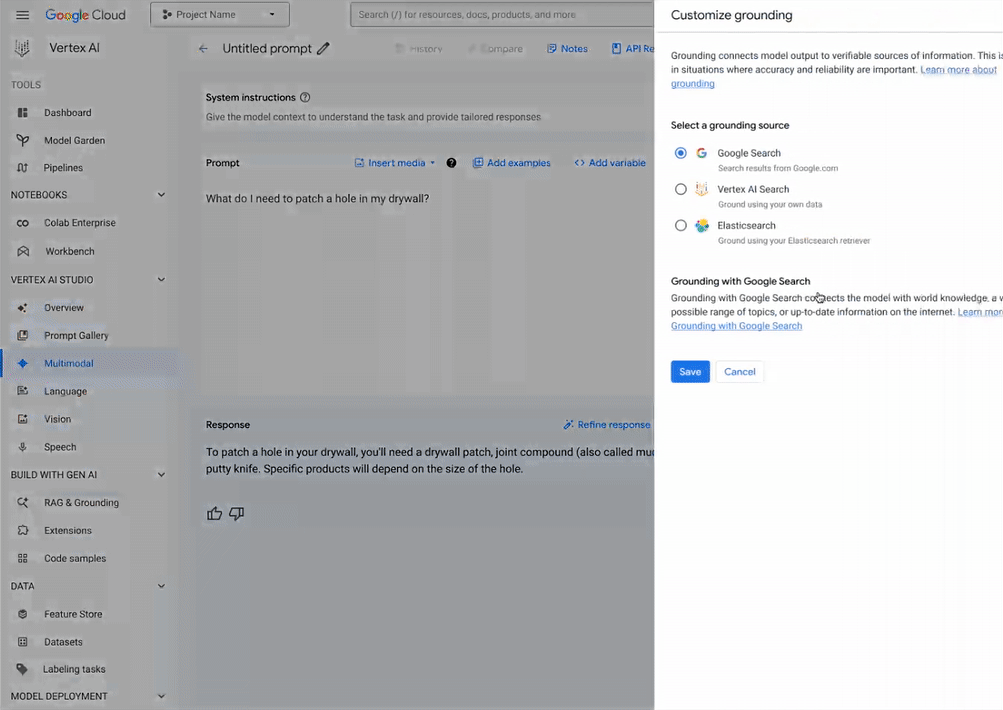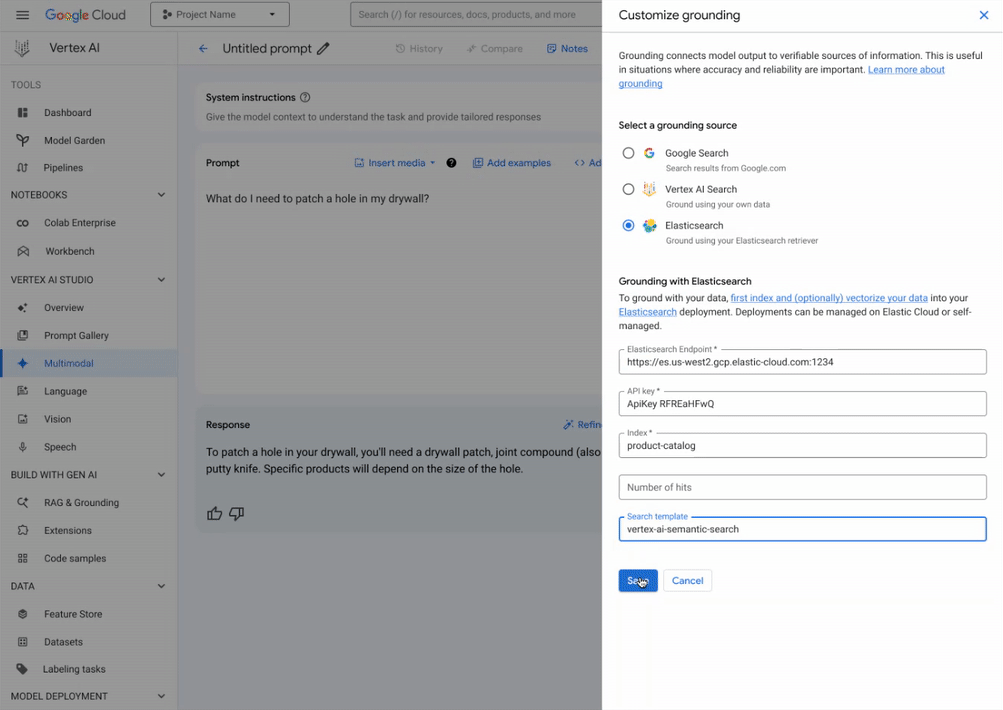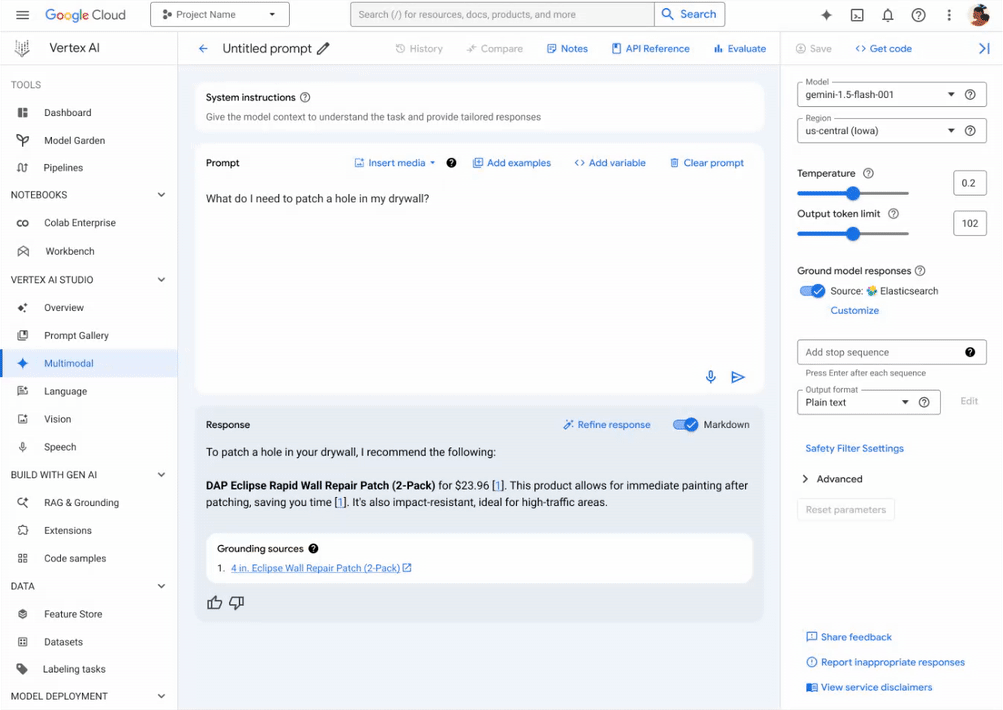
Des applications GenAI prêtes à la production en toute simplicité
Elastic et Google Cloud s'efforcent d'offrir aux développeurs des expériences complètes et agréables. La connexion à Elastic en mode natif dans les API LLM et Grounding Generation réduit la complexité et les frais généraux lors de la création d'applications GAI sur Vertex AI, en évitant les API supplémentaires inutiles et l'orchestration des données tout en s'appuyant sur un seul appel unifié.
Voyons comment cela fonctionne dans les deux cas.
Le premier exemple est exécuté avec l'API LLM :
Dans l'exemple ci-dessus, avec le champ retrieval de l'API demandant la génération de contenu à Gemini 2.0 Flash, nous pouvons définir contextuellement un moteur de recherche pour la demande. Définir api_spec sur "ELASTIC_SEARCH" permet d'utiliser des paramètres de configuration supplémentaires tels que la clé API et le point de terminaison du cluster (nécessaires pour acheminer une requête vers votre cluster Elastic), l'index à partir duquel récupérer les données et le modèle de recherche à utiliser pour votre logique de recherche.
De même, le même résultat peut être obtenu avec l'API "Grounding Generation", en définissant le paramètre groundingSpec:
Dans les deux cas, la réponse contiendra les documents privés les plus pertinents trouvés dans Elasticsearch - et les sources de données connectées connexes - pour répondre à votre requête.
La simplicité ne doit cependant pas être confondue avec un manque de personnalisation pour répondre à vos besoins spécifiques et à vos cas d'utilisation. C'est dans cet esprit que nous l'avons conçu pour vous permettre d'adapter parfaitement la configuration de la recherche à votre scénario.
Une recherche entièrement personnalisable au bout des doigts : modèles de recherche
Pour personnaliser au maximum votre scénario de recherche, nous avons construit, en collaboration avec Google Cloud, l'expérience au-dessus de nos modèles de recherche bien connus. Les modèles de recherche Elasticsearch sont un excellent outil pour créer des requêtes de recherche dynamiques, réutilisables et faciles à maintenir. Ils permettent de prédéfinir et de réutiliser les structures de requête. Ils sont particulièrement utiles lors de l'exécution de requêtes similaires avec des paramètres différents, car ils permettent d'économiser du temps de développement et de réduire le risque d'erreurs. Les modèles peuvent inclure des espaces réservés pour les variables, ce qui rend les requêtes dynamiques et adaptables aux différents besoins de recherche.
Lorsque vous utilisez les API de Vertex AI et Elasticsearch pour l'ancrage, vous devez faire référence à un modèle de recherche souhaité - comme indiqué dans les extraits de code ci-dessus - où la logique de recherche est mise en œuvre et transmise à Elasticsearch. Les utilisateurs d'Elastic Power peuvent gérer, configurer et mettre à jour les approches de recherche de manière asynchrone et les adapter aux indices, modèles et données spécifiques de manière totalement transparente pour les utilisateurs de Vertex AI, les développeurs d'applications web ou les ingénieurs en intelligence artificielle, qui n'ont qu'à spécifier le nom du modèle dans l'API de base.
Cette conception permet une personnalisation complète, mettant à votre disposition les fonctionnalités de recherche étendues d'Elasticsearch dans un environnement Google Cloud AI, tout en garantissant la modularité, la transparence et la facilité d'utilisation pour les différents développeurs, même ceux qui ne sont pas familiers avec Elastic.
Lorsque vous avez besoin d'une recherche BM25, d'une recherche sémantique ou d'une approche hybride entre les deux (avez-vous déjà exploré les récupérateurs? (techniques de recherche composables en un seul appel à l'API de recherche), vous pouvez définir votre logique personnalisée dans un modèle de recherche, que Vertex AI peut automatiquement exploiter.
Cela s'applique également aux modèles d'intégration et de classement que vous choisissez pour gérer les vecteurs et les résultats. En fonction de votre cas d'utilisation, vous pouvez héberger des modèles sur les nœuds ML d'Elastic, utiliser un point de terminaison de service tiers via l'API d'inférence ou exécuter votre modèle local sur site. Cela est possible grâce à un modèle de recherche, dont nous verrons le fonctionnement dans la section suivante.
Commencez par des modèles de référence, puis créez votre propre modèle.
Pour vous aider à démarrer rapidement, nous avons fourni un ensemble d'exemples de modèles de recherche compatibles à utiliser comme référence initiale ; vous pouvez ensuite les modifier et construire vos modèles personnalisés :
- Recherche sémantique avec le modèle ELSER (vecteurs épars et regroupement)
- Recherche sémantique avec le modèle multilingue e5 (vecteurs denses et regroupement)
- Recherche hybride avec le modèle d'insertion de texte de Vertex AI
Vous pouvez les trouver dans ce repo GitHub.
Prenons un exemple : la création d'embeddings avec les API Vertex AI de Google Cloud sur un catalogue de produits. Tout d'abord, nous devons créer le modèle de recherche dans Elasticsearch comme indiqué ci-dessous :
Dans cet exemple, nous allons exécuter une recherche KNN sur deux champs en une seule recherche : title_embedding - le champ vectoriel contenant le nom du produit - et description_embedding - celui contenant la représentation de sa description.
Vous pouvez tirer parti de la syntaxe excludes pour éviter de renvoyer des champs inutiles au LLM, ce qui pourrait provoquer du bruit dans son traitement et avoir un impact sur la qualité de la réponse finale. Dans notre exemple, nous avons exclu les champs contenant des vecteurs et des urls d'images.
Les vecteurs sont créés à la volée au moment de la requête sur l'entrée soumise via un point de terminaison d'inférence de l'API d'intégration de Vertex AI, googlevertexai_embeddings_004, précédemment défini comme suit :
Vous trouverez des informations supplémentaires sur l'utilisation de l'API d'inférence d'Elastic ici.
Nous sommes maintenant prêts à tester notre modèle de recherche :
Les champs params remplaceront les variables que nous avons définies dans les scripts modèles entre doubles crochets. Actuellement, les API Vertex AI LLM et Grounded Generation peuvent envoyer à Elastic les variables d'entrée suivantes :
- "query" - la requête de l'utilisateur à rechercher
- "index_name" - le nom de l'index dans lequel la recherche doit être effectuée
- "num_hits" - le nombre de documents que nous voulons retrouver dans la sortie finale
Voici un exemple de résultat :
La requête ci-dessus est précisément ce que Vertex AI de Google Cloud exécutera en coulisses sur Elasticsearch en se référant au modèle de recherche créé précédemment. Les modèles Gemini utiliseront les documents de sortie pour fonder leur réponse : lorsque vous demandez "De quoi ai-je besoin pour réparer mes cloisons sèches ?", au lieu d'obtenir une suggestion générique, l'agent conversationnel vous fournira des produits spécifiques !
Parcours GenAI de bout en bout avec Elastic et Google Cloud
Elastic s'associe à Google Cloud pour créer des expériences et des solutions GenAI de bout en bout, prêtes à la production. Comme nous venons de le voir, Elastic est le premier ISV à être intégré directement dans l'interface utilisateur et le SDK de la plateforme Vertex AI, ce qui permet des invites et des agents de modèles Gemini transparents et ancrés dans le sol, utilisant nos fonctions de recherche vectorielle. En outre, Elastic s'intègre à Vertex AI et aux modèles d'intégration, de reclassement et d'achèvement de Google AI Studiopour créer et classer des vecteurs sans quitter le paysage Google Cloud, garantissant ainsi les principes de l'IA responsable. En soutenant les approches multimodales, nous facilitons conjointement les applications dans divers formats de données.
Vous pouvez mettre au point, tester et exporter votre code de recherche GenAI via notre terrain de jeu.
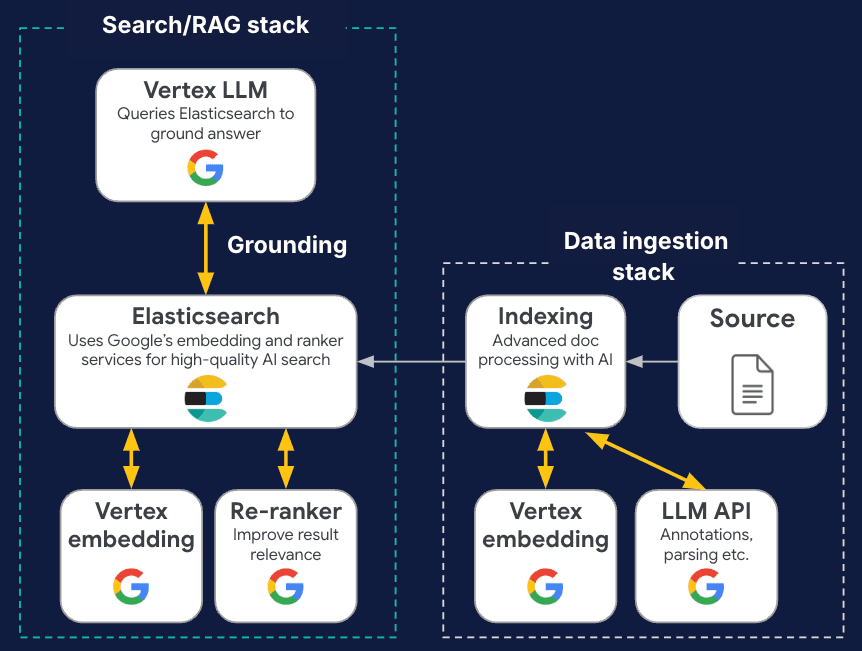
Mais il ne s'agit pas seulement de créer des applications de recherche : Elastic exploite les modèles Gemini pour renforcer les opérations informatiques, comme dans les fonctions Elastic AI Assistants, Attack Discovery et Automatic Import, réduisant la fatigue quotidienne des analystes de sécurité et des SRE sur des tâches à faible valeur ajoutée, et leur permettant de se concentrer sur l'amélioration de leur activité. Elastic permet également une surveillance complète de l'utilisation de Vertex AI, en suivant les métriques et les journaux, comme les temps de réponse, les jetons et les ressources, afin de garantir des performances optimales. Ensemble, nous gérons le cycle de vie complet de la GenAI, depuis l'ingestion de données et la génération d'embedding jusqu'à l'ancrage avec la recherche hybride, tout en garantissant une observabilité et une sécurité robustes des outils de la GenAI avec des actions alimentées par LLM.
Découvrez-en plus et essayez-le !
Êtes-vous intéressé(e) par cet essai ? La fonctionnalité est actuellement disponible sur vos projets Google Cloud !
Si vous ne l'avez pas encore fait, l'une des façons les plus simples de démarrer avec Elastic Search AI Platform et d'explorer nos capacités est d'essayer gratuitement Elastic Cloud ou de vous abonner via Google Cloud Marketplace.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout. Elastic, Elasticsearch et les marques associées sont des marques commerciales, des logos ou des marques déposées d'Elasticsearch N.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
Questions fréquentes
Qu'est-ce que la plateforme Vertex AI de Google Cloud ?
Vertex AI est la plateforme unifiée de Google Cloud pour l'ensemble du cycle de vie de l'intelligence artificielle. Il est conçu pour combler le fossé entre la recherche "" et la production "" en réunissant les meilleurs outils d'apprentissage machine (ML) et d'IA générative de Google.
Quels sont les avantages de l'utilisation d'Elasticsearch dans la plateforme Vertex AI de Google Cloud ?
Les principaux avantages de l'utilisation d'Elasticsearch dans la plateforme Vertex AI de Google résident dans le fait qu'il suffit de quelques étapes simples pour configurer les points de terminaison Elastic avec les paramètres souhaités, tels que l'index à rechercher ou le nombre de documents à récupérer.
Quelles sont les ressources dont dispose Elasticsearch pour faciliter la configuration des requêtes pour les modèles Gemini ?
Elasticsearch dispose de modèles de recherche personnalisables qui peuvent être utilisés pour créer des requêtes de recherche dynamiques et réutilisables.
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.