Von der Vektorsuche bis hin zu leistungsstarken REST-APIs bietet Elasticsearch Entwicklern das umfangreichste Toolkit für Suchvorgänge. Entdecken Sie unsere Beispiel-Notebooks im Elasticsearch Labs Repository, um etwas Neues auszuprobieren. Sie können auch heute noch Ihre kostenlose Testphase starten oder Elasticsearch lokal ausführen.
Wenn die Suche nach freiem Text erforderlich ist und Strg+F bzw. Cmd+F nicht mehr ausreicht, ist die Verwendung einer lexikalischen Suchmaschine normalerweise die nächste logische Wahl, die einem in den Sinn kommt. Lexikalische Suchmaschinen zeichnen sich durch die Analyse und Tokenisierung des zu durchsuchenden Textes in Begriffe aus, die zum Suchzeitpunkt abgeglichen werden können. Allerdings versagen sie in der Regel, wenn es darum geht, die wahre Bedeutung des indizierten und durchsuchten Textes zu verstehen und zu erschließen.
Genau hier glänzen Vektorsuchmaschinen. Sie können denselben Text so indizieren, dass er sowohl auf der Grundlage der dargestellten Bedeutung als auch seiner Beziehungen zu anderen Konzepten mit ähnlicher oder verwandter Bedeutung durchsucht werden kann.
In diesem Blog werden wir kurz darauf eingehen, warum Vektoren ein großartiges mathematisches Konzept sind, um die Bedeutung von Text zu vermitteln. Anschließend werden wir uns eingehender mit den verschiedenen Ähnlichkeitstechniken befassen, die von Elasticsearch bei der Suche nach benachbarten Vektoren unterstützt werden, d. h. bei der Suche nach Vektoren mit ähnlicher Bedeutung, und wie diese bewertet werden.
Was sind Vektoreinbettungen?
Dieser Artikel geht nicht näher auf die Feinheiten von Vektoreinbettungen ein. Wenn Sie dieses Thema weiter vertiefen möchten oder eine Einführung benötigen, bevor Sie fortfahren, empfehlen wir Ihnen, sich den folgenden Leitfaden anzusehen.
Kurz gesagt, Vektoreinbettungen werden durch einen maschinellen Lernprozess erhalten (z. B. Deep-Learning-Neuronale Netzwerke), die jede Art unstrukturierter Eingabedaten (z. B. Rohtext, Bild, Video, Ton usw.) in numerische Daten umwandeln, die deren Bedeutung und Beziehungen enthalten. Verschiedene Arten unstrukturierter Daten erfordern unterschiedliche Arten von maschinellen Lernmodellen, die darauf trainiert wurden, jeden Datentyp zu „verstehen“.
Jeder Vektor lokalisiert ein bestimmtes Datenelement als Punkt in einem mehrdimensionalen Raum und dieser Ort stellt eine Reihe von Merkmalen dar, die das Modell zur Charakterisierung der Daten verwendet. Die Anzahl der Dimensionen hängt vom Modell des maschinellen Lernens ab, liegt aber normalerweise zwischen einigen Hundert und einigen Tausend. Beispielsweise verfügen OpenAI Embeddings-Modelle über 1536 Dimensionen, während Cohere Embeddings-Modelle zwischen 382 und 4096 Dimensionen umfassen können. Der Elasticsearch-Feldtyp „dense_vector“ unterstützt ab der neuesten Version bis zu 4096 Dimensionen.
Die wahre Leistung von Vektoreinbettungen besteht darin, dass Datenpunkte mit ähnlicher Bedeutung im Raum nahe beieinander liegen. Ein weiterer interessanter Aspekt ist, dass Vektoreinbettungen auch dabei helfen, Beziehungen zwischen Datenpunkten zu erfassen.
Wie vergleichen wir Vektoren?
Da wir wissen, dass unstrukturierte Daten von Modellen des maschinellen Lernens in Vektoreinbettungen zerlegt und gewürfelt werden, die die Ähnlichkeit der Daten entlang einer großen Anzahl von Dimensionen erfassen, müssen wir nun verstehen, wie das Zuordnen dieser Vektoren funktioniert. Es stellt sich heraus, dass die Antwort ziemlich einfach ist.
Nahe beieinander liegende Vektoreinbettungen stellen semantisch ähnliche Datenstücke dar. Wenn wir also eine Vektordatenbank abfragen, wird die Sucheingabe (Bild, Text usw.) zunächst mithilfe desselben maschinellen Lernmodells, das zum Indizieren aller unstrukturierten Daten verwendet wurde, in Vektoreinbettungen umgewandelt. Das ultimative Ziel besteht darin, die nächstgelegenen Nachbarvektoren zu diesem Abfragevektor zu finden. Daher müssen wir nur herausfinden, wie wir die „Distanz“ oder „Ähnlichkeit“ zwischen dem Abfragevektor und allen vorhandenen, in der Datenbank indizierten Vektoren messen können – so einfach ist das.
Distanz, Ähnlichkeit und Wertung
Glücklicherweise ist das Messen der Distanz oder Ähnlichkeit zwischen zwei Vektoren dank der Vektorarithmetik ein leicht zu lösendes Problem. Sehen wir uns also die beliebtesten Distanz- und Ähnlichkeitsfunktionen an, die von Elasticsearch unterstützt werden. Achtung, Mathematik voraus!
Bevor wir eintauchen, werfen wir einen kurzen Blick auf die Wertung. Tatsächlich lässt Lucene nur positive Ergebnisse zu. Alle Distanz- und Ähnlichkeitsfunktionen, die wir in Kürze vorstellen werden, liefern ein Maß dafür, wie nahe oder ähnlich zwei Vektoren beieinander liegen. Diese Rohwerte eignen sich jedoch selten als Bewertung, da sie negativ sein können. Aus diesem Grund muss die endgültige Punktzahl aus dem Distanz- oder Ähnlichkeitswert so abgeleitet werden, dass sichergestellt ist, dass die Punktzahl positiv ist und eine höhere Punktzahl einer höheren Rangfolge entspricht (d. h. näheren Vektoren).
L1-Abstand
Die L1-Distanz, auch Manhattan-Distanz genannt, zweier Vektoren und wird durch Summieren der paarweisen absoluten Differenz aller ihrer Elemente gemessen. Offensichtlich ist es so, dass die beiden Vektoren umso näher beieinander liegen, je kleiner der Abstand ist. Die L1-Distanzformel (1) ist ziemlich einfach, wie unten zu sehen ist:
Visuell kann der L1-Abstand wie im folgenden Bild (in Rot) dargestellt dargestellt werden:

Die Berechnung der L1-Distanz der folgenden beiden Vektoren und würde ergeben
Wichtig: Es ist zu beachten, dass die L1-Distanzfunktion nur für die exakte Vektorsuche (auch Brute-Force-Suche genannt) mit der script_score DSL-Abfrage unterstützt wird, nicht jedoch für die ungefähre kNN-Suche mit der knn -Suchoption oder der knn DSL-Abfrage.
L2-Distanz
Die L2-Distanz, auch euklidische Distanz genannt, zweier Vektoren und wird gemessen, indem zunächst die Quadrate der paarweisen Differenz aller ihrer Elemente summiert und dann die Quadratwurzel aus dem Ergebnis gezogen wird. Es ist im Grunde der kürzeste Weg zwischen zwei Punkten. Ähnlich wie bei L1 gilt: Je kleiner der Abstand , desto näher liegen die beiden Vektoren beieinander:
Der L2-Abstand ist im folgenden Bild rot dargestellt:

Lassen Sie uns dieselben beiden Beispielvektoren und wiederverwenden, die wir für die -Distanz verwendet haben, und wir können nun die -Distanz als berechnen.
Was die Bewertung betrifft, gilt: Je kleiner der Abstand zwischen zwei Vektoren ist, desto näher (d. h. desto ähnlicher) sind sie sich. Um also eine Punktzahl abzuleiten, müssen wir das Distanzmaß umkehren, sodass die kleinste Distanz die höchste Punktzahl ergibt. Die Berechnung des Scores bei Verwendung der L2-Distanz sieht wie in der folgenden Formel (3) dargestellt aus:
Bei erneuter Verwendung der Beispielvektoren aus dem vorherigen Beispiel wäre ihr Ergebnis . Zwei Vektoren, die sehr nahe beieinander liegen, erreichen einen Wert von 1, während der Wert zweier Vektoren, die sehr weit voneinander entfernt sind, gegen 0 tendiert.
Um die Distanzfunktionen L1 und L2 abzuschließen: Eine gute Analogie zum Vergleich besteht darin, sich A und B als zwei Gebäude in Manhattan, New York, vorzustellen. Ein Taxi, das von A nach B fährt, müsste den Weg L1 (Straßen und Alleen) entlangfahren, während ein Vogel wahrscheinlich den Weg L2 (gerade Linie) benutzen würde.
Kosinusähnlichkeit
Im Gegensatz zu L1 und L2 misst die Kosinusähnlichkeit nicht den Abstand zwischen zwei Vektoren und , sondern ihren relativen Winkel, d. h., ob sie beide ungefähr in die gleiche Richtung zeigen. Je höher die Ähnlichkeit , desto kleiner ist der Winkel zwischen den beiden Vektoren und desto „näher“ sind sie sich und desto „ähnlich“ ist ihre vermittelte Bedeutung.
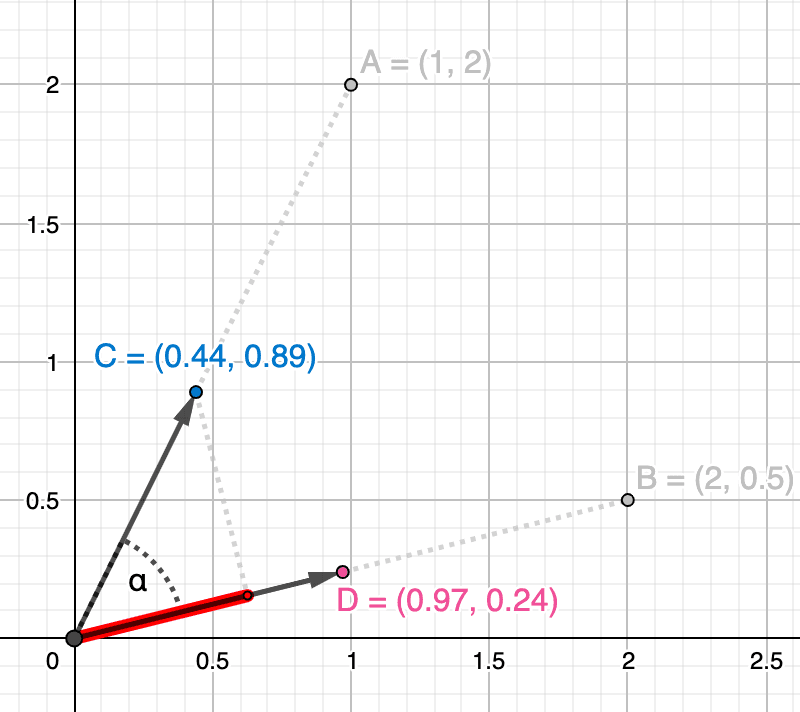
Um dies zu veranschaulichen, stellen wir uns zwei Menschen in der Wildnis vor, die in unterschiedliche Richtungen schauen. In der folgenden Abbildung blickt die Person in Blau in die durch den Vektor symbolisierte Richtung und die Person in Rot in die Richtung des Vektors . Je mehr sie ihren Blick in die gleiche Richtung richten (d. h. je näher ihre Vektoren beieinander liegen), desto mehr überlappen sich ihre Sichtfelder, die durch die blauen und roten Bereiche symbolisiert werden. Wie stark sich ihre Sichtfelder überschneiden, ist ihre Kosinusähnlichkeit. Beachten Sie jedoch, dass Person B weiter weg schaut als Person A (d. h., der Vektor ist länger). Person B könnte einen Berg weit entfernt am Horizont betrachten, während Person A einen nahegelegenen Baum betrachten könnte. Bei der Kosinusähnlichkeit spielt das keine Rolle, da es nur um den Winkel geht.

Berechnen wir nun diese Kosinusähnlichkeit. Die Formel (4) ist ziemlich einfach, wobei der Zähler aus dem Skalarprodukt beider Vektoren besteht und der Nenner das Produkt ihrer Beträge (also ihrer Länge) enthält:
Die Kosinusähnlichkeit zwischen und wird im Bild unten als Maß für den Winkel zwischen ihnen (in Rot) dargestellt:

Machen wir einen kurzen Umweg, um zu erklären, was diese Kosinus-Ähnlichkeitswerte konkret bedeuten. Wie im Bild unten zur Darstellung der Kosinusfunktion zu sehen ist, schwanken die Werte immer im Intervall .
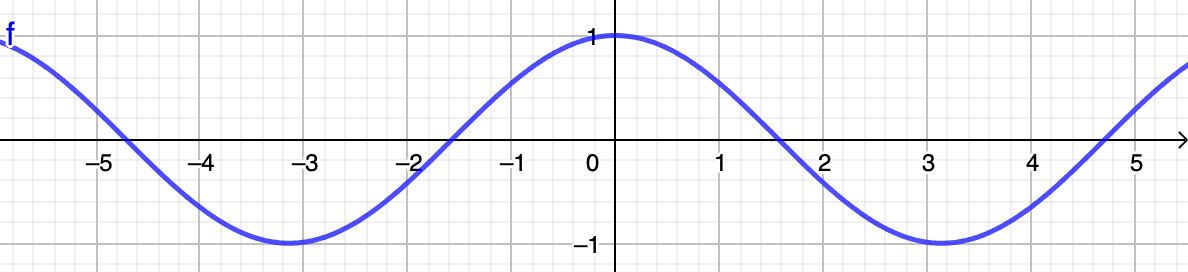
Denken Sie daran, dass der Winkel zweier Vektoren so spitz wie möglich sein muss, damit sie als ähnlich gelten. Idealerweise sollte er nahe bei liegen, was auf eine perfekte Ähnlichkeit von hinauslaufen würde. Mit anderen Worten, wenn Vektoren ...
- ... nahe beieinander liegt , nähert sich der Kosinus ihres Winkels (d. h. nahe )

- ...unabhängig, der Kosinus ihres Winkels nähert sich (d. h. nahe )

- ...gegenüberliegend, der Kosinus ihres Winkels nähert sich (d. h. nahe )

Da wir nun wissen, wie man die Kosinusähnlichkeit zwischen zwei Vektoren berechnet und eine gute Vorstellung davon haben, wie der resultierende Wert zu interpretieren ist, können wir dieselben Beispielvektoren und erneut verwenden und ihre Kosinusähnlichkeit mit der Formel (4) berechnen, die wir zuvor gesehen haben.
Wir erhalten eine Kosinusähnlichkeit von , die näher bei als bei liegt, was bedeutet, dass die beiden Vektoren einigermaßen ähnlich sind, d. h. nicht perfekt ähnlich, aber auch nicht völlig unabhängig voneinander und sicherlich nicht gegensätzliche Bedeutungen haben.
Um aus einem beliebigen Kosinus-Ähnlichkeitswert einen positiven Wert abzuleiten, müssen wir die folgende Formel (5) verwenden, die Kosinus-Ähnlichkeitswerte, die innerhalb des Intervalls schwanken, in Werte im Intervall umwandelt:
Der Score für die Stichprobenvektoren und wäre somit: .
Skalarproduktähnlichkeit
Ein Nachteil der Kosinusähnlichkeit besteht darin, dass sie nur den Winkel zwischen zwei Vektoren berücksichtigt, nicht jedoch deren Betrag. Das bedeutet, dass, wenn zwei Vektoren ungefähr in die gleiche Richtung zeigen, einer jedoch viel länger ist als der andere, beide immer noch als ähnlich betrachtet werden. Die Skalarproduktähnlichkeit, auch Skalarproduktähnlichkeit oder innere Produktähnlichkeit genannt, verbessert dies, indem sie sowohl den Winkel als auch die Größe der Vektoren berücksichtigt, was zu einer genaueren Ähnlichkeitsmetrik führt. Um die Größe der Vektoren irrelevant zu machen, erfordert die Skalarproduktähnlichkeit, dass die Vektoren zuerst normalisiert werden, sodass wir letztendlich nur Vektoren der Einheitslänge 1 vergleichen.
Versuchen wir, dies noch einmal mit denselben zwei Personen wie zuvor zu veranschaulichen, aber diesmal platzieren wir sie in der Mitte eines runden Raums, sodass ihre Sichtweite genau gleich ist (d. h. der Radius des Raums). Ähnlich wie bei der Kosinusähnlichkeit gilt: Je mehr sie sich in die gleiche Richtung drehen (d. h. je näher ihre Vektoren beieinander liegen), desto stärker überlappen sich ihre Sichtfelder. Im Gegensatz zur Kosinusähnlichkeit haben jedoch beide Vektoren die gleiche Länge und beide Bereiche die gleiche Oberfläche, was bedeutet, dass die beiden Personen genau dasselbe Bild in der gleichen Entfernung betrachten. Wie gut sich diese beiden Bereiche überschneiden, zeigt die Ähnlichkeit ihres Skalarprodukts an.

Bevor wir die Formel für die Ähnlichkeit von Skalarprodukten vorstellen, wollen wir kurz sehen, wie ein Vektor normalisiert werden kann. Es ist ziemlich einfach und kann in zwei trivialen Schritten durchgeführt werden:
- Berechnen Sie die Größe des Vektors
- Teilen Sie jede Komponente durch die in 1 erhaltene Größe.
Nehmen wir als Beispiel den Vektor . Wir können seinen Betrag berechnen, wie wir bereits bei der Betrachtung der Kosinusähnlichkeit gesehen haben, d. h. . Wenn wir dann jede Komponente des Vektors durch ihren Betrag dividieren, erhalten wir den folgenden normalisierten Vektor :
Wenn wir den gleichen Prozess für den zweiten Vektor durchführen, erhalten wir den folgenden normalisierten Vektor :
Um die Formel für die Ähnlichkeit des Skalarprodukts abzuleiten, können wir die Kosinusähnlichkeit zwischen unseren normalisierten Vektoren und mithilfe der Formel (4) berechnen, wie unten gezeigt:
Und da der Betrag beider normalisierten Vektoren nun ist, wird die Skalarprodukt-Ähnlichkeitsformel (6) einfach ... Sie haben es erraten, ein Skalarprodukt beider normalisierten Vektoren:
Im Bild unten zeigen wir die normalisierten Vektoren und und können ihre Skalarproduktähnlichkeit als Projektion eines Vektors auf den anderen (in Rot) veranschaulichen.
Mit unserer neuen Formel (6) können wir die Skalarproduktähnlichkeit unserer beiden normalisierten Vektoren berechnen, die wenig überraschend genau denselben Ähnlichkeitswert wie der Kosinuswert ergibt:
Bei der Nutzung der Skalarproduktähnlichkeit wird die Punktzahl unterschiedlich berechnet, je nachdem, ob die Vektoren Gleitkomma- oder Bytewerte enthalten. Im ersten Fall wird der Wert auf die gleiche Weise wie für die Kosinusähnlichkeit berechnet, und zwar mit der folgenden Formel (7):
Wenn der Vektor jedoch aus Bytewerten besteht, wird die Bewertung etwas anders berechnet, wie in der folgenden Formel (8) gezeigt, wobei die Anzahl der Dimensionen des Vektors ist:
Eine weitere Einschränkung zur Erzielung genauer Ergebnisse besteht darin, dass alle Vektoren, einschließlich des Abfragevektors, dieselbe Länge haben müssen, aber nicht unbedingt 1.
Maximale innere Produktähnlichkeit
Seit Version 8.11 gibt es eine neue Ähnlichkeitsfunktion, die weniger Einschränkungen unterliegt als die Skalarproduktähnlichkeit, da die Vektoren nicht normalisiert werden müssen. Der Hauptgrund hierfür wird im folgenden Artikel ausführlich erläutert. Um es jedoch kurz zusammenzufassen: Bestimmte Datensätze sind nicht sehr gut für die Normalisierung ihrer Vektoren geeignet (z. B. Cohere-Einbettungen), und dies kann zu Relevanzproblemen führen.
Die Formel zur Berechnung der maximalen Ähnlichkeit des inneren Produkts ist genau dieselbe wie die Formel für das Skalarprodukt (6). Was sich ändert, ist die Art und Weise, wie der Score berechnet wird, indem die maximale Ähnlichkeit des inneren Produkts mithilfe einer stückweisen Funktion skaliert wird, deren Formel davon abhängt, ob die Ähnlichkeit positiv oder negativ ist, wie in der folgenden Formel (9) gezeigt:
Diese stückweise Funktion skaliert alle negativen maximalen Ähnlichkeitswerte des inneren Produkts im Intervall und alle positiven Werte im Intervall .
Zusammenfassend
Das war mathematisch gesehen eine ziemliche Reise, aber hier sind ein paar Erkenntnisse, die Sie vielleicht nützlich finden.
Welche Ähnlichkeitsfunktion Sie verwenden können, hängt letztendlich davon ab, ob Ihre Vektoreinbettungen normalisiert sind oder nicht. Wenn Ihre Vektoren bereits normalisiert sind oder Ihr Datensatz agnostisch gegenüber der Vektornormalisierung ist (d. h. die Relevanz wird nicht beeinträchtigt), können Sie Ihre Vektoren normalisieren und die Skalarproduktähnlichkeit verwenden, da diese viel schneller zu berechnen ist als die Kosinusähnlichkeit, da die Länge jedes Vektors nicht berechnet werden muss. Beim Vergleich von Millionen von Vektoren können sich diese Berechnungen ziemlich summieren.
Wenn Ihre Vektoren nicht normalisiert sind, haben Sie zwei Möglichkeiten:
- Verwenden Sie die Kosinusähnlichkeit, wenn die Normalisierung Ihrer Vektoren keine Option ist
- Verwenden Sie die neue maximale Ähnlichkeit des inneren Produkts, wenn die Größe Ihrer Vektoren zur Bewertung beitragen soll, da sie eine Bedeutung haben (z. B. Cohere-Einbettungen).
An diesem Punkt sollte es für Sie Sinn ergeben, die Distanz oder Ähnlichkeit zwischen Vektoreinbettungen zu berechnen und ihre Werte abzuleiten. Wir hoffen, dass dieser Artikel für Sie hilfreich war.
Häufige Fragen
Was misst die Kosinus-Ähnlichkeit?
Die Kosinusähnlichkeit misst den relativen Winkel zwischen zwei Vektoren, d. h., ob sie beide ungefähr in die gleiche Richtung zeigen.
Wie wird der L1-Abstand gemessen?
Die L1-Distanz wird gemessen, indem die paarweise absolute Differenz aller ihrer Elemente summiert wird.
Wie wird die L2-Distanz gemessen?
Der L2-Abstand, auch euklidischer Abstand genannt, zweier Vektoren wird gemessen, indem zunächst das Quadrat der paarweisen Differenz aller ihrer Elemente summiert und dann die Quadratwurzel des Ergebnisses gezogen wird.
Worin besteht der Unterschied zwischen den Distanzen L1 und L2?
Der Unterschied zwischen L1- und L2-Distanz hängt davon ab, wie man zwei Vektoren misst. Die L1-Distanz wird gemessen, indem die paarweise absolute Differenz aller ihrer Elemente summiert wird. Die L2-Distanz wird hingegen dadurch gemessen, dass man zuerst die Quadrate der paarweisen Differenzen aller ihrer Elemente aufsummiert und dann die Quadratwurzel des Ergebnisses zieht.
Worin besteht der Unterschied zwischen Kosinusähnlichkeit und Kosinusdistanz?
Die Kosinusähnlichkeit misst den relativen Winkel zweier Vektoren, d. h. ob sie beide in etwa in die gleiche Richtung zeigen. Die Kosinusdistanz hingegen misst, wie unterschiedlich ihre Richtungen sind.
Worin besteht der Unterschied zwischen Skalarprodukt und Kosinusähnlichkeit?
Das Skalarprodukt misst sowohl die Länge als auch die Ausrichtung von Vektoren, während die Kosinusähnlichkeit nur misst, wie stark ihre Richtungen ausgerichtet sind, und die Länge außer Acht lässt.
Wann sollte man das Skalarprodukt und wann die Kosinusähnlichkeit verwenden?
Wenn Ihre Vektoren normalisiert sind (oder normalisiert werden können, ohne die Relevanz zu beeinträchtigen), verwenden Sie die Skalarproduktähnlichkeit – sie ist schneller, da Sie die Vektorlängen nicht berechnen müssen. Sind Ihre Vektoren nicht normalisiert, verwenden Sie die Kosinusähnlichkeit, wenn es Ihnen nur um die Richtung geht, oder das Skalarprodukt, wenn die Vektorgröße eine Bedeutung hat und das Ergebnis beeinflussen soll.
Wie wählt man die richtige Distanzmetrik für die Vektorsuche aus?
Wählen Sie eine Distanzmetrik basierend auf Ihren Vektoren und dem, was für Ihre Suche wichtig ist: Verwenden Sie L1 oder L2, um absolute Unterschiede zu messen, Kosinusähnlichkeit, wenn nur die Richtung wichtig ist, Skalarprodukt, wenn sowohl Richtung als auch Betrag wichtig sind (und die Vektoren normalisiert sind), oder maximales inneres Produkt, wenn die Vektoren nicht normalisiert sind, aber der Betrag die Relevanz beeinflussen soll.
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

20. März 2026
Schnell vs. genau: Messung der Recall-Rate bei der quantisierten Vektorsuche
Eine Erklärung, wie der Recall für die Vektorsuche in Elasticsearch mit minimalem Aufwand gemessen werden kann.