Desde la búsqueda vectorial hasta las potentes API REST, Elasticsearch ofrece a los desarrolladores el conjunto de herramientas de búsqueda más completo. Explora nuestros cuadernos de muestra en el repositorio de Elasticsearch Labs para probar algo nuevo. También puedes iniciar tu prueba gratuita o ejecutar Elasticsearch localmente hoy mismo.
Cuando surge la necesidad de buscar texto libre y Ctrl+F / Cmd+F ya no es suficiente, el uso de un motor de búsqueda léxico suele ser la siguiente opción lógica que se le viene a la mente. Los motores de búsqueda léxicos se destacan en el análisis y la tokenización del texto que se buscará en términos que se pueden comparar en el momento de la búsqueda, pero generalmente se quedan cortos cuando se trata de comprender y dar sentido al verdadero significado del texto que se indexa y busca.
Ahí es exactamente donde brillan los motores de búsqueda vectorial. Pueden indexar el mismo texto de tal manera que se pueda buscar tanto en función del significado que representa como de sus relaciones con otros conceptos que tienen un significado similar o relacionado.
En este blog, abordaremos brevemente cómo los vectores son un gran concepto matemático para transmitir el significado del texto. Luego, profundizaremos en las diferentes técnicas de similitud compatibles con Elasticsearch cuando se trata de buscar vectores vecinos, es decir, buscar vectores que tengan un significado similar y cómo puntuarlos.
¿Qué son las incrustaciones de vectores?
Este artículo no profundiza en las complejidades de las incrustaciones de vectores. Si quieres explorar este tema más a fondo o necesitas una introducción antes de continuar, te recomendamos que consultes la siguiente guía.
En pocas palabras, las incrustaciones vectoriales se obtienen a través de un proceso de aprendizaje automático (p. ej. redes neuronales de aprendizaje profundo) que transforma cualquier tipo de datos de entrada no estructurados (por ejemplo, texto sin procesar, imagen, video, sonido, etc.) en datos numéricos que llevan su significado y relaciones. Los diferentes tipos de datos no estructurados requieren diferentes tipos de modelos de aprendizaje automático que fueron capacitados para "comprender" cada tipo de datos.
Cada vector localiza un dato específico como un punto en un espacio multidimensional y esa ubicación representa un conjunto de características que el modelo emplea para caracterizar los datos. El número de dimensiones depende del modelo de aprendizaje automático, pero generalmente oscilan entre un par de cientos y unos pocos miles. Por ejemplo, los modelos OpenAI Embeddings cuentan con 1536 dimensiones, mientras que los modelos Cohere Embeddings pueden variar de 382 a 4096 dimensiones. El tipo de campo Elasticsearch dense_vector admite hasta 4096 dimensiones a partir de la última versión.
La verdadera hazaña de las incrustaciones vectoriales es que los puntos de datos que comparten un significado similar están muy juntos en el espacio. Otro aspecto interesante es que las incrustaciones vectoriales también ayudan a capturar relaciones entre puntos de datos.
¿Cómo comparamos vectores?
Sabiendo que los datos no estructurados son divididos por modelos de aprendizaje automático en incrustaciones vectoriales que capturan la similitud de los datos a lo largo de una gran cantidad de dimensiones, ahora necesitamos comprender cómo funciona la coincidencia de esos vectores. Resulta que la respuesta es bastante simple.
Las incrustaciones vectoriales que están cerca unas de otras representan datos semánticamente similares . Entonces, cuando consultamos una base de datos vectorial, la entrada de búsqueda (imagen, texto, etc.) se convierte primero en incrustaciones vectoriales empleando el mismo modelo de aprendizaje automático que se empleó para indexar todos los datos no estructurados, y el objetivo final es encontrar los vectores vecinos más cercanos a ese vector de consulta. Por lo tanto, todo lo que tenemos que hacer es averiguar cómo medir la "distancia" o "similitud" entre el vector de consulta y todos los vectores existentes indexados en la base de datos, es así de simple.
Distancia, similitud y puntaje
Por suerte para nosotros, medir la distancia o similitud entre dos vectores es un problema fácil de resolver gracias a la aritmética vectorial. Entonces, veamos las funciones de distancia y similitud más populares que son compatibles con Elasticsearch. ¡Advertencia, matemáticas por delante!
Justo antes de sumergirnos, echemos un vistazo rápido al puntaje. De hecho, Lucene solo permite que los puntajes sean positivos. Todas las funciones de distancia y similitud que presentaremos en breve producen una medida de qué tan cerca o similares están dos vectores, pero esas cifras en bruto rara vez son aptas para usar como puntaje, ya que pueden ser negativas. Por esta razón, el puntaje final debe derivar del valor de distancia o similitud de una manera que garantice que el puntaje sea positivo y que un puntaje mayor corresponda a una clasificación más alta (es decir, a vectores más cercanos).
Distancia L1
La distancia L1, también llamada distancia de Manhattan, de dos vectores y se mide sumando la diferencia absoluta por pares de todos sus elementos. Obviamente, cuanto menor sea la distancia , más cerca estarán los dos vectores. La fórmula de la distancia L1 (1) es bastante simple, como se puede ver a continuación:
Visualmente, la distancia L1 se puede ilustrar como se muestra en la imagen a continuación (en rojo):

Calculando la distancia L1 de los siguientes dos vectores y obtendría
Importante: Vale la pena señalar que la función de distancia L1 solo es compatible con la búsqueda vectorial exacta (también conocida como búsqueda de fuerza bruta) empleando la consulta DSL script_score, pero no para la búsqueda aproximada de kNN empleando la opción de búsqueda knno knn consulta DSL.
Distancia L2
La distancia L2, también llamada distancia euclidiana, de dos vectores y se mide sumando primero el cuadrado de la diferencia por pares de todos sus elementos y luego tomando la raíz cuadrada del resultado. Es básicamente el camino más corto entre dos puntos. De manera similar a L1, cuanto menor sea la distancia , más cerca estarán los dos vectores:
La distancia L2 se muestra en rojo en la siguiente imagen:

Reutilicemos los mismos dos vectores de muestra y que usamos para la distancia , y ahora podemos calcular la distancia como .
En cuanto al puntaje, cuanto menor es la distancia entre dos vectores, más cerca (es decir, más similares) están. Entonces, para derivar un puntaje, necesitamos invertir la medida de distancia, de modo que la distancia más pequeña produzca el puntaje más alta. La forma en que se calcula el puntaje cuando se usa la distancia L2 se ve como se muestra en la fórmula (3) a continuación:
Reutilizando los vectores de muestra del ejemplo anterior, su puntaje sería . Dos vectores que están muy cerca uno del otro se acercarán a un puntaje de 1, mientras que el puntaje de dos vectores que están muy lejos uno del otro tenderá hacia 0.
Terminando con las funciones de distancia L1 y L2, una buena analogía para compararlas es pensar en A y B como dos edificios en Manhattan, Nueva York. Un taxi que va de A a B tendría que manejar por el camino L1 (calles y avenidas), mientras que un pájaro probablemente usaría el camino L2 (línea recta).
Similitud de coseno
A diferencia de L1 y L2, la similitud del coseno no mide la distancia entre dos vectores y , sino su ángulo relativo, es decir, si ambos apuntan aproximadamente en la misma dirección. Cuanto mayor sea la similitud , menor será el ángulo entre los dos vectores y, por lo tanto, más "cercanos" están y "similar" es su significado transmitido.
Para ilustrar esto, pensemos en dos personas en la naturaleza que miran en diferentes direcciones. En la siguiente figura, la persona en azul mira en la dirección simbolizada por el vector y la persona en rojo en la dirección del vector . Cuanto más dirijan su vista hacia la misma dirección (es decir, cuanto más se acerquen sus vectores), más se superpondrá su campo de visión simbolizado por las áreas azul y roja. Cuánto se superpone su campo de visión es su similitud con el coseno. Sin embargo, tenga en cuenta que la persona B mira más lejos que la persona A (es decir, el vector es más largo). La persona B podría estar mirando una montaña lejana en el horizonte, mientras que la persona A podría estar mirando un árbol cercano. Para la similitud del coseno, eso no juega ningún papel, ya que solo se trata del ángulo.

Ahora calculemos esa similitud de coseno. La fórmula (4) es bastante simple, donde el numerador consiste en el producto punto de ambos vectores y el denominador contiene el producto de su magnitud (es decir, su longitud):
La similitud del coseno entre y se muestra en la imagen de abajo como una medida del ángulo entre ellos (en rojo):

Tomemos un desvío rápido para explicar qué significan concretamente estos valores de similitud de coseno. Como se puede ver en la imagen a continuación que muestra la función de coseno, los valores siempre oscilan en el intervalo
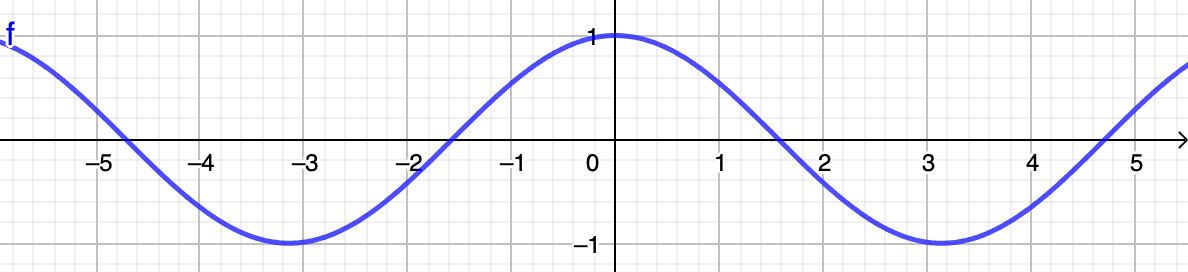
Recuerde que para que dos vectores se consideren similares, su ángulo debe ser lo más agudo posible, idealmente cerca de un ángulo de , lo que se reduciría a una similitud perfecta de . En otras palabras, cuando los vectores son...
- ...cerca uno del otro, el coseno de su ángulo se acerca a (es decir, cerca de )

- ...sin relación, el coseno de su ángulo se acerca a (es decir, cerca de )

- ...opuesto, el coseno de su ángulo se acerca a (es decir, cerca de )

Ahora que sabemos cómo calcular la similitud del coseno entre dos vectores y tenemos una buena idea de cómo interpretar el valor resultante, podemos reutilizar los mismos vectores y y calcular su similitud de coseno usando la fórmula (4) que vimos anteriormente.
Obtenemos una similitud de coseno de , que está más cerca de que de , lo que significa que los dos vectores son algo similares, es decir, no perfectamente similares, pero tampoco completamente desrelacionados, y ciertamente no tienen un significado opuesto.
Para obtener un puntaje positivo de cualquier valor de similitud de coseno, necesitamos usar la siguiente fórmula (5), que transforma los valores de similitud de coseno que oscilan dentro del intervalo en puntajes en el intervalo
El puntaje para los vectores y sería: .
Similitud de productos Dot
Un inconveniente de la similitud del coseno es que solo tiene en cuenta el ángulo entre dos vectores pero no su magnitud, lo que significa que si dos vectores apuntan aproximadamente en la misma dirección pero uno es mucho más largo que el otro, ambos se considerarán similares. La similitud de producto punto, también llamada similitud de producto escalar o interno, mejora eso al tener en cuenta tanto el ángulo como la magnitud de los vectores, lo que proporciona una métrica de similitud más precisa. Para hacer que la magnitud de los vectores sea irrelevante, la similitud del producto punto requiere que los vectores se normalicen primero, por lo que, en última instancia, solo estamos comparando vectores de longitud unitaria 1.
Intentemos ilustrar esto nuevamente con las mismas dos personas que antes, pero esta vez, las colocamos en el medio de una habitación circular, de modo que su alcance visual sea exactamente el mismo (es decir, el radio de la habitación). De manera similar a la similitud del coseno, cuanto más volteen hacia la misma dirección (es decir, cuanto más se acerquen sus vectores), más se superpondrá su campo de visión. Sin embargo, al contrario de la similitud del coseno, ambos vectores tienen la misma longitud y ambas áreas tienen la misma superficie, lo que significa que las dos personas miran exactamente la misma imagen ubicada a la misma distancia. La superposición de esas dos áreas denota su similitud de producto punto.

Antes de introducir la fórmula de similitud de producto punto, veamos rápidamente cómo se puede normalizar un vector. Es bastante simple y se puede hacer en dos pasos triviales:
- calcular la magnitud del vector
- Divida cada componente por la magnitud obtenida en 1.
Como ejemplo, tomemos el vector . Podemos calcular su magnitud como vimos anteriormente al revisar la similitud del coseno, es decir, . Luego, dividiendo cada componente del vector por su magnitud, obtenemos el siguiente vector estandarizado :
Pasar por el mismo proceso para el segundo vector obtendría el siguiente vector estandarizado :
Para derivar la fórmula de similitud de producto punto, podemos calcular la similitud de coseno entre nuestros vectores estandarizados y usando la fórmula (4), como se muestra a continuación:
Y dado que la magnitud de ambos vectores estandarizados es ahora , la fórmula de similitud del producto punto (6) simplemente se convierte en... Lo adivinaste, un producto punto de ambos vectores estandarizados:
En la imagen a continuación, mostramos los vectores estandarizados y y podemos ilustrar su similitud de producto punto como la proyección de un vector sobre el otro (en rojo).
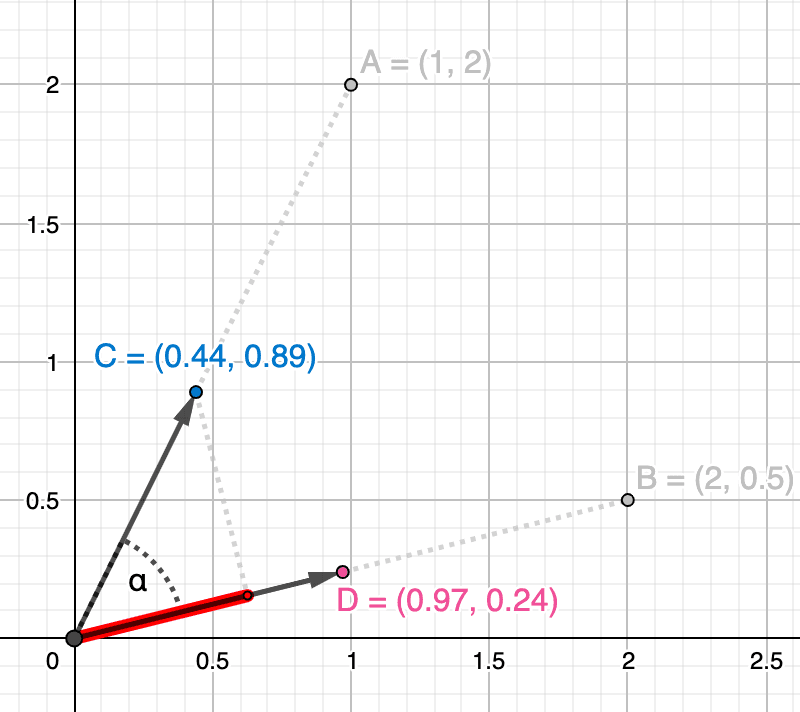
Usando nuestra nueva fórmula (6), podemos calcular la similitud del producto punto de nuestros dos vectores estandarizados, lo que como era de esperar produce exactamente el mismo valor de similitud que el del coseno:
Al aprovechar la similitud de productos puntos, el puntaje se calcula de forma diferente en función de si los vectores contienen valores flotantes o de bytes. En el primer caso, el puntaje se calcula de la misma manera que para la similitud del coseno empleando la fórmula (7) a continuación:
Sin embargo, cuando el vector se compone de valores de bytes, el puntaje se calcula de manera un poco diferente, como se muestra en la fórmula (8) a continuación, donde es el número de dimensiones del vector:
Además, una restricción para obtener puntajes precisos es que todos los vectores, incluido el vector de consulta, deben tener la misma longitud, pero no necesariamente 1.
Máxima similitud interna del producto
Desde la versión 8.11, hay una nueva función de similitud que está menos restringida que la similitud del producto punto, ya que no es necesario normalizar los vectores. La razón principal de esto se explica en detalle en el siguiente artículo, pero para resumirlo muy brevemente, ciertos conjuntos de datos no están muy bien adaptados a tener sus vectores estandarizados (por ejemplo, incrustaciones coherentes) y hacerlo puede causar problemas de relevancia.
La fórmula para calcular la similitud máxima del producto interno es exactamente la misma que la del producto punto (6). Lo que cambia es la forma en que se calcula el puntaje escalando la similitud máxima del producto interno empleando una función por partes cuya fórmula depende de si la similitud es positiva o negativa, como se muestra en la fórmula (9) a continuación:
Lo que hace esta función por partes es que escala todos los valores negativos de similitud del producto interno máximo en el intervalo y todos los valores positivos en el intervalo .
En resumen
Fue un gran viaje, matemáticamente hablando, pero aquí hay algunas conclusiones que pueden resultarle útiles.
La función de similitud que puede usar, en última instancia, depende de si sus incrustaciones vectoriales están normalizadas o no. Si sus vectores ya están estandarizados o si su conjunto de datos es independiente de la normalización de vectores (es decir, la relevancia no se verá afectada), puede continuar y normalizar sus vectores y usar la similitud de producto punto, ya que es mucho más rápido de calcular que el de coseno ya que no es necesario calcular la longitud de cada vector. Al comparar millones de vectores, esos cálculos pueden sumar bastante.
Si los vectores no están estandarizados, tiene dos opciones:
- Use la similitud de coseno si normalizar sus vectores no es una opción
- use la nueva similitud de producto interno máximo si desea que la magnitud de sus vectores contribuya al puntaje porque tienen significado (por ejemplo, incrustaciones coherentes)
En este punto, calcular la distancia o similitud entre las incrustaciones vectoriales y cómo derivar sus puntajes debería tener sentido para usted. Esperamos que este artículo le resultó útil.
Preguntas frecuentes
¿Qué mide la similitud del coseno?
La similitud del coseno mide el ángulo relativo entre dos vectores, es decir, si ambos apuntan aproximadamente en la misma dirección.
¿Cómo se mide la distancia L1?
La distancia L1 se mide sumando la diferencia absoluta por pares de todos sus elementos.
¿Cómo se mide la distancia L2?
La distancia L2, también llamada distancia euclidiana, de dos vectores se mide sumando primero el cuadrado de la diferencia por pares de todos sus elementos y luego tomando la raíz cuadrada del resultado.
¿Cuál es la diferencia entre la distancia L1 y L2?
La diferencia entre la distancia L1 y L2 se reduce a cómo mides dos vectores. La distancia L1 se mide sumando la diferencia absoluta por pares de todos sus elementos. Por otro lado, la distancia L2 se mide primero sumando el cuadrado de la diferencia por pares de todos sus elementos y luego tomando la raíz cuadrada del resultado.
¿Cuál es la diferencia entre la similitud del coseno y la distancia del coseno?
La similitud coseno mide el ángulo relativo de dos vectores, es decir, si ambos apuntan aproximadamente en la misma dirección. Por otro lado, la distancia coseno mide cuán diferentes son sus direcciones.
¿Cuál es la diferencia entre la similitud entre producto escalar y coseno?
El producto escalar mide tanto la longitud como la alineación de los vectores, mientras que la similitud coseno mide solo cuán alineadas están sus direcciones, ignorando la longitud.
¿Cuándo deberías usar la similitud entre producto escalar y coseno?
Si f tus vectores están estandarizados (o pueden normalizar sin afectar la relevancia), usa la similitud del producto escalar — es más rápido porque no necesitas calcular longitudes de vectores. Si tus vectores no están estandarizados, usa similitud coseno cuando solo te importa la dirección, o producto escalar si la magnitud vectorial tiene significado y debería influir en el puntaje.
¿Cómo eliges la métrica de distancia adecuada para la búsqueda vectorial?
Elige una métrica de distancia basada en tus vectores y en lo que importa para tu búsqueda: usa L1 o L2 para medir diferencias absolutas, similitud coseno si solo importa la dirección, producto escalar si tanto dirección como magnitud importan (y los vectores están estandarizados), o producto interno máximo si los vectores no están estandarizados pero la magnitud debería influir en la relevancia.
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.