De busca vetorial a poderosas APIs REST, o Elasticsearch oferece aos desenvolvedores o kit de ferramentas de busca mais completo. Confira nossos notebooks de amostra no repositório Elasticsearch Labs para experimentar algo novo. Você também pode começar uma avaliação gratuita ou executar o Elasticsearch localmente hoje mesmo.
Quando surge a necessidade de pesquisar texto livre e Ctrl+F / Cmd+F não são mais suficientes, usar um mecanismo de busca lexical geralmente é a próxima escolha lógica que vem à mente. Os mecanismos de busca lexical são excelentes em analisar e tokenizar o texto a ser pesquisado em termos que podem ser correspondidos no momento da pesquisa, mas geralmente falham quando se trata de entender e dar sentido ao verdadeiro significado do texto que está sendo indexado e pesquisado.
É exatamente aí que os mecanismos de busca de vetores brilham. Eles podem indexar o mesmo texto de forma que ele possa ser pesquisado com base no significado que ele representa e em suas relações com outros conceitos que tenham significado semelhante ou relacionado.
Neste blog, abordaremos brevemente como os vetores são um ótimo conceito matemático para transmitir o significado do texto. Em seguida, nos aprofundaremos nas diferentes técnicas de similaridade suportadas pelo Elasticsearch quando se trata de pesquisar vetores vizinhos, ou seja, pesquisar vetores com significado semelhante, e como pontuá-los.
O que são embeddings vetoriais?
Este artigo não se aprofunda nas complexidades das incorporações de vetores. Se você quiser explorar mais esse tópico ou precisar de uma introdução antes de continuar, recomendamos conferir o guia a seguir.
Em poucas palavras, os embeddings vetoriais são obtidos por meio de um processo de aprendizado de máquina (por exemplo, redes neurais de aprendizado profundo) que transformam qualquer tipo de dado de entrada não estruturado (por exemplo, texto bruto, imagem, vídeo, som, etc.) em dados numéricos que carregam seu significado e relacionamentos. Diferentes tipos de dados não estruturados exigem diferentes tipos de modelos de aprendizado de máquina que foram treinados para "entender" cada tipo de dado.
Cada vetor localiza um dado específico como um ponto em um espaço multidimensional e essa localização representa um conjunto de características que o modelo usa para caracterizar os dados. O número de dimensões depende do modelo de aprendizado de máquina, mas geralmente varia de algumas centenas a alguns milhares. Por exemplo, os modelos OpenAI Embeddings possuem 1536 dimensões, enquanto os modelos Cohere Embeddings podem variar de 382 a 4096 dimensões. O tipo de campo dense_vector do Elasticsearch suporta até 4.096 dimensões na versão mais recente.
O verdadeiro feito das incorporações vetoriais é que os pontos de dados que compartilham significados semelhantes ficam próximos no espaço. Outro aspecto interessante é que as incorporações vetoriais também ajudam a capturar relacionamentos entre pontos de dados.
Como comparamos vetores?
Sabendo que dados não estruturados são fatiados e divididos por modelos de aprendizado de máquina em incorporações vetoriais que capturam a similaridade dos dados ao longo de um grande número de dimensões, agora precisamos entender como funciona a correspondência desses vetores. Acontece que a resposta é bem simples.
Incorporações de vetores que estão próximas umas das outras representam partes de dados semanticamente semelhantes . Então, quando consultamos um banco de dados vetorial, a entrada da pesquisa (imagem, texto, etc.) é primeiro transformada em embeddings vetoriais usando o mesmo modelo de aprendizado de máquina que foi usado para indexar todos os dados não estruturados, e o objetivo final é encontrar os vetores vizinhos mais próximos daquele vetor de consulta. Portanto, tudo o que precisamos fazer é descobrir como medir a "distância" ou "similaridade" entre o vetor de consulta e todos os vetores existentes indexados no banco de dados - é simples assim.
Distância, similaridade e pontuação
Felizmente para nós, medir a distância ou similaridade entre dois vetores é um problema fácil de resolver graças à aritmética vetorial. Então, vamos dar uma olhada nas funções de distância e similaridade mais populares suportadas pelo Elasticsearch. Atenção, matemática à frente!
Antes de começarmos, vamos dar uma olhada rápida na pontuação. Na verdade, o Lucene só permite que as pontuações sejam positivas. Todas as funções de distância e similaridade que apresentaremos em breve fornecem uma medida de quão próximos ou similares dois vetores são, mas esses números brutos raramente são adequados para serem usados como pontuação, pois podem ser negativos. Por esse motivo, a pontuação final precisa ser derivada do valor de distância ou similaridade de uma forma que garanta que a pontuação será positiva e uma pontuação maior corresponde a uma classificação mais alta (ou seja, para vetores mais próximos).
Distância L1
A distância L1, também chamada de distância de Manhattan, de dois vetores e é medida pela soma da diferença absoluta em pares de todos os seus elementos. Obviamente, quanto menor a distância , mais próximos os dois vetores estarão. A fórmula da distância L1 (1) é bastante simples, como pode ser visto abaixo:
Visualmente, a distância L1 pode ser ilustrada conforme mostrado na imagem abaixo (em vermelho):

O cálculo da distância L1 dos dois vetores a seguir e resultaria em
Importante: Vale ressaltar que a função de distância L1 só é suportada para pesquisa vetorial exata (também conhecida como pesquisa de força bruta) usando a consulta DSL script_score , mas não para pesquisa kNN aproximada usando a opção de pesquisa knnou a consulta DSL knn .
Distância L2
A distância L2, também chamada de distância euclidiana, de dois vetores e é medida primeiro somando o quadrado da diferença de pares de todos os seus elementos e depois tirando a raiz quadrada do resultado. É basicamente o caminho mais curto entre dois pontos. Similarmente a L1, quanto menor a distância , mais próximos os dois vetores estão:
A distância L2 é mostrada em vermelho na imagem abaixo:

Vamos reutilizar os mesmos dois vetores de amostra e que usamos para a distância , e agora podemos calcular a distância como .
Em termos de pontuação, quanto menor a distância entre dois vetores, mais próximos (ou seja, mais semelhantes) eles são. Então, para derivar uma pontuação, precisamos inverter a medida de distância, de modo que a menor distância produza a maior pontuação. A maneira como a pontuação é calculada ao usar a distância L2 é mostrada na fórmula (3) abaixo:
Reutilizando os vetores de amostra do exemplo anterior, sua pontuação seria . Dois vetores muito próximos um do outro tenderão a uma pontuação de 1, enquanto a pontuação de dois vetores muito distantes um do outro tenderá a 0.
Concluindo as funções de distância L1 e L2, uma boa analogia para compará-las é pensar em A e B como dois edifícios em Manhattan, Nova York. Um táxi indo de A para B teria que dirigir pelo caminho L1 (ruas e avenidas), enquanto um pássaro provavelmente usaria o caminho L2 (linha reta).
Similaridade de cosseno
Ao contrário de L1 e L2, a similaridade do cosseno não mede a distância entre dois vetores e , mas sim seu ângulo relativo, ou seja, se ambos estão apontando aproximadamente na mesma direção. Quanto maior a similaridade , menor o ângulo entre os dois vetores e, portanto, mais "próximos" eles são e mais "semelhantes" são seus significados transmitidos.
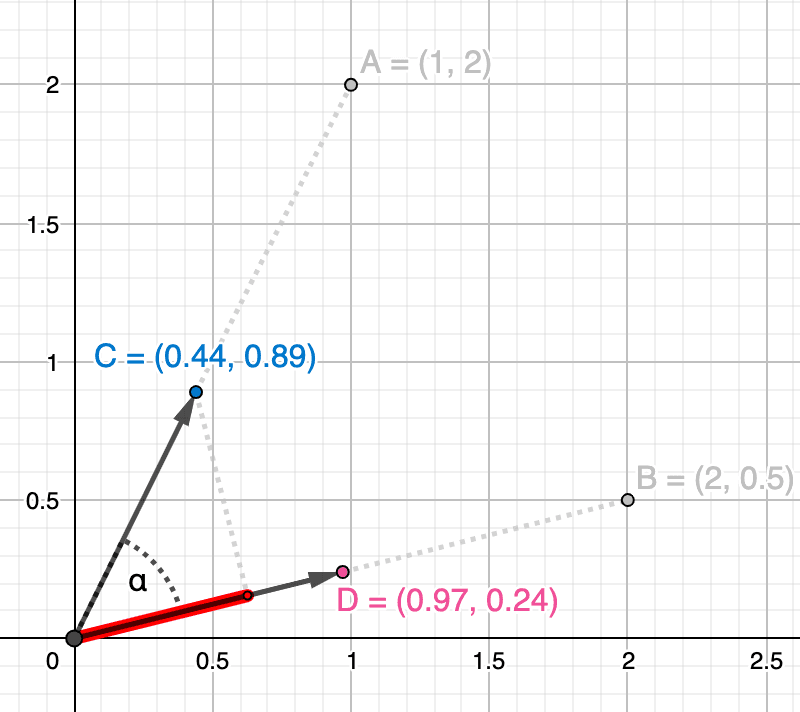
Para ilustrar isso, vamos pensar em duas pessoas em uma área selvagem olhando em direções diferentes. Na figura abaixo, a pessoa de azul olha na direção simbolizada pelo vetor e a pessoa de vermelho na direção do vetor . Quanto mais eles direcionarem sua visão na mesma direção (ou seja, quanto mais próximos seus vetores estiverem), mais seu campo de visão simbolizado pelas áreas azul e vermelha se sobreporá. O quanto seus campos de visão se sobrepõem é a similaridade de seus cossenos. Entretanto, observe que a pessoa B parece mais distante do que a pessoa A (ou seja, o vetor é maior). A pessoa B pode estar olhando para uma montanha distante no horizonte, enquanto a pessoa A pode estar olhando para uma árvore próxima. Para similaridade de cosseno, isso não desempenha nenhum papel, pois é apenas uma questão de ângulo.

Agora vamos calcular essa similaridade de cosseno. A fórmula (4) é bastante simples, onde o numerador consiste no produto escalar de ambos os vetores e o denominador contém o produto de sua magnitude (ou seja, seu comprimento):
A similaridade do cosseno entre e é mostrada na imagem abaixo como uma medida do ângulo entre eles (em vermelho):

Vamos fazer um rápido desvio para explicar o que esses valores de similaridade de cosseno significam concretamente. Como pode ser visto na imagem abaixo representando a função cosseno, os valores sempre oscilam no intervalo .
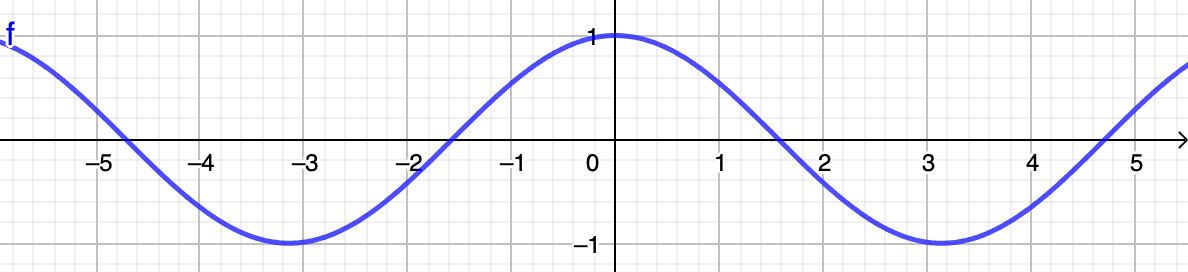
Lembre-se de que, para que dois vetores sejam considerados semelhantes, seu ângulo deve ser o mais agudo possível, idealmente próximo de um ângulo , o que se resumiria a uma semelhança perfeita de . Em outras palavras, quando os vetores são...
- ...próximos um do outro, o cosseno do seu ângulo se aproxima (ou seja, próximo de )

- ...não relacionados, o cosseno do seu ângulo se aproxima (ou seja, próximo de )

- ...oposto, o cosseno do seu ângulo se aproxima (ou seja, próximo de )

Agora que sabemos como calcular a similaridade do cosseno entre dois vetores e temos uma boa ideia de como interpretar o valor resultante, podemos reutilizar os mesmos vetores de amostra e e calcular sua similaridade do cosseno usando a fórmula (4) que vimos anteriormente.
Obtemos uma similaridade de cosseno de , que é mais próxima de do que de , o que significa que os dois vetores são um tanto similares, ou seja, não são perfeitamente similares, mas também não são completamente independentes e certamente não têm significados opostos.
Para derivar uma pontuação positiva de qualquer valor de similaridade de cosseno, precisamos usar a seguinte fórmula (5), que transforma os valores de similaridade de cosseno que oscilam dentro do intervalo em pontuações no intervalo :
A pontuação para os vetores de amostra e seria: .
Similaridade do produto escalar
Uma desvantagem da similaridade de cosseno é que ela leva em conta apenas o ângulo entre dois vetores, mas não sua magnitude, o que significa que se dois vetores apontam aproximadamente na mesma direção, mas um é muito maior que o outro, ambos ainda serão considerados semelhantes. A similaridade do produto escalar, também chamada de similaridade escalar ou de produto interno, melhora isso ao levar em conta tanto o ângulo quanto a magnitude dos vetores, o que fornece uma métrica de similaridade mais precisa. Para tornar a magnitude dos vetores irrelevante, a similaridade do produto escalar exige que os vetores sejam normalizados primeiro, de modo que, em última análise, estamos apenas comparando vetores de comprimento unitário 1.
Vamos tentar ilustrar isso novamente com as mesmas duas pessoas de antes, mas, desta vez, as colocamos no meio de uma sala circular, de modo que seu alcance de visão seja exatamente o mesmo (ou seja, o raio da sala). De forma semelhante à similaridade do cosseno, quanto mais eles se voltam na mesma direção (ou seja, quanto mais próximos seus vetores ficam), mais seus campos de visão se sobrepõem. Entretanto, ao contrário da similaridade de cosseno, ambos os vetores têm o mesmo comprimento e ambas as áreas têm a mesma superfície, o que significa que as duas pessoas olham exatamente para a mesma imagem localizada à mesma distância. O quão bem essas duas áreas se sobrepõem denota sua similaridade de produto escalar.

Antes de introduzir a fórmula de similaridade do produto escalar, vamos ver rapidamente como um vetor pode ser normalizado. É bem simples e pode ser feito em duas etapas triviais:
- calcular a magnitude do vetor
- divida cada componente pela magnitude obtida em 1.
Como exemplo, vamos pegar o vetor . Podemos calcular sua magnitude como vimos anteriormente ao revisar a similaridade do cosseno, ou seja, . Então, dividindo cada componente do vetor por sua magnitude, obtemos o seguinte vetor normalizado :
Passar pelo mesmo processo para o segundo vetor produziria o seguinte vetor normalizado :
Para derivar a fórmula de similaridade do produto escalar, podemos calcular a similaridade do cosseno entre nossos vetores normalizados e usando a fórmula (4), conforme mostrado abaixo:
E como a magnitude de ambos os vetores normalizados é agora , a fórmula de similaridade do produto escalar (6) simplesmente se torna... você adivinhou, um produto escalar de ambos os vetores normalizados:
Na imagem abaixo, mostramos os vetores normalizados e e podemos ilustrar sua similaridade de produto escalar como a projeção de um vetor sobre o outro (em vermelho).
Usando nossa nova fórmula (6), podemos calcular a similaridade do produto escalar de nossos dois vetores normalizados, o que, sem surpresa, produz exatamente o mesmo valor de similaridade que o do cosseno:
Ao aproveitar a similaridade do produto escalar, a pontuação é calculada de forma diferente dependendo se os vetores contêm valores flutuantes ou de bytes. No primeiro caso, a pontuação é calculada da mesma forma que para a similaridade do cosseno usando a fórmula (7) abaixo:
Entretanto, quando o vetor é composto de valores de bytes, a pontuação é calculada de forma um pouco diferente, conforme mostrado na fórmula (8) abaixo, onde é o número de dimensões do vetor:
Além disso, uma restrição para produzir pontuações precisas é que todos os vetores, incluindo o vetor de consulta, devem ter o mesmo comprimento, mas não necessariamente 1.
Similaridade máxima do produto interno
Desde a versão 8.11, há uma nova função de similaridade que é menos restrita do que a similaridade do produto escalar, pois os vetores não precisam ser normalizados. O principal motivo para isso é explicado detalhadamente no artigo a seguir, mas, para resumir muito brevemente, certos conjuntos de dados não são muito bem adaptados para ter seus vetores normalizados (por exemplo, incorporações Cohere) e isso pode causar problemas de relevância.
A fórmula para calcular a similaridade máxima do produto interno é exatamente a mesma que a do produto escalar (6). O que muda é a maneira como a pontuação é calculada, escalando a similaridade máxima do produto interno usando uma função por partes cuja fórmula depende se a similaridade é positiva ou negativa, conforme mostrado na fórmula (9) abaixo:
O que essa função por partes faz é dimensionar todos os valores negativos de similaridade do produto interno máximo no intervalo e todos os valores positivos no intervalo .
Resumindo
Foi uma jornada e tanto, matematicamente falando, mas aqui estão algumas lições que você pode achar úteis.
A função de similaridade que você pode usar depende, em última análise, se seus embeddings vetoriais são normalizados ou não. Se seus vetores já estiverem normalizados ou se seu conjunto de dados for independente da normalização vetorial (ou seja, a relevância não será afetada), você pode prosseguir e normalizar seus vetores e usar a similaridade do produto escalar, pois é muito mais rápido de calcular do que o cosseno, pois não há necessidade de calcular o comprimento de cada vetor. Ao comparar milhões de vetores, esses cálculos podem somar bastante.
Se seus vetores não estiverem normalizados, você tem duas opções:
- use similaridade de cosseno se normalizar seus vetores não for uma opção
- use a nova similaridade máxima do produto interno se quiser que a magnitude dos seus vetores contribua para a pontuação porque eles carregam significado (por exemplo, incorporações Cohere)
Neste ponto, calcular a distância ou similaridade entre incorporações vetoriais e como derivar suas pontuações deve fazer sentido para você. Esperamos que você tenha achado este artigo útil.
Perguntas frequentes
O que a similaridade de cosseno mede?
A similaridade de cosseno mede o ângulo relativo entre dois vetores, ou seja, se ambos estão apontando aproximadamente na mesma direção.
Como é medida a distância L1?
A distância L1 é medida somando-se a diferença absoluta entre todos os seus elementos, par a par.
Como a distância L2 é medida?
A distância L2, também chamada de distância euclidiana, de dois vetores é medida primeiro somando o quadrado da diferença entre pares de todos os seus elementos e depois tirando a raiz quadrada do resultado.
Qual a diferença entre as distâncias L1 e L2?
A diferença entre a distância L1 e a distância L2 reside na forma como se mede a distância entre dois vetores. A distância L1 é medida somando-se a diferença absoluta entre todos os seus elementos, par a par. Por outro lado, a distância L2 é medida somando-se primeiro o quadrado da diferença entre todos os seus elementos e, em seguida, extraindo-se a raiz quadrada do resultado.
Qual a diferença entre similaridade de cosseno e distância de cosseno?
A similaridade de cosseno mede o ângulo relativo entre dois vetores, ou seja, se ambos apontam aproximadamente na mesma direção. Por outro lado, a distância cosseno mede o quão diferentes são suas direções.
Qual a diferença entre produto escalar e similaridade de cosseno?
O produto escalar mede tanto o comprimento quanto o alinhamento dos vetores, enquanto a similaridade de cosseno mede apenas o grau de alinhamento de suas direções, ignorando o comprimento.
Quando usar o produto escalar em vez da similaridade de cosseno?
Se seus vetores estiverem normalizados (ou puderem ser normalizados sem afetar a relevância), use a similaridade do produto escalar — é mais rápido porque você não precisa calcular os comprimentos dos vetores. Se seus vetores não estiverem normalizados, use a similaridade de cosseno quando você se importa apenas com a direção, ou o produto escalar se a magnitude do vetor for significativa e deva influenciar a pontuação.
Como escolher a métrica de distância correta para busca vetorial?
Escolha uma métrica de distância com base nos seus vetores e no que é importante para a sua pesquisa: use L1 ou L2 para medir diferenças absolutas, similaridade de cosseno se apenas a direção importa, produto escalar se tanto a direção quanto a magnitude importam (e os vetores estão normalizados), ou produto interno máximo se os vetores não estão normalizados, mas a magnitude deve influenciar a relevância.
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.