De la recherche vectorielle aux API REST puissantes, Elasticsearch met à disposition des développeurs la boîte à outils de recherche la plus complète. Explorez nos notebooks d’exemple dans le dépôt Elasticsearch Labs pour tester de nouvelles approches. Vous pouvez également démarrer un essai gratuit ou exécuter Elasticsearch en local dès aujourd’hui.
Lorsque le besoin de rechercher un texte libre se fait sentir et que les touches Ctrl+F / Cmd+F ne suffisent plus, l'utilisation d'un moteur de recherche lexicale est généralement le choix logique qui vient à l'esprit. Les moteurs de recherche lexicale excellent dans l'analyse et la symbolisation du texte à rechercher en termes qui peuvent être mis en correspondance au moment de la recherche, mais ils ne parviennent généralement pas à comprendre et à donner un sens au texte indexé et recherché.
C'est précisément là que les moteurs de recherche vectoriels brillent. Ils peuvent indexer le même texte de manière à ce qu'il puisse être recherché sur la base du sens qu'il représente et de ses relations avec d'autres concepts ayant un sens similaire ou apparenté.
Dans ce blog, nous aborderons brièvement la façon dont les vecteurs sont un concept mathématique idéal pour transmettre le sens d'un texte. Nous approfondirons ensuite les différentes techniques de similarité prises en charge par Elasticsearch lorsqu'il s'agit de rechercher des vecteurs voisins, c'est-à-dire de rechercher des vecteurs ayant une signification similaire, et la manière de les classer.
Que sont les plongements vectoriels ?
Cet article n'aborde pas en profondeur les subtilités des encastrements vectoriels. Si vous souhaitez approfondir ce sujet ou si vous avez besoin d'une introduction avant de poursuivre, nous vous recommandons de consulter le guide suivant.
En bref, les encastrements vectoriels sont obtenus par un processus d'apprentissage automatique (par ex. réseaux neuronaux d'apprentissage profond) qui transforme tout type de données d'entrée non structurées (texte brut, image, vidéo, son, etc.) en données numériques porteuses de sens et de relations. Les différents types de données non structurées nécessitent différents types de modèles d'apprentissage automatique qui ont été formés pour "comprendre" chaque type de données.
Chaque vecteur localise un élément spécifique des données en tant que point dans un espace multidimensionnel et cette localisation représente un ensemble de caractéristiques que le modèle utilise pour caractériser les données. Le nombre de dimensions dépend du modèle d'apprentissage automatique, mais il varie généralement de quelques centaines à quelques milliers. Par exemple, les modèles OpenAI Embeddings peuvent se vanter d'avoir 1536 dimensions, tandis que les modèles Cohere Embeddings peuvent avoir entre 382 et 4096 dimensions. Le type de champ Elasticsearch dense_vector prend en charge jusqu'à 4096 dimensions depuis la dernière version.
La véritable prouesse des encastrements vectoriels réside dans le fait que les points de données qui partagent une signification similaire sont proches les uns des autres dans l'espace. Un autre aspect intéressant est que l'intégration vectorielle permet également de saisir les relations entre les points de données.
Comment comparer les vecteurs ?
Sachant que les données non structurées sont découpées en tranches par des modèles d'apprentissage automatique sous forme de vecteurs qui capturent la similarité des données selon un grand nombre de dimensions, nous devons maintenant comprendre comment fonctionne la mise en correspondance de ces vecteurs. Il s'avère que la réponse est assez simple.
Les vecteurs intégrés qui sont proches les uns des autres représentent des éléments de données sémantiquement similaires. Ainsi, lorsque nous interrogeons une base de données vectorielle, l'entrée de recherche (image, texte, etc.) est d'abord transformée en un vecteur intégré à l'aide du même modèle d'apprentissage automatique que celui utilisé pour l'indexation de toutes les données non structurées, et l'objectif final est de trouver les vecteurs voisins les plus proches de ce vecteur d'interrogation. Par conséquent, tout ce que nous avons à faire est de trouver comment mesurer la distance "" ou la similarité "" entre le vecteur de la requête et tous les vecteurs existants indexés dans la base de données - c'est aussi simple que cela.
Distance, similarité et notation
Heureusement pour nous, la mesure de la distance ou de la similarité entre deux vecteurs est un problème facile à résoudre grâce à l'arithmétique vectorielle. Examinons donc les fonctions de distance et de similarité les plus populaires prises en charge par Elasticsearch. Attention, mathématiques en perspective !
Avant d'entrer dans le vif du sujet, jetons un coup d'œil rapide au système de notation. En réalité, Lucene n'autorise que les scores positifs. Toutes les fonctions de distance et de similarité que nous présenterons prochainement donnent une mesure de la proximité ou de la similarité de deux vecteurs, mais ces chiffres bruts sont rarement adaptés à une utilisation en tant que score car ils peuvent être négatifs. C'est pourquoi la note finale doit être dérivée de la distance ou de la valeur de similarité de manière à ce que la note soit positive et qu'une note plus élevée corresponde à un meilleur classement (c'est-à-dire à des vecteurs plus proches).
Distance L1
La distance L1, également appelée distance de Manhattan, de deux vecteurs et est mesurée en additionnant la différence absolue par paire de tous leurs éléments. Il est évident que plus la distance est faible, plus les deux vecteurs sont proches. La formule de la distance L1 (1) est assez simple, comme on peut le voir ci-dessous :
Visuellement, la distance L1 peut être illustrée comme le montre l'image ci-dessous (en rouge) :

Le calcul de la distance L1 des deux vecteurs suivants : \vec {A} = \binom{1}{2}et \vec .
Important : il convient de noter que la fonction de distance L1 n'est prise en charge que pour la recherche vectorielle exacte (également appelée recherche par force brute) à l'aide de la script_score requête DSL, mais pas pour la knn recherche approximative kNN à l'aide de l' option de recherche ou de la knn requête DSL.
Distance L2
La distance L2, également appelée distance euclidienne, de deux vecteurs et est mesurée en additionnant d'abord le carré de la différence par paire de tous leurs éléments, puis en prenant la racine carrée du résultat. Il s'agit en fait du chemin le plus court entre deux points. Comme pour L1, plus la distance est faible, plus les deux vecteurs sont proches :
La distance L2 est indiquée en rouge dans l'image ci-dessous :

Réutilisons les deux mêmes vecteurs d'échantillonnage et que nous avons utilisés pour la distance , et nous pouvons maintenant calculer la distance comme \sqrt \approxeq 1,803.
En ce qui concerne la notation, plus la distance entre deux vecteurs est faible, plus ils sont proches (c'est-à-dire plus ils se ressemblent). Pour obtenir un score, nous devons donc inverser la mesure de la distance, de sorte que la distance la plus faible donne le score le plus élevé. La façon dont le score est calculé en utilisant la distance L2 est présentée dans la formule (3) ci-dessous :
En réutilisant les vecteurs d'échantillonnage de l'exemple précédent, leur score serait \frac 0,2352. Deux vecteurs très proches l'un de l'autre auront un score proche de 1, tandis que le score de deux vecteurs très éloignés l'un de l'autre tendra vers 0.
Pour conclure sur les fonctions de distance L1 et L2, une bonne analogie pour les comparer est de considérer A et B comme deux bâtiments à Manhattan, NYC. Un taxi se rendant de A à B devrait emprunter le chemin L1 (rues et avenues), tandis qu'un oiseau utiliserait probablement le chemin L2 (ligne droite).
Similitude du cosinus
Contrairement à L1 et L2, la similarité en cosinus ne mesure pas la distance entre deux vecteurs et , mais plutôt leur angle relatif, c'est-à-dire s'ils pointent tous deux à peu près dans la même direction. Plus la similarité est élevée, plus l'angle entre les deux vecteurs est faible et, par conséquent, plus "" ils sont proches et plus "" leur signification est similaire.
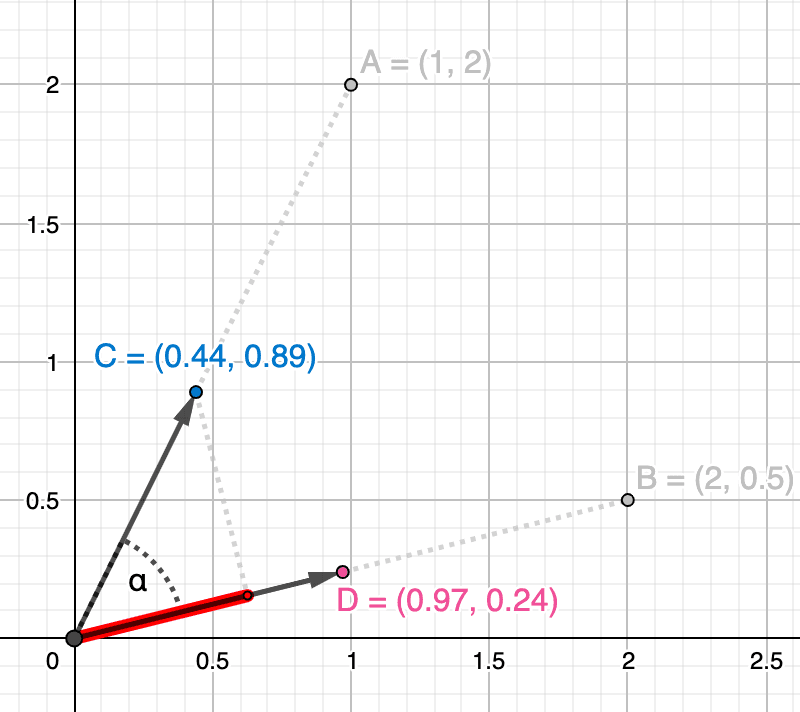
Pour illustrer cela, imaginons deux personnes dans la nature qui regardent dans des directions différentes. Dans la figure ci-dessous, la personne en bleu regarde dans la direction symbolisée par le vecteur et la personne en rouge dans la direction du vecteur . Plus ils orienteront leur regard dans la même direction (c'est-à-dire plus leurs vecteurs se rapprochent), plus leur champ de vision symbolisé par les zones bleues et rouges se chevauchera. Le degré de chevauchement de leur champ de vision correspond à leur similarité cosinusoïdale. Notez toutefois que la personne B regarde plus loin que la personne A (le vecteur est plus long). La personne B peut regarder une montagne au loin à l'horizon, tandis que la personne A peut regarder un arbre à proximité. Pour la similitude du cosinus, cela ne joue aucun rôle puisqu'il s'agit uniquement de l'angle.

Calculons maintenant la similitude en cosinus. La formule (4) est assez simple : le numérateur est le produit de points des deux vecteurs et le dénominateur est le produit de leur magnitude (c'est-à-dire de leur longueur) :
La similarité en cosinus entre et est représentée dans l'image ci-dessous comme une mesure de l'angle qui les sépare (en rouge) :

Faisons un petit détour pour expliquer ce que signifient concrètement ces valeurs de similitude cosinusoïdale. Comme le montre l'image ci-dessous représentant la fonction cosinus, les valeurs oscillent toujours dans l'intervalle
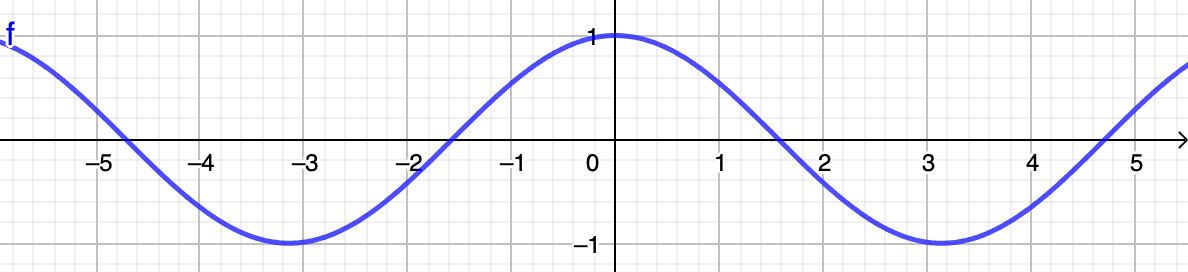
Rappelons que pour que deux vecteurs soient considérés comme similaires, leur angle doit être le plus aigu possible, idéalement proche de , ce qui revient à une similitude parfaite de En d'autres termes, lorsque les vecteurs sont...
- ...proches l'un de l'autre, le cosinus de leur angle est proche de (c'est-à-dire proche de )

- ...sans rapport, le cosinus de leur angle est proche de (c'est-à-dire proche de )

- ...opposé, le cosinus de leur angle est proche de (c'est-à-dire proche de )

Maintenant que nous savons comment calculer la similitude en cosinus entre deux vecteurs et que nous avons une bonne idée de la manière d'interpréter la valeur obtenue, nous pouvons réutiliser les mêmes vecteurs échantillons et et calculer leur similitude en cosinus à l'aide de la formule (4) que nous avons vue précédemment.
Nous obtenons un cosinus similaire de , qui est plus proche de que de . Cela signifie que les deux vecteurs sont quelque peu similaires, c'est-à-dire qu'ils ne sont pas parfaitement similaires, mais qu'ils ne sont pas non plus complètement sans rapport, et qu'ils n'ont certainement pas de signification opposée.
Pour obtenir un score positif à partir de n'importe quelle valeur de similarité en cosinus, nous devons utiliser la formule suivante (5), qui transforme les valeurs de similarité en cosinus oscillant dans l'intervalle en scores dans l'intervalle
Le score pour les vecteurs échantillons et serait donc : \frac 0.8253.
Similitude du produit de points
L'un des inconvénients de la similitude en cosinus est qu'elle ne prend en compte que l'angle entre deux vecteurs et non leur magnitude, ce qui signifie que si deux vecteurs pointent à peu près dans la même direction mais que l'un est beaucoup plus long que l'autre, les deux seront tout de même considérés comme similaires. La similarité du produit de points, également appelée similarité scalaire ou produit intérieur, améliore cette situation en tenant compte à la fois de l'angle et de la magnitude des vecteurs, ce qui permet d'obtenir une mesure de similarité plus précise. Pour que la magnitude des vecteurs n'ait pas d'importance, la similitude du produit de points exige que les vecteurs soient d'abord normalisés, de sorte que nous ne comparons finalement que des vecteurs de longueur unitaire 1.
Essayons à nouveau d'illustrer cela avec les deux mêmes personnes que précédemment, mais cette fois-ci, nous les plaçons au milieu d'une pièce circulaire, de sorte que leur portée visuelle soit exactement la même (c.-à-d. le rayon de la pièce). De la même manière que pour la similarité cosinus, plus ils tournent dans la même direction (c'est-à-dire plus leurs vecteurs se rapprochent), plus leur champ de vision se chevauche. Cependant, contrairement à la similitude de cosinus, les deux vecteurs ont la même longueur et les deux aires ont la même surface, ce qui signifie que les deux personnes regardent exactement la même image située à la même distance. Le degré de chevauchement de ces deux zones correspond à la similitude de leur produit de point.

Avant d'introduire la formule de similarité du produit de points, voyons rapidement comment un vecteur peut être normalisé. C'est assez simple et peut être réalisé en deux étapes triviales :
- calculer la magnitude du vecteur
- diviser chaque composante par la valeur obtenue en 1.
Prenons par exemple le vecteur \vec Nous pouvons calculer sa magnitude \Vert \Vert comme nous l'avons vu précédemment lors de l'examen de la similitude du cosinus, c'est-à-dire \sqrt . Ensuite, en divisant chaque composante du vecteur par sa magnitude, on obtient le vecteur normalisé suivant :
En procédant de la même manière pour le deuxième vecteur \vec :
Afin de dériver la formule de similarité du produit en points, nous pouvons calculer la similarité en cosinus entre nos vecteurs normalisés et en utilisant la formule (4), comme indiqué ci-dessous :
Et comme la magnitude des deux vecteurs normalisés est maintenant de , la formule de similitude du produit par points (6) devient simplement... vous l'avez deviné, un produit par points des deux vecteurs normalisés :
Dans l'image ci-dessous, nous montrons les vecteurs normalisés et et nous pouvons illustrer la similarité de leur produit de point comme la projection d'un vecteur sur l'autre (en rouge).
En utilisant notre nouvelle formule (6), nous pouvons calculer la similarité du produit de points de nos deux vecteurs normalisés, ce qui, sans surprise, donne exactement la même valeur de similarité que celle du cosinus :
Lorsque l'on utilise la similarité du produit de points, le score est calculé différemment selon que les vecteurs contiennent des valeurs flottantes ou des valeurs d'octets. Dans le premier cas, le score est calculé de la même manière que pour la similarité en cosinus en utilisant la formule (7) ci-dessous :
Toutefois, lorsque le vecteur est composé de valeurs d'octets, la notation est calculée un peu différemment, comme le montre la formule (8) ci-dessous, où est le nombre de dimensions du vecteur :
En outre, pour obtenir des résultats précis, il faut que tous les vecteurs, y compris le vecteur d'interrogation, aient la même longueur, mais pas nécessairement la même longueur (1).
Similitude maximale du produit intérieur
Depuis la version 8.11, il existe une nouvelle fonction de similarité qui est moins contraignante que la similarité par produit de points, dans la mesure où les vecteurs n'ont pas besoin d'être normalisés. La raison principale est expliquée en détail dans l'article suivant, mais pour résumer très brièvement, certains ensembles de données ne sont pas très bien adaptés à la normalisation de leurs vecteurs (par exemple, Cohere embeddings) et cette normalisation peut entraîner des problèmes de pertinence.
La formule de calcul de la similarité maximale du produit intérieur est exactement la même que celle du produit de points (6). Ce qui change, c'est la manière dont le score est calculé en mettant à l'échelle la similarité maximale du produit intérieur à l'aide d'une fonction par morceaux dont la formule dépend du fait que la similarité est positive ou négative, comme le montre la formule (9) ci-dessous :
Cette fonction par morceaux met à l'échelle toutes les valeurs négatives du produit intérieur maximal dans l'intervalle et toutes les valeurs positives dans l'intervalle
En résumé
C'était un sacré parcours, mathématiquement parlant, mais voici quelques enseignements qui pourraient vous être utiles.
La fonction de similarité que vous pouvez utiliser dépend en fin de compte de la normalisation ou non de vos encastrements vectoriels. Si vos vecteurs sont déjà normalisés ou si votre ensemble de données ne dépend pas de la normalisation des vecteurs (c'est-à-dire que la pertinence n'en souffrira pas), vous pouvez aller de l'avant et normaliser vos vecteurs et utiliser la similarité par produit de points, car elle est beaucoup plus rapide à calculer que celle par cosinus, puisqu'il n'est pas nécessaire de calculer la longueur de chaque vecteur. Lorsque l'on compare des millions de vecteurs, ces calculs peuvent s'avérer très lourds.
Si vos vecteurs ne sont pas normalisés, vous avez deux possibilités :
- utiliser la similarité en cosinus si la normalisation des vecteurs n'est pas possible
- utiliser le nouveau produit intérieur maximal de similarité si vous souhaitez que la magnitude de vos vecteurs contribue à la notation parce qu'elle est porteuse de sens (par exemple, Cohere embeddings).
À ce stade, le calcul de la distance ou de la similarité entre les intégrations vectorielles et la manière de dériver leurs scores devraient vous sembler évidents. Nous espérons que cet article vous a été utile.
Questions fréquentes
Quelle est la mesure de la similarité en cosinus ?
La similitude cosinusienne mesure l'angle relatif entre deux vecteurs, c'est-à-dire s'ils pointent tous deux à peu près dans la même direction.
Comment la distance L1 est-elle mesurée ?
La distance L1 est mesurée en additionnant la différence absolue par paire de tous leurs éléments.
Comment la distance L2 est-elle mesurée ?
La distance L2, également appelée distance euclidienne, de deux vecteurs est mesurée en additionnant d'abord le carré de la différence par paire de tous leurs éléments, puis en prenant la racine carrée du résultat.
Quelle est la différence entre les distances L1 et L2 ?
La différence entre les distances L1 et L2 tient à la façon dont vous mesurez deux vecteurs. La distance L1 est mesurée en additionnant la différence absolue par paire de tous leurs éléments. En revanche, la distance L2 est mesurée en additionnant d'abord le carré de la différence par paire de tous les éléments, puis en prenant la racine carrée du résultat.
Quelle est la différence entre la similitude et la distance en cosinus ?
La similitude cosinusienne mesure l'angle relatif de deux vecteurs, c'est-à-dire s'ils pointent tous deux à peu près dans la même direction. En revanche, la distance en cosinus mesure la différence entre leurs directions.
Quelle est la différence entre le produit en points et la similitude en cosinus ?
Le produit des points mesure à la fois la longueur et l'alignement des vecteurs, tandis que la similarité en cosinus mesure uniquement l'alignement de leurs directions, sans tenir compte de la longueur.
Quand devez-vous utiliser le produit en points ou la similitude en cosinus ?
Si vos vecteurs sont normalisés (ou peuvent être normalisés sans affecter la pertinence), utilisez la similitude par produit de points - c'est plus rapide car vous n'avez pas besoin de calculer la longueur des vecteurs. Si vos vecteurs ne sont pas normalisés, utilisez la similitude en cosinus si vous ne vous intéressez qu'à la direction, ou le produit en points si la magnitude du vecteur a une signification et doit influencer le score.
Comment choisir la bonne métrique de distance pour la recherche vectorielle ?
Choisissez une mesure de distance en fonction de vos vecteurs et de ce qui importe pour votre recherche : utilisez L1 ou L2 pour mesurer les différences absolues, la similarité en cosinus si seule la direction importe, le produit en points si la direction et la magnitude importent (et si les vecteurs sont normalisés), ou le produit intérieur maximal si les vecteurs ne sont pas normalisés mais que la magnitude devrait influer sur la pertinence.
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.