ベクトル検索からパワフルなREST APIまで、Elasticsearchは最も広範な検索ツールキットを開発者に提供します。Elasticsearch Labsリポジトリのサンプルノートで新しいことに挑戦してみましょう。また、無料トライアルを始めるか、ローカルでElasticsearchを実行することもできます。
フリーテキストを検索する必要が生じ、Ctrl+F / Cmd+F では不十分になった場合、通常、次に思い浮かぶ論理的な選択肢は語彙検索エンジンの使用です。語彙検索エンジンは、検索対象のテキストを分析し、検索時に一致可能な用語にトークン化することに優れていますが、インデックス付けおよび検索対象のテキストの真の意味を理解し、意味を成すという点では、通常、不十分です。
まさにここでベクター検索エンジンが活躍します。同じテキストをインデックス化して、そのテキストが表す意味と、類似または関連する意味を持つ他の概念との関係の両方に基づいて検索できるようにすることができます。
このブログでは、ベクトルがテキストの意味を伝えるための優れた数学的概念である理由について簡単に触れたいと思います。次に、近隣ベクトルの検索、つまり類似の意味を持つベクトルの検索と、それらのスコア付けの方法について、Elasticsearch がサポートするさまざまな類似性テクニックについて詳しく説明します。
ベクトル埋め込みとは何ですか?
この記事では、ベクトル埋め込みの複雑な部分については詳しく説明しません。このトピックをさらに詳しく調べたい場合、または続行する前に入門書が必要な場合は、次のガイドを確認することをお勧めします。
簡単に言えば、ベクトル埋め込みは機械学習プロセスを通じて得られる(例えばあらゆる種類の非構造化入力データ (生のテキスト、画像、ビデオ、音声など) を、意味と関係性を持つ数値データに変換する AI (人工知能) です。非構造化データの種類によって、各データの種類を「理解」するようにトレーニングされたさまざまな種類の機械学習モデルが必要です。
各ベクトルは、特定のデータ部分を多次元空間内の点として配置し、その位置はモデルがデータを特徴付けるために使用する一連の機能を表します。次元の数は機械学習モデルによって異なりますが、通常は数百から数千の範囲です。たとえば、 OpenAI Embeddings モデルは1536 次元を誇りますが、 Cohere Embeddings モデルは382 から 4096 次元の範囲になります。Elasticsearch の dense_vector フィールド タイプは、最新リリース時点で最大 4096 次元をサポートします。
ベクトル埋め込みの本当の特徴は、同様の意味を共有するデータ ポイントが空間内で互いに接近していることです。もう 1 つの興味深い点は、ベクトル埋め込みがデータ ポイント間の関係を捉えるのにも役立つことです。
ベクトルをどのように比較するのでしょうか?
非構造化データは機械学習モデルによって、多数の次元に沿ったデータの類似性を捉えるベクトル埋め込みに細分化されることがわかったので、次にそれらのベクトルのマッチングがどのように機能するかを理解する必要があります。答えは非常に簡単であることがわかりました。
互いに近いベクトル埋め込みは、意味的に類似したデータ部分を表します。したがって、ベクトル データベースをクエリする場合、検索入力 (画像、テキストなど) は、すべての非構造化データのインデックス作成に使用されたのと同じ機械学習モデルを使用して、まずベクトル埋め込みに変換され、最終的な目標はそのクエリ ベクトルに最も近い隣接ベクトルを見つけることです。したがって、必要なのは、クエリ ベクトルと、データベースにインデックスが付けられた既存のすべてのベクトルとの間の「距離」または「類似性」を測定する方法を見つけることだけです。とても簡単です。
距離、類似性、スコアリング
幸いなことに、ベクトル演算のおかげで、2 つのベクトル間の距離または類似性を測定することは簡単に解決できる問題です。それでは、Elasticsearch でサポートされている最も人気のある距離と類似度の関数を見てみましょう。警告、この先は数学です!
始める前に、スコアリングについて簡単に見てみましょう。実際のところ、Lucene ではスコアは正の値のみが許可されます。これから紹介するすべての距離関数と類似度関数は、2 つのベクトルがどれだけ近いか、または類似しているかの尺度を生成しますが、それらの生の数値は負になる可能性があるため、スコアとして使用するのに適することはほとんどありません。このため、最終スコアは、スコアが正になり、スコアが大きいほどランキングが高くなる(つまり、ベクトルが近い)ように、距離または類似度の値から導き出す必要があります。
L1距離
2 つのベクトルとの L1 距離 (マンハッタン距離とも呼ばれます) は、それらのすべての要素のペアワイズ絶対差を合計することによって測定されます。明らかに、距離が小さいほど、2つのベクトルは近くなります。L1距離の式(1)は、以下に示すように非常に単純です。
視覚的に、L1 距離は以下の図 (赤) のように表すことができます。

次の2つのベクトルとのL1距離を計算するととなる。
重要: L1 距離関数は、script_score DSL クエリを使用した 正確なベクトル検索(別名、ブルート フォース検索) でのみサポートされ、knn 検索オプション またはknn DSL クエリ を使用した 近似 kNN 検索 ではサポートされないことに注意してください。
L2距離
2 つのベクトルとの L2 距離 (ユークリッド距離とも呼ばれます) は、まずそれらのすべての要素のペアワイズ差の 2 乗を合計し、次にその結果の平方根をとることによって測定されます。基本的には 2 点間の最短経路です。L1と同様に、距離が小さいほど、2つのベクトルは近くなります。
L2 距離は、下の画像で赤で示されています。

距離に使用したのと同じ 2 つのサンプル ベクトル と 距離を として計算できるようになります。
スコアリングに関しては、2 つのベクトル間の距離が小さいほど、それらのベクトルは近い (つまり、類似している) と言えます。したがって、スコアを導き出すには、距離の測定を逆転させて、最小の距離で最高のスコアが得られるようにする必要があります。L2距離を用いた場合のスコアの計算方法は、以下の式(3)のようになります。
前の例のサンプルベクトルを再利用すると、スコアはになります。互いに非常に近い 2 つのベクトルのスコアは 1 に近づきますが、互いに非常に離れた 2 つのベクトルのスコアは 0 に近づく傾向があります。
L1 距離関数と L2 距離関数についてまとめると、これらを比較する良い例えは、A と B をニューヨーク市マンハッタンの 2 つの建物として考えることです。A から B まで行くタクシーは L1 パス (街路や大通り) に沿って走行する必要がありますが、鳥はおそらく L2 パス (直線) を使用するでしょう。
コサイン類似度
L1 および L2 とは対照的に、コサイン類似度は 2 つのベクトルと間の距離を測定するのではなく、それらの相対的な角度、つまり両方がほぼ同じ方向を向いているかどうかを測定します。類似度が高いほど、2 つのベクトル間の角度が小さくなり、したがって、それらのベクトルは「近く」なり、伝えられる意味は「似ている」ことになります。
これを説明するために、野外でそれぞれ異なる方向を見ている 2 人の人物を考えてみます。下の図では、青い人物はベクトルで示される方向を向いており、赤い人物はベクトルの方向を向いています。視線を同じ方向に向けるほど(つまり、ベクトルが近づくほど)、青と赤の領域で表された視野の重なり合う部分が大きくなります。視野がどの程度重なるかがコサイン類似度です。ただし、人物 B は人物 A よりも遠くを見ていることに注意してください (つまり、ベクトルが長い)。人 B は地平線の遠くの山を眺めているかもしれませんが、人 A は近くの木を眺めているかもしれません。コサイン類似度の場合、角度だけが関係するため、コサイン類似度は役割を果たしません。

それでは、コサイン類似度を計算してみましょう。式(4)は非常に単純で、分子は2つのベクトルのドット積で構成され、分母にはベクトルの大きさ(つまり長さ)の積が含まれます。
と間のコサイン類似度は、それらの間の角度の尺度として以下の画像に示されています (赤で表示)。

これらのコサイン類似度値が具体的に何を意味するのかを説明するために、少し回り道をしてみましょう。下のコサイン関数を示す画像に見られるように、値は常に範囲内で振動します。
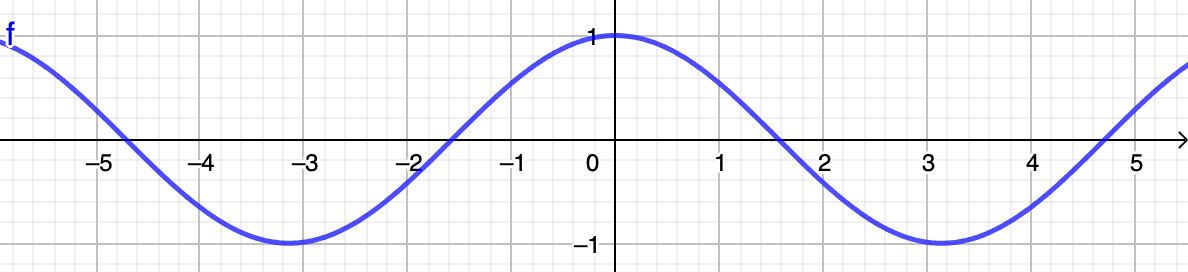
2 つのベクトルが類似しているとみなされるためには、その角度が可能な限り鋭角で、理想的には角度に近く、完全な類似度がになる必要があることに注意してください。つまり、ベクトルは...
- ...互いに近づくと、角度の余弦は近づきます(つまり、 に近づきます)。

- ...無関係ですが、角度の余弦は近づきます(つまり、 に近づきます)。

- ...反対に、その角度の余弦はに近づきます(つまり、 に近づきます)。

2つのベクトル間のコサイン類似度を計算する方法がわかり、結果の値をどのように解釈するかもよくわかったので、同じサンプルベクトルとを再利用し、先ほど見た式(4)を使用してコサイン類似度を計算できます。
コサイン類似度は となり、これは よりも に近いため、 2 つのベクトルは 多少類似して いる、つまり完全に類似しているわけではないが、完全に無関係でもなく、明らかに反対の意味を持っていないことを意味します。
任意のコサイン類似度値から正のスコアを導き出すには、次の式(5)を使用する必要があります。この式は、 範囲内で振動するコサイン類似度値をの範囲内のスコアに変換します。
したがって、サンプルベクトルとのスコアは次のようになります: 。
ドット積類似度
コサイン類似度の欠点の 1 つは、2 つのベクトル間の角度のみが考慮され、大きさは考慮されないことです。つまり、2 つのベクトルがほぼ同じ方向を指していても、一方が他方よりもはるかに長い場合、両方とも類似していると見なされます。ドット積類似度 (スカラー類似度または内積類似度とも呼ばれる) は、ベクトルの角度と大きさの両方を考慮することで類似度を改善し、より正確な類似度メトリックを提供します。ベクトルの大きさを無関係にするために、ドット積類似性では、まずベクトルを正規化する必要があります。そのため、最終的には単位長さ 1 のベクトルのみを比較することになります。
先ほどと同じ 2 人の人物でもう一度これを説明してみます。ただし今回は、彼らを円形の部屋の中央に配置し、彼らの視界の範囲 (つまり、部屋の半径) がまったく同じになるようにします。コサイン類似度と同様に、同じ方向を向くほど(つまり、ベクトルが近づくほど)、視野の重なり合う部分が多くなります。しかし、コサイン相似とは逆に、両方のベクトルの長さは同じで、両方の領域の表面積も同じなので、2 人の人物は同じ距離にあるまったく同じ画像を見ていることになります。これら 2 つの領域がどの程度重なり合っているかは、それらのドット積の類似性を示します。

ドット積の類似度の式を紹介する前に、ベクトルを正規化する方法を簡単に見てみましょう。これは非常に簡単で、2 つの簡単な手順で実行できます。
- ベクトルの大きさを計算する
- 各成分を1で得られた大きさで割ります。
例として、ベクトルを取ります。コサイン類似度を確認したときに見たように、その大きさを計算できます。つまり、 。次に、ベクトルの各成分をその大きさで割ると、次の正規化ベクトルが得られます。
2番目のベクトルに対して同じプロセスを実行すると、次の正規化されたベクトルが生成されます。
ドット積類似度式を導くために、正規化されたベクトルと間のコサイン類似度を式(4)を用いて以下のように計算することができる。
そして、両方の正規化されたベクトルの大きさがなったので、ドット積の相似式(6)は単純に、両方の正規化されたベクトルのドット積になります。
下の図では、正規化されたベクトルとを示しており、1 つのベクトルを他のベクトルに投影することで、それらのドット積の類似性を示しています (赤で表示)。
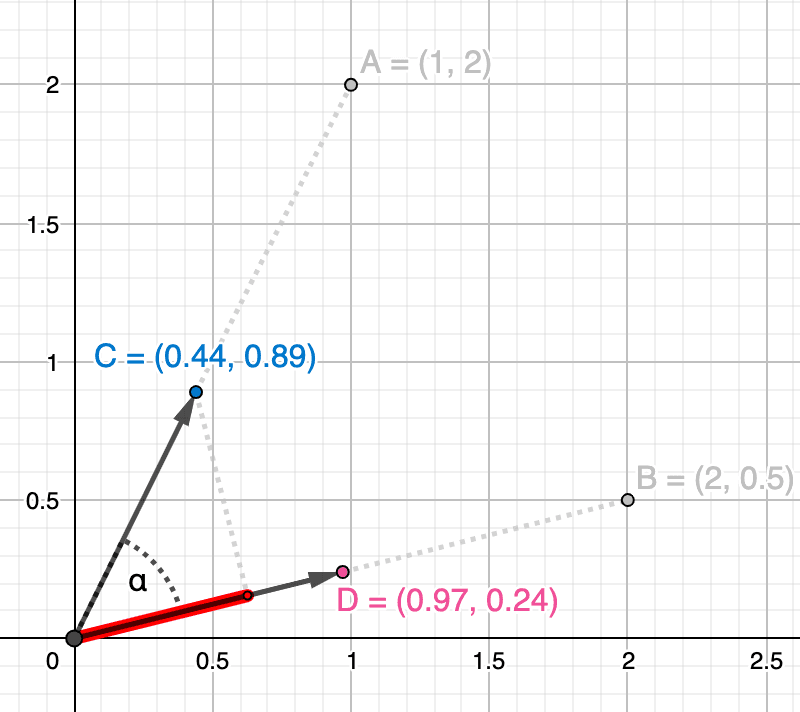
新しい式(6)を使用すると、2つの正規化されたベクトルのドット積類似度を計算することができ、当然のことながら、コサインの類似度とまったく同じ類似度値が得られます。
ドット積類似性を活用する場合、ベクトルに浮動小数点値が含まれているかバイト値が含まれているかに応じて、スコアの計算方法が異なります。前者の場合、スコアはコサイン類似度の場合と同じ方法で以下の式(7)を使用して計算されます。
しかし、ベクトルがバイト値で構成されている場合、スコアリングの計算方法は以下の式(8)に示すように少し異なります。ここで、 ベクトルの次元数です。
また、正確なスコアを生成するための制約の 1 つは、クエリ ベクトルを含むすべてのベクトルの長さが同じである必要があるが、必ずしも 1 である必要はないということです。
最大内積類似度
リリース 8.11 以降では、ベクトルを正規化する必要がないという点で、ドット積類似度よりも制約が少ない新しい類似度関数があります。この主な理由は以下の記事で詳しく説明されていますが、簡単にまとめると、特定のデータセットはベクトルの正規化にあまり適しておらず (例: Cohere 埋め込み)、正規化すると関連性の問題が発生する可能性があります。
最大内積類似度を計算する式は、ドット積の式とまったく同じです(6)。変わるのは、以下の式(9)に示すように、類似性が正か負かによって式が変わる区分関数を使用して最大内積類似度をスケーリングしてスコアを計算する方法です。
この区分関数は、 区間内のすべての負の最大内積類似度値と、 区間内のすべての正の値をスケーリングします。
要約すれば
数学的に言えば、これはかなり大変な話ですが、役に立つと思われるポイントをいくつか挙げておきます。
どの類似度関数を使用できるかは、最終的にはベクトル埋め込みが正規化されているかどうかによって決まります。ベクトルがすでに正規化されている場合、またはデータ セットがベクトルの正規化に依存しない場合 (つまり、関連性が損なわれない場合)、ベクトルを正規化してドット積類似度を使用できます。これは、各ベクトルの長さを計算する必要がないため、コサイン積類似度よりもはるかに高速に計算できるためです。何百万ものベクトルを比較する場合、それらの計算量は非常に多くなることがあります。
ベクトルが正規化されていない場合は、次の 2 つのオプションがあります。
- ベクトルを正規化できない場合はコサイン類似度を使用する
- ベクトルの大きさが意味を持つため、それをスコアリングに反映させたい場合には、新しい最大内積類似度を使用します(例:Cohere埋め込み)。
この時点で、ベクトル埋め込み間の距離または類似性を計算し、そのスコアを導き出す方法が理解できるはずです。この記事がお役に立てれば幸いです。
よくあるご質問
コサイン類似度は何を測定するのでしょうか?
コサイン類似度は、2 つのベクトル間の相対的な角度、つまり、両方がほぼ同じ方向を指しているかどうかを測定します。
L1距離はどのように測定されますか?
L1距離は、すべての要素間の絶対差をペアごとに合計することによって測定されます。
L2距離はどのように測定されますか?
2 つのベクトルの L2 距離 (ユークリッド距離とも呼ばれます) は、まずそのすべての要素のペアワイズ差の 2 乗を合計し、その結果の平方根を取ることによって測定されます。
L1距離とL2距離の違いは何ですか?
L1距離とL2距離の違いは、2つのベクトルをどのように測定するかという点に起因します。L1距離は、すべての要素間の絶対差をペアごとに合計することによって測定されます。一方、L2距離は、まずすべての要素のペアごとの差の二乗を合計し、次にその結果の平方根を取ることによって測定されます。
コサイン類似度とコサイン距離の違いは何ですか?
コサイン類似度は、2つのベクトルの相対的な角度、つまり、それらがほぼ同じ方向を向いているかどうかを測定する指標です。一方、コサイン距離は、それらの方向がどれだけ異なっているかを測定する。
ドット積とコサイン類似度の違いは何ですか?
内積はベクトルの長さと向きの両方を測定するのに対し、コサイン類似度はベクトルの方向の向きのみを測定し、長さは考慮しない。
ドット積とコサイン類似度は、それぞれどのような場合に使い分けるべきでしょうか?
ベクトルが正規化されている場合(または関連性に影響を与えずに正規化できる場合)、内積類似度を使用してください。ベクトルの長さを計算する必要がないため、処理が高速になります。ベクトルが正規化されていない場合は、方向のみに関心がある場合はコサイン類似度を使用し、ベクトルの大きさが意味を持ち、スコアに影響を与えるべきである場合は内積を使用してください。
ベクトル検索に適した距離指標はどのように選択すればよいですか?
ベクトルと検索で重要な要素に基づいて距離指標を選択してください。絶対差を測定するにはL1またはL2を使用し、方向のみが重要な場合はコサイン類似度、方向と大きさの両方が重要でベクトルが正規化されている場合はドット積、ベクトルが正規化されていないが大きさが関連性に影響を与えるべき場合は最大内積を使用します。
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。