从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具包。请访问Elasticsearch Labs 仓库中的示例笔记本,尝试新事物。您也可以立即开始免费试用或在本地运行 Elasticsearch。
当需要搜索自由文本,而 Ctrl+F / Cmd+F 又无法满足要求时,通常会想到使用词法搜索引擎。词法搜索引擎擅长分析和标记要搜索的文本,将其转化为可在搜索时匹配的术语,但在理解和理解被索引和搜索文本的真正含义方面,它们通常存在不足。
这正是矢量搜索引擎的优势所在。它们可以为同一文本编制索引,以便根据文本所代表的含义及其与其他具有相似或相关含义的概念之间的关系进行搜索。
在本博客中,我们将简要介绍矢量是如何传达文本含义的一个重要数学概念。然后,我们将深入探讨 Elasticsearch 在搜索相邻向量(即搜索含义相似的向量)时支持的不同相似性技术,以及如何对它们进行评分。
什么是向量嵌入?
本文不会深入探讨向量嵌入的复杂性。如果您想进一步了解这一主题,或者在继续学习之前需要一些入门知识,我们建议您查看以下指南。
简而言之,矢量嵌入是通过机器学习过程获得的。深度学习神经网络),可将任何类型的非结构化输入数据(如原始文本、图像、视频、声音等)转化为承载其意义和关系的数字数据。不同类型的非结构化数据需要不同类型的机器学习模型,这些模型经过训练,可以"了解" 每种类型的数据。
每个矢量将特定数据定位为多维空间中的一个点,该位置代表了模型用来描述数据特征的一组特征。维度的数量取决于机器学习模型,但通常从几百到几千不等。例如,OpenAI Embeddings 模型拥有 1536 个维度,而Cohere Embeddings 模型则有 382 到 4096 个维度。从最新版本开始,Elasticsearch dense_vector 字段类型支持多达 4096 个维度。
向量嵌入的真正特点是,意义相似的数据点在空间中靠得很近。另一个有趣的方面是,向量嵌入也有助于捕捉数据点之间的关系。
如何比较向量?
我们知道,非结构化数据会被机器学习模型切割成向量嵌入,以捕捉数据在大量维度上的相似性,现在我们需要了解这些向量的匹配是如何进行的。事实证明,答案非常简单。
相互接近的向量嵌入代表语义上相似的数据片段。因此,当我们查询矢量数据库时,搜索输入(图像、文本等)首先会被转化为矢量嵌入,使用的机器学习模型与索引所有非结构化数据时使用的相同,最终目标是找到与该查询矢量最近的相邻矢量。因此,我们需要做的就是找出如何测量查询向量与数据库中索引的所有现有向量之间的"距离" 或"相似性" - 就是这么简单。
距离、相似性和评分
幸运的是,由于有了向量算术,测量两个向量之间的距离或相似性是一个很容易解决的问题。因此,让我们来看看 Elasticsearch 支持的最常用的距离和相似性函数。警告,前方有数学题!
在开始之前,让我们先来了解一下计分。事实上,Lucene 只允许分数为正。我们即将介绍的所有距离和相似度函数都能衡量两个向量的接近或相似程度,但这些原始数据很少适合用作分数,因为它们可能是负数。因此,需要从距离或相似度值中得出最终分数,以确保分数为正值,分数越大,排名越靠前(即向量越接近)。
L1 距离
两个向量和的 L1 距离(也称作曼哈顿距离)是通过将它们所有元素的成对绝对差值相加来测量的。显然,距离 越小,两个向量就越接近。L1 距离公式 (1) 非常简单,如下所示:
下图(红色)可以直观地说明 L1 距离:

计算以下两个向量的 L1 距离 \vec{A} = \binom{1}{2} 和 \vec
重要: 值得注意的是,L1 距离函数仅支持使用 script_scoreDSL 查询进行 精确向量搜索 (又称暴力搜索),但不支持使用knn 搜索选项 或knn DSL 查询 进行 近似 kNN 搜索 。
L2 距离
两个向量和的 L2 距离(也称欧几里得距离)的测量方法是:首先求出它们所有元素的成对差值的平方和,然后取其平方根。它基本上是两点之间最短的路径。与 L1 类似,距离 越小,两个向量越接近:
下图中的 L2 距离用红色表示:

让我们重新使用与 距离相同的两个样本向量 和 距离为 。
就评分而言,两个向量之间的距离越小,它们就越接近(即越相似)。因此,为了得出分数,我们需要反转距离度量,使最小的距离产生最高的分数。使用 L2 距离计算分数的方法如下式(3)所示:
重复使用前面例子中的样本向量,它们的得分是 \frac 0.2352。相距很近的两个向量的得分将接近 1,而相距很远的两个向量的得分将趋于 0。
在总结 L1 和 L2 距离函数时,一个很好的类比方法是将 A 和 B 视为纽约市曼哈顿的两座大楼。一辆从 A 地开往 B 地的出租车必须沿着 L1 路径(街道和大道)行驶,而一只鸟可能会使用 L2 路径(直线)。
余弦相似性
与 L1 和 L2 不同的是,余弦相似度不是测量两个向量和 之间的距离,而是测量它们的相对角度,即它们是否都指向大致相同的方向。相似度 越高,两个矢量之间的夹角就越小,因此,",它们之间的距离就越近," ,它们所表达的含义就越相似,"," 。
为了说明这一点,让我们设想两个人在野外朝不同的方向寻找。在下图中,穿蓝色衣服的人朝矢量的方向看,穿红色衣服的人朝矢量 的方向看。他们的视线越是朝向同一个方向(即他们的矢量越接近),蓝色和红色区域所代表的视野就越是重叠。它们的视场重叠程度就是它们的余弦相似度。但是,请注意,人 B 比人 A 看得更远(即矢量更长)。人 B 可能在看地平线上远处的一座山,而人 A 可能在看附近的一棵树。对于余弦相似度来说,这没有任何作用,因为它只与角度有关。

现在我们来计算余弦相似度。公式 (4) 非常简单,分子是两个矢量的点乘,分母是两个矢量的大小乘积(即长度):
和之间的余弦相似度如下图所示,是它们之间夹角的度量(红色):

让我们绕个弯,具体解释一下这些余弦相似度值的含义。从下面描述余弦函数的图片中可以看出,数值总是在区间内摆动。
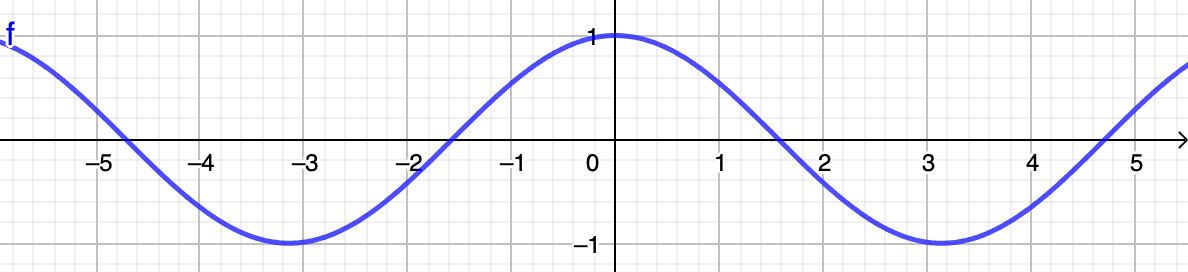
请记住,要使两个矢量相似,它们之间的夹角必须尽可能锐利,最好接近,即完全相似度为。换句话说,当矢量...
- ......彼此接近,其角度的余弦接近(即接近)。

- ......无关,它们的夹角余弦接近(即接近)。

- ......相反,它们的夹角余弦接近(即接近)。

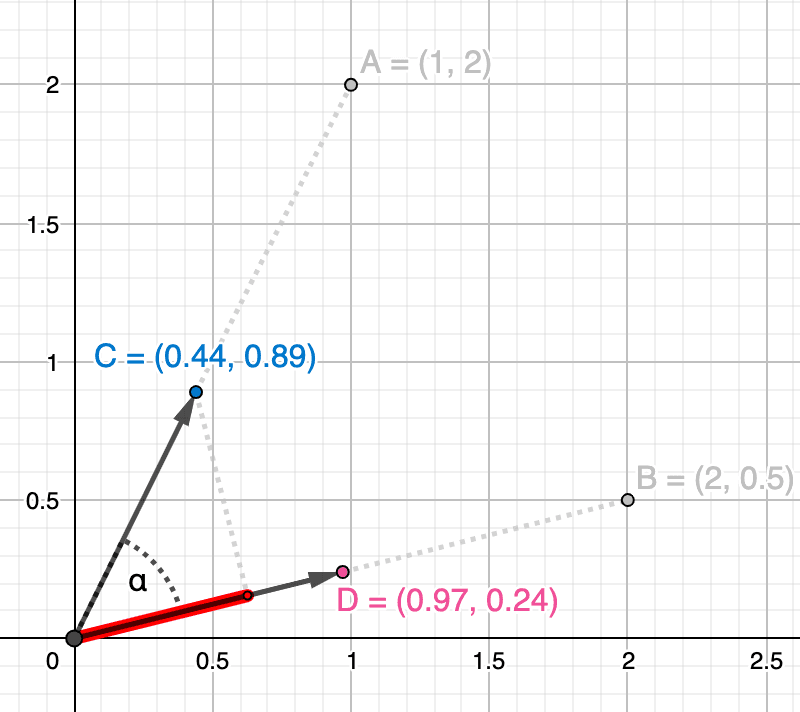
既然我们已经知道如何计算两个向量之间的余弦相似度,并对如何解释所得值有了很好的概念,那么我们就可以重新使用相同的样本向量和,并使用我们之前看到的公式 (4) 计算它们的余弦相似度。
我们得到的余弦相似度为,更接近于而不是,这意味着这两个矢量有些相似,即不是完全相似,但也不是完全无关,当然也没有相反的含义。
为了从任何余弦相似度值中得出正分数,我们需要使用下面的公式 (5),该公式将在区间内摆动的余弦相似度值转换为区间内的分数:
因此,样本向量和的得分为\frac 0.8253。
点积相似性
余弦相似度的一个缺点是,它只考虑两个矢量之间的角度,而不考虑它们的大小,这意味着如果两个矢量大致指向同一个方向,但其中一个矢量比另一个矢量长很多,那么这两个矢量仍然会被认为是相似的。点积相似性(也称为标量或内积相似性)考虑了向量的角度和大小,从而改进了点积相似性,提供了更精确的相似性度量。为了使向量的大小变得无关紧要,点积相似性要求首先对向量进行归一化处理,因此我们最终只比较单位长度为 1 的向量。
让我们用同样的两个人来再次说明这个问题,但这次我们把他们放在一个圆形房间的中间,这样他们的视线范围就完全相同了(即房间的半径)。与余弦相似度类似,它们转向的方向越一致(即它们的矢量越接近),它们的视场重叠就越多。然而,与余弦相似性相反的是,两个矢量的长度相同,两个区域的表面相同,这意味着两个人看的是位于相同距离的完全相同的图片。这两个区域的重叠程度表示它们的点积相似度。

在介绍点积相似性公式之前,让我们先快速了解一下如何对向量进行归一化处理。这非常简单,只需两个微不足道的步骤即可完成:
- 计算向量的大小
- 将每个分量除以 1 中得到的大小。
举例来说,让我们把向量 \vec我们可以计算出它的大小 \Vert\Vert ,就像我们之前在回顾余弦相似性时看到的那样,即 \sqrt 。然后,将矢量的每个分量除以其幅度,我们就得到了下面的归一化矢量 :
对第二个向量 \vec :
为了得出点积相似度公式,我们可以使用公式(4)计算归一化向量和之间的余弦相似度,如下图所示:
由于两个归一化向量的大小现在都是,所以点积相似公式 (6) 就变成了......你猜对了,两个归一化向量的点积:
在下图中,我们显示了归一化向量和,我们可以用一个向量在另一个向量上的投影(红色)来说明它们的点积相似性。
使用新公式 (6),我们可以计算出两个归一化向量的点积相似度,不出意外,这将得到与余弦相似度完全相同的相似度值:
在利用点积相似性时,得分的计算方法会因向量包含浮点值还是字节值而有所不同。在前一种情况下,得分的计算方法与余弦相似性相同,使用下面的公式(7):
但是,当向量由字节值组成时,计算得分的方法就有些不同了,如下式(8)所示,其中是向量的维数:
此外,为了获得准确的分数,还有一个限制条件,即包括查询向量在内的所有向量必须具有相同的长度,但不一定是 1。
最大内积相似度
自 8.11 版起,新的相似度函数比点积相似度的限制更少,因为向量不需要进行归一化处理。下面的文章将详细解释其中的主要原因,但简单来说,某些数据集不太适合对其向量进行归一化处理(例如Cohere 内嵌),这样做可能会导致相关性问题。
计算最大内积相似度的公式与点积公式 (6) 完全相同。改变的是计算得分的方式,即使用一个片断函数对最大内积相似度进行缩放,该函数的计算公式取决于相似度是正还是负,如下式(9)所示:
这个分段函数的作用是,在区间内对所有负的最大内积相似度值进行缩放,在区间内对所有正值进行缩放。
总之
从数学的角度看,这真是一次不寻常的旅程,但这里有一些启示,你可能会觉得有用。
您可以使用哪种相似度函数,最终取决于您的向量嵌入是否经过归一化处理。如果您的矢量已经归一化,或者您的数据集与矢量归一化无关(即相关性不会受到影响),那么您可以继续对矢量进行归一化,并使用点积相似性,因为它的计算速度比余弦相似性快得多,因为不需要计算每个矢量的长度。在比较数百万个向量时,这些计算量会增加很多。
如果您的向量没有标准化,那么您有两种选择:
- 如果无法对向量进行归一化处理,则使用余弦相似度
- 如果您希望矢量的大小对评分有帮助,可以使用新的最大内积相似性,因为它们确实有意义(例如,Cohere 嵌入)。
至此,计算向量嵌入之间的距离或相似性,以及如何得出它们的分数,对你来说应该已经很清楚了。希望这篇文章对您有所帮助。
常见问题
余弦相似度的测量方法是什么?
余弦相似度衡量的是两个向量之间的相对角度,即它们是否都指向大致相同的方向。
如何测量 L1 距离?
L1 距离的测量方法是将所有元素的成对绝对差值相加。
如何测量 L2 距离?
两个向量的 L2 距离(也称欧几里得距离)的测量方法是:首先求出两个向量所有元素的成对差值的平方和,然后取其平方根。
L1 和 L2 距离有什么区别?
L1 和 L2 距离的区别在于如何测量两个矢量。L1 距离的测量方法是将所有元素的成对绝对差值相加。另一方面,L2 距离的测量方法是,首先将所有元素的成对差值的平方相加,然后取结果的平方根。
余弦相似度和余弦距离有什么区别?
余弦相似度测量两个向量的相对角度,即它们是否都指向大致相同的方向。另一方面,余弦距离可以测量它们的方向差异。
点积和余弦相似性有什么区别?
点积同时测量向量的长度和对齐度,而余弦相似度只测量向量方向的对齐度,忽略了长度。
什么时候应该使用点积与余弦相似性?
如果你的向量已经归一化(或可以归一化而不影响相关性),请使用点积相似性--它更快,因为你不需要计算向量长度。如果您的矢量没有进行归一化处理,那么在只关心方向的情况下,可以使用余弦相似度;如果矢量的大小具有意义并会影响得分,则可以使用点积。
如何为矢量搜索选择正确的距离度量?
根据矢量和搜索的重要程度选择距离度量:使用 L1 或 L2 来衡量绝对差异;如果只考虑方向,则使用余弦相似度;如果方向和大小都重要(且矢量已归一化),则使用点积;如果矢量未归一化,但大小会影响相关性,则使用最大内积。
相关内容

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。


LINQ to Elasticsearch ES|QL:编写 C# 代码,查询 Elasticsearch
探索 Elasticsearch .NET 客户端中全新的 LINQ to Elasticsearch ES|QL 提供程序。借助该程序,您可以编写会自动转换为 ES|QL 查询的 C# 代码。