Beobachten, schützen und durchsuchen Sie Ihre Daten mit einer einzigen Lösung. Von der Anwendungsüberwachung bis zur Bedrohungserkennung – Kibana ist Ihre vielseitige Plattform für kritische Anwendungsfälle. Starten Sie jetzt Ihre kostenlose 14-tägige Testphase.
Im ersten Teil dieser Serie, verfasst von Iulia Feroli, haben wir darüber gesprochen, wie man seine Spotify Wrapped-Daten erhält und in Kibana visualisiert. Im zweiten Teil tauchen wir tiefer in die Daten ein, um zu sehen, was wir sonst noch herausfinden können. Hierfür werden wir einen etwas anderen Ansatz wählen und Spotify to Elasticsearch verwenden, um die Daten in Elasticsearch zu indizieren. Dieses Tool ist etwas fortgeschrittener und erfordert etwas mehr Aufwand bei der Einrichtung, aber es lohnt sich. Die Daten sind strukturierter, und wir können komplexere Fragen stellen.
Unterschiede zur ersten Spotify Wrapped-Analyse
Im ersten Blogbeitrag haben wir den Spotify-Export direkt verwendet und keine Normalisierungsaufgaben oder sonstige Datenverarbeitungsschritte durchgeführt. Dieses Mal verwenden wir dieselben Daten, werden sie aber aufbereiten, um sie besser nutzbar zu machen. Dies wird es uns ermöglichen, wesentlich komplexere Fragen zu beantworten, wie zum Beispiel:
- Wie lang ist ein Song in meinen Top 100 im Durchschnitt?
- Wie hoch ist die durchschnittliche Beliebtheit eines Songs in meinen Top 100?
- Wie lange wird ein Lied im Durchschnitt angehört?
- Welcher Song wird bei mir am häufigsten übersprungen?
- Wann überspringe ich gerne Musiktitel?
- Höre ich zu einer bestimmten Tageszeit mehr Musik als zu anderen?
- Höre ich an einem bestimmten Wochentag mehr Musik als an anderen?
- Ist es ein Monat von besonderem Interesse?
- Welcher Künstler hat die längste Hörerschaftszeit?
Spotify Wrapped ist jedes Jahr ein tolles Erlebnis, das dir zeigt, was du dieses Jahr gehört hast. Es werden keine Veränderungen im Jahresvergleich angezeigt, sodass Ihnen möglicherweise einige Künstler entgehen, die einst zu Ihren Top 10 gehörten, aber nun verschwunden sind.
Verarbeitung von Spotify Wrapped-Daten zur Analyse
Es gibt einen großen Unterschied in der Art und Weise, wie wir die Daten im ersten und im zweiten Beitrag verarbeiten. Wenn Sie weiterhin mit den Daten aus dem ersten Beitrag arbeiten möchten, müssen Sie einige Änderungen der Feldnamen berücksichtigen und auf ES|QL zurückgreifen, um bestimmte Extraktionen wie hour of day dynamisch durchzuführen.
Dennoch solltet ihr alle in der Lage sein, diesem Beitrag zu folgen. Die Datenverarbeitung im Spotify-zu-Elasticsearch- Repository beinhaltet das Abfragen der Spotify-API nach der Dauer des Songs, der Popularität sowie das Umbenennen und Erweitern einiger Felder. Das Feld artist im Spotify-Export ist beispielsweise lediglich ein String und repräsentiert weder Features noch Tracks mit mehreren Künstlern.
Visualisierung von Spotify Wrapped-Daten mit Dashboards
Ich habe in Kibana ein Dashboard erstellt, um die Daten zu visualisieren. Das Dashboard ist hier verfügbar und kann in Ihre Kibana-Instanz importiert werden. Das Dashboard ist sehr umfangreich und beantwortet viele der oben genannten Fragen.
Lasst uns einige der Fragen betrachten und gemeinsam überlegen, wie wir sie beantworten können!
Wie lang ist ein Song in meinen Top 100 im Durchschnitt?
Um diese Frage zu beantworten, können wir Lens oder ES|QL verwenden. Lasst uns alle drei Optionen genauer betrachten. Formulieren wir diese Frage einmal korrekt im Elasticsearch-Stil. Wir möchten die 100 beliebtesten Lieder finden und dann die durchschnittliche Dauer aller dieser Lieder zusammen berechnen. In Elasticsearch-Begriffen wären das zwei Aggregationen:
- Finde die Top 100 Songs heraus
- Berechne die durchschnittliche Dauer dieser 100 Lieder.
Lens
In Lens ist das ganz einfach: Man erstellt eine neue Lens, wechselt zu einer Tabelle und zieht das Feld title per Drag & Drop in die Tabelle. Klicken Sie anschließend auf das Feld title und stellen Sie die Größe auf 100 ein. Stellen Sie außerdem den Modus accuracy ein. Ziehen Sie dann das Feld duration per Drag & Drop in die Tabelle und verwenden Sie last value, da wir eigentlich nur den letzten Wert der Dauer jedes Liedes benötigen. Dasselbe Lied hat nur eine einzige Dauer. Am Ende dieser last value -Aggregation befindet sich ein Dropdown-Menü für eine Zusammenfassungszeile. Wählen Sie average aus, um sie anzuzeigen.

ES|QL
ES|QL ist im Vergleich zu DSL und Aggregationen eine recht neue Sprache, aber sie ist sehr leistungsstark und einfach zu bedienen. Um dieselbe Frage in ES|QL zu beantworten, würden Sie die folgende Abfrage schreiben:
Ich führe Sie Schritt für Schritt durch diese ES|QL-Abfrage:
from spotify-history- Dies ist das Indexmuster, das wir verwenden.stats duration=max(duration), count=count() by title- Dies ist die erste Aggregation; wir berechnen die maximale Dauer jedes Liedes und die Anzahl der Lieder. Wir verwendenmaxanstelle vonlast value, wie es in der Lens verwendet wird, da ES|QL derzeit kein erstes oder letztes Element hat.sort count desc- Wir sortieren die Lieder nach der Anzahl der Aufrufe jedes Liedes, sodass das meistgehörte Lied ganz oben steht.limit 100- Wir beschränken das Ergebnis auf die Top 100 Songs.stats Average duration of the songs=avg(duration)- Wir berechnen die durchschnittliche Dauer der Lieder.
Ist ein bestimmter Monat für mich von besonderem Interesse?
Um diese Frage zu beantworten, können wir Lens mithilfe von Laufzeitfeldern und ES|QL verwenden. Was uns sofort auffällt: Es gibt kein Feld in den Daten, das die month direkt angibt; stattdessen müssen wir sie aus dem Feld @timestamp berechnen. Dafür gibt es mehrere Möglichkeiten:
- Verwenden Sie ein Laufzeitfeld, um die Linse mit Strom zu versorgen.
- ES|QL
Ich persönlich halte ES|QL für die elegantere und schnellere Lösung.
Das ist alles, nichts Kompliziertes ist nötig. Wir können die DATE_EXTRACT -Funktion nutzen, um den Monat aus dem @timestamp -Feld zu extrahieren und können dann darüber aggregieren. Mithilfe der ES|QL-Visualisierung können wir das auf dem Dashboard einbinden.

Wie lange höre ich im Durchschnitt pro Künstler und Jahr?
Die Idee dahinter ist, herauszufinden, ob ein Künstler nur eine einmalige Erscheinung ist oder ob es zu einer Wiederholung kommt. Wenn ich mich richtig erinnere, zeigt Spotify nur die Top 5 Künstler im Jahresrückblick an. Vielleicht bleibt dein Künstler auf Platz 6 immer derselbe, oder er wechselt ab Platz 10 stark?
Eine der einfachsten Darstellungsformen hierfür ist ein prozentuales Balkendiagramm. Wir können dafür Lens verwenden. Folgen Sie den folgenden Schritten:
Ziehen Sie das Feld listened_to_ms per Drag & Drop an die gewünschte Stelle. Dieses Feld gibt an, wie lange Sie ein Lied in Millisekunden angehört haben. Standardmäßig erstellt Lens eine median -Aggregation. Das wollen wir nicht, ändern wir das in eine sum. Wählen Sie oben für den Balkendiagrammtyp percentage anstelle von stacked aus. Für die Aufschlüsselung wählen Sie artist und geben Sie „Top 10“ ein. Vergessen Sie nicht, im Dropdown-Menü Advanced die accuracy mode auszuwählen. Jeder Farbblock repräsentiert nun, wie oft Sie diesen einzelnen Künstler gehört haben. Je nach gewähltem Zeitauswahlfeld können die Balken Werte von Tagen über Wochen und Monate bis hin zu Jahren darstellen. Wenn Sie eine wöchentliche Aufschlüsselung wünschen, wählen Sie @timestamp aus und stellen Sie mininum interval auf year ein. Was wir in meinem Fall nun sagen können, ist, dass Fred Again.. der Künstler ist, den ich am häufigsten gehört habe; fast 12 % meiner gesamten Hörzeit entfielen auf Fred Again... Wir sehen auch, dass Fred Again.. im Jahr 2024 etwas zurückging, Jamie XX aber stark zunahm. Wenn wir nur die Größe der Balken vergleichen. Wir können auch feststellen, dass während Billie Eilish im Jahr 2024 ständig gespielt wird, der Balken sich verbreitert. Das bedeutet, dass ich Billie Eilish im Jahr 2024 häufiger gehört habe als im Jahr 2023.

Wie sieht es mit den Top-Titeln pro Künstler pro Hörzeit im Vergleich zur gesamten Hörzeit aus?
Das ist eine ganz schön komplizierte Frage. Ich möchte versuchen, das zu erklären, was ich damit sagen möchte. Spotify informiert dich über den Top-Song eines einzelnen Künstlers oder über deine insgesamt 5 Top-Songs. Das ist auf jeden Fall interessant, aber wie sieht es mit dem Zusammenbruch eines Künstlers aus? Verbringe ich meine gesamte Zeit nur mit einem einzigen Lied, das ich immer und immer wieder höre, oder ist meine Zeit gleichmäßig verteilt?
Erstellen Sie eine neue Linse und wählen Sie Treemap als Typ aus. Für metric gilt dasselbe wie zuvor: Wählen Sie sum aus und verwenden Sie listened_to_ms als Feld. Für die group by benötigen wir zwei Werte. Das erste ist artist und dann füge ein zweites mit title hinzu. Das Zwischenergebnis sieht folgendermaßen aus:

Ändern wir das in Top 100 Künstler und deaktivieren wir die other im erweiterten Dropdown-Menü sowie aktivieren wir den Genauigkeitsmodus. Ändern Sie den Titel in „Top 10“ und aktivieren Sie den Genauigkeitsmodus. Das Endergebnis sieht folgendermaßen aus:
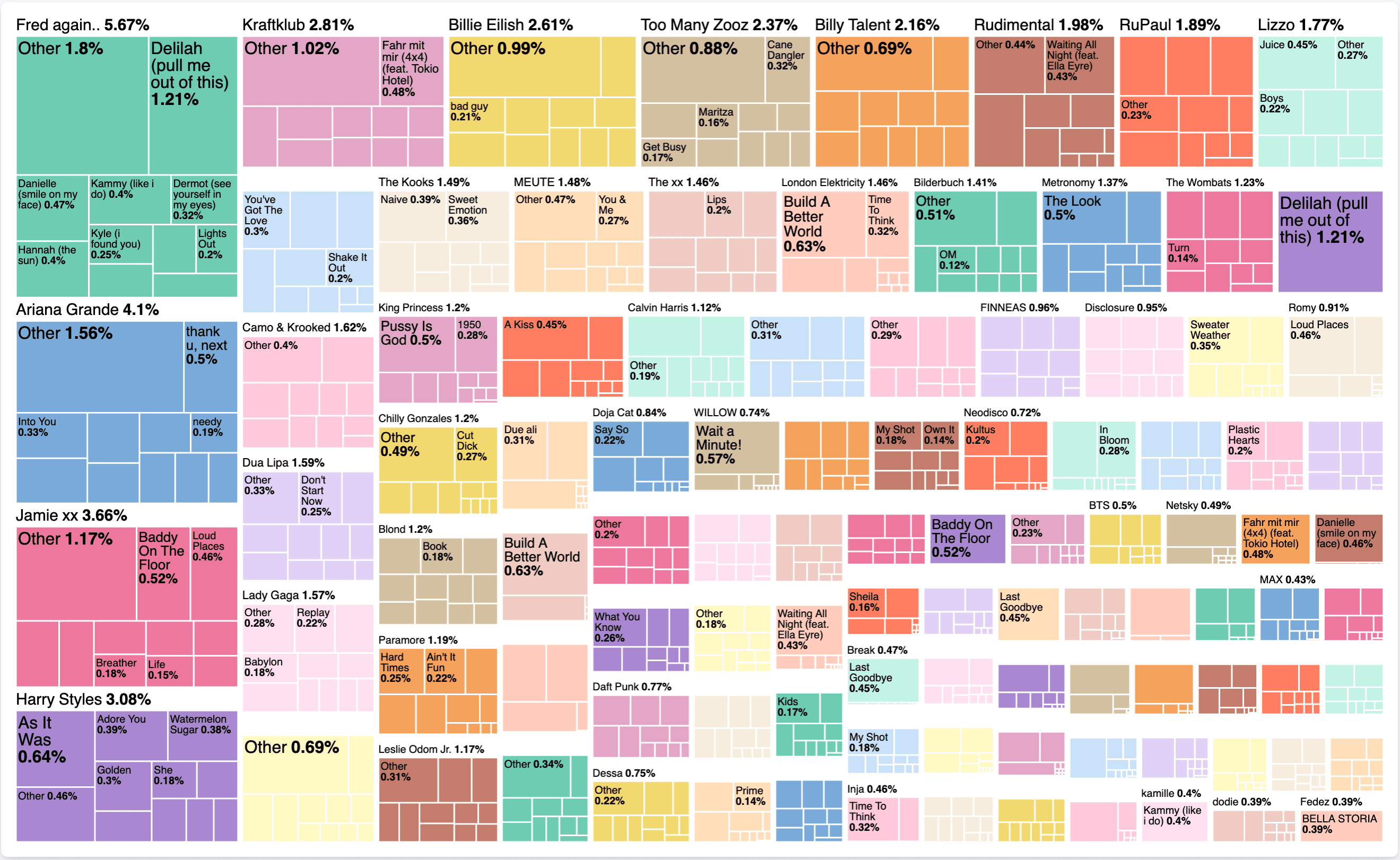
Was genau sagt uns das nun? Ohne die Zeitkomponente zu berücksichtigen, können wir sagen, dass ich in meiner gesamten Hörhistorie bei Spotify 5,67 % mit dem Hören von Fred Again.. verbracht habe. Insbesondere habe ich 1,21 % dieser Zeit mit dem Hören von Delilah (pull me out of this) verbracht. Es ist interessant zu sehen, ob es ein einzelnes Lied gibt, das einen Künstler beschäftigt, oder ob es auch andere Lieder gibt. Die Baumkarte selbst ist eine gute Darstellungsform für solche Datenverteilungen.
Höre ich zu einer bestimmten Uhrzeit und an einem bestimmten Tag?
Nun, das können wir ganz einfach mit einer Lens-Visualisierung beantworten, die die Heat Map nutzt. Erstellen Sie eine neue Linse, wählen Sie Heat Map aus. Wählen Sie für Horizontal Axis das Feld dayOfWeek aus und stellen Sie es auf Top 7 anstatt auf Top 3 ein. Für Vertical Axis wähle hourOfDay und für Cell Value einfach Count of records. Dadurch wird folgendes Panel erzeugt:

Es gibt ein paar ärgerliche Dinge an diesem Objektiv, die mich beim Interpretieren einfach stören. Lasst uns versuchen, es ein wenig aufzuräumen. Zunächst einmal ist mir die Legende nicht so wichtig, verwenden Sie das Symbol oben mit dem Dreieck, Quadrat und Kreis und deaktivieren Sie sie.
Der zweite ärgerliche Punkt ist nun die Sortierung der Tage. Es ist Montag, Mittwoch, Donnerstag oder irgendein anderer Tag, je nachdem, welche Werte Sie haben. Die hourOfDay ist korrekt sortiert. Die Art und Weise, wie die Tage sortiert werden, ist ein witziger Trick, nämlich die Verwendung von Filters anstelle von Top Values. Klicken Sie auf dayOfWeek und wählen Sie Filters aus. Es sollte nun so aussehen:

Jetzt fangen Sie einfach an, die Tage einzugeben. Ein Filter pro Tag. "dayOfWeek" : Monday und gib ihm die Bezeichnung Monday und wiederhole den Vorgang.
Allerdings gibt es dabei einen Haken: Spotify stellt die Daten in UTC+0 ohne Zeitzoneninformationen bereit. Natürlich liefern sie auch die IP-Adresse und das Land, in dem Sie zugehört haben, und wir könnten daraus die Zeitzoneninformationen ableiten, aber das kann ungenau sein, und für Länder wie die USA, die mehrere Zeitzonen haben, kann es zu umständlich sein. Dies ist wichtig, da Elasticsearch und Kibana Zeitzonen unterstützen. Durch die Angabe der korrekten Zeitzone im Feld @timestamp passt Kibana die Zeit automatisch an die Zeit Ihres Browsers an.
So sollte es nach der Fertigstellung aussehen, und man kann erkennen, dass ich während der Arbeitszeit sehr aktiv zuhöre, samstags und sonntags hingegen weniger.

Fazit
In diesem Blogbeitrag sind wir etwas tiefer in die Feinheiten der Spotify-Daten eingetaucht. Wir haben einige einfache und schnelle Wege aufgezeigt, wie man Visualisierungen erstellen und ausführen kann. Es ist einfach fantastisch, so viel Kontrolle über den eigenen Hörverlauf zu haben. Schaut euch auch die anderen Teile der Serie an:
Zugehörige Inhalte

22. Mai 2026
Kibana reduziert die Dashboard-Ladezeit um bis zu 25 % – hier ist die Polling-Strategie dahinter
Erfahren Sie, wie Kibana durch kontinuierliches Polling und browserseitige HTTP/2-Erkennung die Ladezeiten des Dashboards um bis zu 25 % verkürzt und dabei automatisch auf HTTP/1 zurückgreift.

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

25. Mai 2026
AI Chat in Kibana rendert jetzt nativ Dashboards
Der Elastic AI Chat in Kibana erstellt jetzt Dashboards aus natürlicher Sprache, wobei Ihre Visualisierungen und Analysen in einem Thread beibehalten werden und Sie diese als wiederverwendbare Kibana-Objekte speichern können.

Verbesserung der Interaktivität des Kibana-Dashboards mit Steuerelementen für Variablen
Entdecken Sie, wie Sie mit Steuerelementen für Variablen in Kibana 8.18+ einzelne Visualisierungen filtern, Zeitintervalle anpassen und nach verschiedenen Feldern in Kibana-Dashboards gruppieren können.

KI-gestützte Dashboards: Von der Vision zu Kibana
Generieren Sie ein Dashboard mithilfe eines LLM, um ein Bild zu verarbeiten und in ein Kibana-Dashboard umzuwandeln.