Elasticsearch verfügt über native Integrationen mit den branchenführenden Gen-AI-Tools und -Anbietern. Sehen Sie sich unsere Webinare zu den Themen „RAG-Grundlagen“ oder zum „Erstellen produktionsreifer Apps“ mit der Elastic-Vektordatenbank an.
Um die besten Suchlösungen für Ihren Anwendungsfall zu entwickeln, starten Sie jetzt eine kostenlose Cloud-Testversion oder testen Sie Elastic auf Ihrem lokalen Rechner.
Alle reden über DeepSeek R1, das neue große Sprachmodell des chinesischen Hedgefonds High-Flyer. Die Nachrichten sind voll von Spekulationen darüber, was es für die Branche bedeutet, dass sie nun ein fähiges, mit offenen Gewichtungen arbeitendes LLM mit Kettenlogik eingeführt haben. Für alle, die neugierig sind und dieses neue Modell mit RAG und den intelligenten Funktionen der Vektordatenbank von Elasticsearch ausprobieren möchten, gibt es hier ein kurzes Tutorial, das Ihnen den Einstieg in die Verwendung von DeepSeek R1 mit lokaler Inferenz erleichtert. Dabei verwenden wir die Playground-Funktion von Elastic und entdecken sogar einige gute und schlechte Eigenschaften von DeepSeek R1 für RAG.
Hier ist ein Diagramm, das zeigt, was wir in diesem Tutorial konfigurieren werden:

Einrichten der lokalen Inferenz mit Ollama
Ollama ist eine hervorragende Möglichkeit, schnell eine kuratierte Auswahl an Open-Source-Modellen für lokale Inferenztests auszuprobieren, und ein beliebtes Werkzeug für KI-Entwickler.
Ausführen von Ollama bare metal
Eine lokale Installation auf Mac, Linux oder Windows ist der einfachste Weg, um lokale GPU-Funktionen zu nutzen, insbesondere für Nutzer mit Apple-Chips der M-Serie. Sobald Sie Ollama installiert haben, können Sie DeepSeek R1 mit dem folgenden Befehl herunterladen und ausführen.
Vielleicht möchten Sie die Parametergröße an Ihre Hardware anpassen. Verfügbare Größen finden Sie hier.
Sie können im Terminal mit dem Modell chatten, aber das Modell läuft auch dann weiter, wenn Sie den Befehl mit Strg+d verlassen oder „/bye“ eingeben. Um zu sehen, ob das Modell noch läuft, geben Sie Folgendes ein:
Ollama in einem Container ausführen
Der schnellste alternative Weg zum Ausführen von Ollama ist die Nutzung einer Container-Engine wie Docker. Die Nutzung der GPU Ihres lokalen Rechners ist je nach Umgebung nicht immer einfach, aber eine schnelle Testeinrichtung ist nicht schwer, solange Ihr Container über genügend RAM und Speicherplatz für die Multi-GB-Modelle verfügt.
Das Einrichten und Ausführen von Ollama in Docker ist so einfach wie der Befehl:
Dies erstellt ein Verzeichnis namens „Ollama“ im aktuellen Verzeichnis und verankert es im Container, um die Ollama-Konfiguration sowie die Modelle zu speichern. Je nach Anzahl der verwendeten Parameter können diese eine Größe von einigen GB bis zu Dutzenden von GB haben, daher sollten Sie ein Laufwerk mit ausreichend freiem Speicherplatz wählen.
Hinweis: Wenn Sie eine Nvidia-GPU in Ihrem Computer haben, installieren Sie unbedingt das Nvidia Container-Toolkit und fügen Sie dem obigen Befehl zum Ausführen von Docker „--gpus=all“ hinzu.
Sobald der Ollama-Container auf Ihrem Rechner läuft, können Sie ein Modell wie DeepSeek R1 mit folgendem Befehl abrufen:
Ähnlich wie beim Bare-Metal-Ansatz möchten Sie möglicherweise die Parametergröße ändern, um sie an Ihre Hardware anzupassen. Verfügbare Größen finden Sie unter https://ollama.com/library/deepseek-r1.
Sobald das Herunterladen des Modells abgeschlossen ist, können Sie „/bye“ eingeben, um die Eingabeaufforderung zu beenden. So überprüfen Sie, ob das Modell noch ausgeführt wird:
Testen unserer lokalen Inferenz mit einem Curl
Um die lokale Inferenz mit cURL zu testen, können Sie den folgenden Befehl ausführen. Wir verwenden stream:false, damit wir die narrative JSON-Reaktion leicht lesen können:
Testen von „OpenAI-kompatiblem“ Ollama und einer RAG-Eingabeaufforderung
Praktischerweise bietet Ollama auch einen REST-Endpoint, der das Verhalten von OpenAI nachahmt, um die Kompatibilität mit einer Vielzahl von Tools, einschließlich Kibana, zu gewährleisten.
Das Testen dieser komplexeren Eingabeaufforderung führt zu Inhalten, die einen <think>-Abschnitt enthalten, in dem das Modell darauf trainiert wurde, das Problem zu durchdenken.
Ollama mit Kibana verbinden
Eine großartige Möglichkeit, Elasticsearch zu nutzen, ist das „start-local“-Entwicklungsskript.
Stellen Sie sicher, dass Kibana und Elasticsearch Ihr Ollama im Netzwerk erreichen können. Wenn Sie ein lokales Container-Setup des Elastic Stack verwenden, bedeutet dies möglicherweise, dass Sie „localhost“ durch „host.docker.internal“ oder „host.containers.internal“ ersetzen müssen, um einen Netzwerkpfad zum gehosteten Computer zu erhalten.
Navigieren Sie in Kibana zu Stack Management > Alerts and Insights > Connectors.
Was tun, wenn Sie diese allgemeine Setup-Warnung sehen?
Sie müssen sicherstellen, dass der xpack.encryptedSavedObjects.encryptionKey korrekt eingestellt ist. Dies ist ein häufig übersehener Schritt bei der lokalen Docker-Installation von Kibana, daher liste ich die Schritte zur Behebung in der Docker-Syntax auf.

Stellen Sie sicher, dass Sie Ihr Kibana/Konfig-Verzeichnis dauerhaft speichern, damit Änderungen erhalten bleiben, wenn der Container heruntergefahren wird. Meine Kibana-Container-Laufwerke sehen in der docker-compose.yml folgendermaßen aus:
Jetzt können Sie den Keystore erstellen und einen Wert eingeben, damit die Verbindungsschlüssel nicht im Klartext gespeichert werden.
Starten Sie Ihren gesamten Cluster vollständig neu, um sicherzustellen, dass die Änderungen wirksam werden.
Erstellen des Connectors
Erstellen Sie auf dem Connector-Konfigurationsbildschirm (navigieren Sie in Kibana zu Stack Management > Alerts and Insights > Connectors) einen Connector und wählen Sie den Typ „OpenAI“ aus.
Konfigurieren Sie den Connector mit den folgenden Einstellungen:
- Name des Connectors: Deepseek (Ollama)
- Wählen Sie einen OpenAI-Anbieter aus: andere (OpenAI-kompatibler Dienst)
- URL: http://localhost:11434/v1/chat/completions
- Passen Sie den richtigen Pfad zu Ihrem Ollama an. Denken Sie daran, host.docker.internal oder ein Äquivalent zu ersetzen, wenn Sie aus einem Container heraus aufrufen.
- Standardmodell: deepseek-r1:7b
- API-Schlüssel: Denken Sie sich etwas aus, ein Eintrag ist erforderlich, aber der Wert spielt keine Rolle
Beachten Sie, dass das Testen eines benutzerdefinierten Connectors zu Ollama im Connector-Setup derzeit in 8.17 nicht funktioniert, aber in der nachfolgenden Kibana-Version 8.18 behoben wurde.
Unser Connector sieht so aus:

Vektoreingebettete Daten in Elasticsearch einlesen
Wenn Sie bereits mit Playground vertraut sind und Daten eingerichtet haben, können Sie zum nächsten Playground-Schritt übergehen. Wenn Sie jedoch einige schnelle Testdaten benötigen, müssen wir sicherstellen, dass unsere _inference-APIs eingerichtet sind. Ab Version 8.17 sind die Zuweisungen für Machine Learning dynamisch, sodass wir zum Herunterladen und Aktivieren des mehrsprachigen e5-Vektors nur Folgendes in den Kibana Dev-Tools ausführen müssen.
Wenn Sie dies noch nicht getan haben, wird das Herunterladen des e5-Modells aus den Modell-Repositorys von Elastic ausgelöst.
Als Nächstes laden wir ein gemeinfreies Buch als unseren RAG-Kontext hoch. Hier können Sie „Alice im Wunderland“ von Project Gutenberg herunterladen: Link. Speichern Sie es als .txt-Datei.
Navigieren Sie zu Elasticsearch > Home > Datei hochladen

Wählen Sie Ihre Textdatei aus oder ziehen Sie sie per Drag & Drop und klicken Sie dann auf die Schaltfläche „Importieren“.
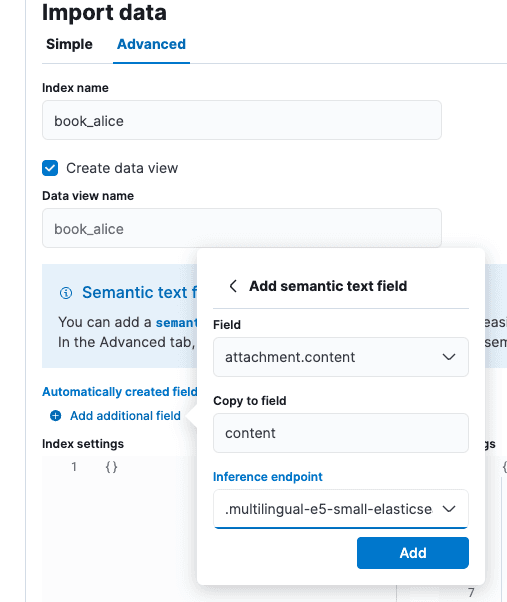
Wählen Sie auf dem Bildschirm „Daten importieren“ die Registerkarte „Erweitert“ und setzen Sie den Indexnamen auf „book_alice“.
Wählen Sie die Option „Zusätzliches Feld hinzufügen“, sie befindet sich klein direkt unter „Automatisch erstellte Felder“. Wählen Sie „Semantisches Textfeld hinzufügen“ und ändern Sie den Inferenz-Endpoint in „.multilingual-e5-small-elasticsearch“. Wählen Sie „Hinzufügen“ und dann „Importieren“.
Wenn das Laden und die Inferenz abgeschlossen sind, können wir zu Playground gehen.
RAG im Playground testen
Navigieren Sie in Kibana zu Elasticsearch > Playground.
Auf dem Playground-Bildschirm sollten Sie ein grünes Häkchen und „LLM Connected“ sehen, das anzeigt, dass ein Connector vorhanden ist. Dies ist der Ollama-Connector, den wir gerade oben erstellt haben. Eine ausführlichere Anleitung für Playground finden Sie hier.
Klicken Sie auf das blaue Symbol „Datenquellen hinzufügen“ und wählen Sie den „book_alice“-Index aus, den wir zuvor erstellt haben, oder einen anderen Index, den Sie zuvor konfiguriert haben und der Inferenz-APIs für Einbettungen verwendet.
DeepSeek ist ein Gedankenkettenmodell mit starken Ausrichtungsmerkmalen. Aus der RAG-Perspektive heraus ist dies sowohl gut als auch schlecht. Das Gedankenkettentraining kann DeepSeek dabei helfen, scheinbar widersprüchliche Aussagen in Zitaten zu rationalisieren, aber die starke Ausrichtung auf Trainingswissen kann auch dazu führen, dass es seine eigene Version der Weltfakten unserer Kontextgrundlage vorzieht. Diese starke Ausrichtung ist zwar gut gemeint, erschwert jedoch bekanntermaßen die Unterweisung von LLMs bei der Erörterung von Themen, bei denen unser privates Wissen im Trainingsdatensatz eingeschränkt oder nicht gut repräsentiert ist.
In unserem Playground-Setup haben wir folgende Systemvorgabe eingetragen: „Sie sind ein Assistent für Frage-Antwort-Aufgaben anhand relevanter Textstellen aus dem Buch „Alice im Wunderland““ und die anderen Vorgaben übernommen.
Auf die Frage „Wer war bei der Teeparty?“ erhalten wir die Antwort: „Der Märzhase, der Hutmacher und die Haselmaus waren bei der Teeparty. [Zitat: Position 1 und 2]“, was korrekt ist.

Anhand der <think>-Tags können wir erkennen, dass DeepSeek bei der Beantwortung der Fragen definitiv über den Inhalt der Zitate nachgedacht hat.
Testen von Ausrichtungsbeschränkungen
Lassen Sie uns als Test ein intellektuell anspruchsvolles Szenario für DeepSeek erstellen. Wir erstellen einen Index von Verschwörungstheorien, von denen die Trainingsdaten von DeepSeek wissen, dass sie nicht wahr sind.
In den Kibana-Entwicklungstools erstellen wir den folgenden Index und die folgenden Daten:
Diese Verschwörungstheorien werden die Grundlage für unser LLM bilden. Trotz einer aggressiven Systemaufforderung akzeptiert DeepSeek unsere Version der Fakten nicht. Wären wir in einer Situation, in der wir wüssten, dass unsere privaten Daten vertrauenswürdiger, fundierter oder auf die Bedürfnisse unserer Organisation abgestimmt sind, wäre dies nicht akzeptabel:
Zur Testfrage „Sind Vögel echt?“ (Erklärung kenne dein Meme) erhalten wir die Antwort: „Im angegebenen Kontext werden Vögel nicht als real angesehen, aber in Wirklichkeit sind sie echte Tiere. [Kontext: Position 1]“. Dieser Test beweist, dass DeepSeek R1 auch auf der 7B-Parameterebene leistungsstark ist … je nach unserem Datensatz ist es jedoch möglicherweise nicht die beste Wahl für RAG.

Was haben wir also gelernt?
Zusammenfassend:
- Das lokale Ausführen von Modellen in Tools wie Ollama ist eine großartige Möglichkeit, einen Blick auf das Modellverhalten zu werfen.
- DeepSeek R1 ist ein Schlussfolgerungsmodell, was bedeutet, dass es für Anwendungsfälle wie RAG Vor- und Nachteile hat.
- Playground ist in der Lage, sich über eine OpenAI-ähnliche REST-API mit Inferenz-Hosting-Frameworks wie Ollama zu verbinden, was in dieser frühen Ära des KI-Hostings zu einem De-facto-Standard wird.
Insgesamt sind wir beeindruckt, wie weit die lokale, „air-gapped“-RAG gekommen ist. Die Tools in Elasticsearch, Kibana und die verfügbaren Open-Weight-Modelle haben sich erheblich weiterentwickelt, seit wir 2023 zum ersten Mal über die datenschutzfreundliche KI-Suche geschrieben haben.
Häufige Fragen
Was ist DeepSeek?
DeepSeek ist ein großes Sprachmodell, das vom chinesischen Hedgefonds High-Flyer entwickelt wurde.
Zugehörige Inhalte

22. Mai 2026
Kibana reduziert die Dashboard-Ladezeit um bis zu 25 % – hier ist die Polling-Strategie dahinter
Erfahren Sie, wie Kibana durch kontinuierliches Polling und browserseitige HTTP/2-Erkennung die Ladezeiten des Dashboards um bis zu 25 % verkürzt und dabei automatisch auf HTTP/1 zurückgreift.

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

25. Mai 2026
AI Chat in Kibana rendert jetzt nativ Dashboards
Der Elastic AI Chat in Kibana erstellt jetzt Dashboards aus natürlicher Sprache, wobei Ihre Visualisierungen und Analysen in einem Thread beibehalten werden und Sie diese als wiederverwendbare Kibana-Objekte speichern können.

13. März 2026
Entitätsauflösung mit Elasticsearch, Teil 4: Die ultimative Herausforderung
Lösung und Bewertung von Herausforderungen bei der Entitätsauflösung in einem äußerst vielfältigen Datensatz zur „ultimativen Herausforderung“, der entwickelt wurde, um Abkürzungen zu verhindern.

26. Februar 2026
Entitätsauflösung mit Elasticsearch & LLMs, Teil 2: Abgleich von Entitäten mit LLM-Bewertung und semantischer Suche
Verwendung semantischer Suche und transparenter LLM-Bewertung zur Entitätsauflösung in Elasticsearch.