Kibana Lens macht das Erstellen von Dashboards per Drag & Drop sehr einfach, aber wenn man Dutzende von Panels benötigt, summieren sich die Klicks. Was wäre, wenn Sie ein Dashboard skizzieren, einen Screenshot davon machen und einen LLM den gesamten Prozess für Sie abschließen lassen könnten?
In diesem Artikel werden wir genau das tun. Wir werden eine Anwendung erstellen, die ein Bild eines Dashboards aufnimmt, unsere Mappings analysiert und anschließend ein Dashboard generiert, ohne dass wir Kibana überhaupt berühren müssen!
Schritte:
Hintergrund und Anwendungsablauf
Mein erster Gedanke war, den LLM das gesamte NDJSON-Format der in Kibana gespeicherten Objekte generieren zu lassen und sie dann in Kibana zu importieren.
Wir haben eine Handvoll Modelle ausprobiert:
- Gemini 2.5 Pro
- GPT o3 / o4-mini-hoch / 4.1
- Claude 4 Sonett
- Grok 3
- Deepseek (Deepthink R1)
Und als Anregungen begannen wir mit ganz einfachen Dingen:
Trotz der Durchsicht einiger weniger Beispiele und detaillierter Erklärungen zum Aufbau der einzelnen Visualisierungen hatten wir keinen Erfolg. Wenn Sie an diesem Experiment interessiert sind, finden Sie hier weitere Informationen.
Das Ergebnis dieser Vorgehensweise war, dass beim Versuch, die vom LLM erzeugten Dateien in Kibana hochzuladen, diese Meldungen angezeigt wurden:


Das bedeutet, dass das generierte JSON ungültig oder schlecht formatiert ist. Die häufigsten Probleme waren, dass der LLM unvollständiges NDJSON erzeugte, Parameter falsch interpretierte oder normales JSON anstelle von NDJSON zurückgab, egal wie sehr wir uns bemühten, das Gegenteil zu erzwingen.
Inspiriert von diesem Artikel – in dem Suchvorlagen besser funktionierten als LLM Freestyle – entschieden wir uns, dem LLM Vorlagen zu übergeben, anstatt die vollständige NDJSON-Datei generieren zu lassen und anschließend im Code die vom LLM bereitgestellten Parameter zur Erstellung der Visualisierungen zu verwenden. Dieser Ansatz hat sich bewährt und ist vorhersehbar und erweiterbar, da nun der Code und nicht mehr das LLM die Hauptarbeit übernimmt.
Der Bewerbungsprozess wird wie folgt ablaufen:
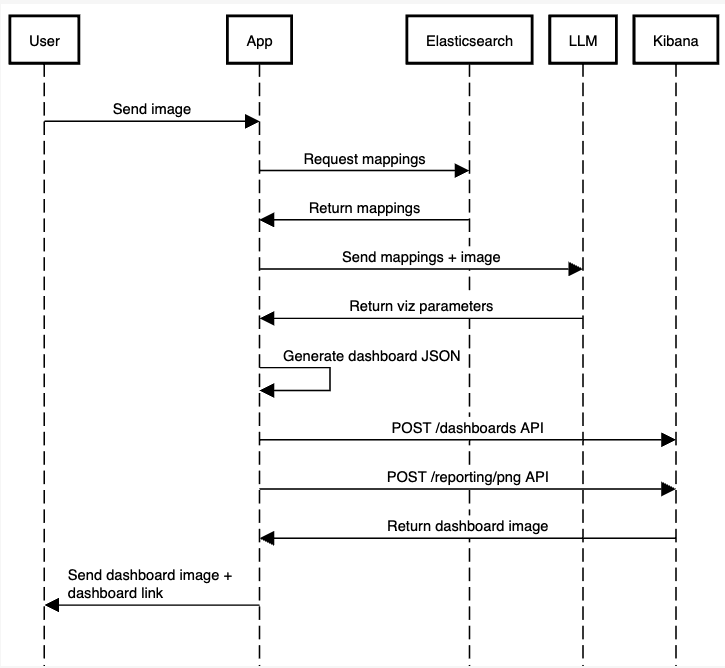
Der Einfachheit halber lassen wir einige Codeabschnitte weg, aber den vollständigen, lauffähigen Code der Anwendung finden Sie in diesem Notebook.
Voraussetzungen
Bevor Sie mit der Entwicklung beginnen, benötigen Sie Folgendes:
- Python 3.8 oder höher
- Eine Venv Python-Umgebung
- Eine laufende Elasticsearch-Instanz, zusammen mit ihrem Endpunkt und API-Schlüssel
- Ein OpenAI-API-Schlüssel, der unter dem Umgebungsvariablennamen OPENAI_API_KEY gespeichert ist:
Daten vorbereiten
Für die Daten halten wir es einfach und verwenden Elastic-Beispiel-Weblogs. Hier erfahren Sie, wie Sie diese Daten in Ihren Cluster importieren.
Jedes Dokument enthält Angaben zum Host, der die Anfragen an die Anwendung gestellt hat, sowie Informationen zur Anfrage selbst und deren Antwortstatus. Nachfolgend finden Sie ein Beispieldokument:
Nun holen wir uns die Zuordnungen des soeben geladenen Index, kibana_sample_data_logs:
Wir werden die Zuordnungen zusammen mit dem Bild übergeben, das wir später laden werden.
LLM-Konfiguration
Konfigurieren wir das LLM so, dass es strukturierte Ausgabe verwendet, um ein Bild einzugeben und ein JSON mit den Informationen zu erhalten, die wir an unsere Funktion übergeben müssen, um die JSON-Objekte zu erzeugen.
Wir installieren die Abhängigkeiten:
Elasticsearch wird uns dabei helfen, die Indexzuordnungen abzurufen. Pydantic ermöglicht es uns, Schemata in Python zu definieren, denen der LLM dann folgen soll, und LangChain ist das Framework, das den Aufruf von LLMs und KI-Tools vereinfacht.
Wir werden ein Pydantic-Schema erstellen, um die gewünschte Ausgabe des LLM zu definieren. Aus dem Bild müssen wir den Diagrammtyp, das Feld, den Visualisierungstitel und den Dashboard-Titel ablesen:
Als Bildeingabe senden wir ein Dashboard, das ich gerade gezeichnet habe:
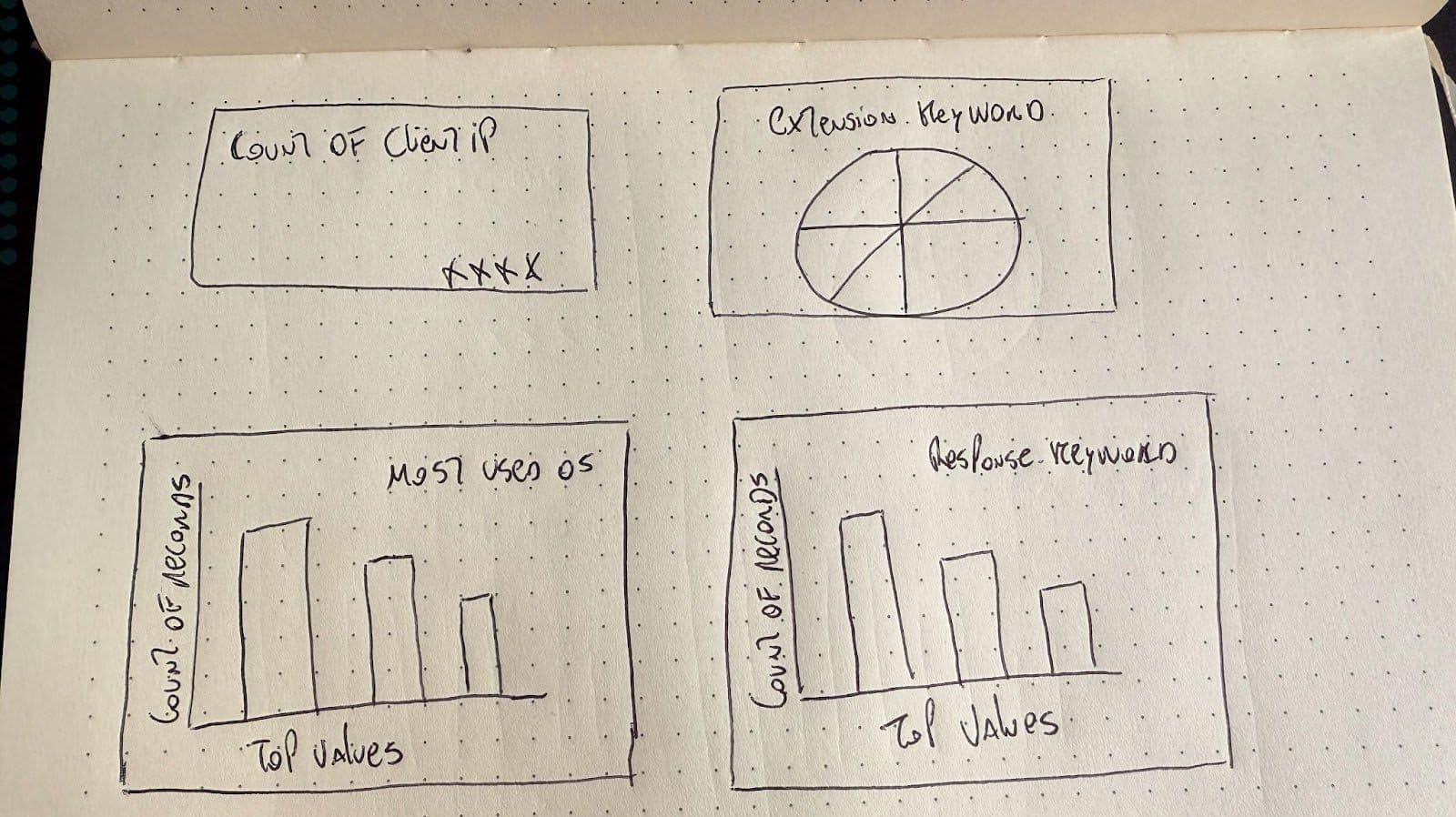
Nun deklarieren wir den LLM-Modellaufruf und das Laden des Bildes. Diese Funktion erhält die Zuordnungen des Elasticsearch-Index und ein Bild des Dashboards, das wir generieren möchten.
Mit with_structured_output können wir unser Pydantic Dashboard Schema als Antwortobjekt verwenden, das der LLM erzeugen wird. Mit Pydantic können wir Datenmodelle mit Validierung definieren, wodurch sichergestellt wird, dass die LLM-Ausgabe der erwarteten Struktur entspricht.
Um das Bild in Base64 zu konvertieren und als Eingabe zu senden, können Sie einen Online-Konverter verwenden oder dies im Code erledigen.
Der LLM verfügt bereits über Kontextinformationen zu Kibana-Dashboards, daher müssen wir nicht alles in der Eingabeaufforderung erklären, sondern nur einige Details, um sicherzustellen, dass er nicht vergisst, dass er mit Elasticsearch und Kibana arbeitet.
Lassen Sie uns die Aufgabenstellung aufschlüsseln:
| Abschnitt | Grund |
|---|---|
| Sie sind Experte in der Analyse von Kibana-Dashboards anhand von Images für die Version 9.0.0 von Kibana. | Durch die Verstärkung dieser Funktion wird Elasticsearch und die Verwendung der Elasticsearch-Version unterstützt, wodurch die Wahrscheinlichkeit verringert wird, dass das LLM alte/ungültige Parameter fälschlicherweise annimmt. |
| Sie erhalten ein Dashboard-Bild und eine Elasticsearch-Indexzuordnung. | Wir erklären, dass es sich bei dem Bild um Dashboards handelt, um Fehlinterpretationen seitens des LLM zu vermeiden. |
| Nachfolgend finden Sie die Indexzuordnungen für den Index, auf dem das Dashboard basiert. Nutzen Sie diese, um die Daten und die verfügbaren Felder besser zu verstehen. Indexzuordnungen: {index_mappings} | Es ist entscheidend, die Zuordnungen bereitzustellen, damit das LLM dynamisch gültige Felder auswählen kann. Andernfalls könnten wir die Zuordnungen hier fest codieren, was zu starr wäre, oder uns darauf verlassen, dass das Bild die richtigen Feldnamen enthält, was nicht zuverlässig ist. |
| Beschränken Sie sich auf die Felder, die für die jeweilige Visualisierung relevant sind, basierend auf dem, was im Bild sichtbar ist. | Wir mussten diese Verstärkung hinzufügen, weil manchmal versucht wird, Felder hinzuzufügen, die nicht zum Bild gehören. |
Dies gibt ein Objekt mit einem Array von anzuzeigenden Visualisierungen zurück:
Verarbeitung der LLM-Antwort
Wir Wir haben ein Beispiel-Dashboard mit 2x2-Panels erstellt und es dann mithilfe der Get a dashboard API im JSON-Format exportiert. Anschließend haben wir die Panels als Visualisierungsvorlagen (Kreisdiagramm, Balkendiagramm, Metrikdiagramm) gespeichert, in denen wir einige der Parameter ersetzen können, um je nach Fragestellung neue Visualisierungen mit anderen Feldern zu erstellen.
Die JSON-Vorlagedateien können Sie hier einsehen. Beachten Sie, wie wir die Objektwerte, die wir später ersetzen möchten, durch {variable_name}ersetzt haben.

Anhand der von LLM bereitgestellten Informationen können wir entscheiden, welche Vorlage wir verwenden und welche Werte wir ersetzen.
fill_template_with_analysis empfängt die Parameter für ein einzelnes Panel, einschließlich der JSON-Vorlage der Visualisierung, eines Titels, eines Feldes und der Koordinaten der Visualisierung im Raster.
Anschließend werden die Werte der Vorlage ersetzt und die endgültige JSON-Visualisierung zurückgegeben.
Um es einfach zu halten, verwenden wir statische Koordinaten, die wir den vom LLM erstellten Panels zuweisen, und erzeugen so ein 2x2-Raster-Dashboard wie in der obigen Abbildung dargestellt.
Je nach dem vom LLM festgelegten Visualisierungstyp wählen wir eine JSON-Dateivorlage aus und ersetzen die relevanten Informationen durch fill_template_with_analysis . Anschließend fügen wir das neue Panel einem Array hinzu, das wir später zum Erstellen des Dashboards verwenden.
Sobald das Dashboard fertig ist, verwenden wir die „Create a dashboard“-API , um die neue JSON-Datei an Kibana zu übertragen und das Dashboard zu generieren:
Um das Skript auszuführen und das Dashboard zu generieren, führen Sie folgenden Befehl in der Konsole aus:
Das Endergebnis wird folgendermaßen aussehen:

Dashboard-URL: https://your-kibana-url/app/dashboards#/view/generated-dashboard-id
Dashboard-ID: generated-dashboard-id
Fazit
LLMs zeigen ihre ausgeprägten visuellen Fähigkeiten bei der Umwandlung von Text in Code oder der Umwandlung von Bildern in Code. Die Dashboards-API ermöglicht es auch, JSON-Dateien in Dashboards umzuwandeln, und mit einem LLM und etwas Code können wir Bilder in ein Kibana-Dashboard umwandeln.
Der nächste Schritt besteht darin, die Flexibilität der Dashboard-Visualisierungen durch die Verwendung unterschiedlicher Rastereinstellungen, Dashboard-Größen und -Positionen zu verbessern. Darüber hinaus wäre die Unterstützung komplexerer Visualisierungen und Visualisierungstypen eine sinnvolle Ergänzung dieser Anwendung.
Zugehörige Inhalte

22. Mai 2026
Kibana reduziert die Dashboard-Ladezeit um bis zu 25 % – hier ist die Polling-Strategie dahinter
Erfahren Sie, wie Kibana durch kontinuierliches Polling und browserseitige HTTP/2-Erkennung die Ladezeiten des Dashboards um bis zu 25 % verkürzt und dabei automatisch auf HTTP/1 zurückgreift.

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

25. Mai 2026
AI Chat in Kibana rendert jetzt nativ Dashboards
Der Elastic AI Chat in Kibana erstellt jetzt Dashboards aus natürlicher Sprache, wobei Ihre Visualisierungen und Analysen in einem Thread beibehalten werden und Sie diese als wiederverwendbare Kibana-Objekte speichern können.

13. März 2026
Entitätsauflösung mit Elasticsearch, Teil 4: Die ultimative Herausforderung
Lösung und Bewertung von Herausforderungen bei der Entitätsauflösung in einem äußerst vielfältigen Datensatz zur „ultimativen Herausforderung“, der entwickelt wurde, um Abkürzungen zu verhindern.

26. Februar 2026
Entitätsauflösung mit Elasticsearch & LLMs, Teil 2: Abgleich von Entitäten mit LLM-Bewertung und semantischer Suche
Verwendung semantischer Suche und transparenter LLM-Bewertung zur Entitätsauflösung in Elasticsearch.