Beobachten, schützen und durchsuchen Sie Ihre Daten mit einer einzigen Lösung. Von der Anwendungsüberwachung bis zur Bedrohungserkennung – Kibana ist Ihre vielseitige Plattform für kritische Anwendungsfälle. Starten Sie jetzt Ihre kostenlose 14-tägige Testphase.
Kürzlich haben wir einen Blogbeitrag veröffentlicht, in dem wir die Verwendung der neuen Geodaten-Suchfunktionen in ES|QL, der neuen, leistungsstarken Abfragesprache von Elasticsearch, beschreiben. Um diese Funktionen nutzen zu können, benötigen Sie Geodaten in Elasticsearch. In diesem Blogbeitrag zeigen wir Ihnen, wie Sie Geodaten einlesen und in ES|QL-Abfragen verwenden.

Importieren von Geodaten mit Kibana
Die Daten, die wir für die Beispiele im vorherigen Blog verwendet haben, basierten auf Daten, die wir intern für Integrationstests verwenden. Zu Ihrer Bequemlichkeit haben wir es hier in Form einiger CSV-Dateien beigefügt, die Sie problemlos mit Kibana importieren können. Die Daten setzen sich aus Flughäfen, Städten und Stadtgrenzen zusammen. Sie können die Daten hier herunterladen:
- airports.csv
- Dies beinhaltet die Zusammenführung von drei Datensätzen:
- Flughäfen (Namen, Standorte und zugehörige Daten) von Natural Earth
- Stadtstandorte von SimpleMaps
- Flughafenhöhen aus der globalen Flughafendatenbank
- Dies beinhaltet die Zusammenführung von drei Datensätzen:
- airport_city_boundaries.csv
- Dies beinhaltet eine Zusammenführung der oben genannten Flughafen- und Städtenamen mit einer neuen Quelle:
- Stadtgrenzen aus OpenStreetMap
- Dies beinhaltet eine Zusammenführung der oben genannten Flughafen- und Städtenamen mit einer neuen Quelle:
Wie Sie sich vorstellen können, haben wir einige Zeit damit verbracht, diese Datenquellen in den beiden oben genannten Dateien zusammenzuführen, mit dem Ziel, die Geodatenfunktionen von ES|QL testen zu können. Dies entspricht möglicherweise nicht ganz Ihren spezifischen Datenanforderungen, aber hoffentlich gibt Ihnen dies eine Vorstellung davon, was möglich ist. Insbesondere möchten wir einige interessante Dinge demonstrieren:
- Importieren von Daten mit Geodatenfeldern zusammen mit anderen indexierbaren Daten
- Importieren von
geo_pointundgeo_shape-Daten und deren gemeinsame Verwendung in Abfragen - Importieren von Daten in zwei Indizes, die über eine räumliche Beziehung verknüpft werden können
- Erstellung einer Ingest-Pipeline zur Erleichterung zukünftiger Importe (über Kibana hinaus)
- Einige Beispiele für Ingest-Prozessoren, wie
csv,convertundsplit
In diesem Blogbeitrag geht es zwar um die Arbeit mit CSV-Daten, aber es ist wichtig zu verstehen, dass es mehrere Möglichkeiten gibt, Geodaten mit Kibana hinzuzufügen . Innerhalb der Kartenanwendung können Sie durch Trennzeichen getrennte Daten wie CSV, GeoJSON und ESRI ShapeFiles hochladen und auch direkt in der Karte Formen zeichnen. In diesem Blogbeitrag konzentrieren wir uns auf den Import von CSV-Dateien von der Kibana-Startseite.
Import der Flughäfen
Die erste Datei, airports.csv, hat einige interessante Eigenheiten, mit denen wir uns auseinandersetzen müssen. Erstens weisen die Spalten zusätzliche Leerzeichen als Trennzeichen auf, was für CSV-Dateien untypisch ist. Zweitens handelt es sich bei dem Feld type um ein Mehrwertfeld, das wir in separate Felder aufteilen müssen. Schließlich handelt es sich bei einigen Feldern nicht um Zeichenketten, sondern um Felder, die in den richtigen Datentyp konvertiert werden müssen. All dies kann mithilfe der CSV-Importfunktion von Kibana erfolgen.

Beginnen Sie auf der Kibana-Startseite. Es gibt einen Abschnitt mit dem Titel „Erste Schritte durch Hinzufügen von Integrationen“, der einen Link mit der Bezeichnung „Datei hochladen“ enthält:
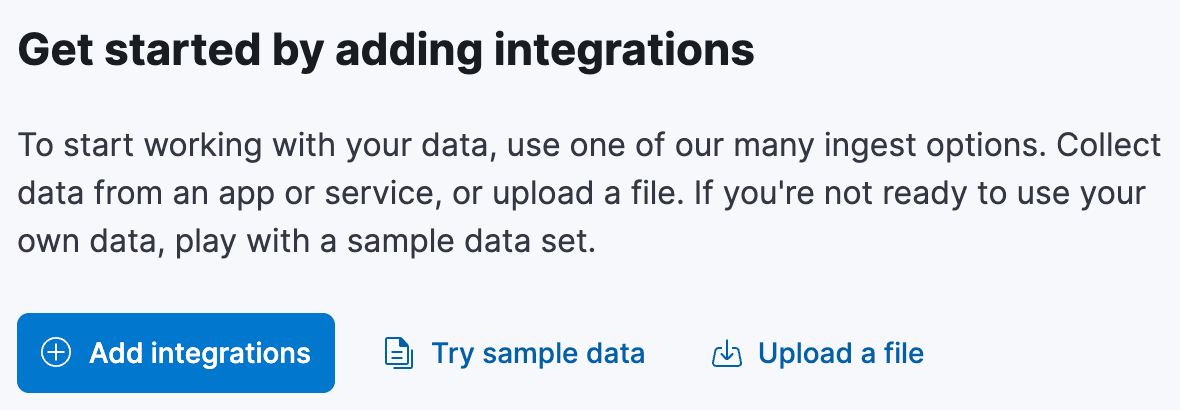
Klicken Sie auf diesen Link, und Sie gelangen zur Seite „Datei hochladen“. Hier können Sie die airports.csv -Datei per Drag & Drop einfügen. Kibana analysiert die Datei und zeigt Ihnen eine Vorschau der Daten an. Das System hätte das Trennzeichen automatisch als Komma und die erste Zeile als Kopfzeile erkennen sollen. Allerdings wurden vermutlich weder die zusätzlichen Leerzeichen zwischen den Spalten entfernt, noch wurden die Typen der Felder bestimmt, da angenommen wurde, dass alle Felder entweder text oder keyword sind. Das müssen wir beheben.

Klicken Sie auf Override settings und aktivieren Sie das Kontrollkästchen für Should trim fields, und anschließend Apply um die Einstellungen zu schließen. Nun müssen wir die Datentypen der Felder korrigieren. Dies ist auf der nächsten Seite verfügbar, also klicken Sie bitte auf Import.

Wählen Sie zuerst einen Indexnamen aus und anschließend Advanced , um zur Seite für Feldzuordnungen und Datenverarbeitung zu gelangen.

Hier müssen wir sowohl die Feldzuordnungen für den Index als auch die Datenaufnahmepipeline anpassen. Erstens hat Kibana wahrscheinlich das Feld scalerank automatisch als long erkannt, aber die Felder location und city_location fälschlicherweise als keyword interpretiert. Ändern Sie sie in geo_point, sodass die Zuordnungen am Ende etwa so aussehen:
Sie haben hier eine gewisse Flexibilität, aber beachten Sie, dass die Wahl des Typs Einfluss darauf hat, wie das Feld indiziert wird und welche Art von Abfragen möglich ist. Wenn Sie beispielsweise location auf keyword belassen, können Sie keine Geodaten-Suchanfragen darauf durchführen. Wenn Sie elevation als text belassen, können Sie keine numerischen Bereichsabfragen darauf durchführen.
Jetzt ist es an der Zeit, die Datenaufnahmepipeline zu reparieren. Falls Kibana scalerank automatisch als long erkannt hat, wurde außerdem ein Prozessor hinzugefügt, um das Feld in long umzuwandeln. Wir müssen einen ähnlichen Prozessor für das Feld elevation hinzufügen, der es diesmal in double umwandelt. Bearbeiten Sie die Pipeline, um sicherzustellen, dass diese Konvertierung vorhanden ist. Bevor wir dies speichern, möchten wir noch eine weitere Konvertierung durchführen, um das Feld type in mehrere Felder aufzuteilen. Fügen Sie der Pipeline einen split -Prozessor mit folgender Konfiguration hinzu:
Die finale Datenaufnahmepipeline sollte wie folgt aussehen:
Beachten Sie, dass wir keinen Konvertierungsprozessor für die Felder location und city_location hinzugefügt haben. Dies liegt daran, dass der Typ geo_point in der Feldzuordnung das WKT- Format der Daten in diesen Feldern bereits versteht. Der Typ geo_point versteht eine Reihe von Formaten, darunter WKT, GeoJSON und mehr. Wenn wir beispielsweise zwei Spalten in der CSV-Datei für latitude und longitude hätten, hätten wir entweder einen script oder einen set Prozessor hinzufügen müssen, um diese zu einem einzigen geo_point Feld zu kombinieren (z. B. "set": {"field": "location", "value": "{{lat}},{{lon}}"}).
Wir sind nun bereit, die Datei zu importieren. Klicken Sie auf Import , und die Daten werden mit den soeben definierten Mappings und der Ingest-Pipeline in den Index importiert. Sollten beim Einlesen der Daten Fehler auftreten, werden diese von Kibana hier gemeldet, sodass Sie entweder die Quelldaten oder die Einlesepipeline bearbeiten und es erneut versuchen können.
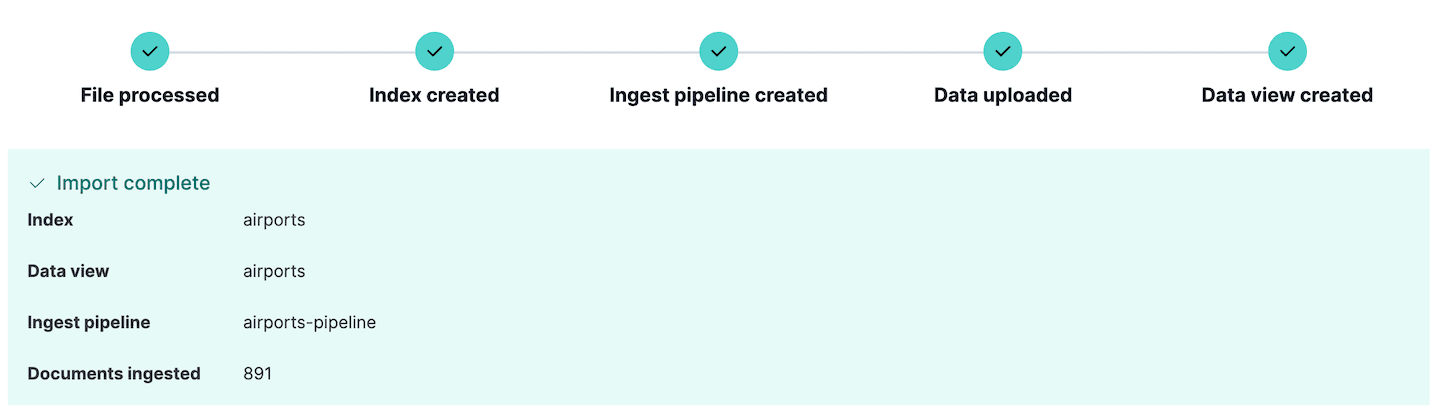
Beachten Sie, dass eine neue Aufnahmepipeline erstellt wurde. Dies kann angezeigt werden, indem man im Kibana-Bereich Stack Management auf die Option Ingest pipelines klickt. Hier können Sie die soeben erstellte Pipeline sehen und sie bei Bedarf bearbeiten. Tatsächlich kann der Abschnitt Ingest pipelines zum Erstellen und Testen von Ingest-Pipelines verwendet werden, eine sehr nützliche Funktion, wenn Sie noch komplexere Ingests planen.
Wenn Sie diese Daten sofort erkunden möchten, springen Sie zu den späteren Abschnitten. Wenn Sie aber auch die Stadtgrenzen importieren möchten, lesen Sie weiter.
Importieren der Stadtgrenzen
Die unter airport_city_boundaries.csv verfügbare Datei mit den Stadtgrenzen ist etwas einfacher zu importieren als das vorherige Beispiel. Es enthält ein city_boundary Feld, das eine WKT-Darstellung der Stadtgrenze als POLYGON ist, und ein city_location Feld, das eine geo_point Darstellung des Stadtstandorts ist. Wir können diese Daten auf ähnliche Weise wie die Flughafendaten importieren, allerdings mit einigen Unterschieden:
- Wir mussten die Überschreibungseinstellung
Has header rowauswählen, da diese nicht automatisch erkannt wurde. - Wir mussten keine Felder kürzen, da die Daten bereits frei von überflüssigen Leerzeichen waren.
- Wir mussten die Datenaufnahmepipeline nicht bearbeiten, da alle Datentypen entweder Zeichenketten oder räumliche Datentypen waren.
- Wir mussten jedoch die Feldzuordnungen bearbeiten, um das Feld
city_boundaryaufgeo_shapeund das Feldcity_locationauf zu setzen.geo_point
Unsere endgültigen Feldzuordnungen sahen wie folgt aus:
Wie beim Import mit airports.csv zuvor, klicken Sie einfach auf Import , um die Daten in den Index zu importieren. Die Daten werden mit den von uns bearbeiteten Mappings und der von Kibana definierten Ingest-Pipeline importiert.
Erkundung von Geodaten mit Entwicklerwerkzeugen
In Kibana ist es üblich, die indizierten Daten mit dem Befehl „Discover“ zu erkunden. Wenn Sie jedoch Ihre eigene Anwendung mit ES|QL-Abfragen schreiben möchten, könnte es interessanter sein, auf die reine Elasticsearch-API zuzugreifen. Kibana verfügt über eine komfortable Konsole zum Experimentieren mit dem Schreiben von Abfragen. Dies wird als Dev Tools -Konsole bezeichnet und befindet sich in der Kibana-Seitenleiste. Diese Konsole kommuniziert direkt mit dem Elasticsearch-Cluster und kann zum Ausführen von Abfragen, Erstellen von Indizes und vielem mehr verwendet werden.
Versuchen Sie Folgendes:
Dies sollte folgende Ergebnisse liefern:
| Distanz | Abkürzung | Name | Ort | Land | Stadt | Elevation |
|---|---|---|---|---|---|---|
| 273418.05776847183 | SCHINKEN | Hamburg | PUNKT (10.005647830925 53.6320011640866) | Deutschland | Norderstedt | 17.0 |
| 337534.653466062 | TXL | Berlin-Tegel Int'l | PUNKT (13.2903090925074 52.5544287044101) | Deutschland | Hohen Neuendorf | 38,0 |
| 483713.15032266214 | OSL | Oslo Gardermoen | Punkt (11.0991032762581 60.1935783171386) | Norwegen | Oslo | 208.0 |
| 522538.03148094116 | BMA | Bromma | PUNKT (17.9456175406145 59.3555902065112) | Schweden | Stockholm | 15.0 |
| 522538.03148094116 | ARN | Arlanda | Punkt (17.9307299016916 59.6511203397372) | Schweden | Stockholm | 38,0 |
| 624274.8274399083 | DUS | Düsseldorf Int'l | PUNKT (6,76494446612174 51,2781820420774) | Deutschland | Düsseldorf | 45,0 |
| 633388.6966435644 | PRG | Ruzyn | PUNKT (14.2674849854076 50.1076511703671) | Tschechien | Prag | 381,0 |
| 635911.1873311149 | AMS | Schiphol | Punkt (4,76437693232812 52,3089323889822) | Niederlande | Hoofddorp | -3.0 |
| 670864.137958866 | FRA | Frankfurt International | PUNKT (8.57182286907608 50.0506770895207) | Deutschland | Frankfurt | 111,0 |
| 683239.2529970079 | WAW | Okecie Int'l | Punkt (20.9727263383587 52.171026749259) | Polen | Piaseczno | 111,0 |
Visualisierung von Geodaten mit Kibana Maps
Kibana Maps ist ein leistungsstarkes Werkzeug zur Visualisierung von Geodaten. Es kann verwendet werden, um Karten mit mehreren Ebenen zu erstellen, wobei jede Ebene einen anderen Datensatz darstellt. Die Daten können auf verschiedene Weise gefiltert, aggregiert und formatiert werden. In diesem Abschnitt zeigen wir Ihnen, wie Sie in Kibana Maps eine Karte mit den Daten erstellen, die wir im vorherigen Abschnitt importiert haben.
Navigieren Sie im Kibana-Menü zu Analytics->Maps , um eine neue Kartenansicht zu öffnen. Klicken Sie auf Add Layer und wählen Sie Documents aus, wählen Sie die Datenansicht airports und bearbeiten Sie dann den Ebenenstil, um die Markierungen mithilfe des Feldes elevation einzufärben, damit wir leicht erkennen können, wie hoch jeder Flughafen liegt.
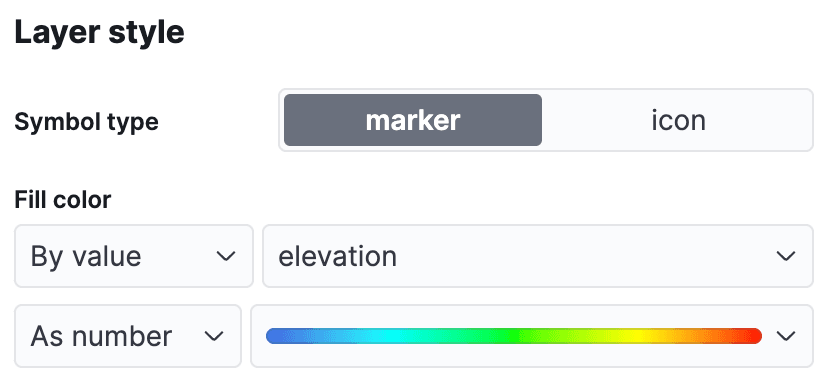
Klicken Sie auf „Änderungen beibehalten“, um die Karte zu speichern:

Fügen Sie nun eine zweite Ebene hinzu und wählen Sie diesmal die Datenansicht airport_city_boundaries aus. Dieses Mal verwenden wir das Feld city_boundary , um die Ebene zu gestalten, und stellen die Füllfarbe auf ein helles Blau ein. Dadurch werden die Stadtgrenzen auf der Karte angezeigt. Achten Sie darauf, die Ebenen neu anzuordnen, damit die Flughafenmarkierungen ganz oben liegen.

Räumliche Verknüpfungen
ES|QL unterstützt keine JOIN -Befehle, aber mit dem ENRICH -Befehl lässt sich ein Sonderfall eines Joins realisieren. Dieser Befehl funktioniert ähnlich wie ein „Left Join“ in SQL und ermöglicht es Ihnen, Ergebnisse aus einem Index mit Daten aus einem anderen Index anzureichern, basierend auf einer räumlichen Beziehung zwischen den beiden Datensätzen.
Nehmen wir beispielsweise an, wir reichern die Ergebnisse einer Tabelle mit Flughäfen um zusätzliche Informationen über die jeweilige Stadt an, indem wir die Stadtgrenze ermitteln, die den Flughafenstandort enthält, und führen dann einige statistische Auswertungen der Ergebnisse durch:
Wenn Sie diese Abfrage ausführen, ohne vorher den Anreicherungsindex vorzubereiten, erhalten Sie eine Fehlermeldung wie:
Dies liegt daran, dass ES|QL, wie bereits erwähnt, keine echten JOIN -Befehle unterstützt. Ein wichtiger Grund dafür ist, dass Elasticsearch ein verteiltes System ist und Joins aufwändige Operationen sind, die schwer zu skalieren sind. Der Befehl ENRICH kann jedoch sehr effizient sein, da er speziell vorbereitete Anreicherungsindizes nutzt, die im gesamten Cluster dupliziert werden, wodurch lokale Joins auf jedem Knoten durchgeführt werden können.
Um dies besser zu verstehen, konzentrieren wir uns auf den Befehl ENRICH in der obigen Abfrage:
Dieser Befehl weist Elasticsearch an, die aus dem Index airports abgerufenen Ergebnisse anzureichern und einen Join intersects zwischen dem Feld city_location des ursprünglichen Index und dem Feld city_boundary des Index airport_city_boundaries durchzuführen, den wir bereits in einigen Beispielen verwendet haben. Einige dieser Informationen sind in dieser Abfrage jedoch nicht klar ersichtlich. Was wir sehen, ist der Name einer Anreicherungsrichtlinie city_boundaries, und die fehlenden Informationen sind in dieser Richtliniendefinition enthalten.
Hier sehen wir, dass eine geo_match -Abfrage durchgeführt wird (intersects ist der Standardwert), das Feld, mit dem abgeglichen werden soll, ist city_boundary, und die enrich_fields sind die Felder, die wir dem Originaldokument hinzufügen möchten. Eines dieser Felder, nämlich region wurde tatsächlich als Gruppierungsschlüssel für den Befehl STATS verwendet, was ohne diese 'left join'-Funktion nicht möglich gewesen wäre. Weitere Informationen zu Anreicherungsrichtlinien finden Sie in der Anreicherungsdokumentation.
Die Anreicherungsindizes und -richtlinien in Elasticsearch wurden ursprünglich für die Anreicherung von Daten während der Indexierung entwickelt, wobei Daten aus einem anderen vorbereiteten Anreicherungsindex verwendet wurden. In ES|QL hingegen funktioniert der Befehl ENRICH zur Abfragezeit und erfordert keine Verwendung von Ingest-Pipelines. Dadurch ähnelt es im Prinzip einem SQL LEFT JOIN, nur dass man nicht beliebige zwei Indizes verknüpfen kann, sondern nur einen normalen Index auf der linken Seite mit einem speziell vorbereiteten Anreicherungsindex auf der rechten Seite.
In beiden Fällen, ob für Ingest-Pipelines oder die Verwendung in ES|QL, müssen einige vorbereitende Schritte durchgeführt werden, um den Anreicherungsindex und die Richtlinie einzurichten. Wir haben den Index airport_city_boundaries bereits oben importiert, dieser kann jedoch nicht direkt als Anreicherungsindex im Befehl ENRICH verwendet werden. Zunächst müssen wir zwei Schritte durchführen:
- Erstellen Sie die oben beschriebene Anreicherungsrichtlinie, um den Quellindex, das Feld im Quellindex, mit dem abgeglichen werden soll, und die Felder, die nach dem Abgleich zurückgegeben werden sollen, zu definieren.
- Führen Sie diese Richtlinie aus, um den Anreicherungsindex zu erstellen. Dabei wird ein spezieller interner Index erstellt, indem der ursprüngliche Quellindex in eine effizientere Datenstruktur eingelesen und anschließend im gesamten Cluster kopiert wird.
Die Anreicherungsrichtlinie kann mit folgendem Befehl erstellt werden:
Die Richtlinie kann mit folgendem Befehl ausgeführt werden:
Beachten Sie, dass Sie diese Richtlinie erneut ausführen müssen, wenn Sie den Inhalt des Index airport_city_boundaries ändern, damit die Änderungen im Anreicherungsindex sichtbar werden. Führen wir nun die ursprüngliche ES|QL-Abfrage erneut aus:
Dies liefert die Top 5 Regionen mit den meisten Flughäfen, zusammen mit dem Schwerpunkt aller Flughäfen, die übereinstimmenden Regionen zugeordnet sind, und der Längenspanne der WKT-Darstellung der Stadtgrenzen innerhalb dieser Regionen:
| Schwerpunkt | Anzahl | Region |
|---|---|---|
| PUNKT (-12.139086859300733 31.024386116624648) | 126 | null |
| PUNKT (-83.10398317873478 42.300230911932886) | 3 | Detroit |
| Punkt (39.74537850357592 47.21613017376512) | 3 | городской округ Батайск |
| PUNKT (-156.80986787192523 20,476673701778054) | 3 | Hawaii |
| PUNKT (-73.94515332765877 40.70366442203522) | 3 | Stadt New York |
| PUNKT (-83.10398317873478 42.300230911932886) | 3 | Detroit |
| PUNKT (-76.66873019188643 24.306286952923983) | 2 | New Providence |
| PUNKT (-3,0252167768776417 51,39245774131268) | 2 | Cardiff |
| PUNKT (-115.40993484668434 32,73126147687435) | 2 | Municipio de Mexicali |
| Punkt (41.790108773857355 50.302146775648) | 2 | Zentralbezirk |
| PUNKT (-73.88902732171118 45.57078813901171) | 2 | Montréal |
Möglicherweise stellen Sie auch fest, dass die am häufigsten vorkommende Region null war. Was könnte das bedeuten? Zur Erinnerung: Ich habe diesen Befehl mit einem 'Left Join' in SQL verglichen. Das bedeutet, dass, wenn keine übereinstimmende Stadtgrenze für einen Flughafen gefunden wird, der Flughafen trotzdem zurückgegeben wird, jedoch mit null Werten für die Felder ab dem airport_city_boundaries Index. Es stellte sich heraus, dass es 125 Flughäfen gab, bei denen kein passender Eintrag city_boundary gefunden wurde, und einen Flughafen mit einer Übereinstimmung, bei dem das Feld region den null hatte. Dies führte zu einer Zählung von 126 Flughäfen ohne region in den Ergebnissen. Falls Ihr Anwendungsfall erfordert, dass alle Flughäfen einer Stadtgrenze zugeordnet werden können, müssten zusätzliche Daten beschafft werden, um die Lücken zu schließen. Es wäre notwendig, zwei Dinge zu ermitteln:
- Welche Datensätze im Index
airport_city_boundarieshaben keinecity_boundaryFelder? - welche Datensätze im Index
airportsnicht mit dem BefehlENRICHübereinstimmen (d.h. (überschneiden sich nicht)
Verwendung von ES|QL für Geodaten in Kibana Maps
Kibana hat die Unterstützung für Spatial ES|QL in der Kartenanwendung hinzugefügt. Das bedeutet, dass Sie nun ES|QL verwenden können, um in Elasticsearch nach Geodaten zu suchen und die Ergebnisse auf einer Karte zu visualisieren.
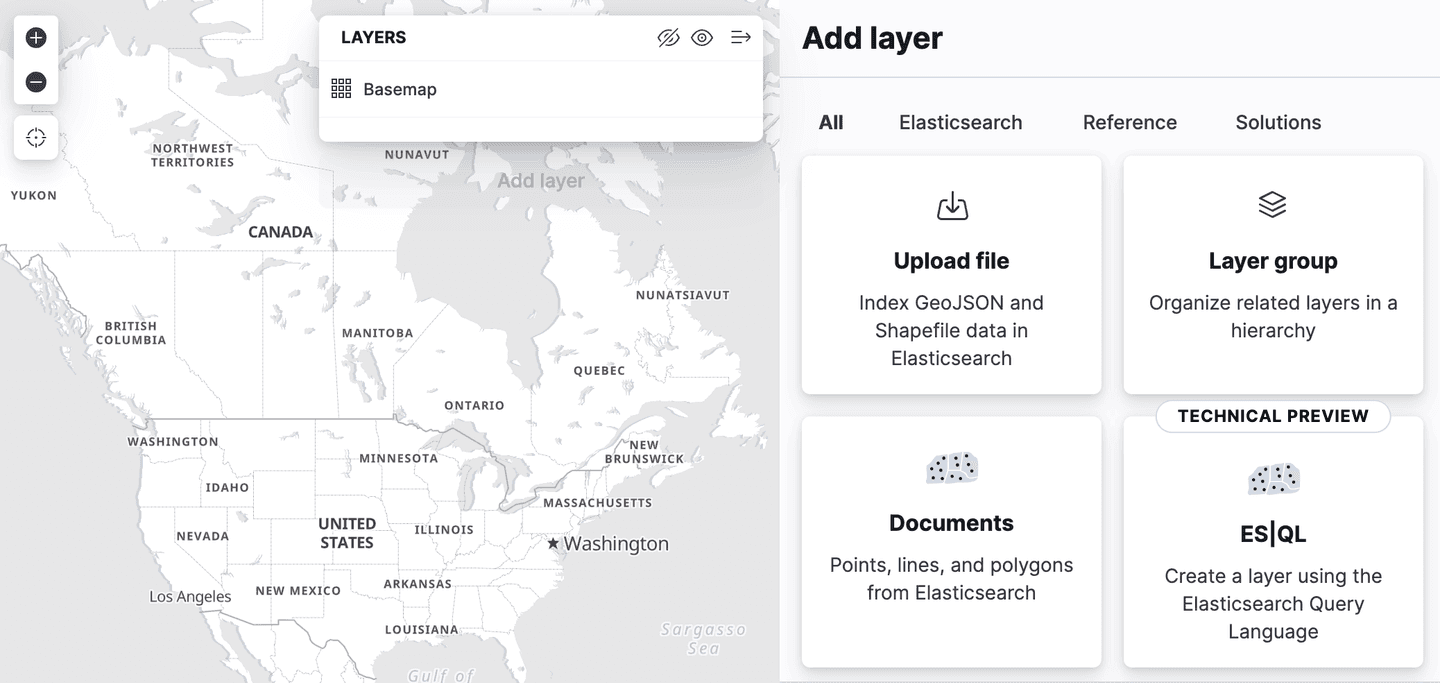
Im Menü „Ebenen hinzufügen“ gibt es eine neue Ebenenoption mit der Bezeichnung „ES|QL“. Wie alle bisher beschriebenen Geodatenfunktionen befindet sich auch diese in der „technischen Vorschauphase“. Durch Auswahl dieser Option können Sie der Karte eine Ebene hinzufügen, die auf den Ergebnissen einer ES|QL-Abfrage basiert. Man könnte beispielsweise eine Ebene zur Karte hinzufügen, die alle Flughäfen der Welt anzeigt.

Oder Sie könnten eine Ebene hinzufügen, die die Polygone ab dem Index airport_city_boundaries anzeigt, oder noch besser, wie wäre es mit der komplexen ENRICH -Abfrage oben, die Statistiken darüber generiert, wie viele Flughäfen sich in jeder Region befinden?
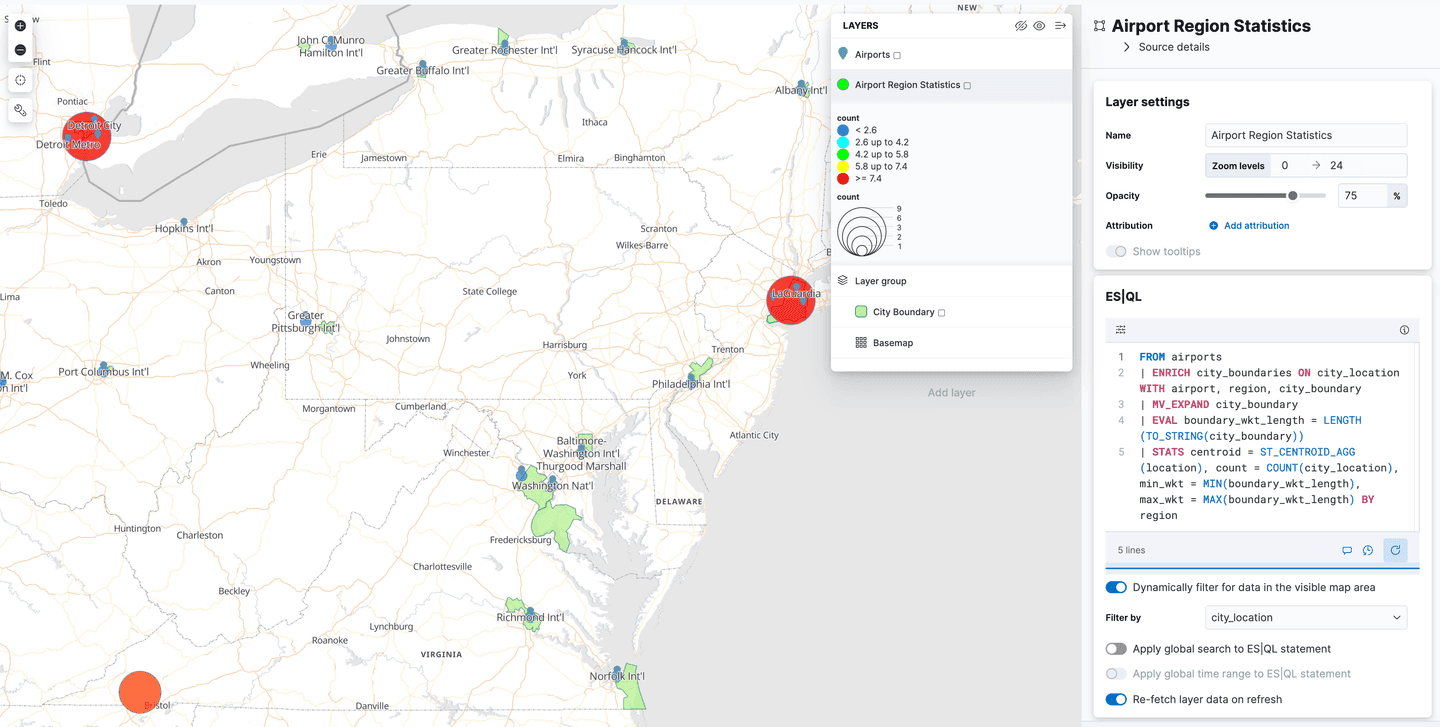
Was kommt als Nächstes?
Der vorherige Blogbeitrag zum Thema Geodaten-Suche konzentrierte sich auf die Verwendung von Funktionen wie ST_INTERSECTS zur Durchführung von Suchvorgängen, die in Elasticsearch seit Version 8.14 verfügbar sind. Und in diesem Blog erfahren Sie, wie Sie die Daten importieren können, die wir für diese Suchvorgänge verwendet haben. Elasticsearch 8.15 brachte jedoch eine besonders interessante Funktion mit sich: ST_DISTANCE , mit der sich effiziente räumliche Distanzsuchen durchführen lassen, und dies wird das Thema des nächsten Blogbeitrags sein!
Zugehörige Inhalte

22. Mai 2026
Kibana reduziert die Dashboard-Ladezeit um bis zu 25 % – hier ist die Polling-Strategie dahinter
Erfahren Sie, wie Kibana durch kontinuierliches Polling und browserseitige HTTP/2-Erkennung die Ladezeiten des Dashboards um bis zu 25 % verkürzt und dabei automatisch auf HTTP/1 zurückgreift.

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

25. Mai 2026
AI Chat in Kibana rendert jetzt nativ Dashboards
Der Elastic AI Chat in Kibana erstellt jetzt Dashboards aus natürlicher Sprache, wobei Ihre Visualisierungen und Analysen in einem Thread beibehalten werden und Sie diese als wiederverwendbare Kibana-Objekte speichern können.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.
19. Januar 2026
Schnellere ES|QL-Statistiken mit Hashtabellen im Schweizer Stil
Wie von der Schweiz inspiriertes Hashing und ein SIMD-freundlicher Entwurf konsistente, messbare Geschwindigkeitssteigerungen in der Elasticsearch-Abfragesprache (ES|QL) liefern.