Wir haben kürzlich zentrale Teile der Hashtabellenimplementierung von Elasticsearch durch einen Entwurf im Schweizer Stil ersetzt und bis zu 2–3-mal schnellere Build- und Iterationszeiten bei einheitlichen, hochkardinalen Workloads beobachtet. Das Ergebnis ist eine geringere Latenz, ein besserer Durchsatz und eine vorhersehbarere Leistung für die Elasticsearch-Abfragesprache (ES|QL) sowie Statistik- und Analyseoperationen.
Warum das wichtig ist
Die meisten typischen analytischen Workflows laufen letztendlich auf die Gruppierung von Daten hinaus. Ob es nun um die Berechnung der durchschnittlichen Bytes pro Host, das Zählen von Ereignissen pro Nutzer oder das Aggregieren von Metriken über Dimensionen hinweg geht, die Kernoperation ist immer dieselbe – Schlüssel werden Gruppen zugeordnet und laufende Aggregate aktualisiert.
In kleinem Maßstab funktioniert fast jede vernünftige Hashtabelle einwandfrei. Bei großer Skalierung (Hunderte Millionen Dokumente und Millionen verschiedener Gruppen) beginnen Details eine Rolle zu spielen. Auslastungsfaktoren, Sondierungsstrategie, Speicherlayout und Cache-Verhalten können den Unterschied zwischen linearer Leistung und einer Flut von Cache-Fehlern ausmachen.
Elasticsearch unterstützt diese Workloads seit Jahren und wir suchen stets nach Möglichkeiten, die Kernalgorithmen zu modernisieren. Daher haben wir einen neueren, von Schweizer Tabellen inspirierten Ansatz evaluiert und ihn auf die Art und Weise angewendet, wie ES|QL Statistiken berechnet.
Was genau sind Schweizer Tabellen?
Schweizer Tabellen sind eine Familie moderner Hash-Tabellen, die von Googles SwissTable popularisiert und später in Abseil und anderen Bibliotheken übernommen wurden.
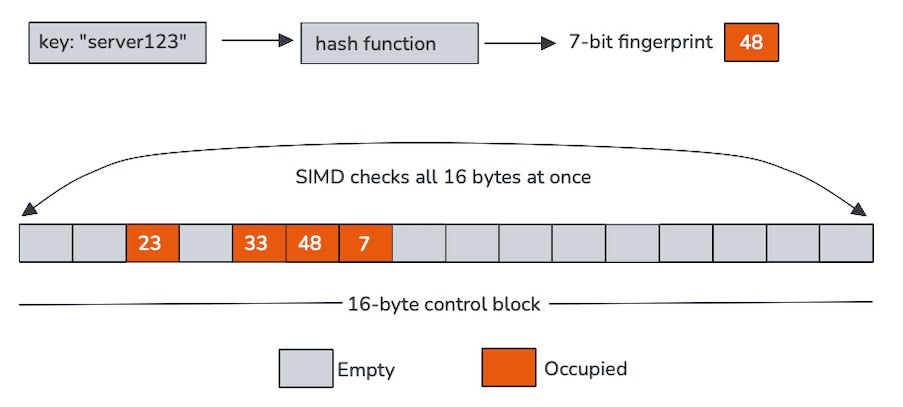
Traditionelle Hash-Tabellen verbringen viel Zeit damit, Zeiger zu verfolgen oder Schlüssel zu laden, nur um festzustellen, dass sie nicht übereinstimmen. Das definierende Feature von Schweizer Tabellen ist die Fähigkeit, die meisten Anfragen mit einer winzigen, im Cache befindlichen Array-Struktur abzulehnen, die getrennt von Schlüsseln und Werten gespeichert wird und als Kontrollbytes bezeichnet wird, um den Speicherverkehr drastisch zu reduzieren.
Jedes Kontrollbyte repräsentiert einen einzelnen Slot und kodiert in unserem Fall zwei Dinge: ob der Slot leer ist und einen kurzen Fingerabdruck, der aus dem Hash abgeleitet wird. Diese Steuerbytes sind zusammenhängend im Speicher angeordnet, typischerweise in Gruppen von 16, was sie ideal für die SIMD-Verarbeitung (Single Instruction, Multiple Data).
Anstatt einen Slot nach dem anderen zu testen, scannen Schweizer Tabellen einen gesamten Kontrollbyte-Block mithilfe von Vektorinstruktionen. In einer einzigen Operation vergleicht die CPU den Fingerabdruck des eingehenden Schlüssels mit 16 Slots und filtert leere Einträge heraus. Nur bei den wenigen Kandidaten, die diesen Schnelltest überstehen, ist das Laden und Vergleichen der tatsächlichen Schlüssel erforderlich.
Dieses Design tauscht eine kleine Menge zusätzlicher Metadaten gegen eine viel bessere Cache-Lokalität und weitaus weniger zufällige Ladevorgänge ein. Wenn die Tabelle wächst und die Sondenketten länger werden, werden diese Eigenschaften immer wertvoller.
SIMD im Mittelpunkt
Der eigentliche Star der Show ist SIMD.
Die Steuerbytes sind nicht nur kompakt, sondern auch explizit für die Verarbeitung mit Vektorbefehlen konzipiert. Ein einzelner SIMD-Vergleich kann 16 Fingerabdrücke gleichzeitig überprüfen und verwandelt, was normalerweise eine Schleife wäre, in eine Handvoll breiter Operationen. Zum Beispiel:
In der Praxis bedeutet das:
- Weniger Zweige.
- Kürzere Testketten.
- Weniger Ladevorgänge aus Schlüssel- und Wertspeicher.
- Viel bessere Nutzung der Ausführungseinheiten der CPU.
Die meisten Suchvorgänge kommen nie über den Control-Byte-Scan hinaus. Wenn sie das tun, ist die verbleibende Arbeit zielgerichtet und vorhersehbar. Das ist genau die Art von Arbeitslast, für die moderne CPUs gut geeignet sind.
SIMD unter der Haube
Für Leser, die gerne einen Blick hinter die Kulissen werfen, hier eine Erklärung, was beim Einfügen eines neuen Schlüssels in die Tabelle passiert. Wir verwenden die Panama Vector API mit 128-Bit-Vektoren und bearbeiten somit 16 Kontrollbytes parallel.
Der folgende Ausschnitt zeigt den Code, der auf einem Intel Rocket Lake mit AVX-512 generiert wurde. Obwohl die Anweisungen diese Umgebung widerspiegeln, hängt das Design nicht von AVX-512 ab. Die gleichen hochstufigen Vektoroperationen werden auf anderen Plattformen mit gleichwertigen Befehlen (zum Beispiel AVX2, SSE oder NEON) ausgesendet.
Jede Anweisung hat eine klare Rolle im Einfügeprozess:
vmovdqu: Lädt 16 aufeinanderfolgende Steuerbytes in das 128-Bit-xmm0-Register.vpbroadcastb: Repliziert den 7-Bit-Fingerabdruck des neuen Schlüssels über alle Spuren desxmm1-Registers.vpcmpeqb: Vergleicht jedes Steuerbyte mit dem gesendeten Fingerabdruck und erstellt eine Maske mit möglichen Übereinstimmungen.kmovq+test: Verschiebt die Maske in ein allgemeines Register und überprüft schnell, ob ein Match existiert.
Schließlich entschieden wir uns dafür, Gruppen von jeweils 16 Kontrollbytes zu untersuchen, da Benchmarks zeigten, dass eine Erweiterung auf 32 oder 64 Bytes mit breiteren Registern keinen messbaren Leistungsvorteil brachte.
Integration in ES|QL
Die Einführung des Hashing im Schweizer Stil in Elasticsearch war nicht einfach ein direkter Ersatz. ES|QL stellt hohe Anforderungen an die Speicherverwaltung, die Sicherheit und die Integration mit dem Rest der Compute Engine.
Wir haben die neue Hash-Tabelle eng in die Speicherverwaltung von Elasticsearch integriert, einschließlich des Seitenrecyclers und der Abrechnung von Schutzschaltern, um sicherzustellen, dass die Zuweisungen sichtbar und begrenzt bleiben. Die Aggregationen von Elasticsearch werden dicht gespeichert und durch eine Gruppen-ID indexiert, wodurch das Speicherlayout kompakt und schnell für Iterationen bleibt und zudem bestimmte Leistungsoptimierungen durch zufälligen Zugriff ermöglicht werden.
Bei Byte-Schlüsseln mit variabler Länge wird der vollständige Hash zusammen mit der Gruppen-ID zwischengespeichert. Dadurch wird die Neuberechnung teurer Hash-Codes während der Sondierung vermieden und die Cache-Lokalität verbessert, indem zusammengehörige Metadaten nahe beieinander gehalten werden. Während des Rehashings können wir uns auf den zwischengespeicherten Hash und die Kontroll-Bytes verlassen, ohne die Werte selbst zu inspizieren, wodurch die Kosten für die Größenänderung niedrig gehalten werden.
Eine wichtige Vereinfachung in unserer Implementierung besteht darin, dass Einträge niemals gelöscht werden. Dadurch werden Tombstones (Markierungen zur Identifizierung zuvor belegter Steckplätze) überflüssig, und leere Steckplätze bleiben wirklich leer, was das Verhalten der Sonde weiter verbessert und Kontroll-Byte-Scans effizient macht.
Das Ergebnis ist ein Design, das sich nahtlos in das Ausführungsmodell von Elasticsearch einfügt und gleichzeitig die Leistungsmerkmale beibehält, die Schweizer Tabellen so attraktiv machen.
Wie ist die Performance?
Bei kleinen Kardinalitäten schneiden die Schweizer Tabellen in etwa gleich gut ab wie die bestehende Implementierung. Das ist zu erwarten: Bei kleinen Tabellen spielen Cache-Effekte eine geringere Rolle und es gibt wenig Optimierungsbedarf.
Mit zunehmender Kardinalität ändert sich das Bild schnell.
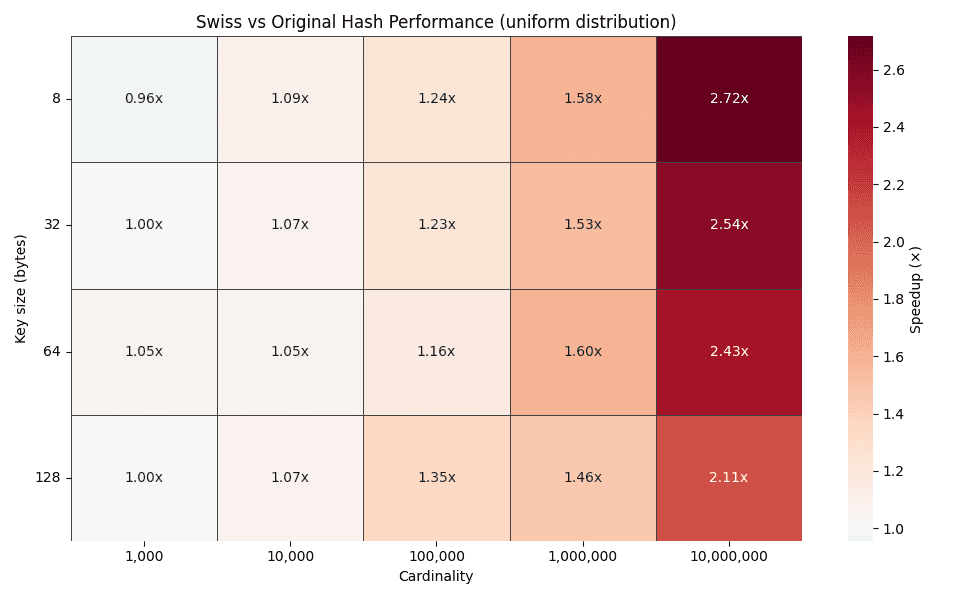
Die obige Heatmap zeigt die Zeitverbesserungsfaktoren für verschiedene Schlüsselgrößen (8, 32, 64 und 128 Byte) über Kardinalitäten von 1.000 bis 10.000.000 Gruppen hinweg. Mit zunehmender Kardinalität steigt der Verbesserungsfaktor stetig an und erreicht bei Gleichverteilungen Werte von bis zu 2–3x.
Dieser Trend entspricht genau dem, was die Konstruktion vorhersagt. Höhere Kardinalität führt zu längeren Prüfketten in traditionellen Hash-Tabellen, während die meisten Suchvorgänge nach wie vor in SIMD-freundlichen Kontroll-Byte-Blöcken gelöst werden.
Das Cache-Verhalten erzählt die Geschichte
Um die Beschleunigungen besser zu verstehen, haben wir denselben JMH-benchmarks unter Linux perf ausgeführt und Cache- sowie TLB-Statistiken erfasst.
Im Vergleich zur ursprünglichen Implementierung benötigt die Schweizer Version insgesamt etwa 60 % weniger Cache-Zugriffe. Die Last-Level-Cache-Ladevorgänge sinken um mehr als das Vierfache, und LLC-Ladefehler gehen um mehr als das Sechsfache zurück. Da LLC-Fehlzugriffe oft direkt in Hauptspeicherzugriffe übersetzt werden, erklärt diese Reduzierung allein einen großen Teil der End-to-End-Verbesserung.
Näher an der CPU beobachten wir weniger L1-Datencache-Fehler und fast 6x weniger TLB-Datenfehler, was auf eine engere räumliche Lokalität und besser vorhersagbare Speicherzugriffsmuster hindeutet.
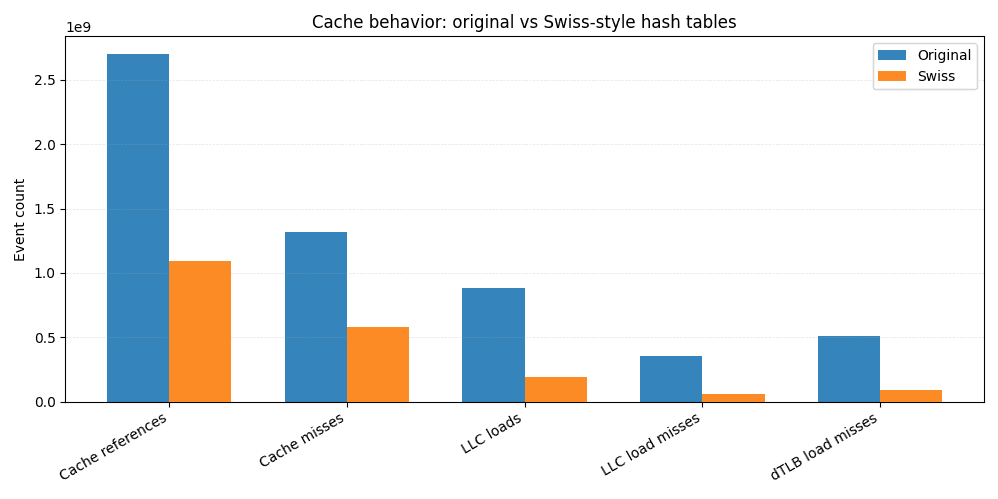
Dies ist der praktische Nutzen von SIMD-freundlichen Kontrollbytes. Anstatt Schlüssel und Werte immer wieder von verstreuten Speicherplätzen zu laden, werden die meisten Suchvorgänge durch das Durchsuchen einer kompakten, im Cache befindlichen Struktur gelöst. Weniger berührter Speicher bedeutet weniger Fehltritte, und weniger Fehltritte bedeuten schnellere Abfragen.
Fazit
Indem wir einen Hashtabellenentwurf im Schweizer Stil verwendeten und uns stark auf SIMD-freundliche Sondierungen konzentrierten, erreichten wir 2–3-fache Beschleunigungen für ES|QL-Statistik-Workloads mit hoher Kardinalität sowie eine stabilere und vorhersehbarere Leistung.
Diese Arbeit zeigt, wie moderne CPU-fähige Datenstrukturen erhebliche Verbesserungen ermöglichen können, selbst bei bekannten Problemen wie Hash-Tabellen. Hier gibt es mehr Raum für Erkundungen, wie etwa zusätzliche Spezialisierungen von primitiven Typen und die Verwendung in anderen Pfaden mit hoher Kardinalität, wie Joins, die alle Teil der umfassenderen und fortlaufenden Bemühungen sind, die internen Abläufe von Elasticsearch kontinuierlich zu modernisieren.
Wenn Sie an den Details interessiert sind oder die Arbeit verfolgen möchten, schauen Sie sich diesen Pull Request und den Meta-Issue-Fortschritt auf Github an.
Viel Spaß beim Hashing!
Zugehörige Inhalte

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.
12. Dezember 2025
Einführung der Elasticsearch-Unterstützung in der Google MCP Toolbox for Databases
Erfahren Sie, wie die Unterstützung für Elasticsearch jetzt in der Google MCP Toolbox for Databases verfügbar ist, und nutzen Sie ES|QL-Tools, um Ihren Index sicher mit jedem MCP-Client zu integrieren.
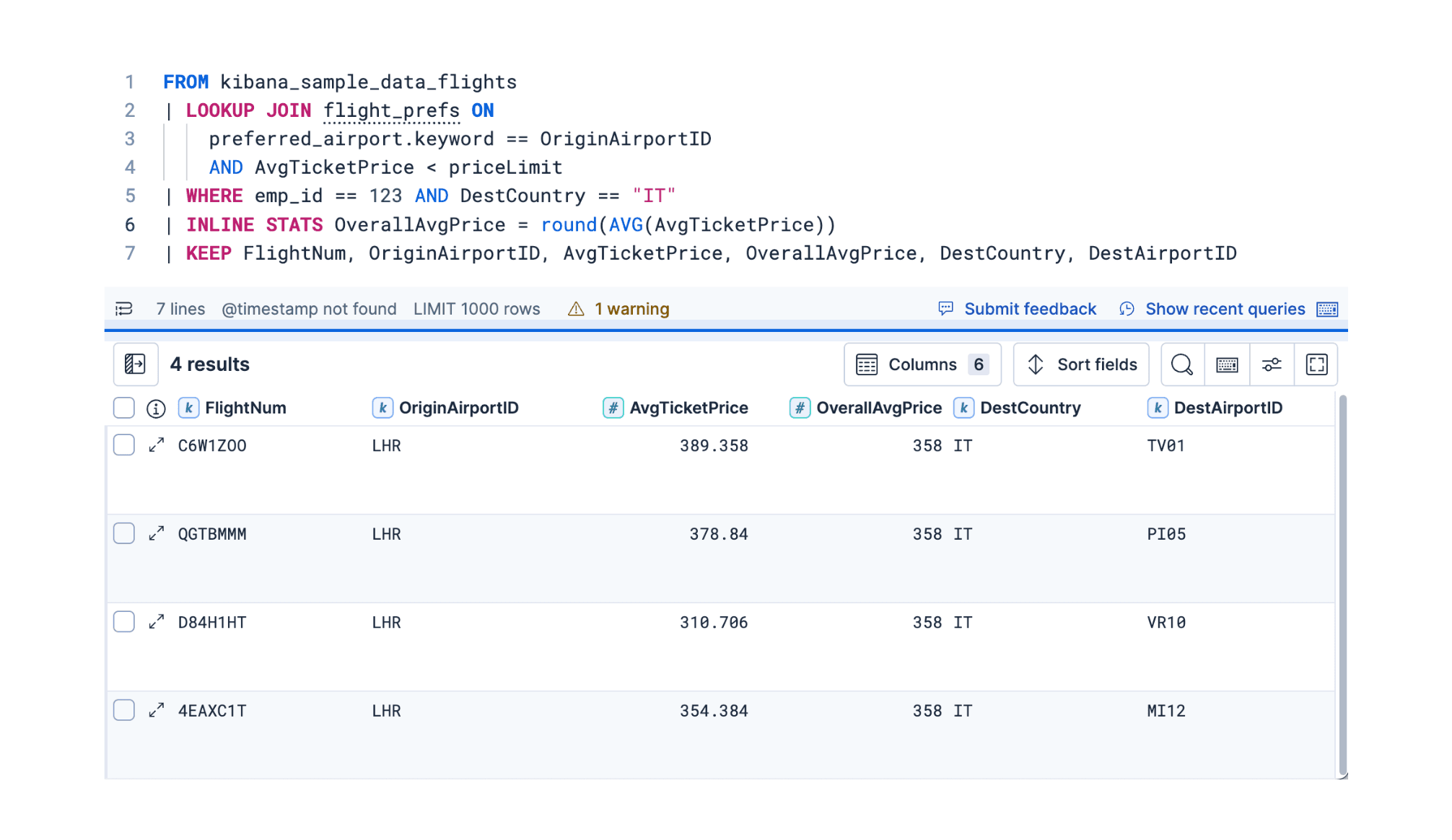
2. Dezember 2025
ES|QL in 9.2: Unterstützung für intelligente Lookup Joins und Zeitreihen
Entdecken Sie drei separate Updates für ES|QL in Elasticsearch 9.2: ein verbessertes LOOKUP JOIN für ausdrucksstärkere Datenkorrelation, den neuen TS-Befehl für die Zeitreihenanalyse und den flexiblen INLINE STATS-Befehl für die Aggregation.

18. September 2025
Elasticsearchs ES|QL-Editor-Benutzererfahrung im Vergleich zum PPL-Ereignisanalysator von OpenSearch.
Entdecken Sie, wie die erweiterten Funktionen des ES|QL Editors Ihren Workflow beschleunigen und sich damit deutlich vom manuellen Ansatz des PPL Event Analyzer von OpenSearch abheben.

Einführung des ES|QL-Abfragegenerators für den Elasticsearch Ruby Client
Lernen Sie, wie Sie den kürzlich veröffentlichten ES|QL-Abfragegenerator für den Elasticsearch Ruby Client verwenden. Ein Tool, um ES|QL-Abfragen mit Ruby-Code einfacher zu erstellen.