Elasticsearch 9.2, das im Oktober veröffentlicht wurde, bietet zahlreiche bedeutende Verbesserungen, die die Analyse Ihrer Daten schneller, flexibler und zugänglicher als je zuvor machen. Im Mittelpunkt dieser Version stehen wichtige Verbesserungen an ES|QL, unserer Pipe-Abfragesprache, die entwickelt wurden, um Endnutzer:innen direkt noch mehr Nutzen zu bieten.
Hier ist ein Überblick über die Features in Elasticsearch 9.2, die Ihre Datenanalyse-Workflows mit ES|QL verändern werden.
Revolutionierung der Datenkorrelation: Eine intelligentere, schnellere und flexiblere Lookup-Verknüpfung
Der Befehl LOOKUP JOIN in ES|QL hat in Elasticsearch 9.2 eine bedeutende Transformation durchlaufen und ist deutlich effizienter und vielseitiger geworden. LOOKUP JOIN kombiniert Daten aus Ihrer ES|QL-Abfrageergebnistabelle mit übereinstimmenden Einträgen aus einem angegebenen Lookup-Modus-Index. Es fügt Felder aus dem Lookup-Index als neue Spalten zu Ihrer Ergebnistabelle hinzu, basierend auf übereinstimmenden Werten im Join-Feld. Zuvor war die Verknüpfung von Daten auf ein einziges Feld und einfache Gleichheit beschränkt. Das ist Geschichte! Dank dieser Erweiterungen können Sie komplexe Datenkorrelationsszenarien mühelos bewältigen.
Zu den wichtigsten Verbesserungen von Lookup Join gehören:
- Verknüpfungen mit mehreren Feldern: Einfaches Verknüpfen mehrerer Felder. So verbinden Sie beispielsweise
application_logsmitservice_registryanhand vonservice_name,environmentundversion:
- Freischalten komplexer Join-Prädikate mit Ausdrücken (technische Vorschau):
Sie sind nicht mehr auf einfache Gleichheit beschränkt. LOOKUP JOIN ermöglicht es Ihnen nun, mehrere Kriterien für die Korrelation anzugeben und eine Reihe von binären Operatoren einzubeziehen, darunter ==, !=, <, >, <= und >=. Dies bedeutet, dass Sie hochgradig nuancierte Join-Bedingungen erstellen können, die es Ihnen ermöglichen, viel anspruchsvollere Fragen an Ihre Daten zu stellen.
Beispiel 1: Ermittlung von Anwendungsmetriken mit SLA-Schwellenwert pro Dienst
Beispiel 2: Diese Abfrage berechnet den fälligen Betrag auf Grundlage regionaler Preisrichtlinien, die sich im Laufe der Zeit ändern. Es verknüpft drei Datensätze basierend auf komplexen Datumsbereichs- und Gleichheitsbedingungen, um eine endgültige due_amount zu berechnen. Der zweite Lookup-Join verwendet das Feld measurement_date aus dem Index meter_readings und das Feld region_id aus dem Index customers, um mit dem Index pricing_policies verknüpft zu werden und die richtige Preispolitik für die jeweiligen region und measurement_date zu finden.
- Enorme Leistungsgewinne bei gefilterten Joins:
Wir haben die Leistung für „erweiterte Verknüpfungen” verbessert, die anhand von Lookup-Tabellenbedingungen gefiltert werden. Erweiterte Verknüpfungen führen zu mehreren Übereinstimmungen pro Eingabezeile, wodurch große Zwischenergebnismengen entstehen können. Dies wird noch schlimmer, wenn viele dieser Zeilen durch einen nachfolgenden Filter verworfen werden. In 9.2 optimieren wir diese Verknüpfungen, indem wir unnötige Zeilen herausfiltern, wenn ein Filter auf Suchdaten angewendet wird. Dadurch wird die Verarbeitung von Zeilen vermieden, die verworfen würden. In einigen Szenarien können diese Joins bis zu 1000-mal schneller sein!
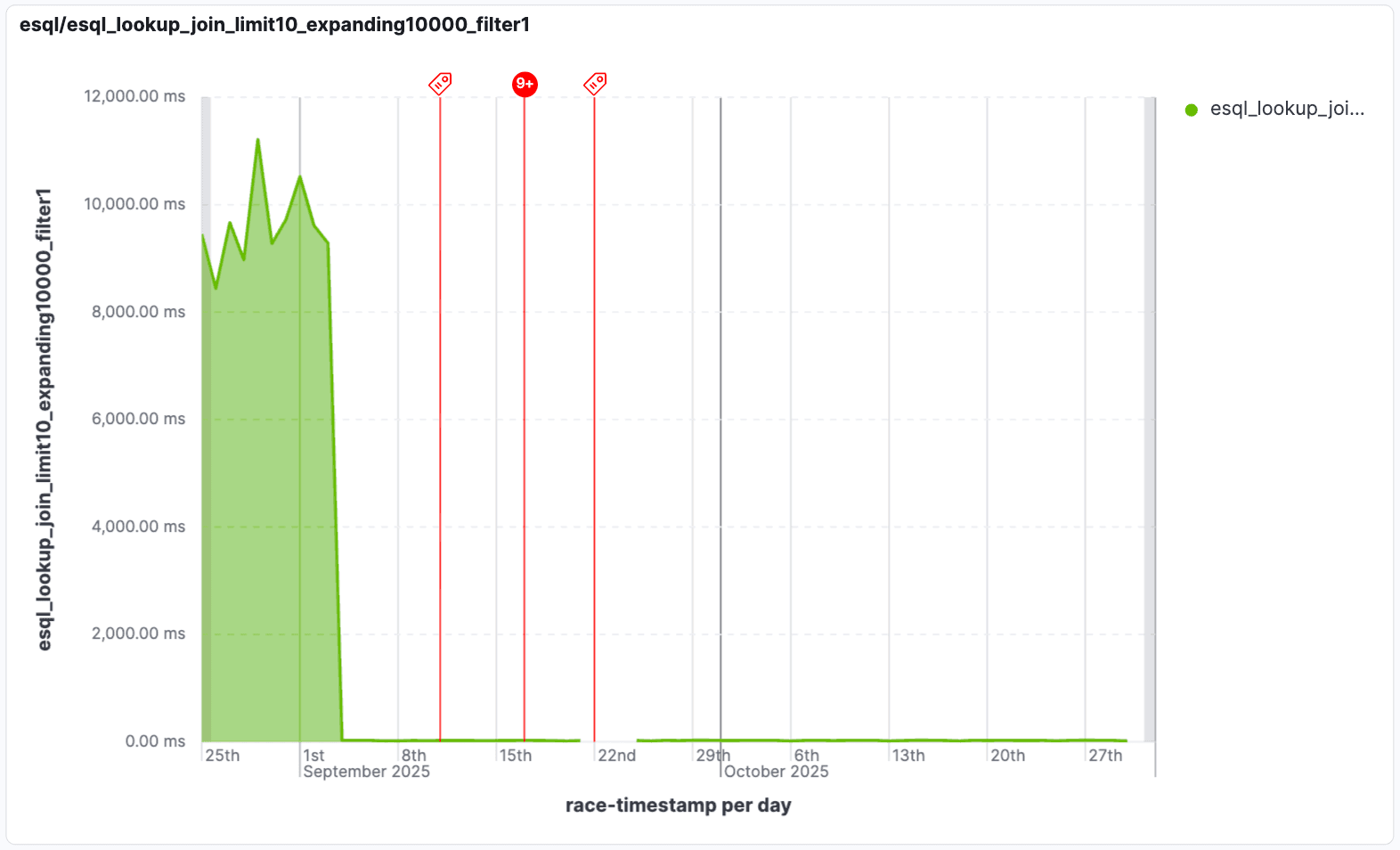
Diese Optimierung ist entscheidend bei der Verarbeitung von „expandierenden Joins“, bei denen eine Suche anfänglich viele potenzielle Übereinstimmungen erzeugen kann. Durch intelligentes Herunterdrücken von Filtern werden nur die relevanten Daten verarbeitet, was die Ausführungszeit von Abfragen drastisch verkürzt und die Echtzeitanalyse großer Datensätze ermöglicht. Das bedeutet, dass Sie Ihre Einblicke viel schneller erhalten, selbst bei sehr großen oder komplexen Join-Operationen.
Kompatibilität mit der clusterübergreifenden Suche (CCS) Lookup Join:
Als Lookup Join in den Versionen 8.19 und 9.1 allgemein verfügbar wurde, fehlte die Unterstützung für die clusterübergreifende Suche (CCS). Für Organisationen, die in mehreren Clustern arbeiten, lässt sich LOOKUP JOIN in 9.2 jetzt nahtlos in CCS integrieren. Platzieren Sie einfach Ihren Lookup-Index auf allen Remote-Clustern, mit denen Sie einen Join durchführen möchten, und ES|QL nutzt diese Remote-Lookup-Indizes automatisch, um den Join mit Ihren Remote-Daten durchzuführen. Dies vereinfacht die verteilte Datenanalyse und gewährleistet eine konsistente Anreicherung Ihres gesamten Elasticsearch-Deployments.
Diese Verbesserungen ermöglichen es Ihnen, vielfältige Datensätze mit beispielloser Präzision, Geschwindigkeit und Leichtigkeit zu korrelieren und so tiefere, umsetzbare Einblicke ohne komplexe Workarounds oder Vorverarbeitungsschritte zu gewinnen.
Reichern Sie Ihre Daten mühelos an: Kibana Discover UX für Lookup-Indizes
Die Datenanreicherung sollte unkompliziert sein und keine Hürde darstellen. Wir haben in Kibana Discover eine fantastische neue Nutzererfahrung für die Erstellung und Verwaltung von Lookup-Indizes eingeführt.
Intuitiver Workflow: Die umfassende Autovervollständigung von Discover führt Sie durch den Prozess, schlägt Suchindizes und Join-Felder im ES|QL-Editor vor und macht es unglaublich einfach, Ihre hochgeladenen Daten mit vorhandenen Indizes zu verbinden. Geben Sie den Namen eines Lookup-Index ein, der nicht existiert, und erhalten Sie mit einem Klick direkten Zugriff auf den Lookup-Editor, um den Index zu erstellen. Geben Sie den Namen eines bestehenden Nachschlageindex ein, und wir schlagen eine Option zur Bearbeitung vor:

Inline-Management (CRUD): Halten Sie Ihre Datensätze mit Inline-Bearbeitungsfunktionen (Erstellen, Lesen, Aktualisieren, Löschen) und Liniendiagramm direkt in Discover auf dem neuesten Stand.

Müheloses Hochladen von Dateien: Sie können jetzt Dateien wie CSVs direkt in Discover hochladen und sofort in Ihren LOOKUP JOIN verwenden. Keine Kontextwechsel mehr durch das Springen zwischen verschiedenen Bereichen von Kibana!
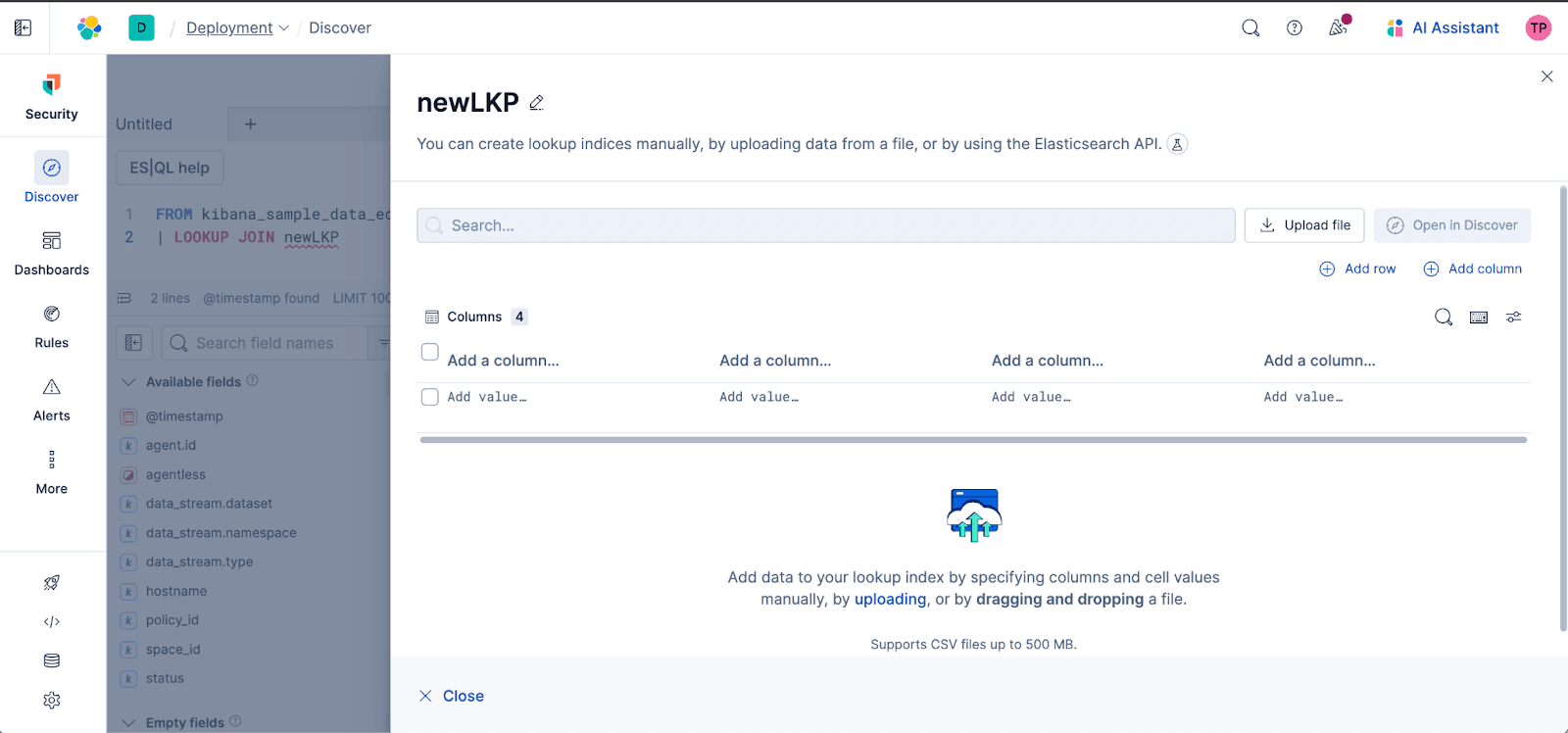
Egal, ob Sie Nutzer-IDs mit Namen mappen, Geschäfts-Metadaten hinzufügen oder statische Referenzdateien verknüpfen – dieses Feature demokratisiert die Datenanreicherung und versorgt die Joins direkt in den Händen aller Nutzer:innen mit Energie – schnell, einfach und alles an einem Ort.
Bewahren Sie Ihren Kontext: Einführung von INLINE STATS (technische Vorschau)
Die Aggregation von Daten ist entscheidend, aber manchmal müssen Sie die Aggregate neben Ihren ursprünglichen Daten sehen. Wir freuen uns, INLINE STATS als Tech Preview-Feature vorzustellen.
Im Gegensatz zum Befehl STATS, der Ihre Eingabefelder durch aggregierte Ausgaben ersetzt, behält INLINE STATS alle Ihre ursprünglichen Eingabefelder bei und fügt lediglich die neuen aggregierten Felder hinzu. Dies ermöglicht es Ihnen, nach der Aggregation weitere Operationen auf Ihren ursprünglichen Eingabefeldern durchzuführen und bietet so einen kontinuierlicheren und flexibleren Analyse-Workflow.
Um beispielsweise die durchschnittliche Flugdistanz unter Beibehaltung der einzelnen Flugreihen zu berechnen:

Bei dieser Abfrage wird jeder Zeile avgDist mit der entsprechenden Dest(ination) hinzugefügt, nach der wir gruppiert haben. Da wir dann immer noch die Spalten mit den Fluginformationen haben, können wir die Ergebnisse auf die Flüge mit einer Entfernung, die größer als der Durchschnitt ist, filtern.
Zeitreihenunterstützung in ES|QL (technische Vorschau)
Elasticsearch verwendet Zeitreihen-Datenströme zum Speichern von Metriken. Wir fügen Unterstützung für Zeitreihenaggregationen in ES|QL über den TS Source-Befehl hinzu. Dies ist in Elastic Cloud Serverless und 9.2 Basic als Tech-Vorschau verfügbar.
Die Zeitreihenanalyse basiert größtenteils auf Aggregationsabfragen, die Metrikwerte in Zeit-Buckets zusammenfassen, unterteilt durch eine oder mehrere Filterdimensionen. Die meisten Aggregationsabfragen basieren auf einer zweistufigen Verarbeitung: (a) eine innere Aggregationsfunktion, die Werte pro Zeitreihe zusammenfasst, und (b) eine äußere Aggregationsfunktion, die die Ergebnisse von (a) über Zeitreihen hinweg kombiniert.
Der Quellbefehl TS bietet in Kombination mit STATS eine prägnante und dennoch effektive Möglichkeit, solche Abfragen über Zeitreihen auszudrücken. Betrachten wir konkreter das folgende Beispiel zur Berechnung der Gesamtanforderungsrate pro Host und Stunde:
In diesem Fall wird die Aggregationsfunktion RATE zuerst pro Zeitreihe und Stunde ausgewertet. Die erzeugten Teilaggregate werden dann mit SUM kombiniert, um die endgültigen Aggregatwerte pro Host und Stunde zu berechnen.
Eine Liste der verfügbaren Funktionen zur Aggregation von Zeitreihen finden Sie hier. Zählerrate wird jetzt unterstützt, die wohl wichtigste Aggregationsfunktion für die Verarbeitung von Zählern.
Der Quellbefehl TS ist so konzipiert, dass er mit STATS kombiniert werden kann, wobei die Ausführung so abgestimmt ist, dass sie Zeitreihenaggregationen effizient unterstützt. Zum Beispiel werden die Daten sortiert, bevor sie in die STATS gelangen. Verarbeitungsbefehle, die die Zeitreihendaten oder ihre Reihenfolge anreichern oder verändern können, wie FORK oder INLINE STATS, sind derzeit zwischen TS und STATS nicht zulässig. Diese Beschränkung könnte in Zukunft aufgehoben werden.
Die tabellarische Ausgabe von STATS kann mit einem beliebigen Befehl weiterverarbeitet werden. Zum Beispiel berechnet die folgende Abfrage das Verhältnis des durchschnittlichen cpu_usage pro Host und Stunde bis zum maximalen Wert pro Host:
Zeitreihendaten werden auf unserer zugrunde liegenden spaltenförmigen Speicher-Engine gespeichert, die von Lucene-Doc-Werten betrieben wird. Der TS-Befehl fügt die vektorisierte Abfrageausführung über die ES|QL-Compute-Engine hinzu. Die Abfrageleistung wird im Vergleich zu äquivalenten DSL-Abfragen oft um mehr als eine Größenordnung verbessert und ist mit etablierten, metrikspezifischen Systemen vergleichbar. Wir werden in Zukunft eine detaillierte Architektur- und Leistungsanalyse bereitstellen, also bleiben Sie gespannt.
Erweiterung Ihres Toolkits: Neue ES|QL-Funktionen
Zeichenfolgenmanipulation: CONTAINS, MV_CONTAINS, URL_ENCODE, URL_ENCODE_COMPONENT, URL_DECODE für eine robustere Text- und URL-Verarbeitung.
Zeitreihen und Geodaten: TBUCKET für flexible Buckets, TO_DENSE_VECTOR für Vektoroperationen und ein umfassender Satz von Geodatenfunktionen wie ST_GEOHASH, ST_GEOTILE, ST_GEOHEX, TO_GEOHASH, TO_GEOTILE, TO_GEOHEX für fortgeschrittene ortsbezogene Analysen.
Datumsformatierung: DAY_NAME, MONTH_NAME für besser lesbare Datumsdarstellungen.
Diese Funktionen bieten Ihnen eine umfangreichere Auswahl an Werkzeugen, um Ihre Daten direkt innerhalb von ES|QL zu bearbeiten und zu analysieren.
Unter der Haube: Mehr Leistung und Effizienz
Neben den hervorgehobenen Features bietet Elasticsearch 9.2 zahlreiche Leistungsoptimierungen für ES|QL. Wir haben RLIKE (LIST) mit Pushdown beschleunigt, wenn die Funktion mehrere ähnliche RLIKE-Abfragen in einem Ticket ersetzt. Mit RLIKE (LIST) können wir diese Abfragen zu einem einzigen Automaten zusammenführen und einen Automaten anstelle mehrerer anwenden. Wir bieten außerdem ein schnelleres Laden von Schlüsselwortfeldern durch Indexsortierungen und allgemeine Abfrageoptimierungen – diese Verbesserungen gewährleisten, dass Ihre ES|QL-Abfragen effizienter als je zuvor ausgeführt werden.
Legen Sie noch heute los!
Elasticsearch 9.2 ist ein bedeutender Fortschritt für ES|QL und bringt beispiellose Leistung und Flexibilität in Ihre Datenanalyse-Workflows. Wir ermutigen Sie, diese neuen Features zu erkunden und den Unterschied selbst zu erleben.
Eine vollständige Liste aller Änderungen und Verbesserungen in Elasticsearch 9.2 finden Sie in den offiziellen Versionshinweisen. Viel Spaß beim Abfragen!
Zugehörige Inhalte

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.
19. Januar 2026
Schnellere ES|QL-Statistiken mit Hashtabellen im Schweizer Stil
Wie von der Schweiz inspiriertes Hashing und ein SIMD-freundlicher Entwurf konsistente, messbare Geschwindigkeitssteigerungen in der Elasticsearch-Abfragesprache (ES|QL) liefern.
12. Dezember 2025
Einführung der Elasticsearch-Unterstützung in der Google MCP Toolbox for Databases
Erfahren Sie, wie die Unterstützung für Elasticsearch jetzt in der Google MCP Toolbox for Databases verfügbar ist, und nutzen Sie ES|QL-Tools, um Ihren Index sicher mit jedem MCP-Client zu integrieren.

18. September 2025
Elasticsearchs ES|QL-Editor-Benutzererfahrung im Vergleich zum PPL-Ereignisanalysator von OpenSearch.
Entdecken Sie, wie die erweiterten Funktionen des ES|QL Editors Ihren Workflow beschleunigen und sich damit deutlich vom manuellen Ansatz des PPL Event Analyzer von OpenSearch abheben.

Einführung des ES|QL-Abfragegenerators für den Elasticsearch Ruby Client
Lernen Sie, wie Sie den kürzlich veröffentlichten ES|QL-Abfragegenerator für den Elasticsearch Ruby Client verwenden. Ein Tool, um ES|QL-Abfragen mit Ruby-Code einfacher zu erstellen.