Test Elastic's leading-edge, out-of-the-box capabilities. Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
This blog series reveals how our Field Engineering team used the Elastic stack with generative AI to develop a lovable and effective customer support chatbot. If you missed other installments in the series, be sure to check out part one, part three, part four, the launch blog, and part five.
Retrieval-Augmented Generation (RAG) Over a Fine Tuned Model
As an engineering team, we knew that Elastic customers would need to trust a generative AI-based Support Assistant to provide accurate and relevant answers. Our initial proof of concept showed that large language model (LLM) foundational training was insufficient on technologies as technically deep and broad as Elastic. We explored fine-tuning our own model for the Support Assistant and instead landed on an RAG-based approach for several reasons.
- Easier with unstructured data: Fine-tuning required question-answer pairing that did not match our data set and would be challenging to do at the scale of our data.
- Real-time updates: Immediately incorporates new information by accessing up-to-date documents, ensuring current and relevant responses.
- Role-Based Access Control: A single user experience across roles restricts specific documents or sources based on the allowed level of access.
- Less maintenance: Search on the Support Hub and the Support Assistant share much of the same underlying infrastructure. We improved search results and a chatbot from the same work effort.
Understanding the Support Assistant as a Search Problem
We then formed a hypothesis that drove the technical development and testing of the Support Assistant.
Providing more concise and relevant search results as context for the LLM will lead to stronger positive user sentiment by minimizing the chance of the model using unrelated information to answer the user's question.

In order to test our team hypothesis, we had to reframe our understanding of chatbots in the context of search. Think of a support chatbot as a librarian. The librarian has access to an extensive pool of books (via search) and innately knows (the LLM) a bit about a broad range of topics. When asked a question, the librarian might be able to answer from their own knowledge but may need to find the appropriate book(s) to address questions about deep domain knowledge.
Search extends the ”librarian” ability to find passages within the book in ways that have never existed before. The Dewey Decimal Classification enabled a searchable index of books. Personal computers evolved into a better catalog with some limited text search. RAG via Elasticsearch + Lucene enables the ability to not only find key passages within books across an entire library, but also to synthesize an answer for the user, often in less than a minute. The system is infinitely scalable as by adding more books to the library, the chances are stronger of having the required knowledge to answer a given question.
The phrasing of the user input, prompts and settings like temperature (degree of randomness) still matter but we found that we can use search as a way to understand user intent and better augment the context passed on to the large language model for higher user satisfaction.
Elastic Support’s Knowledge Library
The body of knowledge that we draw from for both search and the Elastic Support Assistant depends on three key activities: the technical support articles our Support Engineers author, the product documentation and blogs that we ingest, and the enrichment service, which increases the search relevancy for each document in our hybrid search approach.
It is also important to note that the answers to user questions often come from specific passages across multiple documents. This is a significant driver for why we chose to offer the Support Assistant. The effort for a user to find an answer in a specific paragraph across multiple documents is substantial. By extracting this information and sending it to the large language model, we both save the user time and return an answer in natural language that is easy to understand
Technical Support Articles
Elastic Support follows a knowledge-centered service approach where Support Engineers document their solutions and insights to cases so that our knowledge base (both internal and external) grows daily. This is run entirely on Elasticsearch on the back end and the EUI Markdown Editor control on the front end and is one of the key information sources for the Elastic Support Assistant.
The majority of our work for the Support Assistant was to enable semantic search so we could take advantage of ELSER. Our prior architecture had two separate storage methods for knowledge articles. One was a Swiftype instance used for customer facing articles and the other was through Elastic Appsearch for internal Support team articles. This was tech debt on the part of our engineering team as Elasticsearch had already brought parity to several of the features we needed.
Our new architecture takes advantage of document level security to enable role-based access from a single index source. Depending on the Elastic Support Assistant user, we could retrieve documents appropriate for them to use as part of the context sent to OpenAI. This can scale in the future to new roles as required.
At times, we also find a need to annotate external articles with information for the Support team. To accommodate this, we developed an EUI plugin called private context. This finds multiline private context tags within the article that begin a block of text, parses them using regex to find private context blocks and then processes them as special things called AST nodes, of type privateContext.
The result of these changes resulted in an index that we could use with ELSER for semantic search and nuanced access to information based on the role of the user.
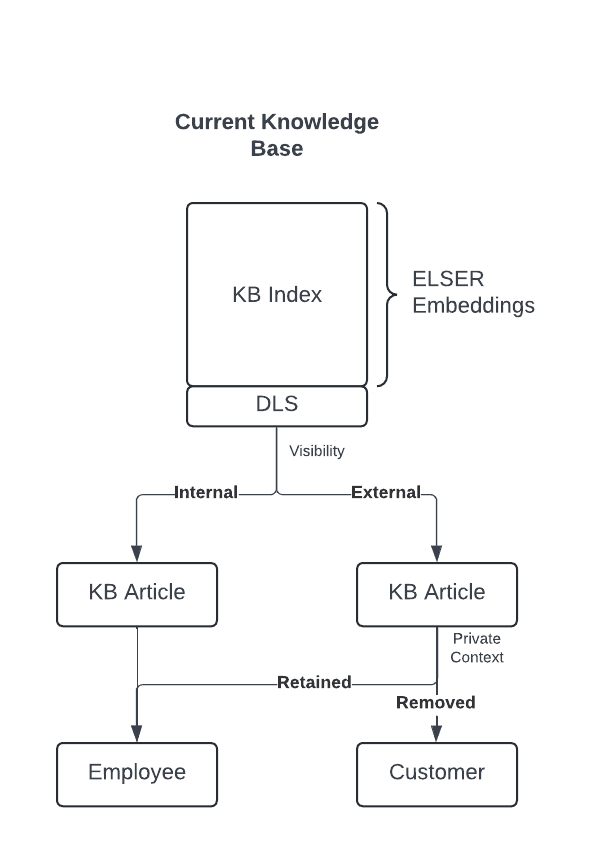
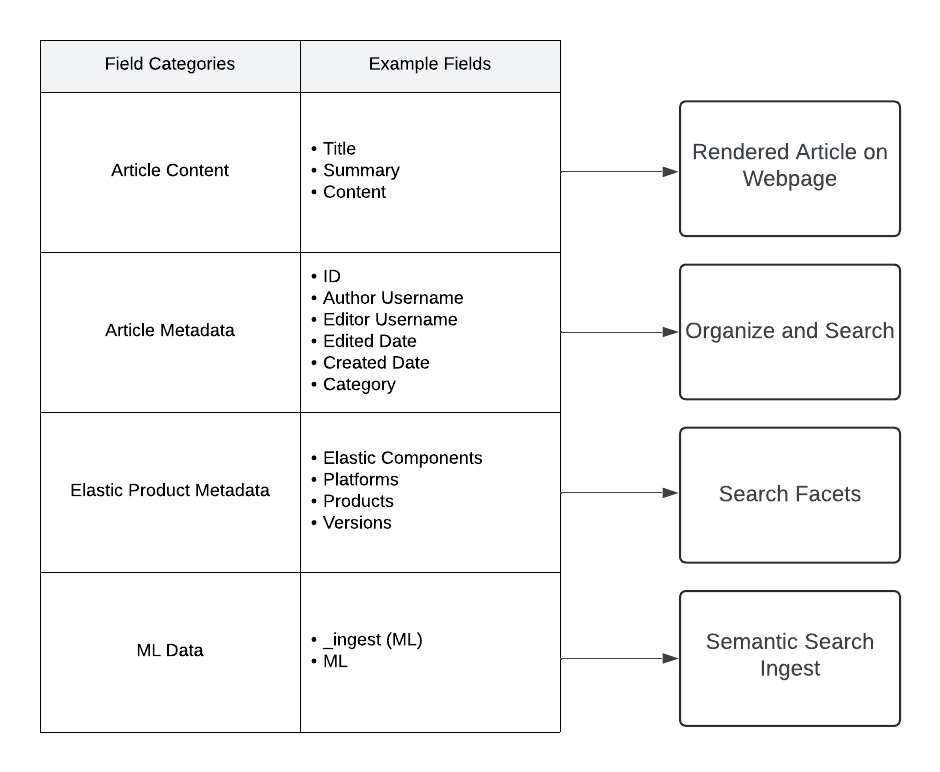
We performed multiple index migrations, resulting in a single document structure for both use cases. Each document contains four broad categories of fields. By storing the metadata and article content in the same JSON document, we can efficiently leverage different fields as needed.
For our hybrid search approach in the Support Assistant, we use the title and summary fields for semantic search with BM25 on the much larger content field. This enables the Support Assistant to have both speed and high relevance to the text we will pass as context to the OpenAI GPT.
Ingesting Product Documentation, Blogs & Search Labs Content
Even though our technical support knowledge base has over 2,800 articles, we knew that there would be questions that these would not answer for users of the Elastic Support Assistant. For example: What new features would be available if I upgraded from Elastic Cloud 8.11 to 8.14? wouldn’t be present in technical support articles since it’s not a break-fix question or in the OpenAI model since 8.14 is past the model training date cutoff.
We elected to address this by including more official Elastic sources, such as product documentation across all versions, Elastic blogs, Search/Security/Observability Labs and Elastic onboarding guides as the source for our semantic search implementation, similar to this example. By using semantic search to retrieve these docs when they were relevant, we enabled the Support Assistant to answer a much broader range of questions.
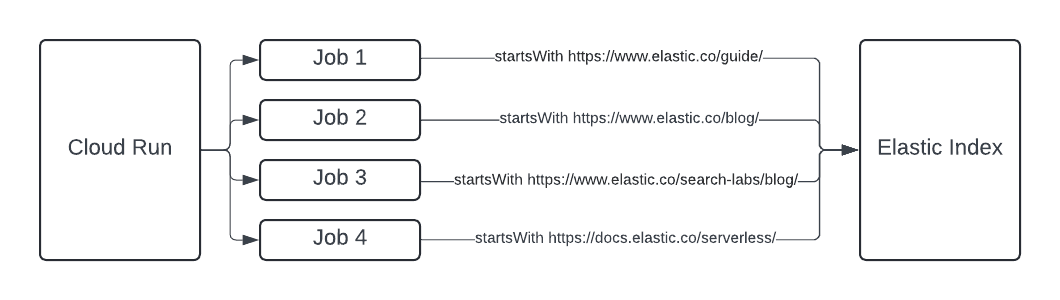
The ingest process includes several hundred thousand documents and deals with complex site maps across Elastic properties. We elected to use a scraping and automation library called Crawlee in order to handle the scale and frequency needed to keep our knowledge library up to date.
Each of the four crawler jobs executes on Google Cloud Run. We chose this because jobs can have a timeout of 24 hours and they can be scheduled without the use of Cloud Tasks or PubSub. Our needs resulted in a total of four jobs running in parallel, each with a base url that would capture a specific category of documents. When crawling websites we recommend starting with base urls that do not have overlapping content so as to avoid the ingestion of duplicates. This must be balanced with crawling at too high of a level and ingesting documents that aren't helpful to your knowledge store. For example, we crawl https://elastic.com/blog and https://www.elastic.co/search-labs/blog rather than elastic.co/ since our objective was technical documents.
Even with the correct base url, we needed to account for different versions of the Elastic product docs (we have 114 unique versions across major/minors in our knowledge library). First, we built the table of contents for a product page in order to load and cache the different versions of the product. Our tech stack is a combination of Typescript with Node.js and Elastic's EUI for the front end components.
We then load the table of contents for a product page and cache the versions of the product. If the product versions are already cached, then the function will do nothing. If the product versions are not cached, then the function will also enqueue all of the versions of the product page so that it can crawl all versions of the docs for the product.
Request Handlers
Since the structure of the documents we crawl can vary widely, we created a request handler for each document type. The request handler tells the crawler which CSS to parse as the body of the document. This creates consistency in the documents we store in Elasticsearch and captures the text that would be relevant. This is especially important for our RAG methodology as any filler text would also be searchable and could be returned incorrectly as a result for the context we send to the LLM.
Blogs Request Handler
This example is our most straightforward request handler. We specify that the crawler should look for a div element that matches the provided parameter. Any text within that div will be ingested as the content for the resulting Elasticsearch document.
Product Documentation Request Handler
In this product docs example, multiple css selectors contain text we want to ingest, giving each selector a list of possibilities. Text in one or more of these matching parameters will be included in the resulting document.
The crawler also allows us to configure and send an authorization header, which prevents it from being denied access to scrape pages of all Elastic product documentation versions. Since we needed to anticipate that users of the Support Assistant might ask about any version of Elastic, it was crucial to capture enough documentation to account for nuances in each release. The product docs do have some duplication of content as a given page may not change across multiple product versions. We handled this by fine-tuning our search queries to default to the most current product docs unless otherwise specified by the user. The fourth blog will cover this in detail.
Enriching Document Sources
Our entire knowledge library at Elastic consists of over 300,000 documents. The documents varied widely in the type of metadata they had, if any at all. This created a need for us to enrich these documents so search would accommodate a larger range of user questions against them. At this scale, the team needed the process of enriching documents to be automated, simple and able to both backfill existing documents and to run on demand as new documents are created. We chose to use Elastic as a vector database and enable ELSER to power our semantic search – and generative ai to fill in the metadata gaps.
ELSER
Elastic ELSER (Elastic Learned Sparse Embedding Retrieval) enriches Elastic documents by transforming them into enriched embeddings that enhance search relevance and accuracy. This advanced embedding mechanism leverages machine learning to understand the contextual relationships within the data, going beyond traditional keyword-based search methods. This transformation allows for faster retrieval of pertinent information, even from large and complex datasets such as ours.
What made ELSER a clear choice for our team was the ease of setup. We downloaded and deployed the model, created an ingest pipeline and reindexed our data. The result were enriched documents.
How to install and run the support diagnostics troubleshooting utility is a popular technical support article. ELSER computed the vector database embeddings for both the title and summary since we use those with semantic search as part of our hybrid search approach. The result was stored in an Elastic doc as the ml field.
Vector Embeddings for How to Install and Run…
The embeddings in the ml field are stored as a keyword and vector pair. When a search query is issued, it is also converted into an embedding. Documents that have embeddings close to the query embedding are considered relevant and are retrieved and ranked accordingly. The example below is what the ELSER embeddings look like for the title field How to install and run the support diagnostics troubleshooting utility. Although, only the title is shown below, the field will also have all the vector embeddings for the summary.
Summaries & Questions
Semantic search could only be as effective as the quality of the document summaries. Our technical support articles have a summary written by support engineers but other docs that we ingested did not. Given the scale of our ingested knowledge, we needed an automated process to generate these. The simplest approach was to take the first 280 characters of each document and use that as the summary. We tested this and found that it led to poor search relevancy.
One of our team’s engineers had the idea to instead use AI to do this. We created a new service which leveraged OpenAI GPT3.5 Turbo to backfill all of our documents which lacked a summary upon ingestion. In the future, we intend to test the output of other models to find what improvements we might see in the final summaries. As we have a private instance for GPT3.5 Turbo, we chose to use it in order to keep costs lows at the scale required.
The service itself is straightforward and a result of finding and fine tuning an effective prompt. The prompt provides the large language model with a set of overall directions and then a specific subset of directions for each task. While more complex, this enabled us to create a Cloud Run job that loops through each doc in our knowledge library. The loop does the following tasks before moving onto the next document.
- Sends an API call to the LLM with the prompt and the text from the document's
contentfield. - Waits for a completed response (or handles any errors gracefully).
- Updates the
summaryandquestionsfields in the document. - Runs the next document.
Cloud Run allows us to control the number of concurrent workers so that we don't use all of the allocated threads to our LLM instance. Doing so would result in a timeout for any users of the Support Assistant, so we elected to backfill the existing knowledge library over a period of weeks -- starting with the most current product docs.
Create the Overall Summary
This section of the prompt outputs a summary that is as concise as possible while still maintaining accuracy. We achieve this through asking the LLM to take multiple passes at the text it generates and check for accuracy against the source document. Specific guidelines are indicated so that each document's outputs will be consistent. Try this prompt for yourself with an article to see the type of results it can generate. Then change one or more guidelines and run the prompt in a new chat to observe the difference in output.
Create the Second Summary Type
We create a second summary which enables us to search for specific passages of the overall text that will represent the article. In this use case, we try to maintain a closer output to the key sentences already within the document.
Create a Set of Relevant Questions
In addition to the summaries, we asked the GPT to generate a set of questions that would be relevant to the document. This will be used in several ways, including semantic-search based suggestions for the user. We are also testing the relevancy of including the question set in our hybrid search approach for the Elastic Support Assistant so that we search the title, summary, body content and question set.
Support Assistant Demo
Despite a large number of tasks and queries that run in the back end, we elected to keep the chat interface itself simple to use. A successful Support Assistant will work without friction and provide expertise that the user can trust. Our alpha build is shown below.
Key Learnings
The process of building our current knowledge library has not been linear. As a team we test new hypotheses daily and observe the behaviors of our Support Assistant users to understand their needs. We push code often to production and measure the impact so that we have small failures rather than feature and project level ones.
Smaller, more precise context makes the LLM responses significantly more deterministic.
We initially passed larger text passages as context to the user question. This decreased the accuracy of the results as the large language model would often pass over key sentences in favor of ones that didn’t answer the question. This transitioned search to become a problem of both finding the right documents and how these aligned with user questions.
An RBAC strategy is essential for managing what data a given persona can access. Document level security reduced our infrastructure duplication, drove down deployment costs and simplified the queries we needed to run.
As a team, we realized early on that our tech debt would prevent us from achieving a lovable experience for the Support Assistant. We collaborated closely with our product engineers and came up with a blueprint for using the latest Elastic features. We will write an in-depth blog about our transition from Swiftype and Appsearch to elaborate on this learning. Stay tuned!
One search query does not cover the potential range of user questions. More on this in Part 4 (search and relevancy tuning for a RAG chatbot).
We measured the user sentiment of responses and learned to interpret user intent much more effectively. In effect, what is the search question behind the user question?
Understanding what our users search for plays a key role in how we enrich our data.
Even at the scale of hundreds of thousands of documents, we still find gaps in our documented knowledge. By analyzing our user trends we are able to determine when to add new types of sources and better enrich our existing data to allow us to package together a context from multiple sources that the LLM can use for further elaboration.
What's next?
At the time of writing, we have vector embeddings for the more than 300,000 documents in our indices and over 128,000 ai-generated summaries with an average of 8 questions per document. Given that we only have ~8,000 technical support articles with human-written summaries, this was a 10x improvement for our semantic search results.
Field Engineering has a roadmap of new ways to expand our knowledge library and stretch what's technically possible with our explicit search interface and the Elastic Support Assistant. For example, we plan to create an ingest and search strategy for technical diagrams and ingest Github issues for Elastic employees.
Creating the knowledge sources was just one step of our journey with the Elastic Support Assistant. Read about our initial GenAI experiments in the first blog here. In the third blog, we dive into the design and implementation of the user experience. Following that, our fourth blog discusses our strategies for tuning search relevancy to provide the best context to LLMs. Stay tuned for more insights and inspiration for your own generative AI projects!
Related Content

July 9, 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

July 7, 2026
Your compliance posture just got an upgrade: Elasticsearch now supports FIPS 140-3
Elastic 9.4 brings FIPS 140-3 support for Elasticsearch and Kibana to GA. Here's what changes for federal, defense and regulated deployments, and how to migrate from 140-2.

July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

June 29, 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.