Agent Builder is available now GA. Get started with an Elastic Cloud Trial, and check out the documentation for Agent Builder here.
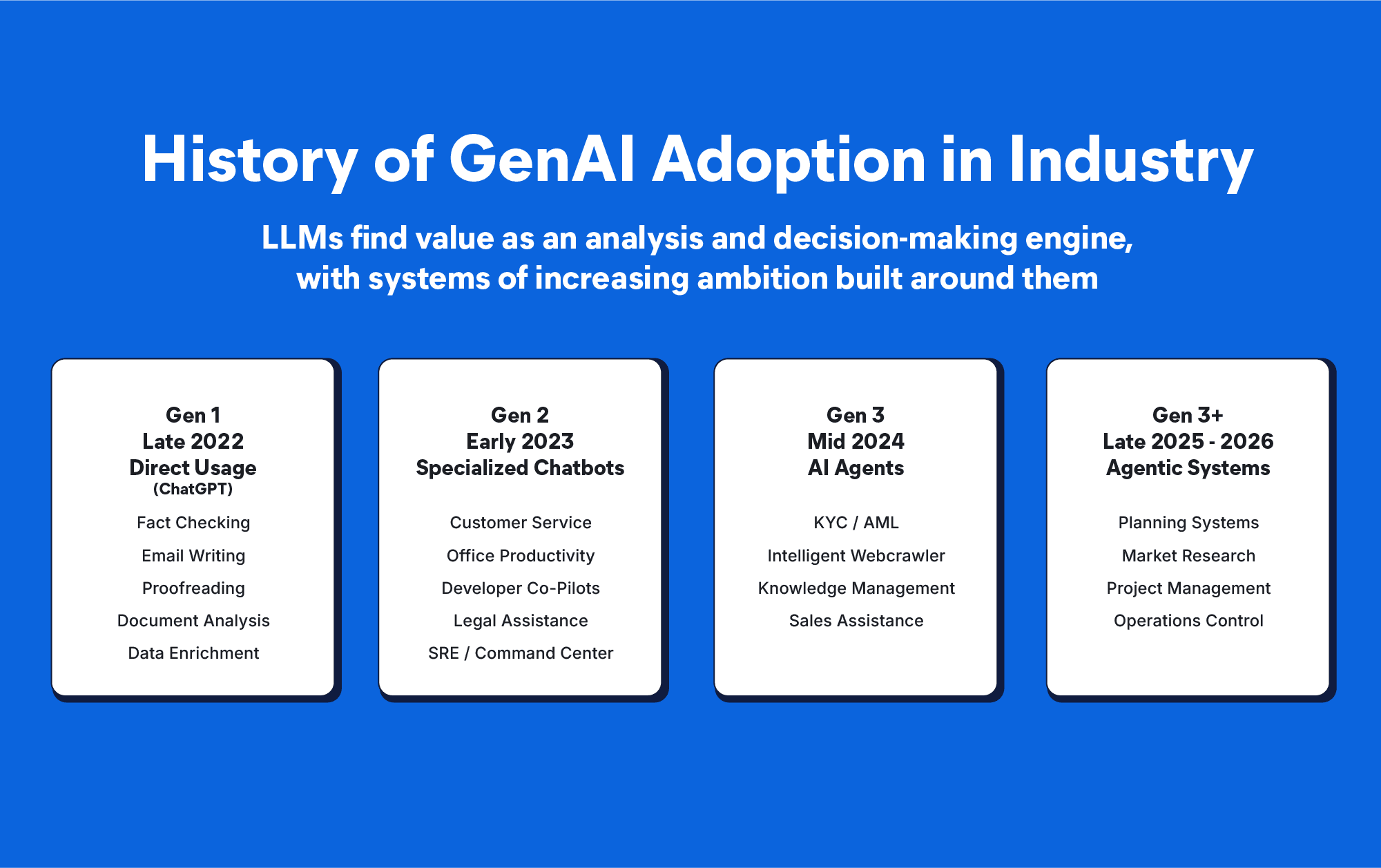
Applications of large language models throughout the industry.
In industry use cases, there are two primary modes of interacting with large language models (LLMs). Direct querying, ie., conversing with an LLM on an ad-hoc basis, is useful for getting assistance on tasks like summarization, proofreading, information extraction, and non-domain-specific querying.
For specific business applications, such as in customer relationship management, maintenance of IT systems, and investigative work, to name only a few examples, direct LLM usage is insufficient. Private, enterprise-specific information, or information about niche interests and topics, or even from specific documents and written sources, tends to be lacking from LLM training datasets.
In addition, real-world data is constantly changing, and enterprise contexts are constantly evolving. LLMs also tend to require reinforcement of factual accuracy. All these factors limit the utility value of using LLMs directly for enterprise use-cases, especially those requiring up-to-date factual information about specific technical or business topics.
Retrieval Augmented Generation (RAG), the use of searchable data stores to retrieve information sources relevant to the context and intention of a user query, was popularized as a way to address this deficiency. A large amount of work has been done to implement, assess, and improve the quality of RAG applications, and RAG has enjoyed widespread adoption in enterprise use cases for productivity enhancement and workflow automation. However, RAG does not leverage the decision-making capacity of large language models.
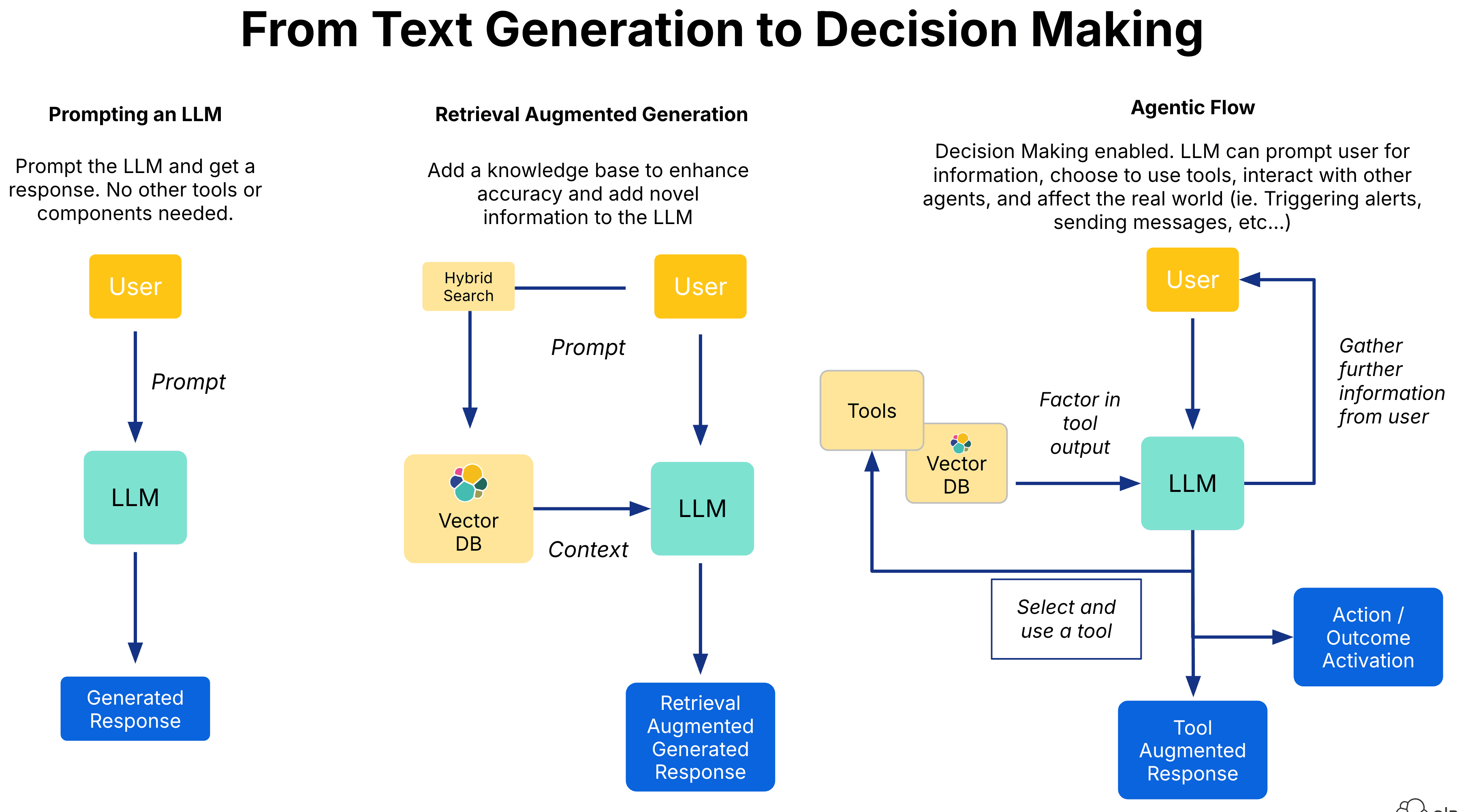
Different application modes of large language models.
The agentic model revolves around the LLM being able to take specific actions in response to a user input. These actions may involve the use of tools to augment the LLM's existing capabilities. In this sense, RAG functions as a long-term memory store that the LLM agent may choose to use to augment and reinforce answers to user queries. Where the traditional RAG model involves the LLM querying one or more knowledge bases, an agentic implementation allows an LLM to choose from a set of knowledge bases. This allows for more flexible question-answering behavior, and can improve accuracy, as information from irrelevant knowledge bases is omitted, reducing potential sources of noise. We might call such a system an "agent knowledge base." Let's take a look at how to implement such a system using Elasticsearch.
Designing an agent knowledge base
All code may be found in the GitHub repo.
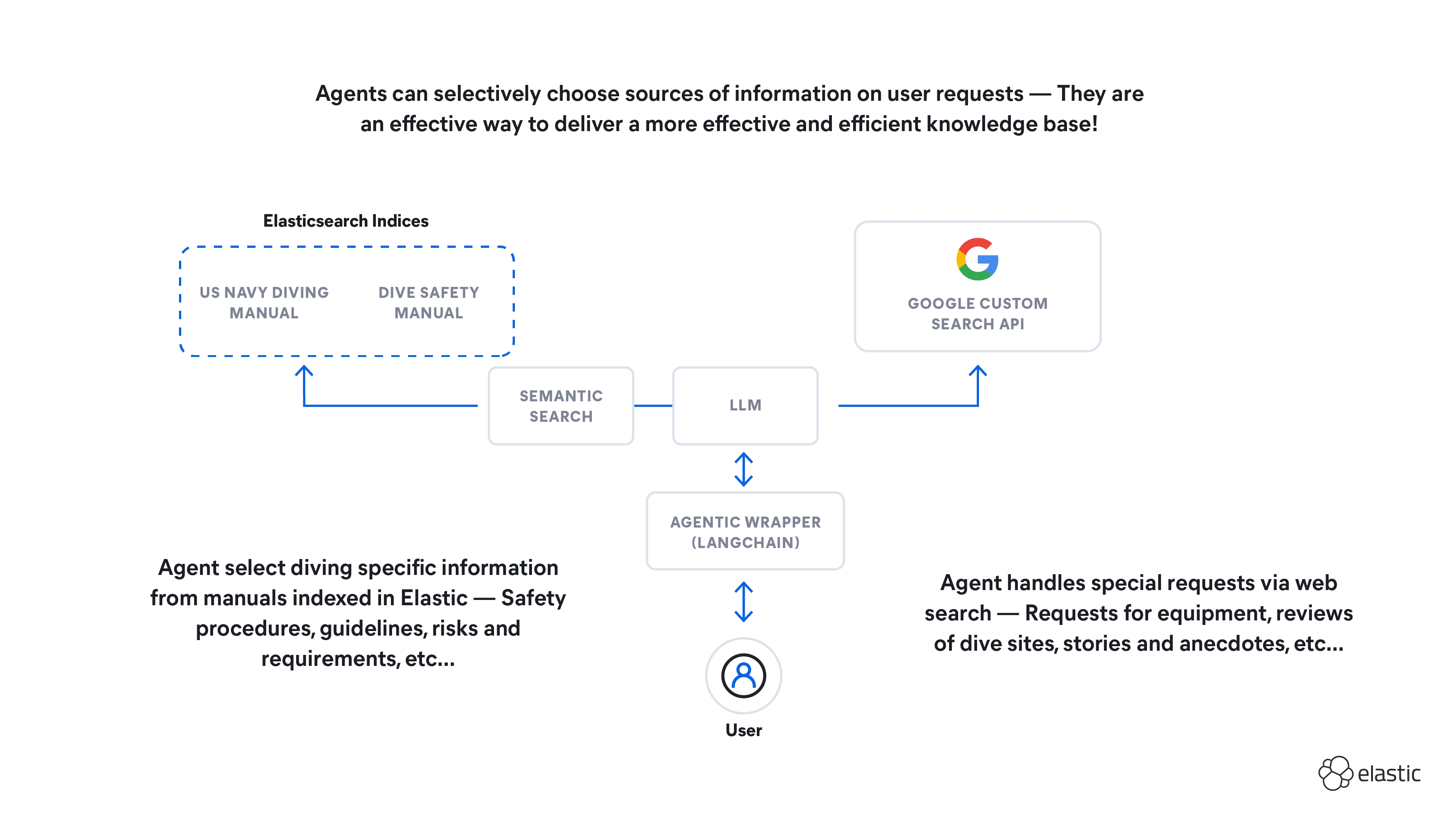
The agent knowledge base implemented in this article.
I recently became interested in scuba diving after trying it and realizing it could cure my persistent thalassophobia, so I decided to set up an agentic knowledge base for diving specifically.
- The US Navy Dive Manual - Containing a wealth of technical detail about diving operations and equipment.
- Diving Safety Manual - Containing general guidelines and procedures aimed at recreational divers.
- The Google Custom Search API - Capable of searching the web for any information not contained within the two manuals.
The intention was that this Diving Assistant would be a one-stop shop for diving-related knowledge, which would be capable of responding to any query, even those out of scope of the knowledge bases ingested. The LLM would recognize the motivation behind a user query, and select the source of information most likely to be relevant. I decided to use LangChain as the agentic wrapper, and built a streamlit UI around it.
Setting up the endpoints
I start by creating a .env file and populating it with the following variables:
This project makes use of a GPT-4o-Mini deployed on Azure OpenAI, as well as the Google Custom Search API, and an Elastic Cloud deployment to hold my data. I also add a custom system prompt encouraging the LLM to avoid wordiness as much as possible.
Ingestion and processing
The US Navy Dive Manual and Diving Safety Manual are in PDF format, so the next step was to ingest them into an Elastic Cloud deployment. I set-up this python script using Elastic's bulk API to upload documents to Elastic Cloud:
After downloading the US Navy Dive Manual PDF and storing it in its own folder, I use LlamaIndex's SimpleDirectoryReader to load the PDF data, then trigger a bulk upload:
This sends all the text content to Elastic Cloud, with each page of the PDF as a separate document, to an index called us_navy_dive_manual_raw. No further processing is done, so the process of uploading all 991 pages takes less than a second. The next step is to do semantic embedding within Elastic Cloud.
Semantic data embedding and chunking
In my Elastic Cloud DevTools console, I first deploy the ELSER v2 model using the Elastic inference API
I then define a simple pipeline. Each document stores the text of a page from the dive manual in the body field, so I copy the contents of body to a field called semantic_content.
I then create a new index called us_navy_dive_manual, and set semantic_content as a semantic_text field:
I then trigger a reindex job. Now the data will flow from us_navy_dive_manual_raw, to be chunked and embedded using ELSER, and be reindexed into us_navy_dive_manual ready for use.
I repeat this process for the Diving Safety Manual, and with this simple process, data ingestion is completed.
Tooling for agentic search
This agent is relatively simple, so I make use of LangChain's AgentExecutor which creates an agent and bundles it with a set of tools. Complex decisionmaking flows can be achieved using the LangGaph implementation , which we will use in a future blog. We will focus on the parts related to the agents, so for details on the actual streamlit UI, please check out the github repo.
I create two tools for my agent to use. The first is an ElasticSearcher class, which performs a semantic search over an Elastic index, then returns the top 10 articles as text.
The second tools is the Googler class, which calls the Google Custom Search API to perform a general web search.
I then create a set of tools for the agent to use. The description of each tool is an important part of the prompt engineering, as the agent will refer to it primarily when choosing which tool to use for its response to a user query.
Next, I define an LLM using the AzureChatOpenAI abstraction:
And also create a custom prompt for the LLM, telling it how to make use of the tools and their outputs.
Finally, I define the agent, passing it the LLM, prompt, and toolset, and integrate it into the rest of the UI.
And with that, we are ready to test out our agent knowledge base.
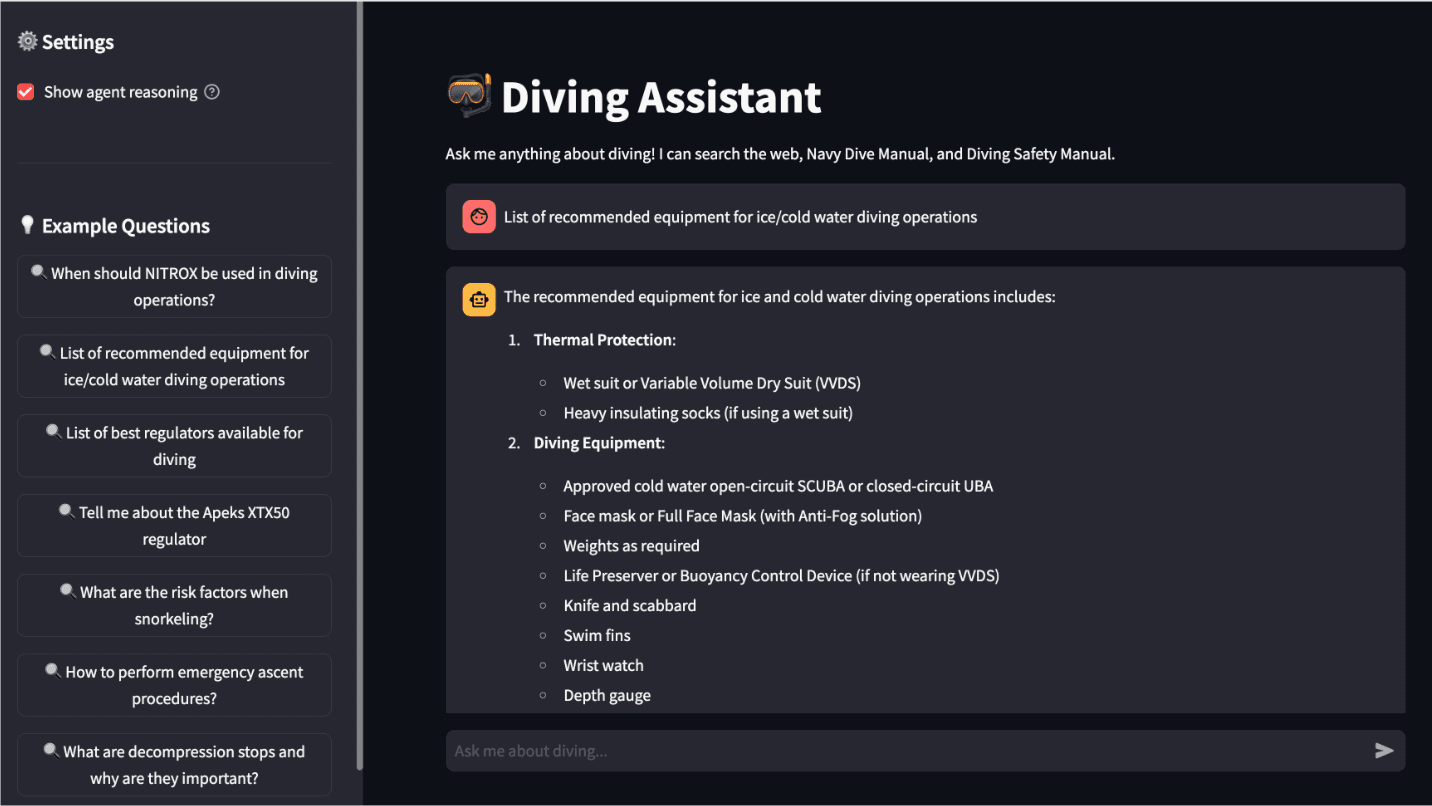
The UI implemented for the agentic knowledge base.
Test 1: Retrieve knowledge from a specific knowledge base
First, we should test that the knowledge base component is working as intended. Let's start by asking a detailed technical question. The agent should choose the right knowledge base, retrieve some information, and use it to craft a response.
The UI displays the Agent's thought process, and the first thought it has is to consult the diving safety manual:
The agent uses the NavyDiveManual tool to perform a semantic search of the us_navy_dive_manual index. The result is information like this:
Which the LLM then uses to craft a response:
The response is exactly what we wanted. Great!
Test 2: Iteratively refine knowledge collection
The next test is to see whether the agent can select multiple sources of knowledge to refine its responses.
Let's ask a more open ended question:
The first thought the agent has involves searching Google for information specific to risk factors and dangers:
This returns web results such as:
The agent then chooses to consult the diving_safety_manual, and takes the appropriate action to retrieve safety protocols and guidelines.
Which returns relevant information from the DivingSafetyManual tool:
Finally, the LLM provides a comprehensive answer, containing both risk factors and safety guidelines:
Test 3: Searching out of scope
The final test is to see what happens when the user asks a query that is certainly out of scope of the prepared knowledge bases. Let's ask about a specific diving product:
The agent's first thought is to check the external web for relevant information:
It discovers a wealth of information from commercial and diving hobbyist sites, and returns both technical specifications and user feedback:
The agent did not choose to search the US Navy Dive Manual, which is concerned with operational planning, or with the DivingSafetyManual.
Conclusion
In a traditional RAG implementation, we might have chosen to force the LLM to search and use information from all three data sources simultaneously, but this would have negatively impacted accuracy by introducing noise from irrelevant information. With the agentic knowledge base, we see the LLM making targeted searches to specific sources of knowledge based on user intention and context. The agent is able to refine the knowledge collected by building upon initial searches, and combining them with information collected from other sources.
The agent is also able to handle questions out of the scope of its prepared data, and is also able to exclude knowledge bases not pertinent to the query - Significant enhancements on the traditional RAG model.
This agent knowledge base concept provides a graceful way to combine many different sources into a coherent and comprehensive system, and the next steps would be to expand the range of actions and the diversity of information that can be referred to. Introducing workflows for fact-checking and cross referencing would be a boon to overall reliability, and tools for specialized capabilities like calculation would be a very interesting direction to explore.
Related Content
July 20, 2026
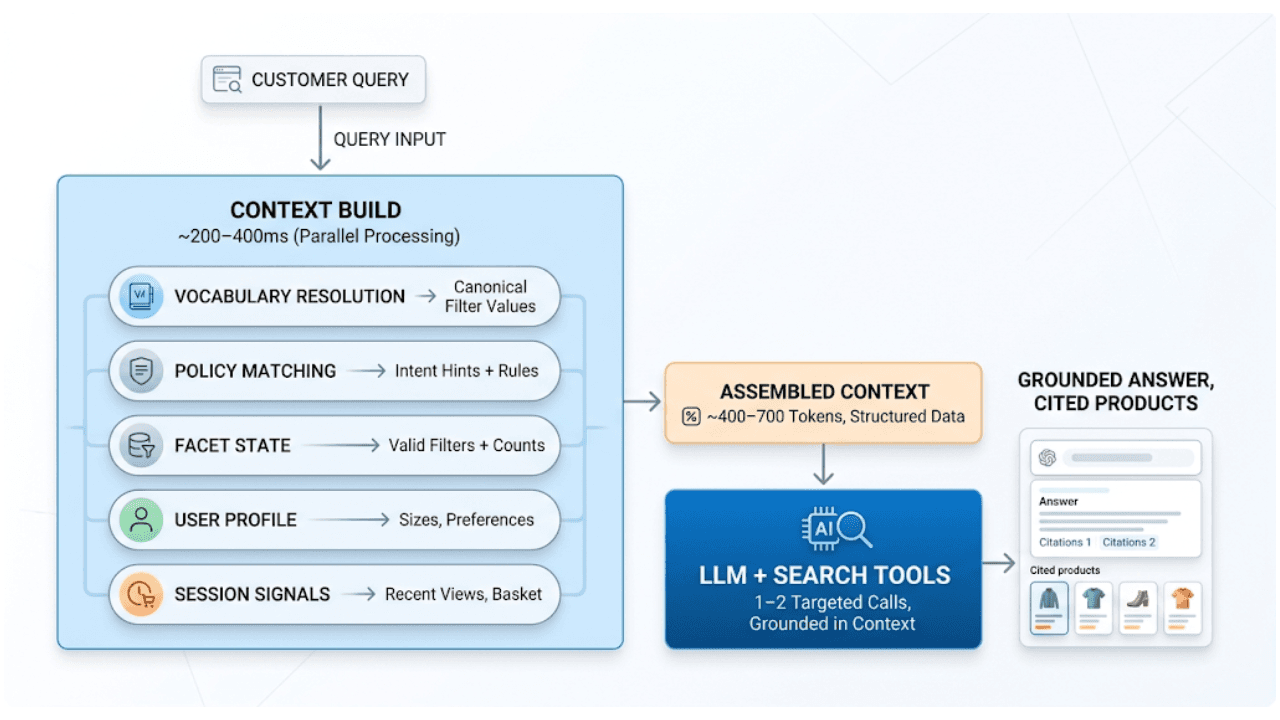
AI shopping agents: Why context comes before the query
AI shopping agents that guess at your vocabulary make expensive mistakes. Pre-computed catalog context stops the guessing before the first tool call.

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.
June 26, 2026
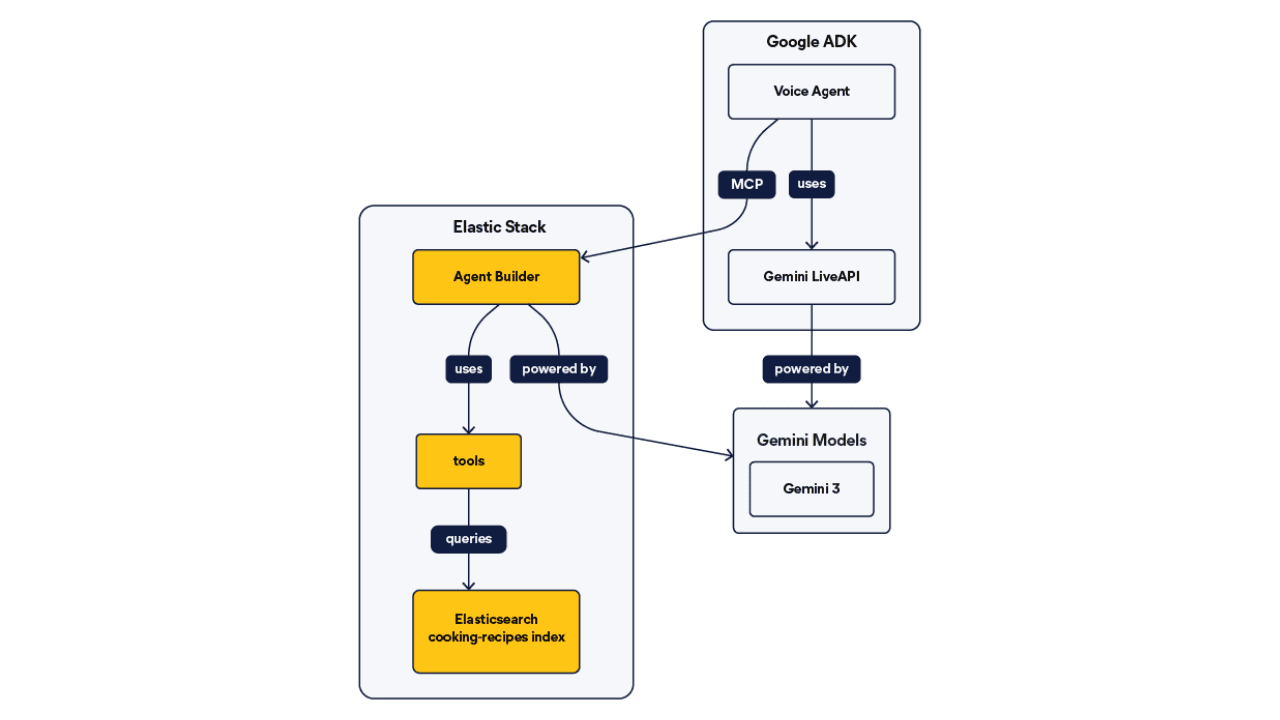
Talk to your Elasticsearch data: building a real-time voice agent with Google ADK and MCP in 3 components
Wire Google ADK's real-time voice streaming to your Elasticsearch data via Agent Builder's built-in MCP server; no custom integration code required.