単一のソリューションでデータを監視、保護、検索します。アプリケーション監視から検出まで、Kibanaはユースケースに対応する多機能なプラットフォームです。今すぐ14日間の無料トライアルを始めましょう。
Iulia Feroli が執筆したこのシリーズの最初の部分では、Spotify Wrapped データを取得して Kibana で視覚化する方法について説明しました。パート 2 では、データをさらに深く掘り下げて、他に何がわかるかを調べます。これを実現するために、少し異なるアプローチを活用し、 Spotify から Elasticsearch を使用してデータを Elasticsearch にインデックスします。このツールは少し高度で、もう少しセットアップが必要ですが、その価値はあります。データがより構造化され、より複雑な質問をすることができます。
最初のSpotify Wrapped分析との違い
最初のブログでは、Spotify エクスポートを直接使用し、正規化タスクやその他のデータ処理は実行しませんでした。今回も同じデータを使用しますが、データをより使いやすくするためにデータ処理を行います。これにより、次のようなより複雑な質問に答えることができるようになります。
- トップ 100 の曲の平均再生時間はどれくらいですか?
- トップ 100 の曲の平均的な人気はどれくらいですか?
- 曲の平均視聴時間はどれくらいですか?
- 最もスキップされたトラックは何ですか?
- いつトラックをスキップしたいですか?
- 一日のうち特定の時間帯に他の時間帯よりも多く音楽を聴いていますか?
- 特定の曜日に他の曜日よりも多く聴いていますか?
- 特に興味のある月ですか?
- 最も長い聴取時間を持つアーティストは誰ですか?
Spotify Wrapped は、今年何を聴いたかを示してくれる、毎年楽しい体験です。前年比の変化は表示されないため、かつてはトップ 10 に入っていたものの、現在は消えてしまったアーティストを見逃してしまう可能性があります。
Spotify Wrapped データを分析用に処理する
最初の投稿と 2 番目の投稿では、データの処理方法に大きな違いがあります。最初の投稿のデータを使用して作業を継続する場合は、いくつかのフィールド名の変更を考慮する必要があり、また、ES|QL に戻ってhour of dayなどの特定の抽出をオンザフライで実行する必要があります。
それでも、皆さんはこの投稿を追うことができるはずです。Spotify から Elasticsearch リポジトリへのデータ処理では、Spotify API に曲の長さや人気度を問い合わせ、いくつかのフィールドの名前を変更したり、強化したりします。たとえば、Spotify エクスポートのartistフィールド自体は単なる文字列であり、フィーチャーや複数のアーティストのトラックを表すものではありません。
ダッシュボードでSpotify Wrappedデータを視覚化する
データを視覚化するために Kibana でダッシュボードを作成しました。ダッシュボードはここから入手でき、Kibana インスタンスにインポートできます。ダッシュボードは非常に広範囲にわたっており、上記の質問の多くに答えてくれます。
いくつかの質問とその答え方を一緒に見ていきましょう。
トップ 100 の曲の平均再生時間はどれくらいですか?
この質問に答えるには、Lens または ES|QL を使用できます。3つのオプションをすべて検討してみましょう。この質問を Elasticsearch のやり方で正しく表現してみましょう。上位 100 曲を見つけて、それらの曲すべてを合わせた平均時間を計算します。Elasticsearch の用語では、これは 2 つの集約になります。
- トップ100曲を調べる
- 100 曲の平均再生時間を計算します。
Lens
Lens では、これはかなり簡単です。新しい Lens を作成し、テーブルに切り替えて、 titleフィールドをテーブルにドラッグ アンド ドロップします。次に、 titleフィールドをクリックしてサイズを 100 に設定し、 accuracyモードを設定します。次に、 durationフィールドをテーブルにドラッグ アンド ドロップし、 last valueを使用します。実際に必要なのは、各曲の長さの最後の値だけだからです。同じ曲の長さは 1 つだけです。このlast value集計の下部には要約行のドロップダウンがあり、 averageを選択すると要約行が表示されます。

ES|QL
ES|QL は、DSL や集約と比較するとかなり新しい言語ですが、非常に強力で使いやすいです。ES|QL で同じ質問に答えるには、次のクエリを記述します。
この ES|QL クエリを段階的に説明します。
from spotify-history- これは私たちが使用しているインデックス パターンです。stats duration=max(duration), count=count() by title- これは最初の集計であり、各曲の最大継続時間と各曲の数を計算しています。Lens で使用されているlast valueの代わりにmaxを使用します。これは、ES|QL には現在 first または last がないためです。sort count desc- 曲は各曲のカウントで並べ替えられるため、最も多く聴かれた曲が一番上に表示されます。limit 100- 結果は上位 100 曲に制限されます。stats Average duration of the songs=avg(duration)- 曲の平均再生時間を計算します。
私にとって特に興味深い月はありますか?
この質問に答えるには、ランタイム フィールドと ES|QL の助けを借りて Lens を使用できます。すぐに気づくのは、データ内にmonthを直接示すフィールドがないため、代わりに@timestampフィールドから計算する必要があるということです。これを行うには複数の方法があります。
- ランタイムフィールドを使用してレンズに電力を供給する
- ES|QL
個人的には、ES|QL の方がすっきりして素早いソリューションだと思います。
これで完了です。特別なことは何も必要ありません。 DATE_EXTRACT関数を利用して@timestampフィールドから月を抽出し、それを集計することができます。ES|QL 視覚化を使用すると、それをダッシュボードにドロップできます。

アーティストごとの年間視聴時間はどのくらいですか?
その背後にある考え方は、アーティストが単なる一回限りのものなのか、それとも再発するものなのかを確認することです。私の記憶が正しければ、Spotify では年間ラップのトップ 5 アーティストのみが表示されます。おそらく、6 位のアーティストはずっと同じままでしょうか、それとも 10 位以降は大きく変わるのでしょうか?
これを最も簡単に表現したものの 1 つは、パーセンテージ棒グラフです。これには Lens を使用できます。次の手順に従ってください:
listened_to_msフィールドをドラッグ アンド ドロップします。このフィールドは、曲を聴いた時間をミリ秒単位で表します。デフォルトでは、Lens はmedian集約を作成しますが、これは不要なので、 sumに変更します。上部の棒グラフの種類として、 stackedではなくpercentage選択します。内訳については、 artist選択し、トップ 10 を選択してください。Advancedドロップダウンでは必ずaccuracy modeを選択してください。各カラーブロックは、このアーティストをどれだけ聴いたかを表します。タイムピッカーに応じて、バーは日、週、月、年などの値を表す場合があります。週ごとの内訳が必要な場合は、 @timestampを選択し、 mininum intervalをyearに設定します。私の場合、最もよく聴いたアーティストはFred Again..であり、総聴取時間の約 12% がFred Again..に費やされたことがわかります。また、2024年にはFred Again..若干減少しましたが、 Jamie XX大幅に増加しました。バーの大きさだけを比較してみましょう。また、 Billie Eilishが 2024 年に継続的に再生されている間、バーの幅が広くなっていることもわかります。これは、2023 年よりも 2024 年にBillie Eilish多く聴いたことを意味します。

全体の視聴時間に対するアーティストごとのトップトラックはどうですか?
それは長い質問ですね。私が何を言いたいのか、それで説明してみたいと思います。Spotify では、特定のアーティストのトップソング、または全体のトップ 5 曲を教えてくれます。それは確かに興味深いですが、アーティストの内訳はどうですか?私の時間はすべて、何度も繰り返し再生する 1 つの曲に費やされているのでしょうか、それとも均等に分散されているのでしょうか?
新しいレンズを作成し、タイプとしてTreemapを選択します。metricについては、前と同じように、 sumを選択し、フィールドとしてlistened_to_msを使用します。group byには 2 つの値が必要です。最初はartistで、次に 2 番目にtitleを追加します。中間結果は次のようになります。

これをトップ 100 アーティストに変更し、詳細ドロップダウンでotherを選択解除し、精度モードを有効にしましょう。タイトルをトップ 10 に変更し、精度モードを有効にします。最終結果は次のようになります。
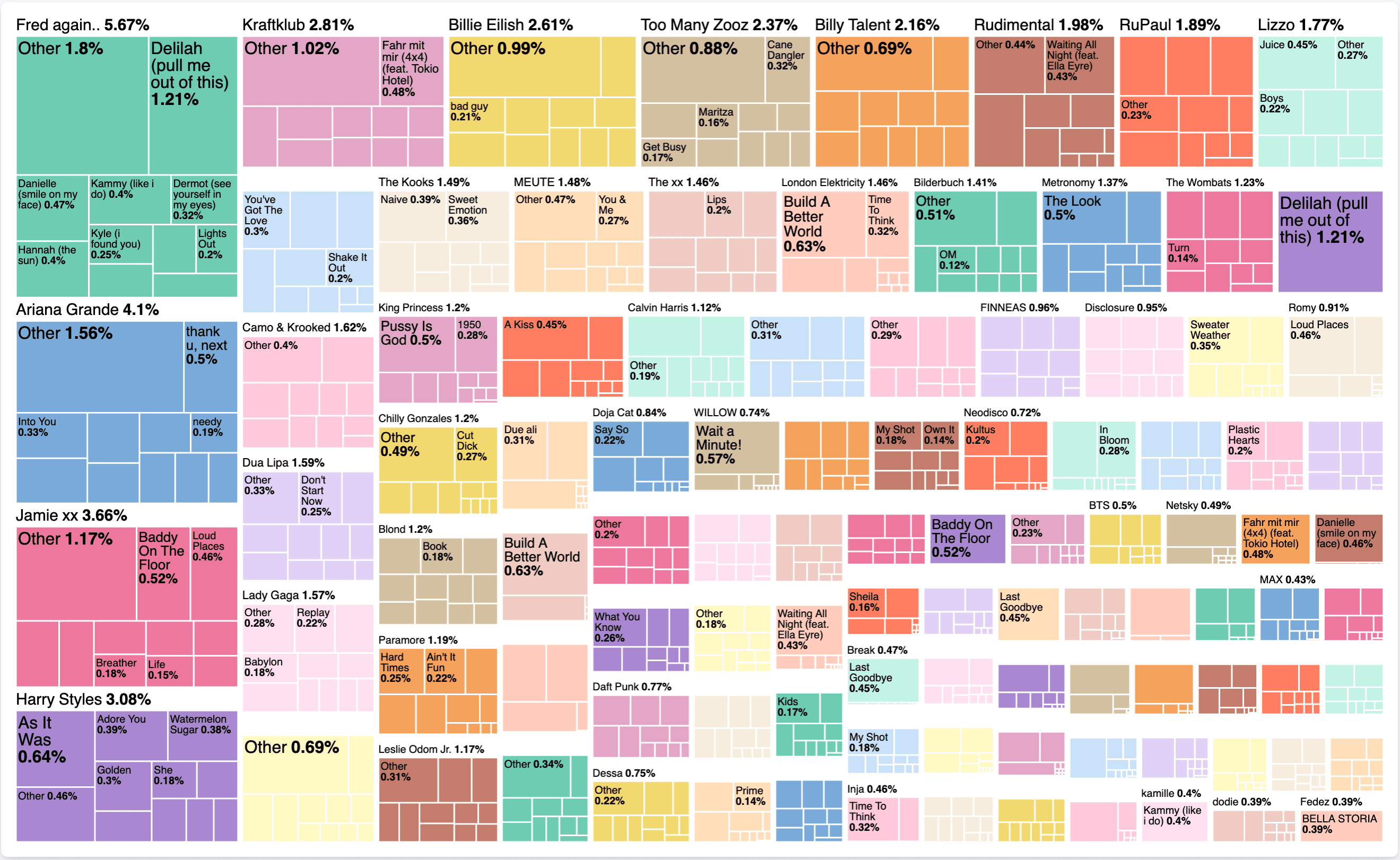
これは具体的に何を意味するのでしょうか?時間要素を見なくても、Spotify での私の全視聴履歴のうち、5.67% をFred Again..視聴に費やしたことがわかります。特に、その時間のうち 1.21% をDelilah (pull me out of this)視聴に費やしました。アーティストが占める曲が 1 曲だけなのか、それとも他の曲もあるのかどうかを見るのは興味深いです。ツリーマップ自体は、このようなデータ分布を表すのに適した形式です。
特定の時間と曜日に聞きますか?
そうですね、 Heat Mapを活用した Lens 視覚化を使えば、非常に簡単に答えることができます。新しいレンズを作成するには、 Heat Mapを選択します。Horizontal AxisではdayOfWeekフィールドを選択し、トップ 3 ではなくTop 7に設定します。Vertical Axisの場合はhourOfDayを選択し、 Cell Valueの場合は単純なCount of records選択します。これで次のパネルが生成されます:

このレンズには、解釈するときに邪魔になる厄介な点がいくつかあります。少し整理してみましょう。まず、凡例はあまり気にしないので、上部の三角形、四角形、円の記号を使用して無効にします。
さて、2番目に面倒なのは、日付の並べ替えです。指定した値に応じて、月曜日、水曜日、木曜日などになります。hourOfDayは正しくソートされています。日をソートする方法は面白いハックであり、 Top Valuesの代わりにFilters使用すると言われています。dayOfWeekをクリックしてFiltersを選択すると、次のようになります。

さあ、日付を入力し始めましょう。1 日につき 1 つのフィルター。"dayOfWeek" : MondayにしてラベルMondayを付け、これを繰り返します。
ただし、1 つの注意点は、Spotify がタイムゾーン情報なしで UTC+0 でデータを提供していることです。もちろん、IP アドレスと視聴した国も提供されており、そこからタイムゾーン情報を推測することはできますが、これは不正確になる可能性があり、米国のように複数のタイムゾーンがある国では面倒すぎる可能性があります。これは重要です。Elasticsearch と Kibana はタイムゾーンをサポートしており、 @timestampフィールドに正しいタイムゾーンを指定すると、Kibana は自動的に時間をブラウザの時間に合わせて調整します。
完成するとこのようになり、私は勤務時間中は非常に積極的に聞き手であり、土曜日と日曜日はそれほどではないことがわかります。

まとめ
このブログでは、Spotify データが提供する複雑な点について、もう少し詳しく説明します。いくつかの視覚化を実現するためのシンプルで簡単な方法をいくつか紹介しました。自分の視聴履歴をこれほど細かく制御できるのは、本当に素晴らしいことです。シリーズの他の部分もご覧ください:
関連記事

2026年5月22日
Kibanaはダッシュボードの読み込み時間を最大25%短縮 - その背後にあるポーリング戦略を紹介
Kibanaが継続的なポーリングとブラウザ側のHTTP/2検出を使用して、ダッシュボードの読み込み時間を最大25%削減し、HTTP/1に自動的にフォールバックする仕組みをご覧ください。

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年5月25日
KibanaのAI Chatがダッシュボードをネイティブにレンダリングするように
KibanaのElastic AI Chatでは、自然言語からダッシュボードを構築し、ビジュアルと分析を1つのスレッドに保持し、再利用可能なKibanaオブジェクトとして保存できるようになりました。

変数コントロールによるKibanaダッシュボードのインタラクション性の向上
Kibana 8.18+の変数コントロールを使用して、個々の可視化をフィルタリングし、時間間隔を調整し、Kibanaダッシュボード内の異なるフィールドでグループ化する方法を学びます。
