単一のソリューションでデータを監視、保護、検索します。アプリケーション監視から検出まで、Kibanaはユースケースに対応する多機能なプラットフォームです。今すぐ14日間の無料トライアルを始めましょう。
最近、Elasticsearch の新しい強力な パイプ クエリ言語 である ES|QL の 新しい 地理空間検索 機能 の使用方法を説明するブログを公開しました。これらの機能を使用するには、Elasticsearch に地理空間データが必要です。そこでこのブログでは、地理空間データを取り込む方法と、それを ES|QL クエリで使用する方法を紹介します。

Kibanaを使用した地理空間データのインポート
前回のブログの例に使用したデータは、統合テストのために社内で使用しているデータに基づいています。便宜上、Kibana を使用して簡単にインポートできるいくつかの CSV ファイルの形式でここに含めました。データには空港、都市、都市境界が混在しています。データは以下からダウンロードできます:
- 空港.csv
- これには 3 つのデータセットの結合が含まれます。
- Natural Earthの空港(名称、場所、関連データ)
- SimpleMapsからの都市の位置
- 世界の空港データベースからの空港標高
- これには 3 つのデータセットの結合が含まれます。
- 空港都市境界.csv
- これには、上記の空港名と都市名が 1 つの新しいソースと結合されたものが含まれています。
- OpenStreetMapの都市境界
- これには、上記の空港名と都市名が 1 つの新しいソースと結合されたものが含まれています。
ご想像のとおり、私たちは ES|QL の地理空間機能をテストできるようにすることを目的として、これらのデータ ソースを上記の 2 つのファイルに結合するのに時間を費やしました。これは、特定のデータ ニーズとまったく同じではないかもしれませんが、これによって、何が可能かについてのアイデアが得られると思います。特に、いくつかの興味深い点について説明したいと思います。
- 地理空間フィールドを含むデータを他のインデックス可能なデータと一緒にインポートする
geo_pointとgeo_shape両方のデータをインポートし、クエリで一緒に使用します- 空間関係を使用して結合できる 2 つのインデックスにデータをインポートする
- 将来のインポートを容易にするための取り込みパイプラインの作成(Kibana 以外)
csv、convert、split
このブログでは CSV データの操作について説明しますが、 Kibana を使用して地理データを追加する 方法はいくつかある こと を理解することが重要です。マップ アプリケーション内では、CSV、GeoJSON、ESRI ShapeFiles などの区切りデータをアップロードでき、マップ内に直接図形を描画することもできます。このブログでは、Kibana ホームページから CSV ファイルをインポートすることに焦点を当てます。
空港の輸入
最初のファイル、 airports.csv 、対処する必要がある興味深い癖がいくつかあります。まず、列を区切る追加の空白がありますが、これは CSV ファイルでは一般的ではありません。次に、 typeフィールドは複数値フィールドであるため、個別のフィールドに分割する必要があります。最後に、一部のフィールドは文字列ではないため、適切な型に変換する必要があります。これらはすべて、Kibana の CSV インポート機能を使用して実行できます。

Kibana のホームページから始めましょう。「統合を追加して開始する」というセクションがあり、そこに「ファイルをアップロードする」というリンクがあります。
このリンクをクリックすると、「ファイルのアップロード」ページに移動します。ここでairports.csvファイルをドラッグ アンド ドロップすると、Kibana がファイルを分析し、データのプレビューを表示します。区切り文字がコンマであること、最初の行がヘッダー行であることが自動的に検出されるはずです。ただし、すべてのフィールドがtextまたはkeywordであると想定すると、列間の余分な空白が削除されず、フィールドの種類も判別されなかった可能性があります。これを修正する必要があります。

Override settingsをクリックし、 Should trim fieldsのチェックボックスをオンにして、 Applyクリックして設定を閉じます。ここで、フィールドのタイプを修正する必要があります。これは次のページでご覧いただけますので、 Importをクリックしてください。

まずインデックス名を選択し、次にAdvancedを選択してフィールド マッピングと取り込みプロセッサ ページに移動します。

ここでは、インデックスのフィールド マッピングと、データをインポートするための取り込みパイプラインの両方に変更を加える必要があります。まず、Kibana はscalerankフィールドをlongとして自動検出したと思われますが、 locationフィールドとcity_locationフィールドをkeywordとして誤って認識しました。これらをgeo_pointに編集すると、マッピングは次のようになります。
ここではある程度の柔軟性がありますが、選択したタイプによって、フィールドのインデックス作成方法や、可能なクエリの種類が影響を受けることに注意してください。たとえば、 location keywordのままにしておくと、地理空間検索クエリを実行することはできません。同様に、 elevation textのままにしておくと、数値範囲のクエリを実行することはできません。
ここで、取り込みパイプラインを修正します。Kibana が上記のscalerank longとして自動検出した場合、フィールドをlongに変換するプロセッサも追加されます。elevationフィールドに同様のプロセッサを追加して、今回はdoubleに変換する必要があります。この変換が確実に実行されるようにパイプラインを編集します。これを保存する前に、 typeフィールドを複数のフィールドに分割する変換をもう 1 つ実行する必要があります。次の構成で、パイプラインにsplitプロセッサを追加します。
最終的な取り込みパイプラインは次のようになります。
locationフィールドとcity_locationフィールドには変換プロセッサを追加していないことに注意してください。これは、フィールド マッピングのgeo_pointタイプが、これらのフィールドのデータのWKT形式をすでに理解しているためです。geo_point型は、 WKT、GeoJSON など、さまざまな形式を理解できます。たとえば、CSV ファイルにlatitudeとlongitudeの 2 つの列がある場合、これらを 1 つのgeo_pointフィールドに結合するには、 scriptまたはsetプロセッサを追加する必要がありました (例:"set": {"field": "location", "value": "{{lat}},{{lon}}"} )。
これでファイルをインポートする準備が整いました。Importをクリックすると、定義したマッピングと取り込みパイプラインを使用してデータがインデックスにインポートされます。データの取り込み中にエラーが発生した場合は、Kibana によってここで報告されるので、ソース データまたは取り込みパイプラインを編集して再試行できます。
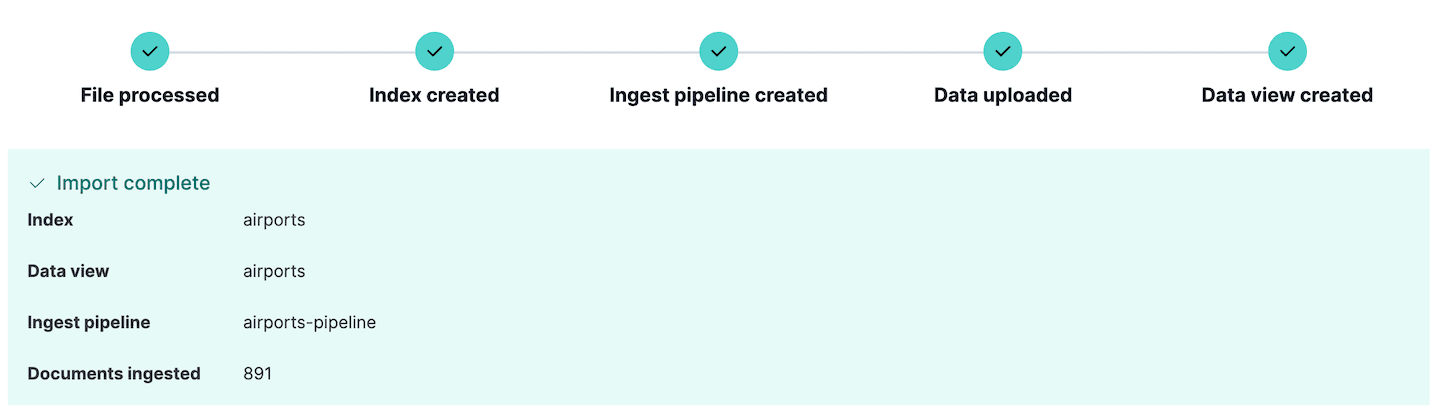
新しい取り込みパイプラインが作成されたことに注意してください。これは、Kibana のStack Managementセクションに移動し、 Ingest pipelinesを選択すると表示されます。ここで、作成したパイプラインを確認し、必要に応じて編集できます。実際、 Ingest pipelinesセクションは取り込みパイプラインの作成とテストに使用できます。これは、さらに複雑な取り込みを行う予定がある場合に非常に便利な機能です。
このデータをすぐに調べたい場合は後のセクションに進んでください。ただし、都市の境界もインポートしたい場合は読み続けてください。
都市境界のインポート
airport_city_boundaries.csvで利用可能な都市境界ファイルは、前の例よりもインポートが少し簡単です。これには、都市の境界をPOLYGONとして WKT で表現したcity_boundaryフィールドと、都市の位置をgeo_point表現したcity_locationフィールドが含まれています。このデータは空港データと同様の方法でインポートできますが、いくつか違いがあります。
- 自動検出されなかったため、オーバーライド設定
Has header rowを選択する必要がありました - データにはすでに余分な空白が除去されていたため、フィールドをトリミングする必要はありませんでした。
- すべての型が文字列または空間型であったため、取り込みパイプラインを編集する必要はありませんでした。
- ただし、フィールドマッピングを編集して、
city_boundaryフィールドをgeo_shapeに設定し、city_locationフィールドをgeo_point
最終的なフィールド マッピングは次のようになります。
以前のairports.csvインポートと同様に、 Importをクリックするだけでデータがインデックスにインポートされます。データは、編集したマッピングと Kibana が定義した取り込みパイプラインを使用してインポートされます。
開発ツールで地理空間データを探索する
Kibana では、インデックス化されたデータを「Discover」で探索するのが一般的です。ただし、ES|QL クエリを使用して独自のアプリを作成することが目的である場合は、生の Elasticsearch API にアクセスしてみる方が興味深いかもしれません。Kibana には、クエリの記述を試すための便利なコンソールがあります。これはDev Toolsコンソールと呼ばれ、Kibana サイドバーにあります。このコンソールは Elasticsearch クラスターと直接通信し、クエリの実行、インデックスの作成などに使用できます。
次のことを試してください。
これにより、次の結果が得られます。
| 距離 | 略語 | 名前 | 場所 | 国 | 市 | 標高 |
|---|---|---|---|---|---|---|
| 273418.05776847183 | ハム | ハンブルク | ポイント (10.005647830925 53.6320011640866) | ドイツ | ノルダーシュテット | 17.0 |
| 337534.653466062 | テキサス | ベルリン・テーゲル国際空港 | ポイント (13.2903090925074 52.5544287044101) | ドイツ | ホーエン・ノイエンドルフ | 38.0 |
| 483713.15032266214 | OSL | オスロ・ガーデモエン | ポイント (11.0991032762581 60.1935783171386) | ノルウェー | オスロ | 208.0 |
| 522538.03148094116 | BMA | ブロンマ | ポイント (17.9456175406145 59.3555902065112) | スウェーデン | ストックホルム | 15.0 |
| 522538.03148094116 | アーン | アーランダ | ポイント (17.9307299016916 59.6511203397372) | スウェーデン | ストックホルム | 38.0 |
| 624274.8274399083 | ダス | デュッセルドルフ国際空港 | ポイント (6.76494446612174 51.2781820420774) | ドイツ | デュッセルドルフ | 45.0 |
| 633388.6966435644 | PRG | ルジン | ポイント (14.2674849854076 50.1076511703671) | チェコ | プラハ | 381.0 |
| 635911.1873311149 | アムス | スキポール | ポイント (4.76437693232812 52.3089323889822) | オランダ | ホーフトドルプ | -3.0 |
| 670864.137958866 | フランス | フランクフルト国際空港 | ポイント (8.57182286907608 50.0506770895207) | ドイツ | フランクフルト | 111.0 |
| 683239.2529970079 | ワウ | オケシー国際空港 | ポイント (20.9727263383587 52.171026749259) | ポーランド | ピアセチュノ | 111.0 |
Kibana Maps で地理空間データを視覚化する
Kibana Maps は、地理空間データを視覚化するための強力なツールです。これを使用すると、各レイヤーが異なるデータセットを表す複数のレイヤーを持つマップを作成できます。データはさまざまな方法でフィルタリング、集計、スタイル設定できます。このセクションでは、前のセクションでインポートしたデータを使用して、Kibana Maps でマップを作成する方法を説明します。
Kibana メニューで、 Analytics -> Mapsに移動して新しいマップ ビューを開きます。Add LayerをクリックしてDocumentsを選択し、データ ビューairportsを選択して、レイヤー スタイルを編集し、 elevationフィールドを使用してマーカーに色を付けます。これにより、各空港の高さが簡単にわかります。
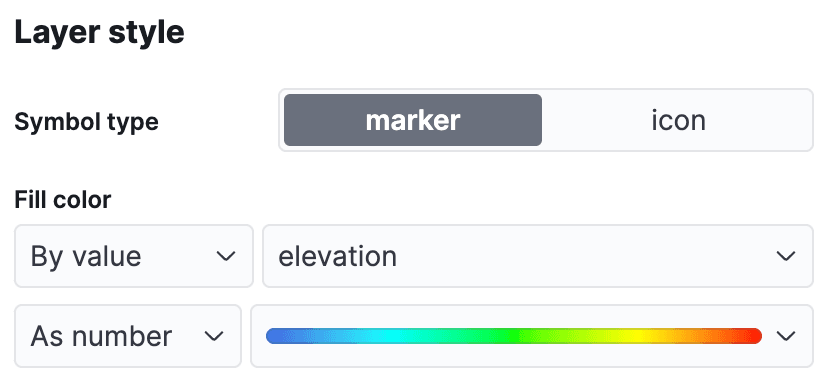
マップを保存するには、「変更を保持」をクリックします。

次に、 airport_city_boundariesデータ ビューを選択して、2 番目のレイヤーを追加します。今回は、 city_boundaryフィールドを使用してレイヤーのスタイルを設定し、塗りつぶしの色を薄い青に設定します。これにより、地図上に都市の境界が表示されます。空港マーカーが最上部になるようにレイヤーの順序を変更してください。

空間結合
ES|QL はJOINコマンドをサポートしていませんが、 ENRICHコマンドを使用して特殊な結合を実現できます。このコマンドは SQL の「左結合」に似た動作をし、2 つのデータセット間の空間関係に基づいて、1 つのインデックスの結果を別のインデックスのデータで強化することができます。
たとえば、空港の場所を含む都市の境界を見つけることで、空港のテーブルからの結果に、空港がサービスを提供する都市に関する追加情報を付加し、結果に対していくつかの統計を実行してみましょう。
最初にエンリッチインデックスを準備せずにこのクエリを実行すると、次のようなエラー メッセージが表示されます。
これは、前述したように、ES|QL が真のJOINコマンドをサポートしていないためです。その重要な理由の 1 つは、Elasticsearch が分散システムであり、結合はスケーリングが難しい高コストの操作であることです。ただし、 ENRICHコマンドは、クラスター全体に複製された特別に準備されたエンリッチ インデックスを利用し、各ノードでローカル結合を実行できるため、非常に効率的です。
これをよりよく理解するために、上記のクエリのENRICHコマンドに注目してみましょう。
このコマンドは、Elasticsearch に、 airportsインデックスから取得された結果を強化し、元のインデックスのcity_locationフィールドと、前のいくつかの例で使用したairport_city_boundariesインデックスのcity_boundaryフィールドの間でintersects結合を実行するように指示します。しかし、この情報の一部はこのクエリでは明確に表示されません。表示されるのはエンリッチポリシーの名前city_boundariesであり、不足している情報はそのポリシー定義内にカプセル化されています。
ここでは、 geo_matchクエリ ( intersectsがデフォルト) が実行され、照合するフィールドがcity_boundaryであり、 enrich_fieldsが元のドキュメントに追加するフィールドであることがわかります。これらのフィールドの 1 つであるregionは、実際にはSTATSコマンドのグループ化キーとして使用されていましたが、これはこの「左結合」機能がなければ実行できませんでした。エンリッチ ポリシーの詳細については、エンリッチのドキュメントを参照してください。
Elasticsearch のエンリッチ インデックスとポリシーは、もともと、別の準備されたエンリッチ インデックスのデータを使用して、インデックス作成時にデータをエンリッチするために設計されました。ただし、ES|QL では、 ENRICHコマンドはクエリ時に機能し、取り込みパイプラインを使用する必要はありません。これは実質的に SQL LEFT JOINと非常に似ていますが、2 つのインデックスを結合することはできず、左側の通常のインデックスと、右側の特別に準備されたエンリッチ インデックスのみを結合できます。
どちらの場合でも、取り込みパイプライン用でも ES|QL で使用する場合でも、エンリッチ インデックスとポリシーを設定するためにいくつかの準備手順を実行する必要があります。上記ですでにairport_city_boundariesインデックスをインポートしましたが、これをENRICHコマンドのエンリッチ インデックスとして直接使用することはできません。まず、次の 2 つの手順を実行する必要があります。
- 上記のエンリッチ ポリシーを作成して、ソース インデックス、照合するソース インデックス内のフィールド、一致した場合に返されるフィールドを定義します。
- このポリシーを実行して、エンリッチ インデックスを作成します。これにより、元のソース インデックスをより効率的なデータ構造に読み取り、クラスター全体にコピーすることで、特別な内部インデックスが構築されます。
エンリッチ ポリシーは、次のコマンドを使用して作成できます。
そして、次のコマンドを使用してポリシーを実行できます。
airport_city_boundariesインデックスの内容を変更した場合は、エンリッチ インデックスに反映された変更を確認するためにこのポリシーを再実行する必要があることに注意してください。ここで、元の ES|QL クエリをもう一度実行してみましょう。
これは、空港が最も多い上位 5 つの地域と、一致する地域を持つすべての空港の重心、およびそれらの地域内の都市境界の WKT 表現の長さの範囲を返します。
| 重心 | カウント | 地域 |
|---|---|---|
| ポイント (-12.13908685930073331.024386116624648) | 126 | ヌル |
| ポイント (-83.1039831787347842.300230911932886) | 3 | デトロイト |
| ポイント (39.74537850357592 47.21613017376512) | 3 | городской округ Батайск |
| ポイント (-156.8098678719252320.476673701778054) | 3 | ハワイ |
| ポイント (-73.9451533276587740.70366442203522) | 3 | ニューヨーク市 |
| ポイント (-83.1039831787347842.300230911932886) | 3 | デトロイト |
| ポイント (-76.6687301918864324.306286952923983) | 2 | ニュープロビデンス |
| ポイント (-3.0252167768776417 51.39245774131268) | 2 | カーディフ |
| ポイント (-115.4099348466843432.73126147687435) | 2 | メヒカリ市 |
| ポイント (41.790108773857355 50.302146775648) | 2 | Центральный район |
| ポイント (-73.8890273217111845.57078813901171) | 2 | モントリオール |
また、最も頻繁に見つかった地域はnullであったことにも気付くでしょう。これは何を意味するのでしょうか?このコマンドを SQL の「左結合」に例えたことを思い出してください。つまり、空港に一致する都市境界が見つからない場合でも、その空港は返されますが、 airport_city_boundariesインデックスのフィールドにはnull値が含まれます。一致するcity_boundaryが見つからなかった空港が 125 か所あり、 regionフィールドがnullである一致する空港が 1 か所あることがわかりました。これにより、結果にregionが含まれない空港が 126 件見つかりました。ユースケースですべての空港を都市の境界に一致させる必要がある場合は、ギャップを埋めるために追加のデータを入手する必要があります。次の 2 つの点を決定する必要があります。
airport_city_boundariesインデックス内のどのレコードにcity_boundaryフィールドがありませんかairportsインデックス内のどのレコードがENRICHコマンドを使用しても一致しないか (つまり、交差しない)
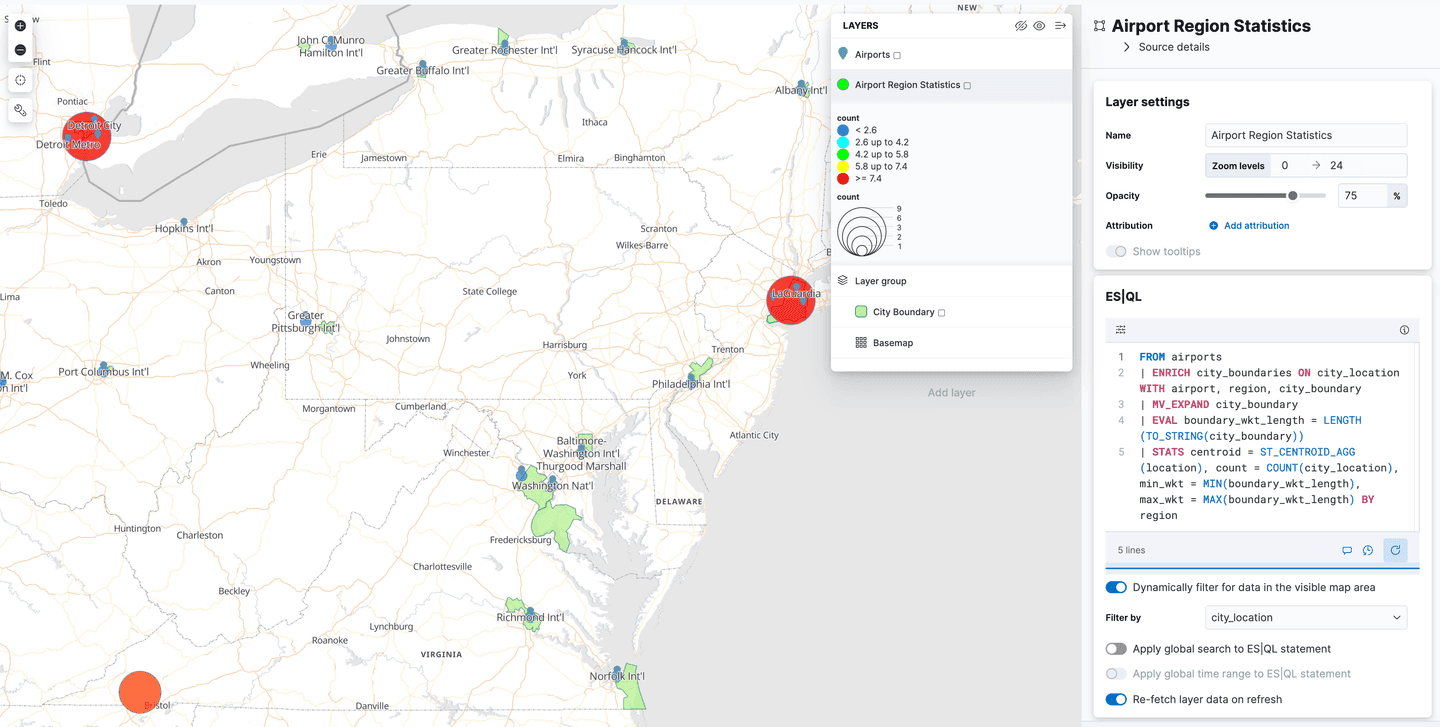
Kibana Maps の地理空間データに ES|QL を使用する
Kibana は、マップ アプリケーションに Spatial ES|QL のサポートを追加しました。つまり、ES|QL を使用して Elasticsearch で地理空間データを検索し、その結果をマップ上に視覚化できるようになりました。
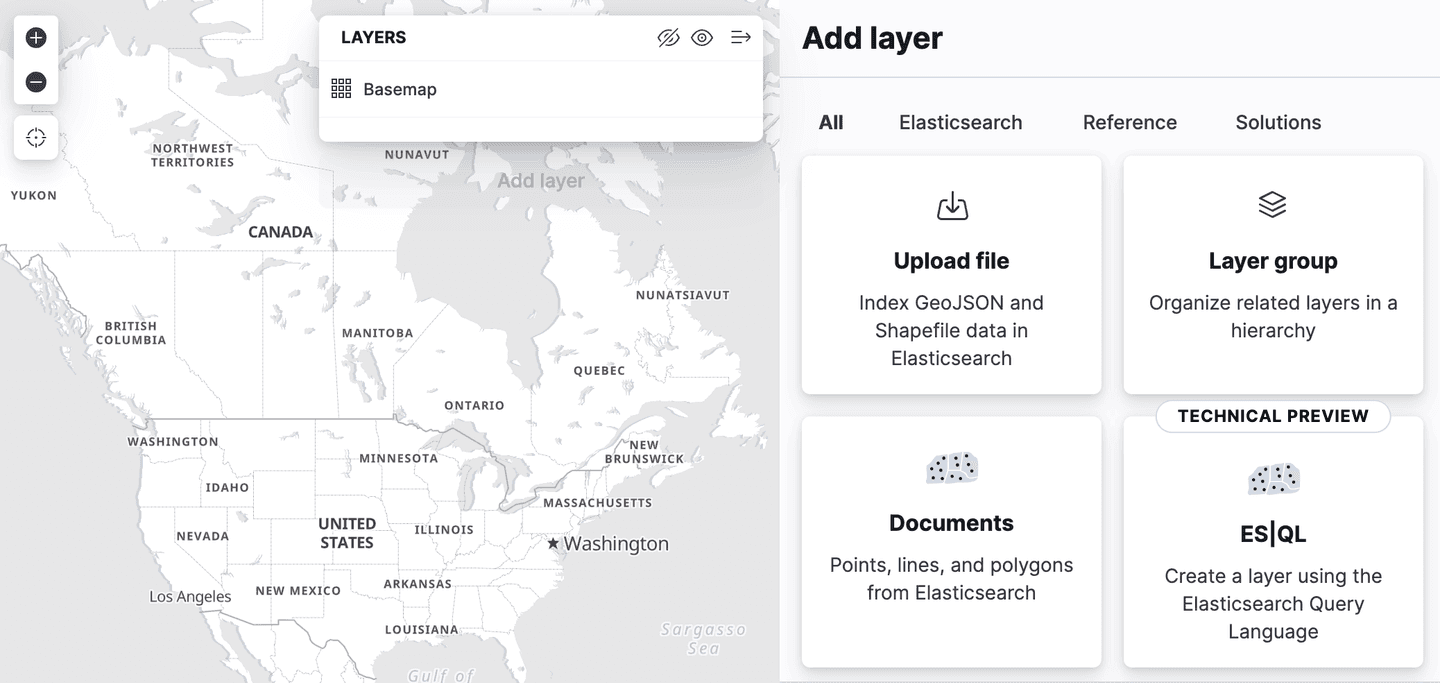
レイヤー追加メニューに、「ES|QL」という新しいレイヤー オプションがあります。これまで説明したすべての地理空間機能と同様に、これは「技術プレビュー」段階です。このオプションを選択すると、ES|QL クエリの結果に基づいてマップにレイヤーを追加できます。たとえば、世界中のすべての空港を表示するレイヤーをマップに追加できます。

または、 airport_city_boundariesインデックスからポリゴンを表示するレイヤーを追加することもできます。さらに良い方法として、各地域に空港がいくつあるかという統計を生成する、上記の複雑なENRICHクエリはどうでしょうか。
新しいエクスペリエンス
前回の地理空間検索ブログでは、Elasticsearch 8.14 以降で利用可能なST_INTERSECTSなどの関数を使用して検索を実行することに焦点を当てました。このブログでは、これらの検索に使用したデータをインポートする方法を説明します。ただし、Elasticsearch 8.15 には特に興味深い関数ST_DISTANCEが搭載されており、これを使用して効率的な空間距離検索を実行できます。これが次のブログのトピックになります。
関連記事

2026年5月22日
Kibanaはダッシュボードの読み込み時間を最大25%短縮 - その背後にあるポーリング戦略を紹介
Kibanaが継続的なポーリングとブラウザ側のHTTP/2検出を使用して、ダッシュボードの読み込み時間を最大25%削減し、HTTP/1に自動的にフォールバックする仕組みをご覧ください。

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年5月25日
KibanaのAI Chatがダッシュボードをネイティブにレンダリングするように
KibanaのElastic AI Chatでは、自然言語からダッシュボードを構築し、ビジュアルと分析を1つのスレッドに保持し、再利用可能なKibanaオブジェクトとして保存できるようになりました。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。
2026年1月19日
スイススタイルのハッシュテーブルを使用したより高速なES|QL統計
スイスにインスパイアされたハッシュとSIMDフレンドリーな設計が、Elasticsearch Query Language (ES|QL) で一貫性のある測定可能なスピードアップを実現する方法。