最近、Elasticsearchのハッシュテーブル実装の重要な部分をスイススタイルの設計に置き換えたところ、均一でカーディナリティの高いワークロードでビルドと反復処理の時間が最大2~3倍高速化されることがわかりました。結果として、Elasticsearch Query Language (ES|QL) の統計と分析操作において、低いレイテンシ、より良いスループット、そしてより予測可能なパフォーマンスが得られます。
これが重要である理由
ほとんどの典型的な分析ワークフローは最終的にデータのグループ化に集約されます。ホストあたりの平均バイト数の計算、ユーザーごとのイベントのカウント、または次元全体でのメトリクスの集計など、コアとなる操作は同じです。キーをグループにマップし、実行中の集計を更新します。
小規模であれば、ほぼすべての適切なハッシュテーブルで問題なく動作します。大規模になると(数億のドキュメントと数百万の個別のグループなど)、詳細が重要になってきます。負荷係数、プローブ戦略、メモリレイアウト、キャッシュの動作によって、線形パフォーマンスとキャッシュミスの連続との間に違いが生じる可能性があります。
Elasticsearchは長年にわたってこれらのワークロードをサポートしてきましたが、コアアルゴリズムを最新化する機会を常に探しています。そのため、スイステーブルからヒントを得た新しいアプローチを評価し、それをES|QLが統計を計算する方法に適用しました。
スイステーブルとは?
スイステーブルは、GoogleのSwissTableによって普及し、後にAbseilやその他のライブラリに採用された最新のハッシュテーブルファミリーです。
従来のハッシュテーブルでは、ポインターの追跡やキーのロードに多くの時間を費やし、結局一致しないことが判明します。スイステーブルの特徴は、キーと値とは別に保存される制御バイトと呼ばれる小さなキャッシュ常駐配列構造を使用してほとんどのプローブを拒否し、メモリトラフィックを大幅に削減できることです。
各制御バイトは単一のスロットを表し、この場合、スロットが空かどうかと、ハッシュから導出された短いフィンガープリントの2つの項目をエンコードします。これらの制御バイトはメモリ上に連続的に配置され、通常16個のグループで構成されており、単一命令多重データ(SIMD)処理に理想的です。
スイステーブルは、一度に1つのスロットをプローブする代わりに、ベクトル命令を使用して制御バイトブロック全体をスキャンします。1回の操作で、CPUは入力キーのフィンガープリントを16個のスロットと比較し、空のエントリーを除外します。この高速パスを通過する少数の候補のみが、実際のキーのロードとの比較を必要とします。
この設計では、少量の追加メタデータと引き換えに、はるかに優れたキャッシュローカリティと大幅に少ないランダムロードを実現しています。テーブルが拡大し、プローブチェーンが長くなるにつれて、それらのプロパティはますます価値が高くなります。
中央にSIMDがあります
ここでの真の主役はSIMDです。
制御バイトは単にコンパクトであるだけでなく、ベクトル命令で処理されるように明示的に設計されています。1 回のSIMD比較で16個のフィンガープリントを一度にチェックできるため、通常はループとなる処理が複数の広範な操作に変わります。例:
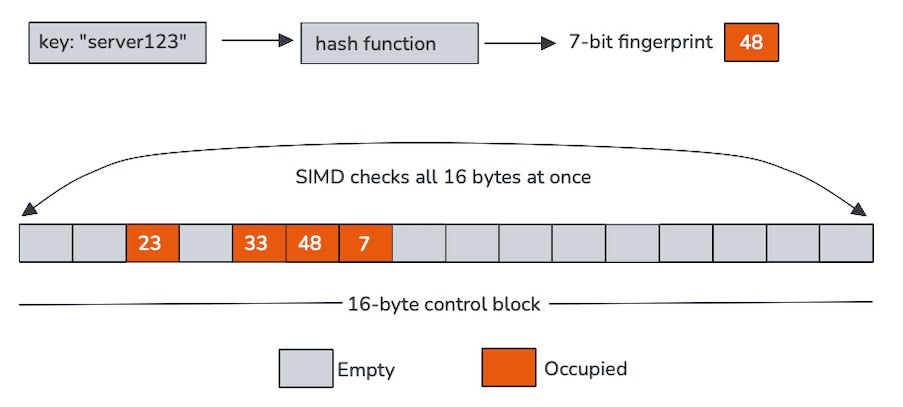
実際には、これは次のことを意味します。
- ブランチ数の低減。
- プローブチェーンの短縮。
- キーメモリや値メモリからのロードの減少。
- CPU実行ユニットの利用率が大幅に向上。
ほとんどの検索は制御バイトのスキャンを通過することはありません。そうすれば、残りの作業は焦点が絞られ、予測可能になります。これはまさに、最新のCPUが得意とする種類のワークロードです。
SIMDの仕組み
仕組みを知りたい読者のために、テーブルに新しいキーを挿入すると何が起こるかを説明します。128ビットベクトルのPanama Vector APIを使用し、16の制御バイトを並列で処理します。
次のスニペットは、Intel Rocket LakeとAVX-512で生成されたコードを示しています。手順はその環境を反映していますが、設計はAVX-512に依存しません。同じ高レベルのベクトル操作が、同等の命令(AVX2、SSE、NEONなど)を使用して他のプラットフォームでも実行されます。
各命令は挿入プロセスにおいて明確な役割を果たします。
vmovdqu:128ビットのxmm0レジスタに16個の連続制御バイトを読み込みます。vpbroadcastb:新しいキーの7ビットのフィンガープリントをxmm1レジスタのすべてのレーンにわたって複製します。vpcmpeqb: 各制御バイトをブロードキャストされたフィンガープリントと比較し、一致する可能性のあるマスクを生成します。kmovq+test:マスクを汎用レジスタに移動し、一致が存在するかどうかをすばやく確認します。
最終的に、ベンチマークにより、レジスタの幅を広げて32バイトまたは64バイトに拡張しても測定可能なパフォーマンス上の利点が得られないことが示されたため、一度に16個の制御バイトのグループをプローブすることに決定しました。
ES|QLにおける統合
Elasticsearchでのスイススタイルのハッシュの採用は、単なる置き換えではありませんでした。ES|QLには、メモリアカウンティング、安全性、コンピューティングエンジンの他の部分との統合に関して厳しい要件があります。
新しいハッシュテーブルを、ページリサイクラーやサーキットブレーカーアカウンティングなどのElasticsearchのメモリ管理と緊密に統合し、割り当てが常に可視かつ制限された状態になるようにしました。Elasticsearchのアグリゲーションは密に格納され、グループIDでインデックス化されるため、メモリレイアウトはコンパクトで高速に保たれ、反復処理も高速になります。また、ランダムアクセスを許可することで特定のパフォーマンスを最適化できます。
可変長バイトキーの場合、グループIDと一緒に完全なハッシュをキャッシュします。これにより、プローブ中に高価なハッシュコードを再計算する必要がなくなり、関連するメタデータを近くに保持することでキャッシュの局所性が向上します。再ハッシュ中は、値自体を検査せずにキャッシュされたハッシュと制御バイトに依存できるため、サイズ変更のコストが低く抑えられます。
実装における重要な簡素化の一つは、エントリーが決して削除されないことです。これにより、トゥームストーン(以前占有されていたスロットを識別するためのマーカー)の必要性がなくなり、空のスロットは実際に空のままになるので、プローブの動作がさらに改善され、制御バイトスキャンが効率的に維持されます。
その結果、スイステーブルの魅力となるパフォーマンス特性を維持しながら、Elasticsearchの実行モデルに自然に適合する設計が実現しました。
パフォーマンス
カーディナリティが小さい場合、スイステーブルのパフォーマンスは既存の実装とほぼ同等になります。これは予想どおりです。テーブルが小さい場合、キャッシュの影響は少なくなり、最適化するための調査もほとんど行われません。
カーディナリティが増加するにつれて、状況は急速に変化します。
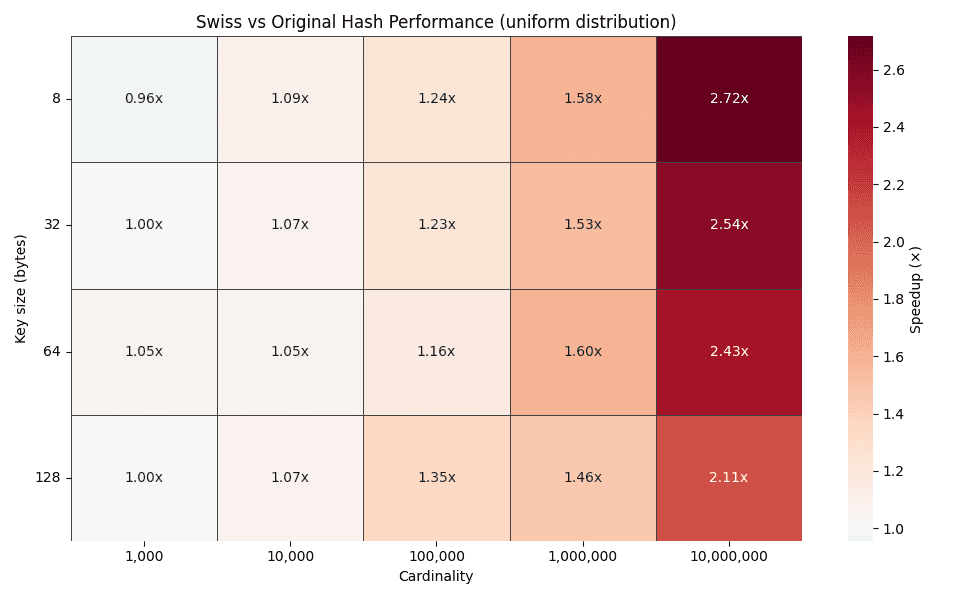
上記のヒートマップは、異なるキーサイズ(8、32、64、128バイト)に対する時間改善係数を、1,000から10,000,000グループまでの基数にわたってプロットしています。カーディナリティが増加するにつれて、改善係数は着実に増加し、均一分布の場合は2~3倍に達します。
この傾向はまさに設計が予測していることです。カーディナリティが高くなると、従来のハッシュテーブルではプローブチェーンが長くなりますが、スイススタイルのプローブでは、SIMD対応の制御バイトブロック内でほとんどの検索が引き続き解決されます。
キャッシュの挙動が物語るもの
速度の向上をよりよく理解するために、同じJMH benchmarks をLinuxperf で実行し、キャッシュとTLBの統計を取得しました。
元の実装と比較すると、スイスバージョンでは全体的にキャッシュ参照が約60%少なくなります。最終レベルのキャッシュのロードは4倍以上減少し、LLCロードミスは6倍以上減少します。LLCのミスはメインメモリアクセスに直接変換されることが多いので、この減少だけでエンドツーエンドの改善の大部分を説明できます。
CPUに近いほどL1データキャッシュミスが少なくなり、データTLBミスが約6倍少なくなります。これは、空間的局所性が高く、メモリアクセスパターンがより予測可能であることを示しています。
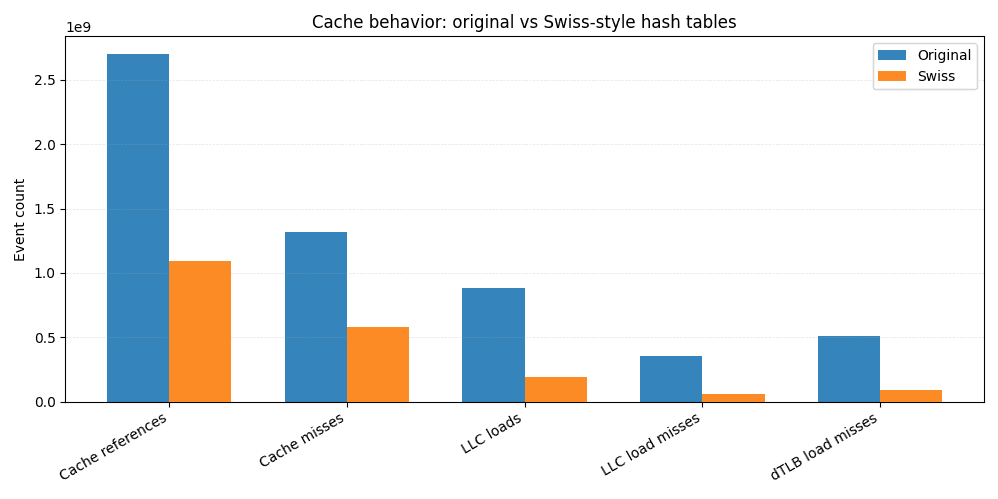
これがSIMD対応の制御バイトの実用的なメリットです。散在したメモリ位置からキーと値を繰り返しロードする代わりに、ほとんどのプローブは、コンパクトなキャッシュ常駐構造をスキャンすることによって解決されます。アクセスされるメモリが少なければミスも減り、ミスが少なければクエリも速くなります。
まとめ
スイススタイルのハッシュテーブル設計を採用し、SIMDフレンドリーなプロービングを積極的に活用することで、高カーディナリティのES|QL統計ワークロードで2〜3倍の速度向上を達成し、より安定的で予測可能なパフォーマンスを実現しました。
この研究は、現代のCPUに対応したデータ構造が、ハッシュテーブルのような十分に確立された問題においても、大きな性能向上を実現できることを示しています。ここでは、追加のプリミティブ型の特殊化や、結合などの他の高カーディナリティパスでの使用など、さらに検討する余地がありますが、これらはすべて、Elasticsearchの内部を継続的に近代化するための広範かつ継続的な取り組みの一部に過ぎません。
詳細に興味がある方や作業をフォローしたい方は、GitHubのプルリクエストとメタイシューの進捗追跡をチェックしてみてください。
ハッシュを活用しましょう!
関連記事

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。
Google MCP Toolbox for DatabasesにElasticsearchサポートを導入
Google MCP Toolbox for Databasesで利用可能になったElasticsearchサポートの詳細を確認し、ES|QLツールを活用してインデックスを任意の MCP クライアントと安全に統合します。
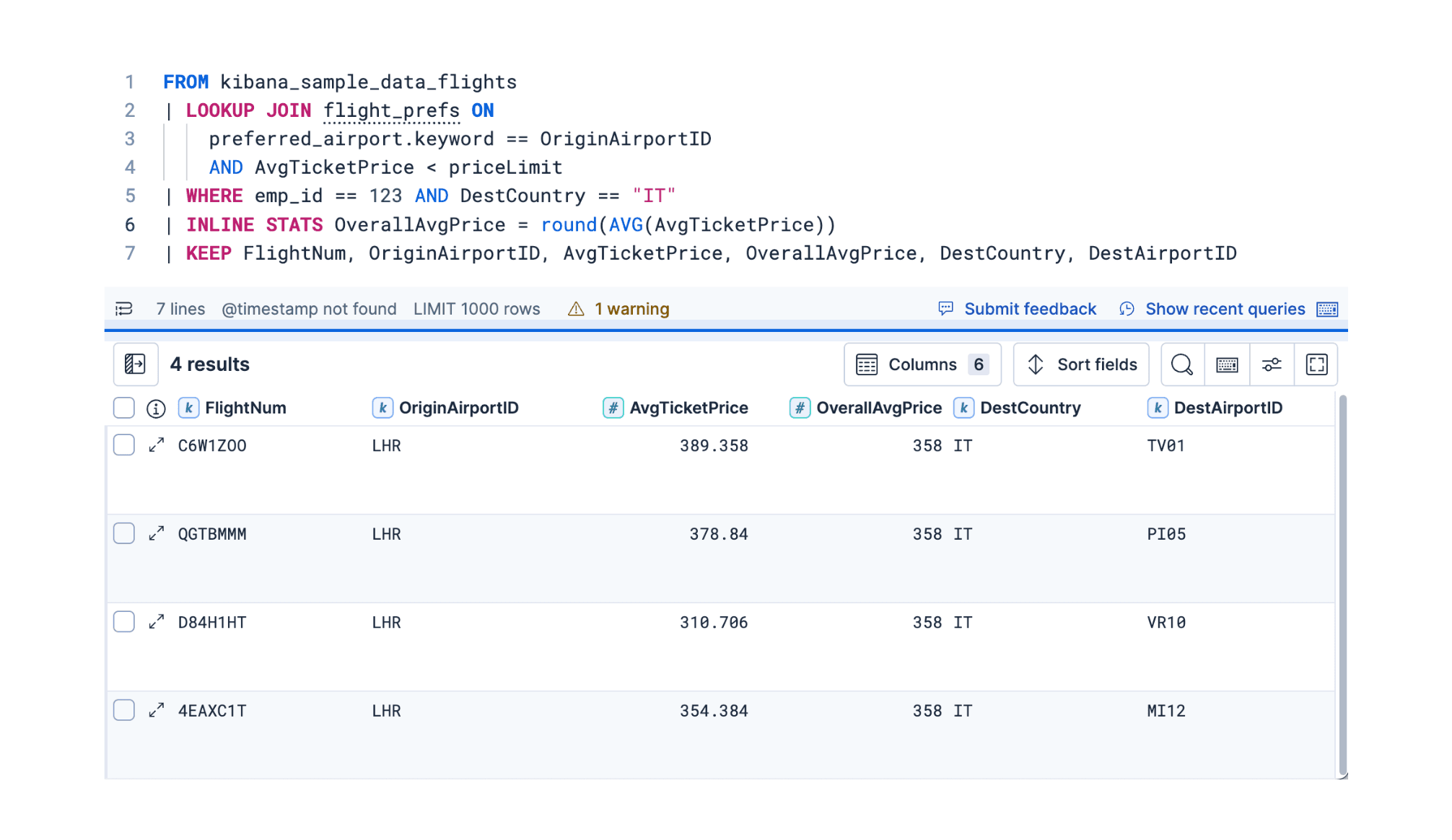
2025年12月2日
ES|QL 9.2:スマートになったLookup Joinと時系列サポート
Elasticsearch 9.2のES|QLでは、データ相関をより表現豊かにするためのLOOKUP JOIN強化、時系列分析用の新しいTSコマンド、集計用の柔軟なINLINE STATSコマンドの3つのアップデートを行いました。

2025年9月18日
Elasticsearch の ES|QL エディターエクスペリエンスと OpenSearch の PPL イベントアナライザーの比較
OpenSearch の PPL イベント アナライザーの手動アプローチと直接対照的に、ES|QL エディターの高度な機能がどのようにワークフローを加速するかをご覧ください。

Elasticsearch Ruby クライアント向け ES|QL クエリビルダーのご紹介
Elasticsearch Ruby クライアント用に最近リリースされた ES|QL クエリ ビルダーの使用方法を学習します。Ruby コードを使用して ES|QL クエリをより簡単に構築するためのツール。