10月にリリースされたElasticsearch 9.2には、データの分析をこれまで以上に高速化、柔軟化、アクセスしやすくするための大きな進化が詰まっています。このリリースの中心となるのは、パイプクエリ言語であるES|QLの重要な機能強化で、エンドユーザーに直接さらに多くの価値をもたらすように設計されています。
ES|QLを使用してデータ分析ワークフローを変革するElasticsearch 9.2の特徴を見てみましょう。
データ相関の革命:よりスマート高速、柔軟になったLookup Join
ES|QLのLOOKUP JOINコマンドはElasticsearch 9.2で大幅に変更され、効率性と汎用性が飛躍的に向上しました。LOOKUP JOINは、ES|QLクエリ結果テーブルのデータを、指定されたルックアップモードインデックスの一致するレコードと結合します。結合フィールド内の一致する値に基づいて、ルックアップ インデックスのフィールドが新しい列として結果テーブルに追加されます。以前は、データの結合は単一のフィールドと単純な等式に制限されていましたが、これが改善されました。これらの機能強化により、複雑なデータ相関シナリオに簡単に対処できるようになります。
Lookup Joinの主な機能強化は次のとおりです。
- 複数フィールド結合:複数のフィールドを簡単に結合できます。例えば、
application_logsをservice_name、environmentのservice_registryと結合する場合version:
- 式を使用して複雑なjoin述語を活用(テクニカルプレビュー):
もはや、単純な等式に制限されることはありません。LOOKUP JOINでは、複数の条件を相関に指定し、==、!=、、<=、>= を含む 二項演算子の範囲を組み込むことができます。つまり、非常に微妙な結合条件を作成できるようになり、データに対してより高度な質問をすることができるようになります。
例1:サービスごとのSLAしきい値を使用したアプリケーションメトリクスの検索
例2:このクエリは、時間とともに変化する地域の価格ポリシーに基づいて支払われるべき金額を計算します。複雑な日付範囲と等しい条件に基づく3つのデータセットを統合し、最終的に due_amountを算出します。2番目のルックアップ結合では、 meter_readingsインデックスのmeasurement_dateフィールドとcustomersインデックスのregion_idフィールドを使用してpricing_policiesインデックスに結合し、特定のregionとmeasurement_dateの正しい価格設定ポリシーを検索します。
- フィルターされた結合のパフォーマンスが大幅に向上:
ルックアップテーブル条件を使用してフィルター処理される「拡張結合」のパフォーマンスが向上しました。拡張結合では、入力行ごとに複数の一致が生成され、大きな中間結果セットが作成されることがあります。これらの行の多くが後続のフィルターによって破棄されると、状況はさらに悪化します。9.2では、ルックアップデータにフィルターを適用するときに不要な行を除外することでこれらの結合を最適化し、破棄される行の処理を回避します。シナリオによっては、これらの結合は最大1000倍高速化される可能性があります。
この最適化は、ルックアップによって最初に多くの潜在的な一致が生成される可能性がある「拡張結合」を処理する場合に重要です。フィルターをインテリジェントにプッシュダウンすることで、関連するデータのみが処理され、クエリ実行時間が大幅に短縮され、膨大なデータセットでのリアルタイム分析が可能になります。つまり、非常に大規模または複雑な結合操作の場合でも、はるかに速く洞察を得ることができます。
Lookup Joinクラスター横断検索(CCS)の互換性:
8.19および9.1でLookup Joinが一般公開となった際、クロスクラスター検索(CCS)のサポートはありませんでした。複数のクラスターにまたがって運用している組織のため、LOOKUP JOINは9.2でCCSとシームレスに統合されるようになりました。ルックアップインデックスを結合したいすべてのリモートクラスターに配置するだけで、ES|QLは自動的にこれらのリモートルックアップインデックスを活用して、リモートデータと結合します。これにより、分散データ分析が簡素化され、Elasticsearch展開全体で一貫したエンリッチメントが保証されます。
これらの改善により、多様なデータセットを前例のない精度、速度、そして容易さで関連付けることができ、複雑な回避策や前処理のステップなしに、より深く、実用的な洞察を明らかにすることができます。
データを簡単に充実化:ルックアップインデックスのためのKibana Discoverユーザーエクスペリエンス
データのエンリッチメントはハードルではなく、シンプルであるべきです。KibanaのDiscoverに、ルックアップインデックスの作成と管理のための素晴らしい新しいユーザーエクスペリエンスを導入しました。
直感的なワークフロー:Discoverの包括的なオートコンプリートがES|QLエディターでルックアップインデックスや結合フィールドを提案するため、アップロードされたデータを既存のインデックスと驚くほど簡単に結びつけることができます。存在しないルックアップインデックスの名前を入力し、ワンクリックでルックアップエディターに直接アクセスしてインデックスを作成できます。既存の検索インデックスの名前を入力すると、編集オプションを提案します。

インライン管理(CRUD): Discoverで直接、参照データセットをインライン編集機能(作成、読み取り、更新、削除)で最新の状態に保ちます。

簡単なファイルアップロード:CSVなどのファイルをDiscover内で直接アップロードし、 LOOKUP JOINですぐに使用できるようになりました。Kibanaのさまざまなエリアにジャンプしてコンテキストを切り替える必要はもうありません!
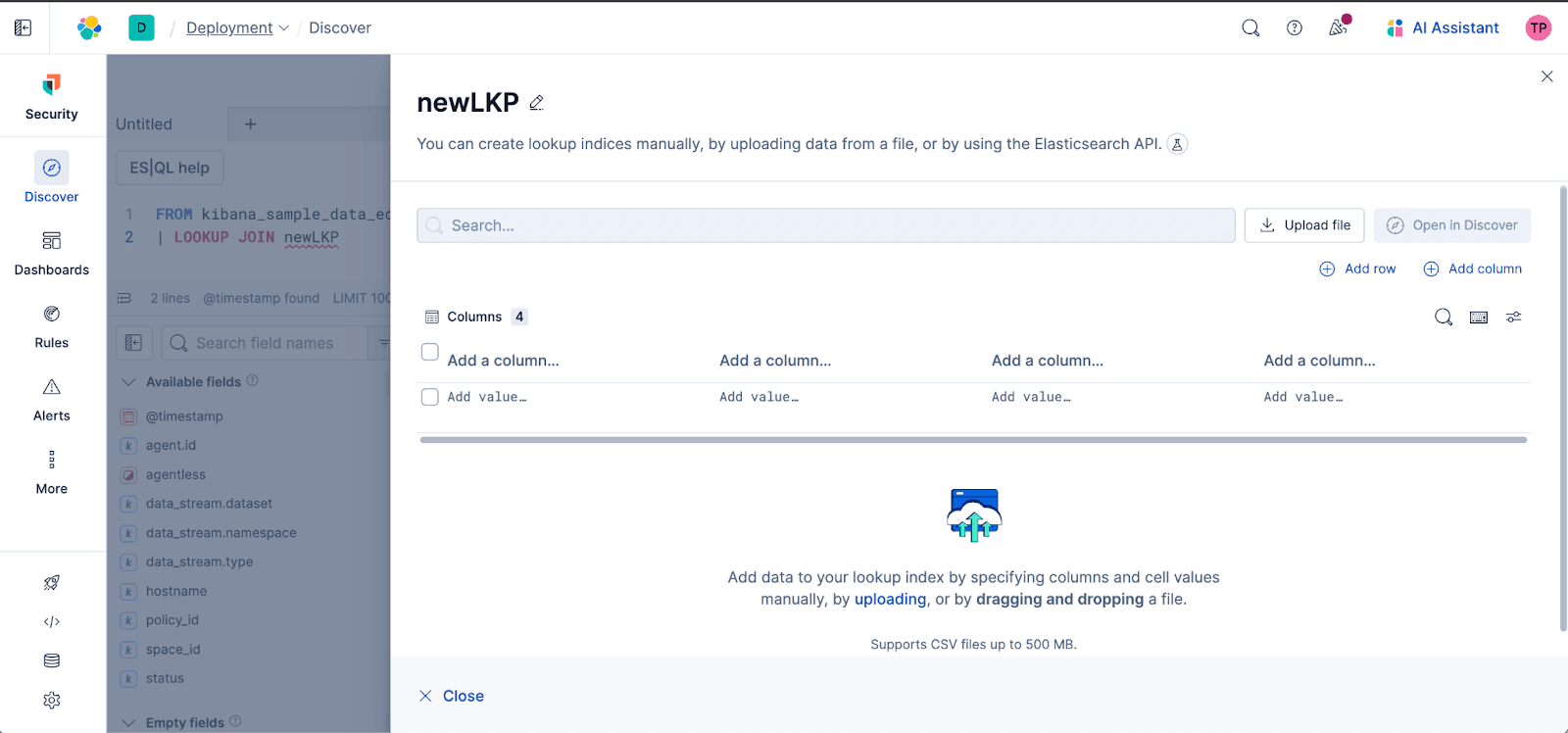
ユーザーIDを名前にマッピングしたり、ビジネスメタデータを追加したり、静的参照ファイルを結合したりする際、この特徴はデータのエンリッチメントを民主化し、結合のパワーをすべてのユーザーの手元に直接、迅速かつシンプルに、そして一箇所で提供します。
コンテキストの保持:INLINE STATSのご紹介(テクニカルプレビュー)
データの集約は重要ですが、時には集約を元のデータと並べて見る必要があることもあります。INLINE STATSをテクニカルプレビュー機能としてご紹介できることを嬉しく思います。
入力フィールドを集約された出力に置き換えるSTATSコマンドとは異なり、 INLINE STATS元の入力フィールドをすべて保持し、新しい集約されたフィールドを追加します。これにより、集計後に元の入力フィールドに対してさらに操作を実行できるようになり、より継続的で柔軟な分析ワークフローが実現します。
例えば、個々のフライトの行を保持しながら平均飛行距離を計算する場合:

このクエリでは、avgDistが各行に対応するDest(ination)と共に追加され、さらに、フライト情報の列が残っているため、平均を超える距離のフライトに結果をフィルタリングできます。
ES|QL における時系列サポート (技術プレビュー)
Elasticsearchは、メトリックを格納するために時系列データストリームを使用します。TSソースコマンドを通じて、ES|QLの時系列集計のサポートを追加しています。これは、Elastic Cloud Serverlessと9.2 basicでテクニカルプレビューとして利用できます。
時系列分析は主に、1つ以上のフィルタリングディメンションでスライスされた時間バケット全体のメトリック値を要約する集計クエリに基づいています。ほとんどの集計クエリは、(a) 時系列ごとに値を集計する内部集計関数と、(b) 時系列全体で (a) の結果を結合する外部集計関数という2段階の処理に依存しています。
TSソースコマンドをSTATSと組み合わせると、時系列にわたるこのようなクエリを簡潔かつ効果的に表現できるようになります。より具体的には、ホストおよび時間あたりのリクエストの合計レートを計算する次の例を考えてみましょう。
この場合、時系列アグリゲーション関数 RATE はまず時系列と時間ごとに評価されます。生成された部分集計は、 SUMを使用して結合され、ホストおよび時間ごとの最終的な集計値が計算されます。
利用可能な時系列集計関数のリストはこちらで確認できます。カウンターを処理するための最も重要な集計関数のcounterレートがサポートされるようになりました。
TSソースコマンドはSTATSと組み合わせて使用するように設計されており、時系列集計を効率的にサポートするように実行が調整されています。例えば、データはSTATSに入る前にソートされます。処理コマンド(FORKやINLINE STATSなど)によって時系列データを強化または変更したり、その順序を変更したりすることは、現在TSとSTATSの間で許可されていません。この制限は将来解除される可能性があります。
STATS表形式の出力は、適用可能なコマンドを使用してさらに処理できます。例えば、以下のクエリは、ホストごとの平均の cpu_usage と時間の比率とホストごとの最大値の比率を計算します。
時系列データは、Luceneドキュメント値を利用した基盤となる列指向ストレージエンジンに保存されます。TSコマンドは、ES|QLコンピュートエンジンを介してベクトル化されたクエリの実行を追加します。クエリパフォーマンスは、同等のDSLクエリと比較して、しばしば1桁以上の向上が見られ、確立されたメトリクス固有のシステムと同等になります。今後、詳細なアーキテクチャおよびパフォーマンス分析も提供する予定ですので、どうぞご期待ください。
ツールキットの拡張:新しい ES|QL関数
文字列操作:INCLUDES、MV_CONTAINS、URL_ENCODE、 URL_ENCODE_COMPONENT、URL_DECODEが追加され、より堅牢なテキストおよびURL処理を実現します。
時系列と地理空間:柔軟な時間バケツ処理のためのTBUCKET 、ベクトル演算のための TO_DENSE_VECTOR、高度な位置ベースの分析のためのST_GEOHASH 、 ST_GEOTILE 、 ST_GEOHEX 、 TO_GEOHASH 、 TO_GEOTILE 、 TO_GEOHEXなどの包括的な地理空間関数のセット。
日付のフォーマット:DAY_NAME、MONTH_NAMEは、より読みやすい日付表現のために使用されます。
これらの関数には、ES|QL内で直接データを操作および分析するための豊富なツールセットが用意されています。
内部の改善:パフォーマンスと効率性の向上
注目の機能以外にも、Elasticsearch 9.2にはES|QL全体にわたる数多くのパフォーマンス最適化が含まれています。関数が複数の類似したRLIKEクエリを置き換える場合に、プッシュダウンを使用してRLIKE (LIST) を高速化しました。RLIKE (LIST) を使用すると、これらのクエリを1つのオートマトンに結合し、複数ではなく1つのオートマトンを適用できます。また、インデックスの並べ替えによるキーワードフィールドの読み込みが高速化され、クエリ全般が最適化されました。これらの改善により、ES|QLクエリがこれまで以上に効率的に実行されるようになります。
今すぐ始めましょう!
Elasticsearch 9.2は、ES|QLを大きく飛躍させ、データ分析ワークフローにかつてないパワーと柔軟性をもたらします。ぜひこれらの新機能を試して、その違いを体験してください。
Elasticsearch 9.2のすべての変更点と機能強化の包括的なリストについては、公式リリースノートを参照してください。楽しいクエリングを!
関連記事

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。
2026年1月19日
スイススタイルのハッシュテーブルを使用したより高速なES|QL統計
スイスにインスパイアされたハッシュとSIMDフレンドリーな設計が、Elasticsearch Query Language (ES|QL) で一貫性のある測定可能なスピードアップを実現する方法。
Google MCP Toolbox for DatabasesにElasticsearchサポートを導入
Google MCP Toolbox for Databasesで利用可能になったElasticsearchサポートの詳細を確認し、ES|QLツールを活用してインデックスを任意の MCP クライアントと安全に統合します。

2025年9月18日
Elasticsearch の ES|QL エディターエクスペリエンスと OpenSearch の PPL イベントアナライザーの比較
OpenSearch の PPL イベント アナライザーの手動アプローチと直接対照的に、ES|QL エディターの高度な機能がどのようにワークフローを加速するかをご覧ください。

Elasticsearch Ruby クライアント向け ES|QL クエリビルダーのご紹介
Elasticsearch Ruby クライアント用に最近リリースされた ES|QL クエリ ビルダーの使用方法を学習します。Ruby コードを使用して ES|QL クエリをより簡単に構築するためのツール。