Elasticsearchは、業界をリードする生成AIツールやプロバイダーとネイティブに統合されています。RAG応用編やElasticベクトルデータベースで本番環境対応のアプリを構築する方法についてのウェビナーをご覧ください。
ユースケースに最適な検索ソリューションを構築するには、無料のクラウドトライアルを始めるか、ローカルマシンでElasticを試してみてください。
中国のヘッジファンドHigh-Flyerの新しい大規模言語モデルDeepSeek R1が話題になっています。オープンウェイトの有能で思考の連鎖的推論法が導入された今、業界にとってこれが何を意味するのかについての憶測が飛び交っています。RAGとElasticsearchのすべてのベクトルデータベース機能を使用してこの新しいモデルを試してみたい方のために、ローカル推論を使用してDeepSeek R1を使い始めるための簡単なチュートリアルを以下に示します。その過程で、ElasticのPlayground機能を使用し、RAGに対するDeepseek R1の良い点と悪い点も発見します。
このチュートリアルで設定する内容の図を以下に示します。

Ollamaを使用したローカル推論の設定
Ollamaは、ローカル推論用に厳選されたオープンソースモデルのセットを迅速にテストするための優れた方法であり、AI開発者に人気のツールです。
Ollamaをベアメタルで実行
Mac、Linux、またはWindowsでのローカルインストールは、特にMシリーズのAppleチップを使用しているユーザーにとって、ローカルのGPU機能を活用する最も簡単な方法です。Ollamaをインストールしたら、次のコマンドを使用してDeepSeek R1をダウンロードして実行できます。
ハードウェアに適したパラメータサイズに調整することをお勧めします。利用可能なサイズはこちらでご確認いただけます。
ターミナルでモデルとチャットできますが、CTL+dでコマンドを終了するか「/bye」と入力しても、モデルは実行されたままです。モデルがまだ実行中であることを確認するには、次のように入力します。
Ollamaをコンテナ内で実行
最も簡単な方法としては、OllamaをDockerのようなコンテナエンジンを利用して実行することもできます。ローカルマシンのGPUの使用は、環境によっては必ずしも簡単ではありませんが、コンテナに数GBモデルに適合するRAMとストレージがあれば、簡単なテストセットアップを行うことは難しくありません。
OllamaをDockerで起動して実行するには、次のコマンドを実行するだけです。
これにより、現在のディレクトリに「ollama」というディレクトリが作成され、コンテナ内にマウントされ、Ollamaの設定とモデルを格納します。使用するパラメータの数によって、数GBから数十GBまでの範囲になるため、十分な空き容量があるボリュームを選択してください。
注意:マシンにNvidia GPUが搭載されている場合は、必ずNvidia コンテナツールキットをインストールし、上記のdocker 実行コマンドに「--gpus=all」を追加してください。
Ollamaコンテナがマシン上で起動したら、deepseek-r1のようなモデルを次のコマンドでプルできます。
ベアメタルアプローチと同様に、ハードウェアに合ったサイズにパラメーターサイズを調整したい場合があります。利用可能なサイズについては、https://ollama.com/library/deepseek-r1をご覧ください。
モデルのプルが終了したら、「/bye」と入力してプロンプトを終了できます。モデルがまだ実行中であることを確認するには以下の手段を実行します。
curlを使用したローカル推論のテスト
curlを使用してローカル推論をテストするには、次のコマンドを実行します。JSONナラティブ応答を簡単に読み取れるように、stream:falseを使用しています。
「OpenAI互換」のOllamaとRAGプロンプトをテスト
便利なことに、OllamaはKibanaを含む幅広いツールとの互換性のために、OpenAIの動作を模倣するRESTエンドポイントも提供しています。
このより複雑なプロンプトをテストすると、<think>セクションを含むコンテンツが生成されます。このセクションでは、モデルが問題を推論するようにトレーニングされています。
OllamaをKibanaに接続する
Elasticsearchを使用する優れた方法は、「start-local」開発スクリプトを使うことです。
KibanaとElastisearchがネットワーク上でOllamaにアクセスできることを確認します。Elastic Stackのローカルコンテナ設定を使用している場合は、「localhost」を「host.docker.internal」または「host.containers.internal」に置き換える必要があるかもしれません。これは、ホストマシンへのネットワークパスを取得するためです。
Kibanaで、[Stack Management] > [アラートと洞察] > [コネクタ]に移動します。
この一般的な設定の警告が表示された場合の対処方法
xpack.encryptedSavedObjects.encryptionKeyが正しく設定されていることを確認する必要があります。これは、KibanaのローカルDockerインストールを実行する際によく見落とされる手順であるため、Docker構文で修正する手順をリストします。

コンテナのシャットダウン時に変更が保存されるように、kibana/configディレクトリを永続化してください。私のKibanaコンテナのボリュームは、docker-compose.ymlで次のようになります。
これで、キーストアを作成し、値を入れて、コネクタのキーが平文で格納されないようにすることができます。
変更を確実に有効にするには、クラスター全体を完全に再起動してください。
コネクタの作成
コネクタ構成画面(Kibana では、[Stack Management] > [アラートと洞察] > [コネクタ] に移動)からコネクタを作成し、[OpenAI] タイプを選択します。
コネクタを次の設定で構成します。
- コネクタ名:Deepseek(Ollama)
- OpenAIプロバイダーを選択:その他(OpenAI互換サービス)
- URL: http://localhost:11434/v1/chat/completions
- ollamaへの正しいパスを調整してください。コンテナ内から呼び出す場合は、host.docker.internalまたは同等のものに置き換えてください。
- デフォルトモデル:deepseek-r1:7b
- APIキー:何か適当に入力してください。入力は必要ですが、値は重要ではありません。
コネクタセットアップでのOllamaへのカスタムコネクタのテストは現在8.17では機能しませんが、Kibanaの今後の8.18ビルドでは修正される予定です。
コネクタは次のようになります。

Elasticsearchにベクトル埋め込みデータを取り込む
すでにPlaygroundに精通していてデータが設定されている場合は以下のPlaygroundの手順にスキップできますが、簡単なテストデータが必要な場合は、_inference APIが設定されていることを確認する必要があります。8.17以降、機械学習の割り当ては動的であるため、e5多言語高密度ベクトルをダウンロードして有効にするには、Kiban Devツールで次のコマンドを実行する必要があります。
まだダウンロードしていない場合は、Elasticのモデルリポジトリからe5モデルのダウンロードが開始されます。
次に、RAGのコンテキストとしてパブリックドメインの書籍を読み込みましょう。こちらのリンクから、プロジェクト・グーテンベルクで「不思議の国のアリス」をダウンロードできます。これを.txtファイルとして保存してください。
[Elasticsearch] > [ホーム] > [ファイルのアップロード] に移動します。

テキストファイルを選択またはドラッグアンドドロップし、インポートボタンを押します。
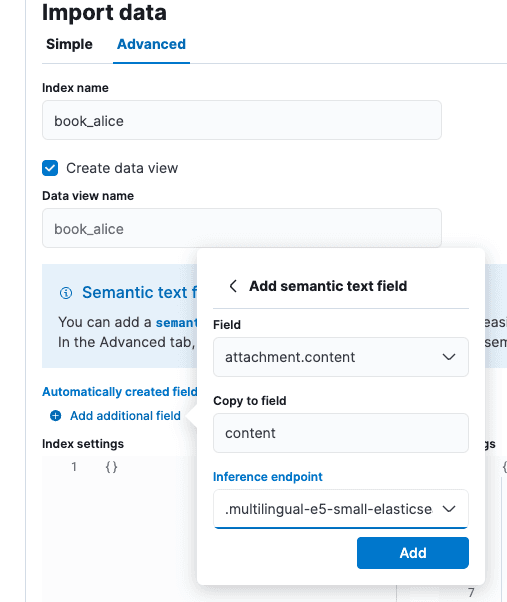
「データのインポート」画面で「詳細設定」タブを選択し、インデックス名を「book_alice」に設定します。
「自動的に作成されたフィールド」のすぐ下にある小さな「追加フィールドを追加」オプションを選択します。「セマンティックテキストフィールドの追加」を選択し、推論エンドポイントを「.multilingual-e5-small-elasticsearch」に変更します。[追加] を選択し、[インポート] を選択します。
ロードと推論が完了したら、Playgroundに向かう準備が整います。
PlaygroundでのRAGのテスト
Kibanaで [Elasticsearch] > [Playground] に移動します。
Playground画面には、コネクタが存在することを示す緑色のチェックマークと「LLM接続済み」と表示されます。これは、上記で作成したOllamaコネクタです。Playgroundのより詳しいガイドについては、こちらをご覧ください。
青色の [データソースを追加] をクリックし、以前に作成したbook_aliceインデックス、または埋め込みに推論APIを利用する以前に構成した別のインデックスを選択します。
Deepseekは、強力なアライメント特性を備えた思考連鎖モデルです。これはRAGの観点から見ると良い点と悪い点の両方があります。思考連鎖のトレーニングは、Deepseekが引用文の中で一見矛盾しているように見える記述を合理化するのに役立つかもしれませんが、トレーニング知識への強力な整合性により、コンテキストの根拠よりも独自の世界の事実を優先する可能性があります。善意ではありますが、この強固な整合性により、LLMが個人的な知識が一致しないトピックや、トレーニングデータセットで十分に表現されていないトピックについて話し合う際に、指導が困難になることが知られています。
Playgroundのセットアップでは、「You are an assistant for question-answering tasks using relevant text passages from the book Alice in wonderland」というシステムプロンプトを入力し、他のデフォルトを受け入れました。
「Who was at the tea party?」という質問に対する答えはこうです。「Answer: The March Hare, the Hatter, and the Dormouse were at the tea party. [Citation: position 1 and 2]」これは正しいです。

<think>タグを見ると、Deepseekが質問に答えるために引用の内容をしっかりと検討したことがわかります。
アライメントの限界をテスト
Deepseekのために知的に挑戦的なシナリオをテストとして作成しましょう。Deepseekのトレーニングデータが真実ではないと知っている陰謀論のインデックスを作成します。
Kibana開発ツールで、次のインデックスとデータを作成しましょう。
これらの陰謀論は、LLMの基礎となるでしょう。積極的にシステムプロンプトを出したにもかかわらず、Deepseekは私たちが説明した事実を受け入れません。自分の個人データの方が信頼性が高く、根拠があり、組織のニーズに合っていることがわかっている状況だったら、これは受け入れられないでしょう。
「are birds real?」というテストの質問(説明はknow your meme)に対して、次の答えが得られます。「In the provided context, birds are not considered real, but in reality, they are real animals. [Context: position 1]」。このテストにより、DeepSeek R1は7Bパラメータレベルでも強力であることが証明されました。ただし、データセットによっては、RAGにとって最適な選択ではない可能性があります。

今回学んだ内容
まとめると以下のようになります。
- Ollamaなどのツールでモデルをローカルで実行することは、モデルの動作を確認するのに最適なオプションです。
- DeepSeek R1は推論モデルであるため、RAGのようなユースケースには利点と欠点があります。
- Playground は、AIホスティングの初期の時代にデファクトスタンダードになりつつあるOpenAIのようなREST APIを介してOllamaなどの推論ホスティングフレームワークに接続できます。
全体として、ローカルの「エアギャップ」RAGがここまで進歩したことに感銘を受けました。Elasticsearch、Kibana、そして利用可能なオープンウェイトモデルのツールは、2023年にプライバシー重視のAI検索について初めて記事を書いたときから大幅に進歩しました。
よくあるご質問
DeepSeekとは?
Deepseek は、中国のヘッジファンド High-Flyer によって作成された大規模な言語モデルです。
関連記事

2026年5月22日
Kibanaはダッシュボードの読み込み時間を最大25%短縮 - その背後にあるポーリング戦略を紹介
Kibanaが継続的なポーリングとブラウザ側のHTTP/2検出を使用して、ダッシュボードの読み込み時間を最大25%削減し、HTTP/1に自動的にフォールバックする仕組みをご覧ください。

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年5月25日
KibanaのAI Chatがダッシュボードをネイティブにレンダリングするように
KibanaのElastic AI Chatでは、自然言語からダッシュボードを構築し、ビジュアルと分析を1つのスレッドに保持し、再利用可能なKibanaオブジェクトとして保存できるようになりました。

Elasticsearchによるエンティティ解決、パート4:究極のチャレンジ
ショートカットを防ぐために設計された、非常に多様な「究極のチャレンジ」データセットにおけるエンティティ解決の課題の解決と評価。

ElasticsearchとLLMによるエンティティ解決(第2部):LLM判定とセマンティック検索によるエンティティのマッチング
Elasticsearch でのエンティティ解決にセマンティック検索と透過的なLLM判断を使用します。