De la recherche vectorielle aux API REST puissantes, Elasticsearch met à disposition des développeurs la boîte à outils de recherche la plus complète. Explorez nos notebooks d’exemple dans le dépôt Elasticsearch Labs pour tester de nouvelles approches. Vous pouvez également démarrer un essai gratuit ou exécuter Elasticsearch en local dès aujourd’hui.
Construire un logiciel dans n'importe quel langage de programmation, y compris Go, c'est s'engager dans une vie d'apprentissage. Tout au long de sa carrière universitaire et professionnelle, Carly a touché à de nombreux langages et technologies de programmation, y compris les dernières et meilleures implémentations de la recherche vectorielle. Mais ce n'était pas suffisant ! Récemment, Carly a commencé à jouer avec Go.
Tout comme les animaux, les langages de programmation et votre sympathique auteur, la recherche a connu une évolution des différentes pratiques qu'il peut être difficile de choisir pour votre propre cas d'utilisation de la recherche. Dans ce blog, nous présenterons une vue d'ensemble de la recherche vectorielle ainsi que des exemples de chaque approche en utilisant Elasticsearch et le client Elasticsearch Go. Ces exemples vous montreront comment trouver des spermophiles et déterminer ce qu'ils mangent en utilisant la recherche vectorielle dans Elasticsearch et Go.
Produits requis
Pour suivre cet exemple, assurez-vous que les conditions préalables suivantes sont remplies :
- Installation de Go version 1.21 ou ultérieure
- Création de votre propre repo Go avec l'outil
- Création de votre propre cluster Elasticsearch, peuplé d'un ensemble de pages sur les rongeurs, y compris pour notre sympathique Gopher, à partir de Wikipedia :
Connexion à Elasticsearch
Dans nos exemples, nous utiliserons l'API typée proposée par le client Go. Pour établir une connexion sécurisée pour n'importe quelle requête, il faut configurer le client en utilisant l'une ou l'autre des méthodes suivantes :
- ID du nuage et clé API si vous utilisez Elastic Cloud.
- URL du cluster, nom d'utilisateur, mot de passe et certificat.
La connexion à notre cluster situé sur Elastic Cloud ressemblerait à ceci :
La connexion client peut ensuite être utilisée pour la recherche vectorielle, comme nous le verrons dans les sections suivantes.
Recherche vectorielle
La recherche vectorielle tente de résoudre ce problème en convertissant le problème de recherche en une comparaison mathématique utilisant des vecteurs. Le processus d'intégration de documents comporte une étape supplémentaire consistant à convertir le document à l'aide d'un modèle en une représentation vectorielle dense, ou simplement en un flux de nombres. L'avantage de cette approche est qu'elle permet de rechercher des documents non textuels, tels que des images et des fichiers audio, en les traduisant en un vecteur accompagné d'une requête.
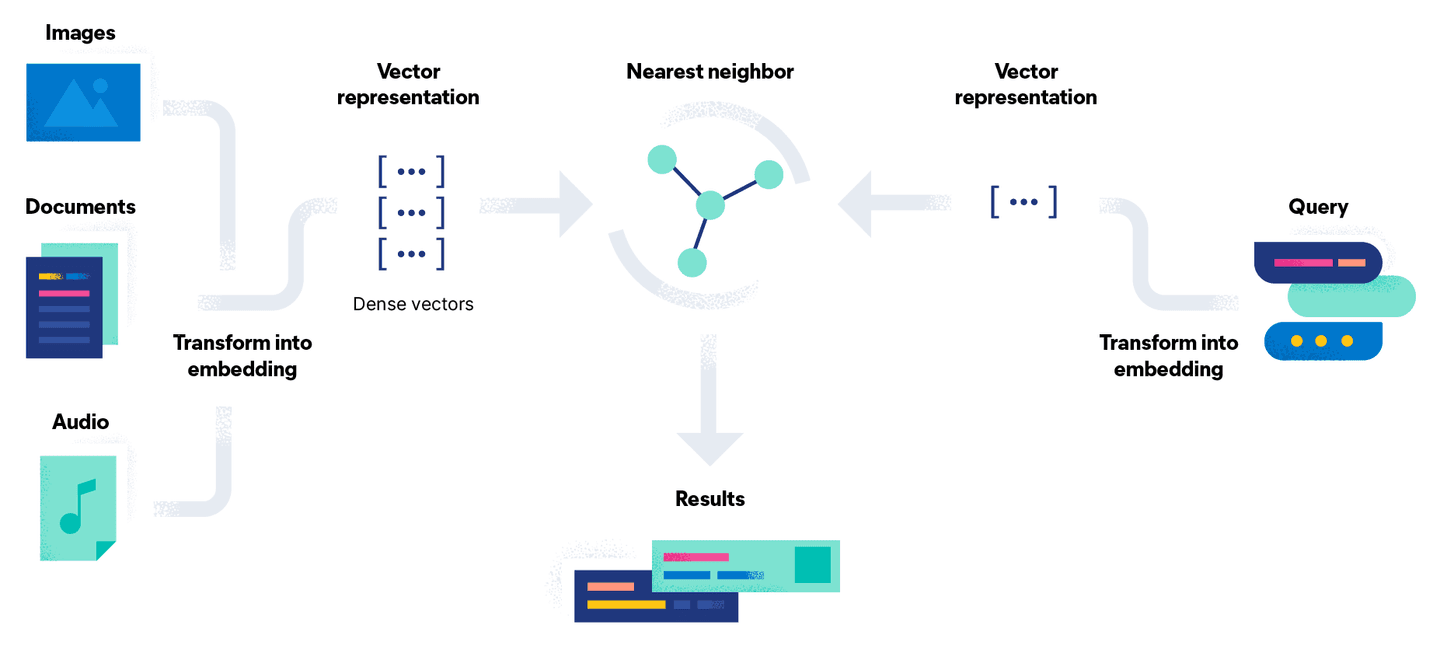
En termes simples, la recherche vectorielle est un ensemble de calculs de distances vectorielles. Dans l'illustration ci-dessous, la représentation vectorielle de notre requête Go Gopherest comparée aux documents de l'espace vectoriel et les résultats les plus proches (désignés par la constante k) sont renvoyés :

En fonction de l'approche utilisée pour générer les enchâssements de vos documents, il y a deux façons différentes de savoir ce que mangent les spermophiles.
Approche 1 : Apportez votre propre modèle
Avec une licence Platinum, il est possible de générer les embeddings dans Elasticsearch en téléchargeant le modèle et en utilisant l'API d'inférence. La mise en place du modèle se fait en six étapes :
- Sélectionnez un modèle PyTorch à télécharger à partir d'un référentiel de modèles. Pour cet exemple, nous utilisons les phrase-transformers/msmarco-MiniLM-L-12-v3 de Hugging Face pour générer les embeddings.
- Charger le modèle dans Elastic à l'aide du client Eland Machine Learning pour Python en utilisant les informations d'identification de notre cluster Elasticsearch et le type de tâche
text_embeddings. Si Eland n'est pas installé, vous pouvez exécuter l'étape d'importation à l'aide de Docker, comme indiqué ci-dessous :
- Une fois téléchargé, testez rapidement le modèle
sentence-transformers__msmarco-minilm-l-12-v3avec un exemple de document pour vous assurer que les enchâssements sont générés comme prévu :

- Créer un pipeline d'ingestion contenant un processeur d'inférence. Cela permettra de générer la représentation vectorielle à l'aide du modèle téléchargé :
- Créer un nouvel index contenant le champ
text_embedding.predicted_valuede typedense_vectorpour stocker les encastrements vectoriels générés pour chaque document :
- Réindexer les documents à l'aide du pipeline d'acquisition nouvellement créé pour générer les enchâssements de texte en tant que champ supplémentaire
text_embedding.predicted_valuesur chaque document :
Nous pouvons maintenant utiliser l'option Knn sur la même API de recherche en utilisant le nouvel index vector-search-rodents, comme le montre l'exemple ci-dessous :
La conversion de l'objet de résultat JSON par unmarshalling se fait exactement de la même manière que dans l'exemple de la recherche par mot-clé. Les constantes K et NumCandidates nous permettent de configurer le nombre de documents voisins à renvoyer et le nombre de candidats à prendre en compte par tesson. Il est à noter que l'augmentation du nombre de candidats accroît la précision des résultats, mais entraîne une requête plus longue, car davantage de comparaisons sont effectuées.
Lorsque le code est exécuté à l'aide de la requête What do Gophers eat?, les résultats renvoyés sont similaires à ceux présentés ci-dessous, ce qui montre que l'article Gopher contient les informations demandées, contrairement à la recherche par mot-clé précédente :
Approche 2 : Inférence du visage étreint API
Une autre option consiste à générer ces mêmes embeddings en dehors d'Elasticsearch et à les intégrer dans votre document. Comme cette option n'utilise pas de nœud d'apprentissage automatique Elasticsearch, elle peut être réalisée sur le niveau gratuit.
Hugging Face expose une API d'inférence gratuite et limitée dans le temps qui, avec un compte et un jeton API, peut être utilisée pour générer manuellement les mêmes enchâssements à des fins d'expérimentation et de prototypage pour vous aider à démarrer. Il n'est pas recommandé pour une utilisation en production. Une approche similaire permet d'invoquer localement vos propres modèles pour générer des embeddings ou d'utiliser l'API payante.
Dans la fonction GetTextEmbeddingForQuery ci-dessous, nous utilisons l'API d'inférence avec notre chaîne de requête pour générer le vecteur renvoyé par une requête POST au point final :
Le vecteur résultant, de type []float32, est alors transmis en tant que QueryVector au lieu d'utiliser l'option QueryVectorBuilder pour exploiter le modèle précédemment téléchargé dans Elastic.
Notez que les options K et NumCandidates restent les mêmes quelles que soient les deux options et que les mêmes résultats sont générés car nous utilisons le même modèle pour générer les encastrements.
Conclusion
Nous avons vu ici comment effectuer une recherche vectorielle dans Elasticsearch en utilisant le client Elasticsearch Go. Consultez le repo GitHub pour tout le code de cette série. Suivez la partie 3 pour avoir une vue d'ensemble de la combinaison de la recherche vectorielle avec les capacités de recherche par mot-clé abordées dans la partie 1 de Go.
D'ici là, bonne chasse aux marmottes !
Ressources
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.