Nous avons récemment remplacé des éléments clés de l'implémentation des tables de hachage d'Elasticsearch par une conception de type suisse et constaté des temps de construction et d'itération jusqu'à 2 à 3 fois plus rapides sur des charges de travail uniformes à forte cardinalité. Il en résulte une latence réduite, un meilleur débit et des performances plus prévisibles pour les opérations statistiques et analytiques du langage de requête Elasticsearch (ES|QL).
Pourquoi c'est important
La plupart des workflows analytiques classiques se résument finalement à regrouper des données. Qu'il s'agisse de calculer la consommation moyenne de données par hôte, de compter les événements par utilisateur ou d'agréger des indicateurs selon différentes dimensions, l'opération de base reste la même : associer des clés à des groupes et mettre à jour les agrégats en cours.
À petite échelle, presque n'importe quelle table de hachage convenable fonctionne bien. À grande échelle (des centaines de millions de documents et des millions de groupes distincts), les détails commencent à avoir leur importance. Les facteurs de charge, la stratégie de sondage, l'organisation de la mémoire et le comportement du cache peuvent faire la différence entre des performances linéaires et une avalanche d'erreurs de cache.
Elasticsearch prend en charge ces charges de travail depuis des années, mais nous cherchons constamment à moderniser ses algorithmes de base. C'est pourquoi nous avons évalué une nouvelle approche inspirée des tables suisses et l'avons appliquée au calcul des statistiques par ES|QL.
Que sont exactement les tables suisses ?
Les tables suisses sont une famille de tables de hachage modernes popularisées par SwissTable de Google, puis adoptées par Abseil et d'autres bibliothèques.
Les tables de hachage traditionnelles passent beaucoup de temps à rechercher des pointeurs ou à charger des clés pour finalement constater qu'elles ne correspondent pas. La caractéristique principale des tables suisses est leur capacité à rejeter la plupart des requêtes grâce à une structure de tableau en cache de petite taille, stockée séparément des clés et des valeurs et appelée octets de contrôle, ce qui réduit considérablement le trafic mémoire.
Chaque octet de contrôle représente un emplacement unique et, dans notre cas, encode deux éléments : si l'emplacement est vide et une courte empreinte numérique dérivée du hachage. Ces octets de contrôle sont disposés de manière contiguë en mémoire, généralement par groupes de 16, idéal pour le traitement SIMD (Single Instruction, Multiple Data).
Au lieu de sonder un emplacement à la fois, les tables suisses parcourent un bloc entier d'octets de contrôle à l'aide d'instructions vectorielles. En une seule opération, le processeur compare l'empreinte de la clé entrante à 16 emplacements et élimine les entrées vides. Seuls les candidats retenus après ce parcours rapide nécessitent le chargement et la comparaison des clés réelles.
Cette conception privilégie une meilleure localité du cache et réduit considérablement les chargements aléatoires, au détriment d'une petite quantité de métadonnées supplémentaires. À mesure que la table s'agrandit et que les chaînes de détection s'allongent, ces avantages deviennent de plus en plus précieux.
SIMD au centre
La vraie star de la série est l'architecture SIMD.
Les octets de contrôle sont non seulement compacts, mais aussi conçus spécifiquement pour être traités par des instructions vectorielles. Une seule comparaison SIMD peut vérifier simultanément 16 empreintes, transformant ainsi une boucle classique en quelques opérations étendues. Exemple :
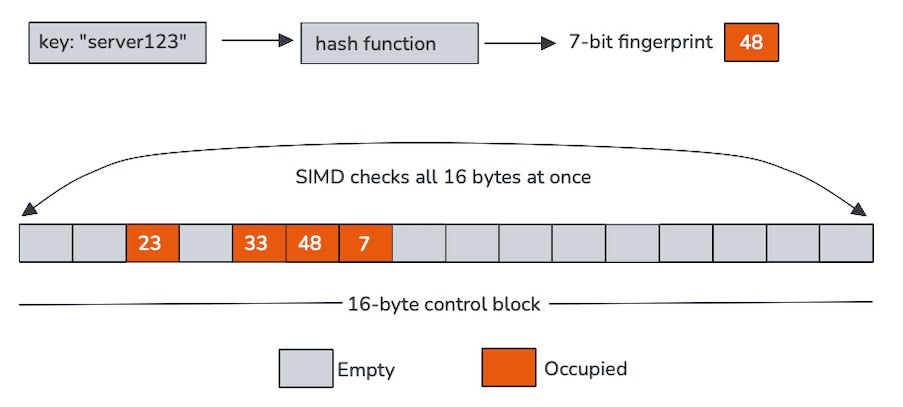
En pratique, cela signifie :
- Moins de branches.
- Des chaînes de détection plus courtes.
- Moins de chargements depuis la mémoire des clés et des valeurs.
- Une bien meilleure utilisation des unités d'exécution du processeur.
La plupart des recherches ne dépassent jamais l'étape de l'analyse de l'octet de contrôle. Lorsqu'elles y parviennent, le travail restant est ciblé et prévisible. C'est précisément le type de charge de travail pour lequel les processeurs modernes excellent.
SIMD sous le capot
Pour les lecteurs qui aiment jeter un œil sous le capot, voici ce qui se passe lors de l'insertion d'une nouvelle clé dans la table. Nous utilisons l'API Panama Vector avec des vecteurs de 128 bits, opérant ainsi sur 16 octets de contrôle en parallèle.
L'extrait suivant montre le code généré sur un processeur Intel Rocket Lake avec AVX-512. Bien que les instructions reflètent cet environnement, la conception ne dépend pas d'AVX-512. Les mêmes opérations vectorielles de haut niveau sont émises sur d'autres plateformes en utilisant des instructions équivalentes (par exemple, AVX2, SSE ou NEON).
Chaque instruction a un rôle clair dans le processus d'insertion :
vmovdqu: Charge 16 octets de contrôle consécutifs dans le registrexmm0de 128 bits.vpbroadcastb: Réplique l'empreinte 7 bits de la nouvelle clé sur toutes les voies du registrexmm1.vpcmpeqb: Compare chaque octet de contrôle à l'empreinte diffusée, produisant un masque de correspondances potentielles.kmovq+test: Déplace le masque vers un registre à usage général et vérifie rapidement si une correspondance existe.
Enfin, nous avons opté pour le sondage de groupes de 16 octets de contrôle à la fois, car les tests comparatifs ont montré que l'extension à 32 ou 64 octets avec des registres plus larges n'apportait aucun avantage mesurable en termes de performances.
Intégration dans ES|QL
L'adoption du hachage suisse dans Elasticsearch n'a pas été une simple solution de remplacement. ES|QL impose des exigences strictes de gestion de la mémoire, de sécurité et d'intégration au reste du moteur de calcul.
Nous avons étroitement intégré la nouvelle table de hachage à la gestion de la mémoire d'Elasticsearch, notamment au recycleur de pages et à la comptabilisation des coupures, afin de garantir la visibilité et la limitation des allocations. Les agrégations d'Elasticsearch sont stockées de manière dense et indexées par un identifiant de groupe, ce qui optimise la structure de la mémoire et la rapidité d'itération, tout en autorisant certaines optimisations de performance grâce à l'accès aléatoire.
Pour les clés binaires de longueur variable, nous mettons en cache le hachage complet ainsi que l'identifiant du groupe. Cela évite le recalcul coûteux des codes de hachage lors du sondage et améliore la localité du cache en regroupant les métadonnées associées. Lors du rehachage, nous pouvons nous appuyer sur le hachage et les octets de contrôle mis en cache sans avoir à examiner les valeurs elles-mêmes, ce qui réduit les coûts de redimensionnement.
Une simplification importante de notre implémentation est que les entrées ne sont jamais supprimées. Cela élimine le besoin de marqueurs (pour identifier les emplacements précédemment occupés) et permet aux emplacements vides de rester véritablement vides, ce qui améliore encore le comportement de sondage et maintient l'efficacité des analyses d'octets de contrôle.
Le résultat est une conception qui s'intègre naturellement dans le modèle d'exécution d'Elasticsearch tout en préservant les caractéristiques de performance qui rendent les tables suisses attrayantes.
Quelles sont ses performances ?
Pour les petites cardinalités, les tables suisses offrent des performances globalement équivalentes à celles de l'implémentation existante. Ce résultat est normal : lorsque les tables sont petites, les effets de cache sont moins importants et il y a peu de détections à optimiser.
À mesure que la cardinalité augmente, la situation change rapidement.
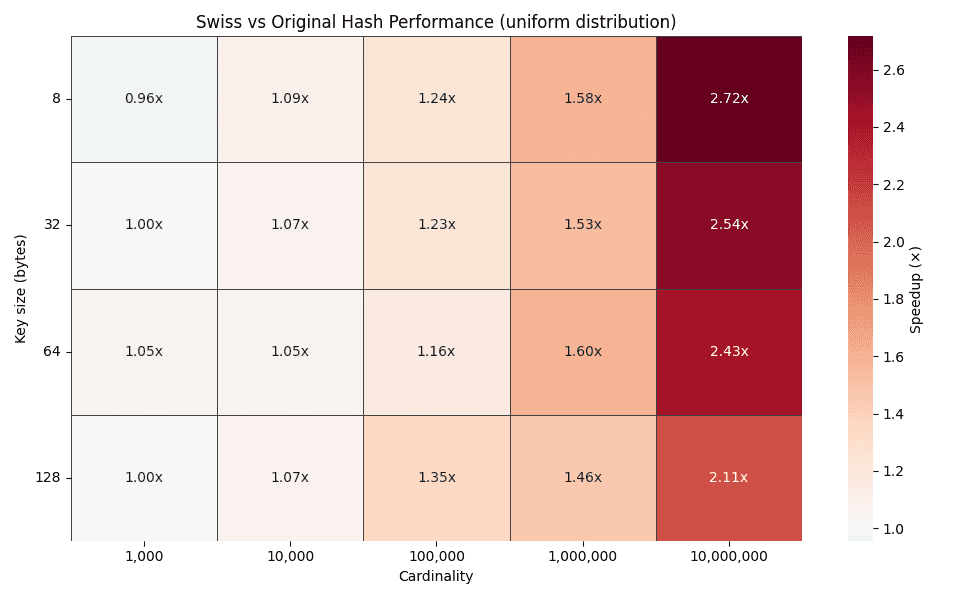
La carte thermique ci-dessus montre les facteurs d'amélioration du temps de traitement pour différentes tailles de clés (8, 32, 64 et 128 octets) pour des cardinalités allant de 1 000 à 10 000 000 de groupes. À mesure que la cardinalité augmente, le facteur d'amélioration s'accroît régulièrement, jusqu'à 2 à 3 fois pour les distributions uniformes.
Cette tendance correspond exactement aux prévisions de conception. Une cardinalité plus élevée entraîne des chaînes de détection plus longues dans les tables de hachage traditionnelles, tandis que le mode de sondage de type suisse continue de résoudre la plupart des recherches dans des blocs d'octets de contrôle compatibles SIMD.
Le comportement du cache raconte l'histoire
Pour mieux comprendre les gains de vitesse, nous avons exécuté le même JMH benchmarks sous Linux perf et capturé les statistiques du cache et du TLB.
Comparée à l'implémentation originale, la version suisse effectue environ 60 % d'accès au cache en moins. Les chargements du cache de dernier niveau sont 4 fois moins nombreux, et les défauts de chargement du cache LLC 6 fois moins. Étant donné que ces défauts se traduisent souvent directement par des accès à la mémoire principale, cette réduction explique à elle seule une grande partie de l'amélioration globale des performances.
Plus on se rapproche du processeur, moins on observe d'échecs de cache de données L1 et près de 6 fois moins d'échecs de TLB de données, ce qui indique une localité spatiale plus étroite et des schémas d'accès à la mémoire plus prévisibles.
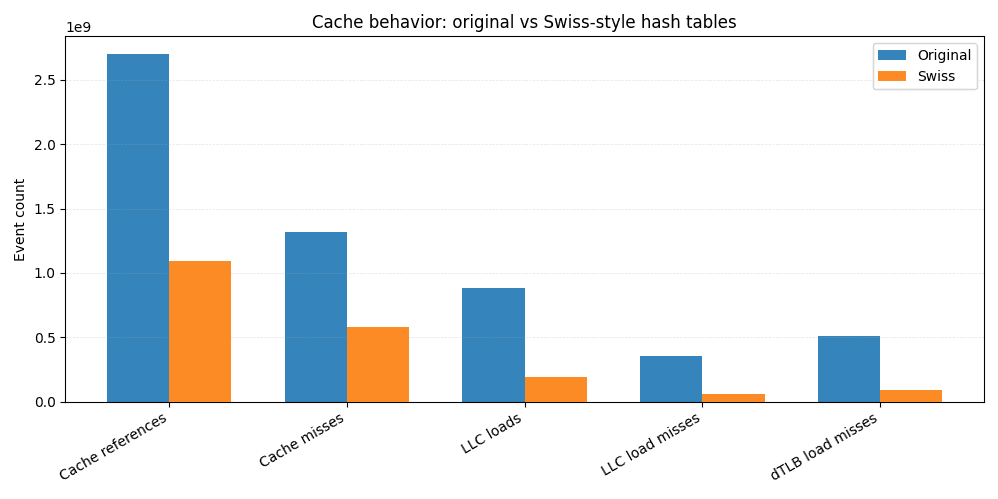
C'est l'avantage concret des octets de contrôle compatibles SIMD. Au lieu de charger sans cesse des clés et des valeurs depuis des emplacements mémoire dispersés, la plupart des requêtes sont résolues par l'analyse d'une structure compacte résidant dans le cache. Moins de mémoire utilisée signifie moins d'échecs de lecture, et moins d'échecs de lecture signifient des requêtes plus rapides.
Conclusion
En adoptant une conception de table de hachage de style suisse et en misant fortement sur le sondage compatible SIMD, nous avons obtenu des gains de vitesse de 2 à 3 fois pour les charges de travail statistiques ES|QL à cardinalité élevée, ainsi que des performances plus stables et prévisibles.
Ce travail met en lumière comment les structures de données modernes optimisées pour le processeur peuvent générer des gains substantiels, même pour des problèmes complexes comme les tables de hachage. Il reste encore beaucoup à explorer, notamment en matière de spécialisation des types primitifs et d'utilisation dans d'autres opérations à forte cardinalité, telles que les jointures. Ces pistes s'inscrivent dans le cadre d'un effort plus vaste et continu de modernisation du fonctionnement interne d'Elasticsearch.
Si vous êtes intéressé par les détails ou souhaitez suivre le travail, consultez cette pull request et la meta issue qui suit les progrès sur Github.
Bon hachage !
Pour aller plus loin

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.
12 décembre 2025
Présentation de la prise en charge d'Elasticsearch dans Google MCP Toolbox for Databases
Découvrez les caractéristiques de la prise en charge d'Elasticsearch maintenant disponible dans Google MCP Toolbox for Databases et utilisez les outils ES|QL pour intégrer en toute sécurité votre index à n'importe quel client MCP.
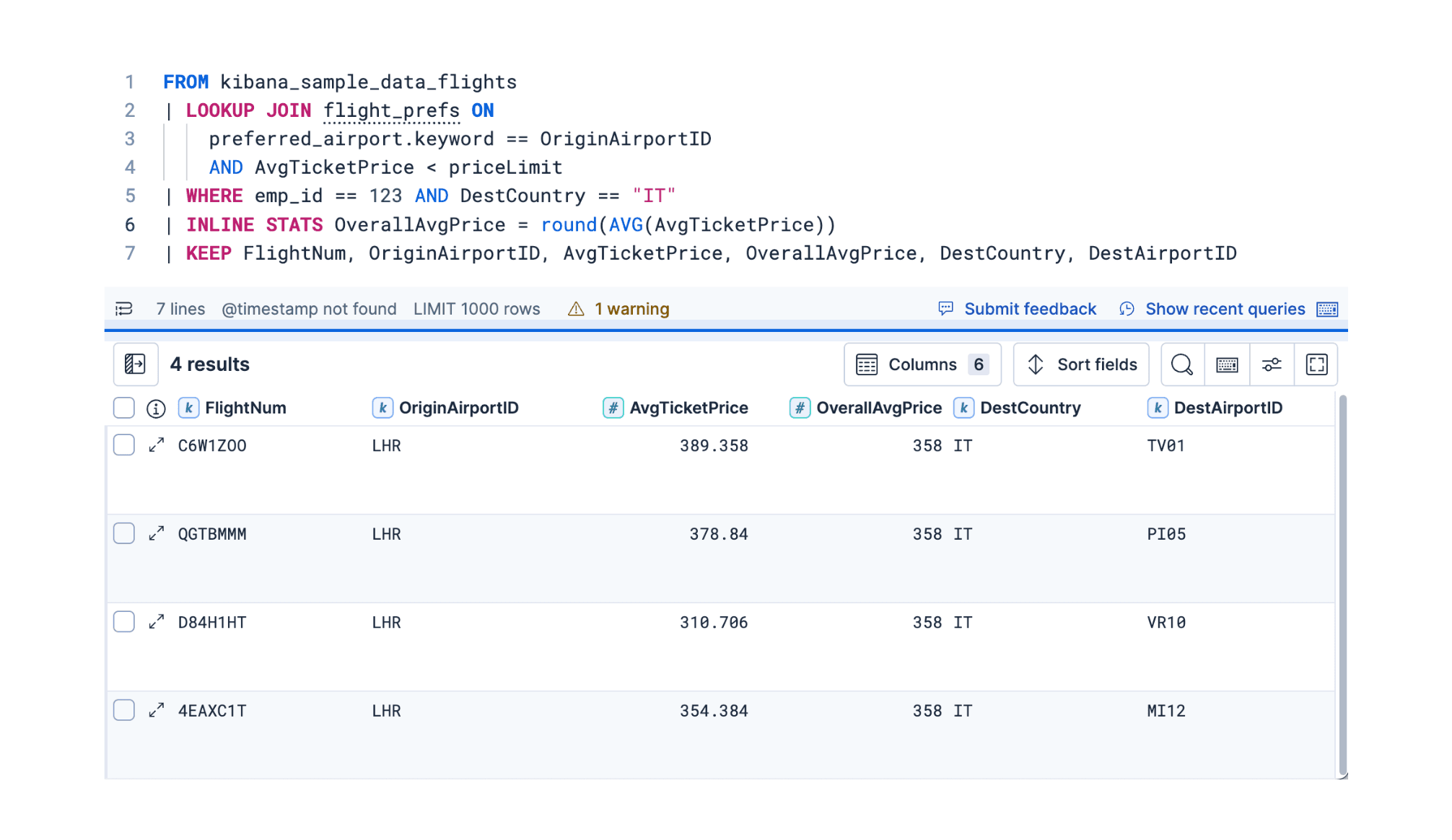
2 décembre 2025
ES|QL dans la version 9.2 : jointures Smart Lookup et prise en charge des séries temporelles
Découvrez trois nouveautés d’ES|QL dans Elasticsearch 9.2 : une jointure LOOKUP optimisée pour une corrélation de données plus expressive, la nouvelle commande TS pour l’analyse des séries temporelles, et la commande flexible INLINE STATS pour l’agrégation.

18 septembre 2025
L'expérience de l'éditeur ES|QL d'Elasticsearch par rapport à l'analyseur d'événements PPL d'OpenSearch
Découvrez comment les fonctionnalités avancées d'ES|QL Editor accélèrent votre flux de travail, en contraste direct avec l'approche manuelle de PPL Event Analyzer d'OpenSearch.

Présentation du générateur de requêtes ES|QL pour le client Elasticsearch Ruby
Apprenez à utiliser le constructeur de requêtes ES|QL récemment publié pour le client Elasticsearch Ruby. Un outil pour construire des requêtes ES|QL plus facilement avec du code Ruby.