我们近期将 Elasticsearch 哈希表实现的核心组件替换为 Swiss 式设计,在均匀高基数工作负载下观察到构建与迭代速度提升 2-3 倍。最终使 Elasticsearch 查询语言 (ES|QL) 的统计数据与分析操作实现更低延迟、更高吞吐量,且性能表现更可预测。
为什么这很重要
绝大多数典型分析流程最终都归结为数据分组操作。无论是计算每台主机的平均字节数、统计每个用户的事件数量,还是跨维度聚合指标,其核心操作始终如一,那就是将键映射到分组并更新累计聚合值。
在小规模场景下,几乎任何合理的哈希表都能良好运行。但在大规模场景(数亿文档、数百万独立分组)中,细节决定成败。负载因素、探测策略、内存布局和缓存行为,这些因素可能让性能呈现线性增长,也可能导致严重的缓存未命中问题。
Elasticsearch 多年来一直支持这些工作负载,但我们一直在寻找机会来更新核心算法。因此,我们评估了一种受 Swiss 表启发的新方法,并将其应用于 ES|QL 如何计算统计数据。
到底什么是 Swiss 表?
Swiss 表是一类由 Google SwissTable 推广的现代哈希表系列,后被 Abseil 等资料库采纳。
传统哈希表在探测过程中需频繁追踪指针或加载键值,却发现大量不匹配情况。Swiss 哈希表的核心创新在于通过独立于键值存储的微型缓存驻留数组结构(称为控制字节),可拒绝大多数探测,从而显著降低内存流量。
每个控制字节对应一个哈希槽,在我们的应用中编码两类信息:槽是否为空,以及从哈希值派生的短指纹。这些控制字节在内存中连续存储(通常以 16 字节为一组),使其非常适合单指令多数据 (SIMD) 并行处理。
Swiss 表摒弃逐槽探测的传统方式,转而通过向量指令一次性扫描整个控制字节块。CPU 在单次操作中,将待插入键的指纹与 16 个槽位的指纹进行批量比对,并过滤掉空条目。仅当少数候选键通过这一快速通道后,才需要加载并比对实际键值。
该设计通过引入少量额外元数据,换取了更高的缓存命中率和大幅减少的随机内存访问。随着哈希表规模扩大及探测链长度增加,这些特性将愈发凸显其价值。
以SIMD为中心
真正的主角是 SIMD。
控制字节不仅结构紧凑,更专门针对向量指令处理进行优化设计。单条 SIMD 比对指令可同时校验 16 个指纹,将传统循环操作转化为数条高效宽指令处理。例如:
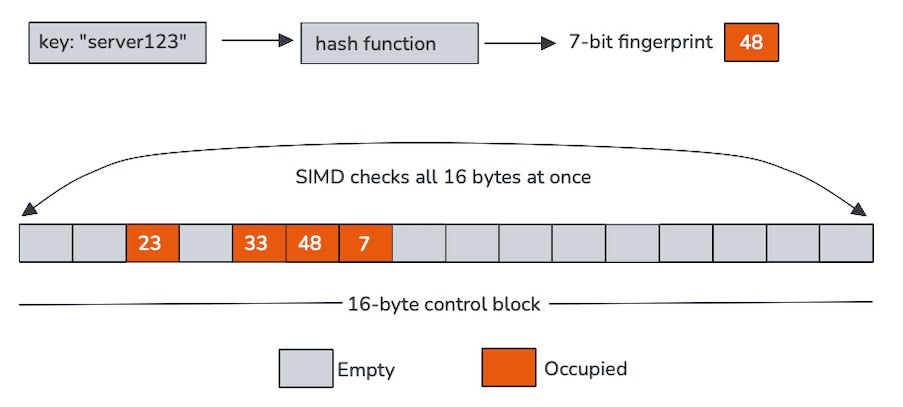
实际上,这意味着:
- 更少的分支。
- 更短的探针链。
- 减少键值存储的内存加载次数。
- 更好地利用了CPU的执行单元。
绝大多数查询在控制字节扫描阶段即可完成过滤。当需要进一步处理时,剩余操作高度集中且可预测,而这正是现代 CPU 所擅长的负载类型。
深入了解 SIMD
对于喜欢探究底层实现细节的读者,以下是向表中插入新键时的具体流程:我们使用 Panama Vector API 配合 128 位向量,因此可并行处理 16 个控制字节。
以下代码片段展示了在配备 AVX-512 的 Intel Rocket Lake 处理器上生成的代码。虽然这些指令反映了当前硬件环境,但该设计并不依赖 AVX-512。在其他平台上会生成等效指令(如 AVX2、SSE 或 NEON)来实现相同的高层向量操作。
每条指令在插入过程中都起着明确的作用:
vmovdqu:将 16 个连续的控制字节加载到 128 位xmm0寄存器中。vpbroadcastb:将新键的 7 位指纹复制到xmm1寄存器的所有向量通道中。vpcmpeqb:将每个控制字节与广播后的指纹进行并行比较,生成潜在匹配的掩码。kmovq+test:将掩码移动到通用寄存器,并快速检查是否存在匹配。
最终,我们决定一次探测 16 个控制字节组,因为基准测试表明,扩展到 32 或 64 个字节并使用更宽的寄存器并没有带来明显的性能提升。
ES|QL 中的集成
在 Elasticsearch 中采用 Swiss 式哈希算法并非简单的替换操作。ES|QL 对内存核算、安全性以及与计算引擎其他部分的集成有着严苛要求。
我们将新型哈希表与 Elasticsearch 的内存管理机制深度集成,包括分页回收器和熔断器核算模块,确保内存分配始终透明且受控。Elasticsearch 的聚合数据采用密集存储方式并通过组 ID 索引,在保持内存布局紧凑、迭代高效的同时,通过支持随机访问实现了特定性能优化。
对于可变长度字节键,我们在存储组 ID 的同时缓存完整哈希值。此设计避免了探测过程中重复计算高开销的哈希码,并通过将关联元数据集中存储提升了缓存命中率。在重新哈希时,系统可直接利用缓存的哈希值和控制字节,无需检查键值本身,从而将容量调整成本降至最低。
我们实施中的一个重要简化策略是永不删除条目。这一设计消除了对“墓碑”标记(用于标识已释放槽位的占位符)的需求,使空槽保持真正空闲状态。这种优化进一步改善了探测行为,并确保控制字节扫描始终保持高效。
这样的设计在完美契合 Elasticsearch 执行模型的同时,保留了使 Swiss 表具吸引力的高性能特性。
它的表现如何?
在小规模数据量下,Swiss 表的性能与现有实现基本持平。这符合预期,当哈希表较小时,缓存效应的影响减弱,且待优化的探测操作本就较少。
随着数据规模扩大,性能特征迅速发生质变。
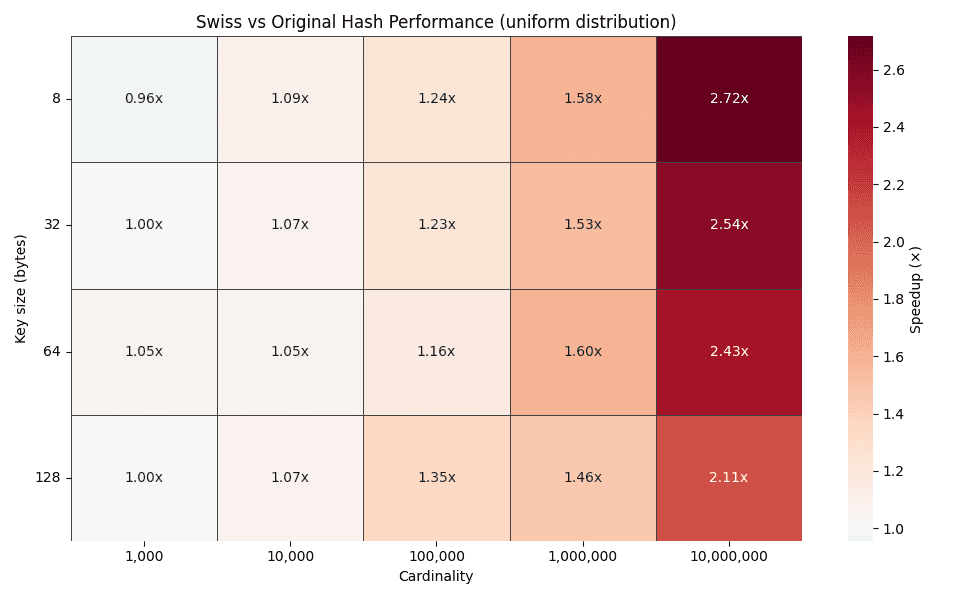
上方热图展示了不同键大小(8、32、64 和 128 字节)在数据规模从 1,000 至 10,000,000 组变化时的时间优化倍数。随着数据规模扩大,优化倍数呈稳定上升趋势,在均匀分布场景下最高可达 2-3 倍。
这一趋势完全符合设计预期。传统哈希表在数据规模扩大时会导致探测链长度增加,而 Swiss 式探测仍能在支持 SIMD 指令的控制字节块内完成绝大多数查询操作。
缓存行为说明了一切
为深入分析加速效果,我们在 Linux perf环境下运行相同的 JMH benchmarks基准测试,并采集缓存与 TLB 统计数据。
与原始实施相比,Swiss 版实现的总缓存引用量减少约 60%,末级缓存(LLC)加载次数下降超 4 倍,LLC 加载未命中次数更是降低超 6 倍。由于 LLC 未命中通常直接导致主存访问,仅此一项优化就解释了端到端性能提升的绝大部分原因。
在更靠近 CPU 的层级,我们观察到 L1 数据缓存未命中次数显著减少,数据 TLB 未命中次数更降低近 6 倍,这表明数据空间局部性增强且内存访问模式更具可预测性。
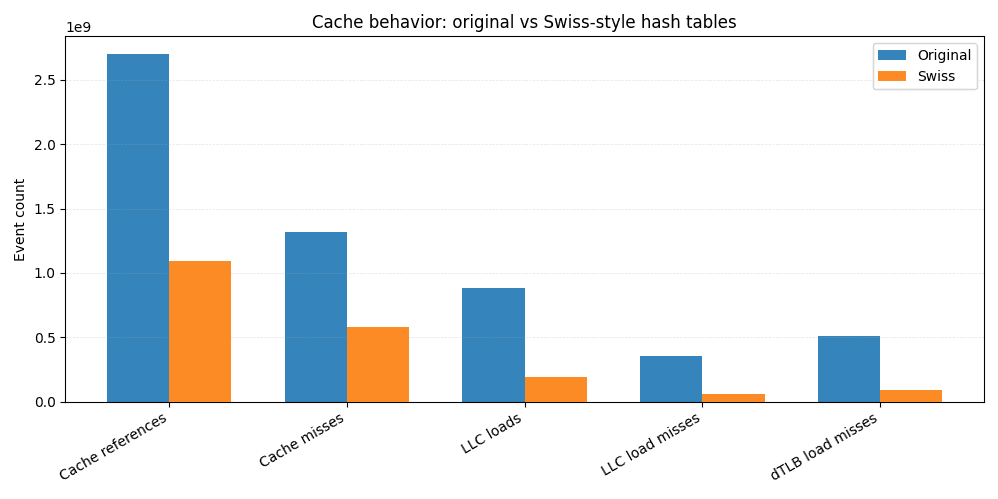
这正是 SIMD 友好型控制字节带来的实际效益。无需反复从分散的内存位置加载键和值,大多数探测操作仅需扫描紧凑、驻留缓存的结构体即可完成。内存访问量减少意味着缓存未命中率降低,而未命中率降低则直接提升查询速度。
总结
通过采用 Swiss 式哈希表设计并深度融合 SIMD 友好型探测机制,我们在高基数 ES|QL 统计工作负载中实现了 2-3 倍的速度提升,同时获得了更稳定且可预测的系统表现。
本研究揭示了现代 CPU 感知型数据结构如何为哈希表等老问题带来显著性能提升。该领域仍有广阔探索空间,例如扩展至更多基础数据类型的特化实现,以及在连接等高基数操作路径中的应用。这些工作均属于 Elasticsearch 内核持续现代化这一长期工程的重要组成部分。
如需了解详细信息或跟进项目进展,可查看 GitHub 上的该拉取请求及追踪进度的元议题。
祝您哈希愉快!
相关内容

LINQ to Elasticsearch ES|QL:编写 C# 代码,查询 Elasticsearch
探索 Elasticsearch .NET 客户端中全新的 LINQ to Elasticsearch ES|QL 提供程序。借助该程序,您可以编写会自动转换为 ES|QL 查询的 C# 代码。
在 Google MCP Toolbox for Databases 中引入 Elasticsearch 支持
了解 Google MCP Toolbox for Databases 现在如何提供 Elasticsearch 支持,并利用 ES|QL 工具将您的索引安全地集成到任何 MCP 客户端中。
2025年12月2日
9.2 中的 ES|QL:Smart Lookup Joins 和时间序列支持
探索 Elasticsearch 9.2 中 ES|QL 的三个独立更新:增强的 LOOKUP JOIN 用于更具表现力的数据关联、新的 TS 命令用于时间序列分析,以及灵活的 INLINE STATS 命令用于聚合。

2025年9月18日
Elasticsearch 的 ES|QL 编辑器体验与 OpenSearch 的 PPL 事件分析器对比
了解 ES|QL Editor 的高级功能如何加速您的工作流程,与 OpenSearch 的 PPL 事件分析器的手动方法形成直接对比。

介绍用于 Elasticsearch Ruby 客户端的 ES|QL 查询生成器
了解如何使用最近发布的用于 Elasticsearch Ruby 客户端的 ES|QL 查询生成器。这是一款使用 Ruby 代码更轻松地构建 ES|QL 查询的工具。