Elasticsearch 9.2, sorti en octobre, est doté d'avancées significatives qui rendent l'analyse de vos données plus rapide, plus flexible et plus accessible que jamais. Au cœur de cette version se trouvent d'importantes améliorations apportées à ES|QL, notre langage de requêtes canalisées, conçu pour apporter encore plus de valeur directement aux utilisateurs finaux.
Découvrez les fonctionnalités d’Elasticsearch 9.2 qui révolutionneront votre analyse de données avec ES|QL.
Révolutionner la corrélation des données : un Lookup Join plus intelligent, plus rapide et plus flexible
La commande LOOKUP JOIN dans ES|QL a subi une transformation importante dans Elasticsearch 9.2, elle devient considérablement plus efficace et polyvalente. LOOKUP JOIN fusionne les données issues de la table de résultats de votre requête ES|QL avec les enregistrements concordants d’un index de mode de recherche que vous avez désigné. Cela permet d’ajouter des champs de l’index de recherche en tant que nouvelles colonnes à votre table de résultats, en faisant correspondre les valeurs du champ de jointure. Auparavant, la jointure des données était limitée à un seul champ et à une simple égalité. Plus maintenant ! Ces améliorations vous permettent de gérer facilement des scénarios complexes de corrélation de données.
Les principales améliorations de Lookup Join incluent :
- Jointures multi-champs : Effectuez facilement des jointures sur plusieurs champs. Par exemple, pour joindre
application_logsàservice_registrysurservice_name,environmentetversion:
- Utilisation d’expressions pour des prédicats de jointure complexes (aperçu technologique) :
Vous n'êtes plus limité à la simple égalité. LOOKUP JOIN permet désormais de spécifier plusieurs critères de corrélation et d’incorporer une gamme d’opérateurs binaires, notamment ==, !=, <, >, <=et >=. Cela signifie que vous pouvez créer des conditions de jointure très nuancées, vous permettant de poser des questions beaucoup plus sophistiquées à vos données.
Exemple 1 : Recherche des métriques d’application avec un seuil de SLA par service
Exemple 2 : Cette requête calcule le montant dû, en se basant sur les politiques tarifaires régionales qui évoluent au fil du temps. Cela relie trois ensembles de données basés sur des périodes complexes et des conditions d’égalité pour calculer un due_amountfinal. La deuxième jonction de recherche utilise le champ measurement_date de l’indice meter_readings et le champ region_id de l’indice customers pour joindre l’indice pricing_policies et trouver la politique de tarification appropriée pour le region et le measurement_date particuliers.
- Des gains de performances considérables pour les jointures filtrées :
Nous avons amélioré les performances des « jointures en expansion » qui sont filtrées à l'aide de conditions de table de recherche. Les jointures en expansion produisent plusieurs correspondances par ligne d'entrée, ce qui peut créer de grands ensembles de résultats intermédiaires. Cela s’aggrave lorsqu’un filtre ultérieur écarte un grand nombre de ces lignes. Avec la version 9.2, nous optimisons ces jointures en excluant les lignes superflues lorsqu’un filtre est appliqué aux données de recherche, ce qui permet d’éviter de traiter des lignes vouées à être éliminées. Dans certains scénarios, ces jointures peuvent être jusqu'à 1000 fois plus rapides !
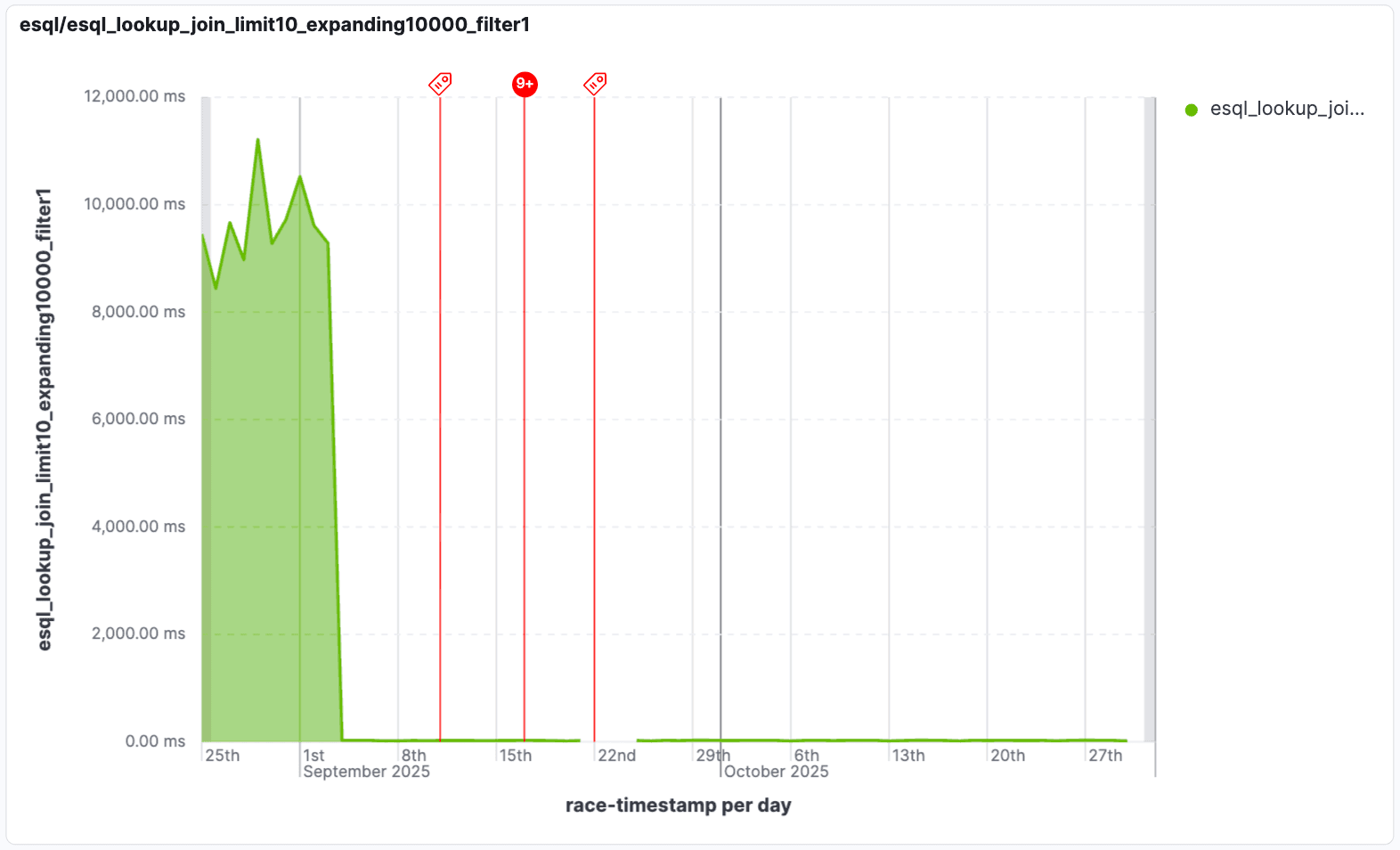
Cette optimisation est déterminante pour gérer les « jointures à résultats multiples », là où une consultation initiale peut produire de nombreux résultats potentiels. La transmission intelligente des filtres garantit que seules les données pertinentes sont traitées, réduisant ainsi fortement le temps d’exécution des requêtes pour une analyse en temps réel sur des ensembles de données gigantesques. Cela signifie que vous obtenez vos informations beaucoup plus rapidement, même avec des opérations de jointure très volumineuses ou complexes.
Recherchez la compatibilité de Lookup Join avec la rechercher inter-clusters (CCS) :
Lorsque Lookup Join est devenu disponible en version générale dans les versions 8.19 et 9.1, il manquait le support de la recherche inter-clusters (CCS). LOOKUP JOIN s’intègre parfaitement à CCS en 9.2, ce qui est un atout majeur pour les entreprises gérant plusieurs clusters. Placez simplement votre index de recherche sur tous les clusters distants où vous souhaitez effectuer une jointure, et ES|QL utilisera automatiquement ces index de recherche distants pour la jointure avec vos données distantes. Cela simplifie l'analyse distribuée des données et garantit un enrichissement constant sur l'ensemble de votre déploiement Elasticsearch.
Ces améliorations vous permettent de corréler divers ensembles de données avec une précision, une rapidité et une facilité sans précédent, afin de découvrir des informations plus approfondies et plus exploitables sans solutions complexes ni étapes de prétraitement.
Enrichissez vos données en toute simplicité : Kibana Discover UX pour les index de recherche
L’enrichissement des données doit rester simple, et non constituer un problème. Une fantastique nouvelle expérience utilisateur a été ajoutée à Discover (Kibana) pour créer et gérer les index de recherche.
Workflow intuitif : la fonction de saisie semi-automatique complète de Discover vous guidera tout au long du processus, en suggérant des index de recherche et des champs de jointure dans l’éditeur ES|QL, ce qui facilite grandement la connexion de vos données téléchargées avec les index existants. Tapez le nom d'un index de recherche qui n'existe pas et accédez directement à l'éditeur de recherche en un seul clic pour créer l'index. Tapez le nom d'un index de recherche existant, et nous vous suggérerons une option pour le modifier :

Gestion en ligne (CRUD) : maintenez vos ensembles de données de référence à jour grâce à des fonctionnalités d'édition en ligne (création, lecture, mise à jour, suppression) directement dans Discover.

Téléchargement de fichiers sans effort : vous pouvez désormais télécharger directement des fichiers, tels que des CSV, dans Discover et les utiliser instantanément dans vos LOOKUP JOIN. Plus besoin de changer constamment de contexte en naviguant entre les différentes zones de Kibana !
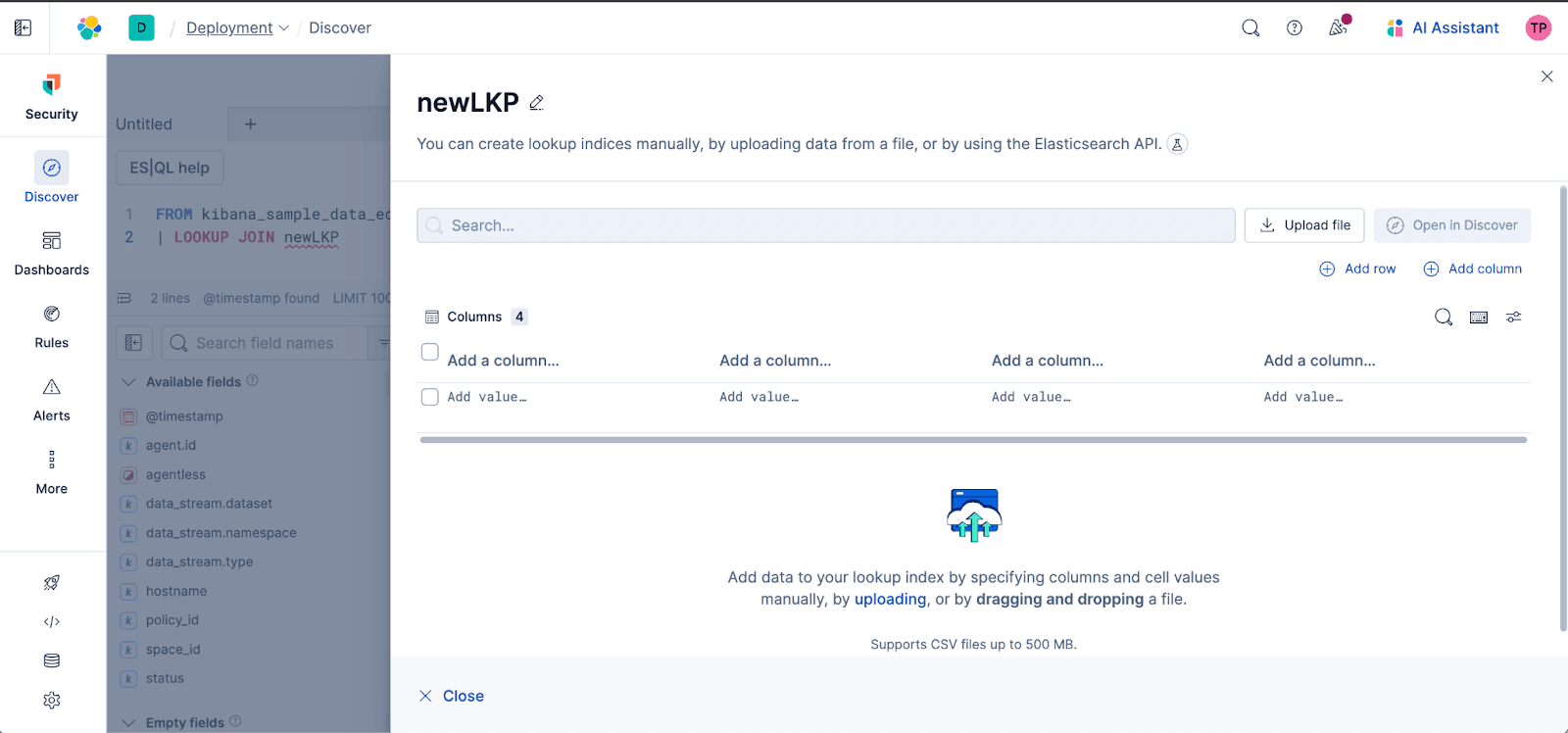
Cette fonctionnalité démocratise l’enrichissement des données, que vous mappiez des ID utilisateur à des noms, ajoutiez des métadonnées d’entreprise ou joigniez des fichiers de référence statiques. La puissance des jointures est désormais à la portée de tous, de manière rapide, simple et au même endroit.
Préservez votre contexte : présentation d'INLINE STATS (aperçu technique)
L'agrégation des données est cruciale, mais parfois vous avez besoin de voir les agrégations à côté de vos données originales. Nous sommes ravis de présenter les STATS EN LIGNE en tant que fonctionnalité de la Tech Preview.
Contrairement à la commande STATS, qui remplace vos champs d'entrée par une sortie agrégée, INLINE STATS préserve tous vos champs d'entrée d'origine et ajoute simplement les nouveaux champs agrégés. Cela vous permet d’effectuer des opérations supplémentaires sur vos champs d’entrée originaux après l’agrégation, offrant ainsi un workflow d’analyse plus continu et plus flexible.
Par exemple, pour calculer la distance moyenne des vols tout en conservant les lignes de vol individuelles :

Dans cette requête, avgDist est ajouté à chaque ligne avec le Destcorrespondant (ination) par lequel nous avons regroupé, puis, comme nous avons toujours les colonnes d’information de vol, nous pouvons filtrer les résultats vers les vols ayant une distance supérieure à la moyenne.
Prise en charge des séries temporelles dans ES|QL (aperçu technique)
Elasticsearch utilise des flux de données temporelles pour stocker des métriques. Nous ajoutons la prise en charge des agrégations de séries temporelles dans ES|QL, via la commande source TS . Cette fonctionnalité est disponible dans Elastic Cloud serverless et en version 9.2 (niveau Basic) en préversion technique.
L’analyse de séries temporelles est principalement basée sur des requêtes d’agrégation qui résument les valeurs de métriques sur des plages de temps, segmentées par une ou plusieurs dimensions de filtrage. La majorité des requêtes d’agrégation nécessitent un traitement en deux étapes, avec (a) une fonction d’agrégation interne qui résume les valeurs de chaque série temporelle, et (b) une fonction d’agrégation externe qui consolide les résultats de (a) au travers des séries temporelles.
La commande source TS, combinée à STATS, offre un moyen concis et efficace d'exprimer de telles requêtes sur des séries temporelles. Plus concrètement, considérons l’exemple suivant pour calculer le taux total de requêtes par hôte et par heure :
Dans ce cas, la fonction d'agrégation de séries chronologiques RATE est d'abord évaluée par série chronologique et par heure. Les agrégats partiels produits sont ensuite combinés à l'aide de SUM pour calculer les valeurs agrégées finales par hôte et par heure.
Vous pouvez consulter la liste des fonctions d'agrégation de séries temporelles disponibles ici. La fonction counter_rate est désormais prise en charge, sans doute la fonction d’agrégation la plus importante pour le traitement des compteurs.
La commande source TS est conçue pour être combinée avec STATS, avec une exécution adaptée pour prendre en charge efficacement les agrégations de séries temporelles. Par exemple, les données sont triées avant d’entrer dans le STATS. Les commandes de traitement susceptibles d’enrichir ou de modifier les données temporelles ou leur ordre, telles que FORK ou INLINE STATS, ne sont actuellement pas autorisées entre TS et STATS. Cette restriction pourrait être levée à l’avenir.
La sortie tabulaire de STATS peut être traitée avec n'importe quelle commande applicable. Par exemple, la requête suivante calcule le rapport entre la valeur moyenne de cpu_usage hébergé par hôte et par heure et la valeur maximale par hôte :
Les données de séries temporelles sont enregistrées sur notre moteur de stockage sous-jacent à colonnes, optimisé par les doc values de Lucene. La commande TS ajoute une exécution vectorisée de requêtes via le moteur de calcul ES|QL. Les performances des requêtes sont souvent améliorées de plus d'un ordre de grandeur, par rapport aux requêtes DSL équivalentes, et sont comparables aux systèmes établis spécifiques aux métriques. Une analyse détaillée de l’architecture et des performances sera bientôt disponible. Ne manquez pas cette publication.
Élargir votre boîte à outils : nouvelles fonctions ES|QL
Manipulation de chaînes : CONTAINS, MV_CONTAINS, URL_ENCODE, URL_ENCODE_COMPONENT, URL_DECODE pour un traitement plus robuste du texte et des URL.
Séries temporelles et géospatial : TBUCKET pour des buckets temporels flexibles, TO_DENSE_VECTOR pour les opérations vectorielles, et un ensemble complet de fonctions géospatiales comme ST_GEOHASH, ST_GEOTILE, ST_GEOHEX, TO_GEOHASH, TO_GEOTILE, TO_GEOHEX pour une analyse avancée basée sur la localisation.
Formatage de la date : DAY_NAME, MONTH_NAME pour une représentation plus lisible des dates.
Ces fonctions vous offrent un ensemble d'outils plus riche pour manipuler et analyser vos données directement dans ES|QL.
Sous le capot : plus de performance et d'efficacité
Au-delà des fonctionnalités mises en avant, Elasticsearch 9.2 inclut de nombreuses optimisations de performances pour ES|QL. Nous avons accéléré RLIKE (LIST) avec pushdown dans les cas où la fonction remplace plusieurs requêtes RLIKE similaires. Avec RLIKE (LIST), nous pouvons fusionner ces requêtes en un seul automate et appliquer un automate au lieu de plusieurs. Nous avons également accéléré le chargement des champs de mots clés grâce à des tris d'index et des optimisations générales des requêtes. Ces améliorations garantissent que vos requêtes ES|QL s'exécutent plus efficacement que jamais.
Lancez-vous dès aujourd'hui !
La version 9.2 d’Elasticsearch représente une avancée majeure pour ES|QL, conférant une puissance et une flexibilité inédites à vos workflows d’analyse de données. Nous vous encourageons à explorer ces nouvelles fonctionnalités et à constater la différence qu’elles apportent.
Pour une liste complète de tous les changements et améliorations dans Elasticsearch 9.2, veuillez consulter les notes de publication officielles. Bonne recherche !
Pour aller plus loin

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.
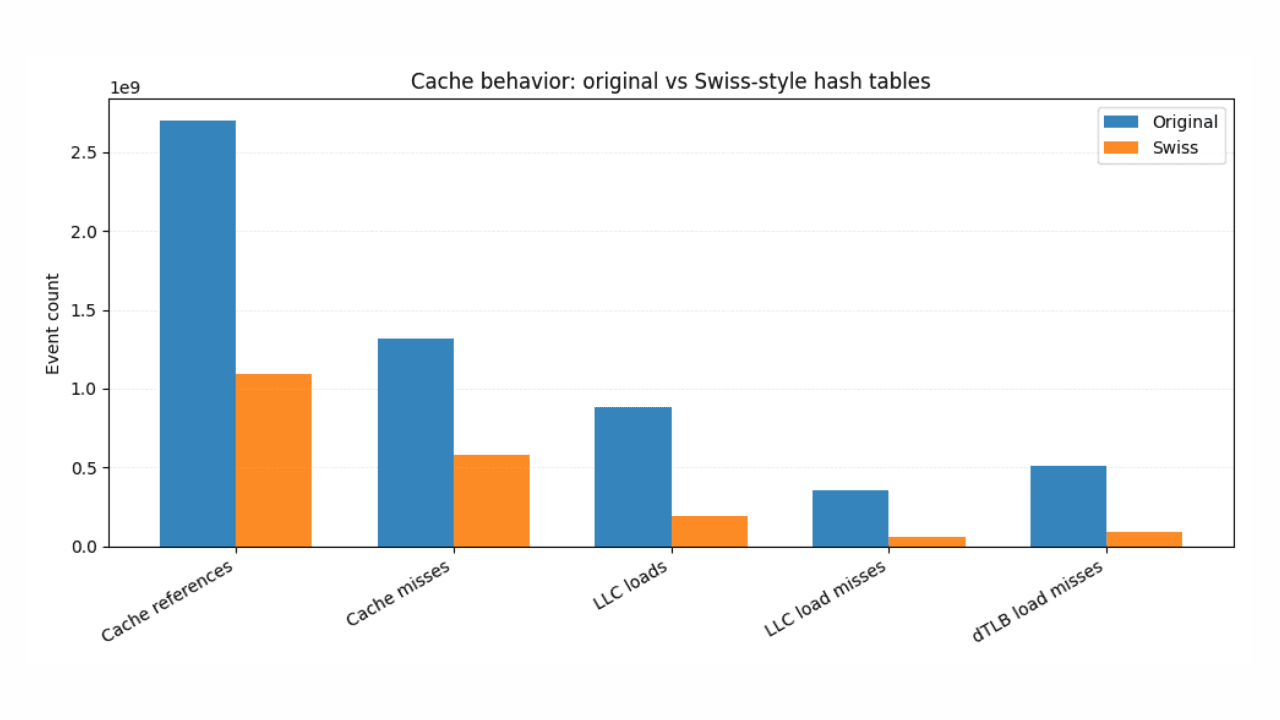
19 janvier 2026
Statistiques ES|QL plus rapides avec des tables de hachage de style suisse
Comment le hachage d'inspiration suisse et la conception compatible SIMD permettent d'obtenir des accélérations constantes et mesurables dans le langage de requête Elasticsearch Query Language (ES|QL).
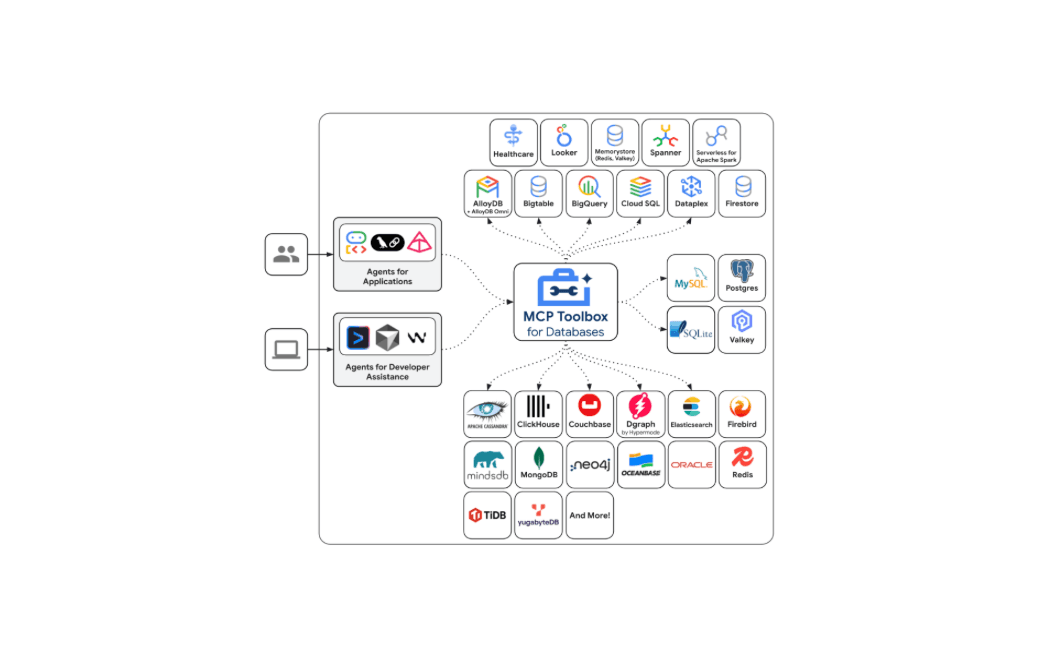
12 décembre 2025
Présentation de la prise en charge d'Elasticsearch dans Google MCP Toolbox for Databases
Découvrez les caractéristiques de la prise en charge d'Elasticsearch maintenant disponible dans Google MCP Toolbox for Databases et utilisez les outils ES|QL pour intégrer en toute sécurité votre index à n'importe quel client MCP.

18 septembre 2025
L'expérience de l'éditeur ES|QL d'Elasticsearch par rapport à l'analyseur d'événements PPL d'OpenSearch
Découvrez comment les fonctionnalités avancées d'ES|QL Editor accélèrent votre flux de travail, en contraste direct avec l'approche manuelle de PPL Event Analyzer d'OpenSearch.

Présentation du générateur de requêtes ES|QL pour le client Elasticsearch Ruby
Apprenez à utiliser le constructeur de requêtes ES|QL récemment publié pour le client Elasticsearch Ruby. Un outil pour construire des requêtes ES|QL plus facilement avec du code Ruby.