Observez, sécurisez et explorez vos données avec une solution unifiée. De la supervision des applications à la détection des menaces, Kibana est votre plateforme polyvalente pour les cas d’usage critiques. Lancez votre essai gratuit de 14 jours dès maintenant.
Nous avons récemment publié un blog décrivant comment utiliser les nouvelles fonctionnalités de recherche géospatiale dans ES|QL, le nouveau et puissant langage de requête par pipeline d' Elasticsearch. Pour utiliser ces fonctionnalités, vous devez disposer de données géospatiales dans Elasticsearch. Dans ce blog, nous allons donc vous montrer comment ingérer des données géospatiales et comment les utiliser dans des requêtes ES|QL.

Importation de données géospatiales à l'aide de Kibana
Les données que nous avons utilisées pour les exemples du blog précédent étaient basées sur les données que nous utilisons en interne pour les tests d'intégration. Pour vous faciliter la tâche, nous l'avons inclus ici sous la forme de quelques fichiers CSV qui peuvent être facilement importés à l'aide de Kibana. Les données sont un mélange d'aéroports, de villes et de limites de villes. Vous pouvez télécharger les données à partir de :
- aéroports.csv
- Il s'agit d'une fusion de trois ensembles de données :
- Aéroports (noms, emplacements et données connexes) de Natural Earth
- Localisation des villes à partir de SimpleMaps
- Élévations des aéroports à partir de la base de données mondiale des aéroports
- Il s'agit d'une fusion de trois ensembles de données :
- limites_de_la_ville_de_l'aeroport.csv
- Il s'agit d'une fusion des noms d'aéroports et de villes ci-dessus avec une nouvelle source :
- Limites de la ville d'après OpenStreetMap
- Il s'agit d'une fusion des noms d'aéroports et de villes ci-dessus avec une nouvelle source :
Comme vous pouvez le deviner, nous avons passé un certain temps à combiner ces sources de données dans les deux fichiers ci-dessus, dans le but de pouvoir tester les fonctionnalités géospatiales d'ES|QL. Il se peut que cela ne corresponde pas tout à fait à vos besoins spécifiques en matière de données, mais j'espère que cela vous donnera une idée de ce qui est possible. En particulier, nous voulons démontrer quelques points intéressants :
- Importation de données contenant des champs géospatiaux avec d'autres données indexables
- Importer les données
geo_pointetgeo_shapeet les utiliser ensemble dans les requêtes - Importation de données dans deux index qui peuvent être reliés à l'aide d'une relation spatiale
- Création d'un pipeline d'ingestion pour faciliter les importations futures (au-delà de Kibana)
- Quelques exemples de processeurs d'acquisition, tels que
csv,convertetsplit
Bien que nous parlions de travailler avec des données CSV dans ce blog, il est important de comprendre qu'il y a plusieurs façons d ' ajouter des données géographiques en utilisant Kibana. Dans l'application Carte, vous pouvez télécharger des données délimitées telles que CSV, GeoJSON et ESRI ShapeFiles et vous pouvez également dessiner des formes directement dans la carte. Pour ce blog, nous nous concentrerons sur l'importation de fichiers CSV à partir de la page d'accueil de Kibana.
Importation des aéroports
Le premier fichier, airports.csv, a quelques particularités intéressantes avec lesquelles nous devons composer. Tout d'abord, les colonnes sont séparées par des espaces blancs supplémentaires, ce qui n'est pas typique des fichiers CSV. Deuxièmement, le champ type est un champ à valeurs multiples, que nous devons diviser en champs distincts. Enfin, certains champs ne sont pas des chaînes de caractères et doivent être convertis dans le bon type. Tout cela peut être fait en utilisant la fonction d'importation CSV de Kibana.

Commencez par la page d'accueil de Kibana. Une section intitulée "Get started by adding integrations" contient un lien intitulé "Upload a file":
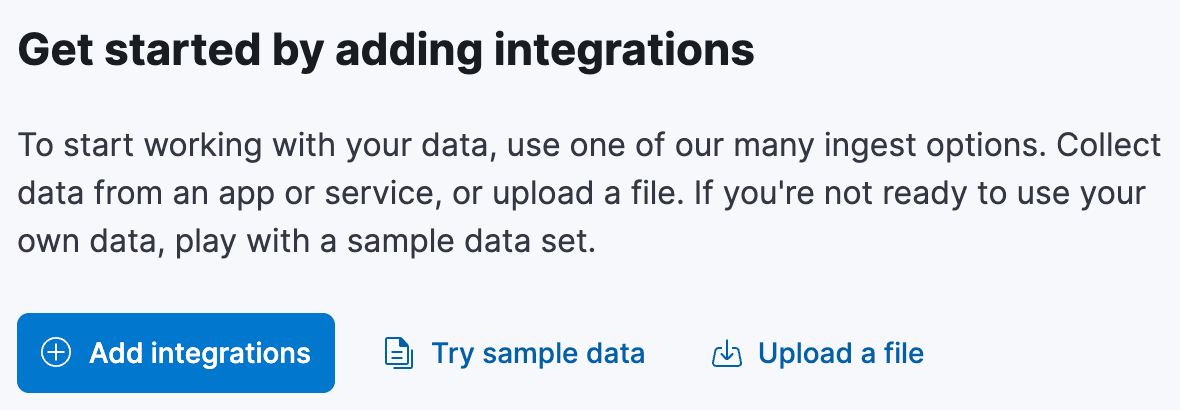
En cliquant sur ce lien, vous accéderez à la page "Upload file". Ici, vous pouvez faire glisser et déposer le fichier airports.csv, et Kibana analysera le fichier et vous présentera un aperçu des données. Il aurait dû détecter automatiquement que le délimiteur était une virgule et que la première ligne était la ligne d'en-tête. Cependant, il n'a probablement pas supprimé les espaces blancs supplémentaires entre les colonnes, ni déterminé les types de champs, en supposant que tous les champs sont soit text, soit keyword. Nous devons y remédier.

Cliquez sur Override settings et cochez les cases Should trim fields et Apply pour fermer les paramètres. Nous devons maintenant fixer les types de champs. Elle est disponible à la page suivante, alors cliquez sur Import.

Choisissez d'abord un nom d'index, puis sélectionnez Advanced pour accéder à la page des mappages de champs et du processeur d'ingestion.

Ici, nous devons apporter des modifications aux mappages de champs pour l'index, ainsi qu'au pipeline d'ingestion pour l'importation des données. Tout d'abord, alors que Kibana a probablement auto-détecté le champ scalerank comme étant long, il a perçu par erreur les champs location et city_location comme étant keyword. Modifiez-les à l'adresse geo_point, et vous obtiendrez des correspondances qui ressembleront à quelque chose de semblable :
Vous disposez d'une certaine marge de manœuvre, mais sachez que le type de champ choisi aura une incidence sur la manière dont il sera indexé et sur le type de requêtes possibles. Par exemple, si vous laissez location comme keyword, vous ne pouvez pas effectuer de recherches géospatiales sur ce site. De même, si vous laissez elevation en tant que text, vous ne pouvez pas effectuer de requêtes sur les plages numériques.
Il est maintenant temps de réparer le pipeline d'ingestion. Si Kibana a détecté automatiquement scalerank comme long ci-dessus, il aura également ajouté un processeur pour convertir le champ en long. Nous devons ajouter un processeur similaire pour le champ elevation, en le convertissant cette fois en double. Modifiez le pipeline pour vous assurer que cette conversion est en place. Avant de l'enregistrer, nous souhaitons effectuer une autre conversion, afin de diviser le champ type en plusieurs champs. Ajouter un processeur split au pipeline, avec la configuration suivante :
Le pipeline d'ingestion final devrait ressembler à ceci :
Notez que nous n'avons pas ajouté de processeur de conversion pour les champs location et city_location. Cela s'explique par le fait que le type geo_point dans la correspondance des champs comprend déjà le format WKT des données de ces champs. Le type geo_point peut comprendre une série de formats, notamment WKT, GeoJSON, etc. Si nous avions, par exemple, deux colonnes dans le fichier CSV pour latitude et longitude, nous aurions dû ajouter un processeur script ou set pour les combiner en un seul champ geo_point (par exemple. "set": {"field": "location", "value": "{{lat}},{{lon}}"}).
Nous sommes maintenant prêts à importer le fichier. Cliquez sur Import et les données seront importées dans l'index avec les mappings et le pipeline d'ingestion que nous venons de définir. Si des erreurs surviennent lors de l'ingestion des données, Kibana les signale ici, afin que vous puissiez modifier les données sources ou le pipeline d'ingestion et réessayer.
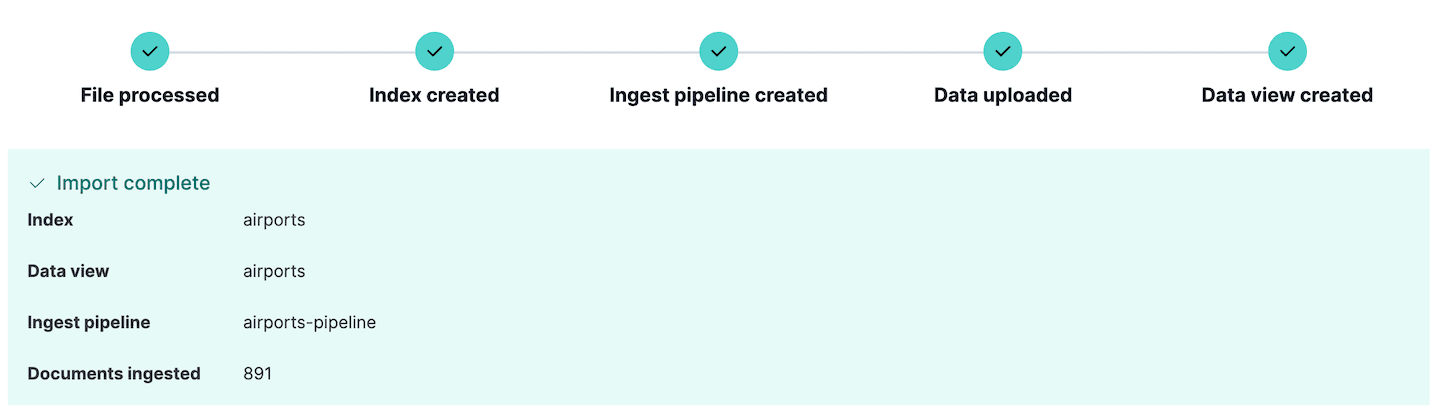
Remarquez qu'une nouvelle ligne d'ingestion a été créée. Il peut être consulté en allant dans la section Stack Management de Kibana, et en sélectionnant Ingest pipelines. Ici, vous pouvez voir le pipeline que nous venons de créer et le modifier si nécessaire. En fait, la section Ingest pipelines peut être utilisée pour créer et tester des pipelines d'ingestion, une fonctionnalité très utile si vous prévoyez d'effectuer des ingérences encore plus complexes.
Si vous souhaitez explorer ces données immédiatement, passez aux sections suivantes, mais si vous souhaitez également importer les limites des villes, continuez à lire.
Importation des limites de la ville
Le fichier des limites des villes disponible à l'adresse airport_city_boundaries.csv est un peu plus simple à importer que l'exemple précédent. Il contient un champ city_boundary qui est une représentation WKT des limites de la ville sous forme de POLYGON, et un champ city_location qui est une représentation geo_point de l'emplacement de la ville. Nous pouvons importer ces données de la même manière que les données aéroportuaires, à quelques différences près :
- Nous avons dû sélectionner le paramètre d'annulation
Has header rowcar il n'était pas détecté automatiquement. - Nous n'avons pas eu besoin de découper les champs, car les données étaient déjà exemptes d'espaces blancs supplémentaires.
- Nous n'avons pas eu besoin de modifier le pipeline d'ingestion car tous les types étaient soit des chaînes de caractères, soit des types spatiaux.
- Nous avons toutefois dû modifier les correspondances entre les champs afin de définir le champ
city_boundarycomme étantgeo_shapeet le champcity_locationcomme étantgeo_point
Nos mappages de champs finaux se présentaient comme suit :
Comme pour l'importation airports.csv, il suffit de cliquer sur Import pour importer les données dans l'index. Les données seront importées avec les mappings que nous avons édités et le pipeline d'ingestion défini par Kibana.
Explorer les données géospatiales avec les outils de développement
Dans Kibana, il est habituel d'explorer les données indexées avec "Discover". Cependant, si votre intention est d'écrire votre propre application en utilisant des requêtes ES|QL, il peut être plus intéressant d'essayer d'accéder à l'API Elasticsearch brute. Kibana dispose d'une console pratique pour expérimenter l'écriture de requêtes. Il s'agit de la console Dev Tools, qui se trouve dans la barre latérale de Kibana. Cette console communique directement avec le cluster Elasticsearch et peut être utilisée pour exécuter des requêtes, créer des index, etc.
Essayez ce qui suit :
Cela devrait donner les résultats suivants :
| distance | abbrev | nom | Lieu | pays | ville | élévation |
|---|---|---|---|---|---|---|
| 273418.05776847183 | HAM | Hambourg | POINT (10.005647830925 53.6320011640866) | Allemagne | Norderstedt | 17.0 |
| 337534.653466062 | TXL | Berlin-Tegel Int'l | POINT (13.2903090925074 52.5544287044101) | Allemagne | Hohen Neuendorf | 38.0 |
| 483713.15032266214 | OSL | Oslo Gardermoen | POINT (11.0991032762581 60.1935783171386) | Norvège | Oslo | 208.0 |
| 522538.03148094116 | BMA | Bromma | POINT (17.9456175406145 59.3555902065112) | Suède | Stockholm | 15.0 |
| 522538.03148094116 | ARN | Arlanda | POINT (17.9307299016916 59.6511203397372) | Suède | Stockholm | 38.0 |
| 624274.8274399083 | DHS | Düsseldorf Int'l | POINT (6.76494446612174 51.2781820420774) | Allemagne | Düsseldorf | 45.0 |
| 633388.6966435644 | PRG | Ruzyn | POINT (14.2674849854076 50.1076511703671) | Tchécoslovaquie | Prague | 381.0 |
| 635911.1873311149 | AMS | Schiphol | POINT (4.76437693232812 52.3089323889822) | Pays-Bas | Hoofddorp | -3.0 |
| 670864.137958866 | FRA | Francfort Int'l | POINT (8.57182286907608 50.0506770895207) | Allemagne | Francfort | 111.0 |
| 683239.2529970079 | WAW | Okecie Int'l | POINT (20.9727263383587 52.171026749259) | Pologne | Piaseczno | 111.0 |
Visualiser des données géospatiales avec Kibana Maps
Kibana Maps est un outil puissant de visualisation des données géospatiales. Il peut être utilisé pour créer des cartes avec plusieurs couches, chaque couche représentant un ensemble de données différent. Les données peuvent être filtrées, agrégées et stylisées de différentes manières. Dans cette section, nous allons vous montrer comment créer une carte dans Kibana Maps en utilisant les données que nous avons importées dans la section précédente.
Dans le menu Kibana, naviguez vers Analytics->Maps pour ouvrir une nouvelle vue de la carte. Cliquez sur Add Layer et sélectionnez Documents, choisissez la vue de données airports et modifiez le style de la couche pour colorer les marqueurs à l'aide du champ elevation, de sorte que nous puissions facilement voir à quelle hauteur se trouve chaque aéroport.
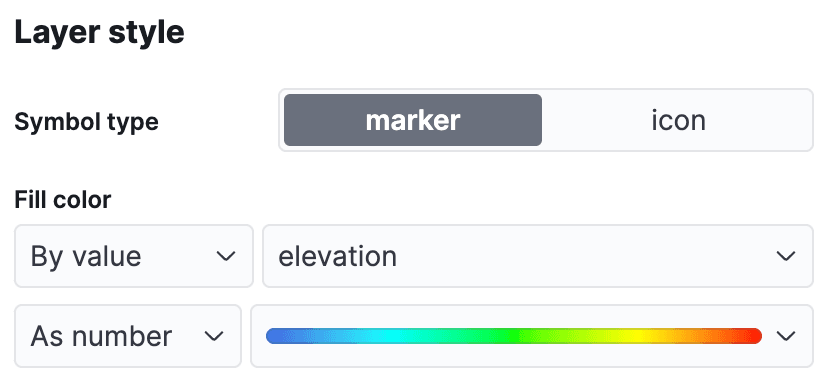
Cliquez sur "Conserver les modifications" pour enregistrer la carte :

Ajoutez maintenant une deuxième couche, en sélectionnant cette fois la vue de données airport_city_boundaries. Cette fois-ci, nous utiliserons le champ city_boundary pour styliser le calque et définir la couleur de remplissage sur un bleu clair. Les limites de la ville apparaissent alors sur la carte. Veillez à réorganiser les couches de manière à ce que les marqueurs d'aéroport soient placés en haut.

Jointures spatiales
ES|QL ne prend pas en charge les commandes JOIN, mais vous pouvez réaliser un cas spécial de jointure à l'aide de la commande ENRICH. Cette commande s'apparente à une "jointure gauche" en SQL, vous permettant d'enrichir les résultats d'un index avec des données d'un autre index sur la base d'une relation spatiale entre les deux ensembles de données.
Par exemple, enrichissons les résultats d'un tableau d'aéroports avec des informations supplémentaires sur la ville qu'ils desservent en trouvant la limite de la ville qui contient l'emplacement de l'aéroport, puis effectuons quelques statistiques sur les résultats :
Si vous exécutez cette requête sans avoir au préalable préparé l'index enrichi, vous obtiendrez un message d'erreur du type
En effet, comme nous l'avons déjà mentionné, ES|QL ne prend pas en charge les véritables commandes JOIN. L'une des raisons principales est qu'Elasticsearch est un système distribué et que les jointures sont des opérations coûteuses qu'il peut être difficile de faire évoluer. Cependant, la commande ENRICH peut être très efficace, car elle utilise des index enrichis spécialement préparés qui sont dupliqués sur l'ensemble du cluster, ce qui permet d'effectuer des jointures locales sur chaque nœud.
Pour mieux comprendre, concentrons-nous sur la commande ENRICH dans la requête ci-dessus :
Cette commande demande à Elasticsearch d'enrichir les résultats extraits de l'index airports et d'effectuer une jointure intersects entre le champ city_location de l'index original et le champ city_boundary de l'index airport_city_boundaries, que nous avons utilisé dans quelques exemples plus tôt. Mais certaines de ces informations ne sont pas clairement visibles dans cette requête. Ce que nous voyons, c'est le nom d'une politique d'enrichissement city_boundaries, et l'information manquante est encapsulée dans cette définition de politique.
Ici, nous pouvons voir qu'il effectuera une requête geo_match (intersects est la valeur par défaut), que le champ à comparer est city_boundary et que les champs enrich_fields sont les champs que nous voulons ajouter au document d'origine. L'un de ces champs, le region, a été utilisé comme clé de regroupement pour la commande STATS, ce que nous n'aurions pas pu faire sans cette capacité de "jointure à gauche". Pour plus d'informations sur les politiques d'enrichissement, voir la documentation d'enrichissement.
Les index et politiques d'enrichissement d'Elasticsearch ont été conçus à l'origine pour enrichir les données au moment de l'indexation, en utilisant les données d'un autre index d'enrichissement préparé. Dans ES|QL, cependant, la commande ENRICH fonctionne au moment de la requête et ne nécessite pas l'utilisation de pipelines d'ingestion. Cela le rend assez similaire à un SQL LEFT JOIN, sauf que vous ne pouvez pas joindre deux index, mais seulement un index normal à gauche avec un index enrichi spécialement préparé à droite.
Dans les deux cas, que ce soit pour les pipelines d'ingestion ou pour l'utilisation dans ES|QL, il est nécessaire d'effectuer quelques étapes préparatoires pour mettre en place l'index et la politique d'enrichissement. Nous avons déjà importé l'index airport_city_boundaries ci-dessus, mais il n'est pas directement utilisable comme index d'enrichissement dans la commande ENRICH. Nous devons d'abord effectuer deux démarches :
- Créez la politique d'enrichissement décrite ci-dessus pour définir l'index source, le champ de l'index source à comparer et les champs à renvoyer une fois la correspondance établie.
- Exécutez cette politique pour créer l'index d'enrichissement. Cela permet de construire un index interne spécial, en lisant l'index source d'origine dans une structure de données plus efficace qui est copiée à travers le cluster.
La politique d'enrichissement peut être créée à l'aide de la commande suivante :
La politique peut être exécutée à l'aide de la commande suivante :
Notez que si vous modifiez le contenu de l'index airport_city_boundaries, vous devrez réexécuter cette politique pour que les changements soient reflétés dans l'index enrichi. Exécutons à nouveau la requête ES|QL d'origine :
Cette méthode permet d'obtenir les 5 régions qui comptent le plus d'aéroports, ainsi que le centroïde de tous les aéroports qui ont des régions correspondantes et la longueur de la représentation WKT des limites des villes à l'intérieur de ces régions :
| centroïde | Compte | région |
|---|---|---|
| POINT (-12.139086859300733 31.024386116624648) | 126 | nul |
| POINT (-83.10398317873478 42.300230911932886) | 3 | Détroit |
| POINT (39.74537850357592 47.21613017376512) | 3 | городской округ Батайск |
| POINT (-156.80986787192523 20.476673701778054) | 3 | Hawaï |
| POINT (-73.94515332765877 40.70366442203522) | 3 | Ville de New York |
| POINT (-83.10398317873478 42.300230911932886) | 3 | Détroit |
| POINT (-76.66873019188643 24.306286952923983) | 2 | New Providence |
| POINT (-3.0252167768776417 51.39245774131268) | 2 | Cardiff |
| POINT (-115.40993484668434 32.73126147687435) | 2 | Municipalité de Mexicali |
| POINT (41.790108773857355 50.302146775648) | 2 | Центральный район |
| POINT (-73.88902732171118 45.57078813901171) | 2 | Montréal |
Vous pouvez également remarquer que la région la plus fréquemment trouvée est null. Qu'est-ce que cela peut signifier ? Rappelez-vous que j'ai comparé cette commande à une "jointure gauche" en SQL, ce qui signifie que si aucune limite de ville correspondante n'est trouvée pour un aéroport, l'aéroport est toujours renvoyé, mais avec les valeurs null pour les champs de l'index airport_city_boundaries. Il s'avère que 125 aéroports n'ont pas trouvé de correspondance avec city_boundary, et un aéroport avec une correspondance où le champ region était null. Cela a conduit à un décompte de 126 aéroports sans region dans les résultats. Si votre cas d'utilisation exige que tous les aéroports puissent être mis en correspondance avec les limites d'une ville, il faudra trouver des données supplémentaires pour combler les lacunes. Il serait nécessaire de déterminer deux choses :
- les enregistrements de l'index
airport_city_boundariesqui n'ont pas de champscity_boundary - les enregistrements de l'index
airportsqui ne correspondent pas à l'aide de la commandeENRICH(c'est-à-dire. ne se croisent pas)
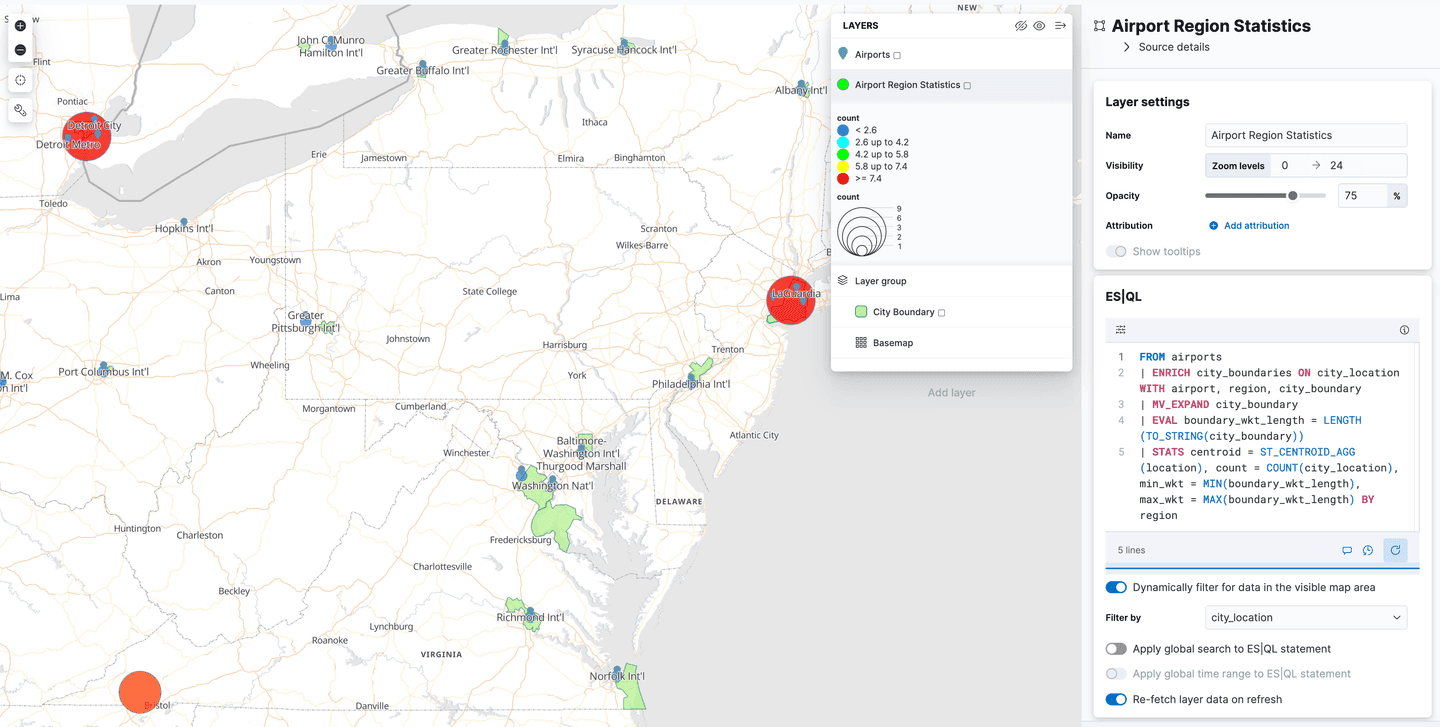
Utilisation de ES|QL pour les données géospatiales dans Kibana Maps
Kibana a ajouté la prise en charge de Spatial ES|QL dans l'application Maps. Cela signifie que vous pouvez désormais utiliser ES|QL pour rechercher des données géospatiales dans Elasticsearch et visualiser les résultats sur une carte.
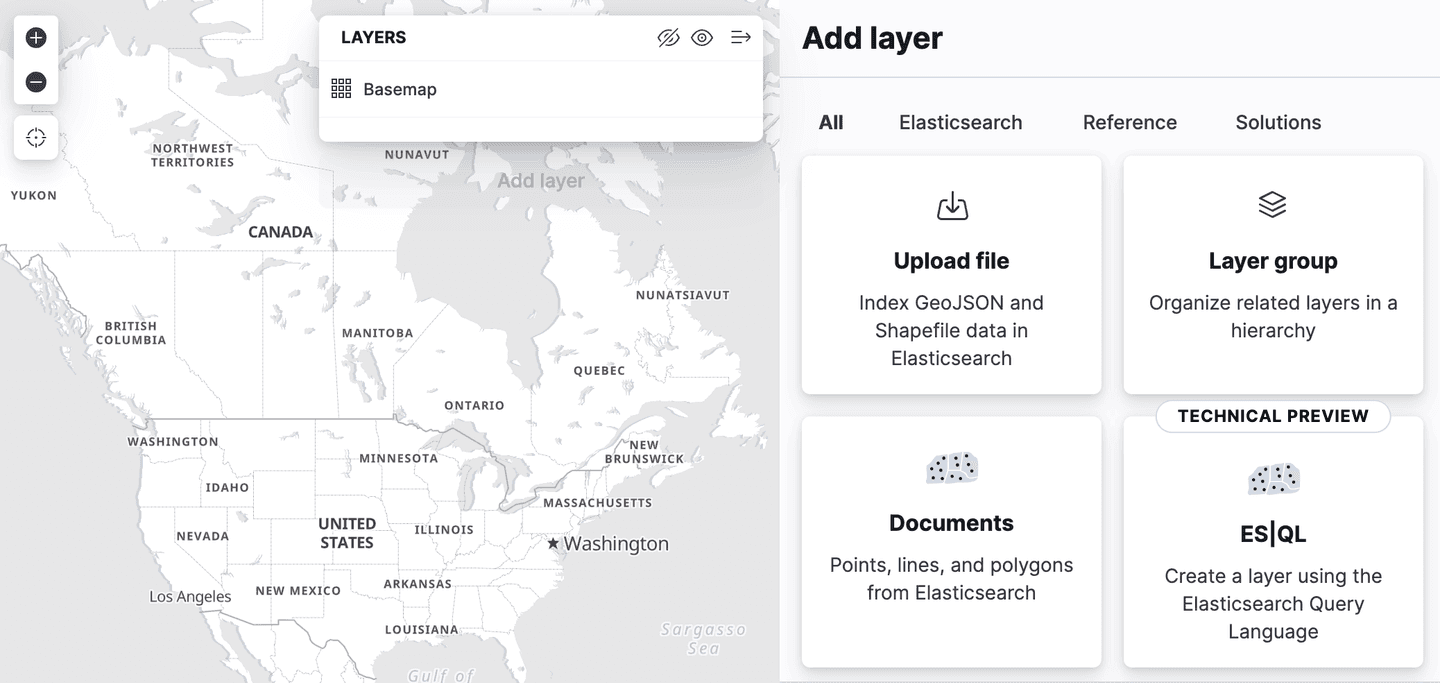
Il existe une nouvelle option de couche dans le menu d'ajout de couches, appelée "ES|QL". Comme toutes les fonctions géospatiales décrites jusqu'à présent, il s'agit d'un aperçu technique "" . Cette option permet d'ajouter une couche à la carte en fonction des résultats d'une requête ES|QL. Par exemple, vous pouvez ajouter une couche à la carte qui montre tous les aéroports du monde.

Vous pouvez également ajouter une couche qui montre les polygones de l'index airport_city_boundaries ou, mieux encore, la requête complexe ENRICH ci-dessus qui génère des statistiques sur le nombre d'aéroports dans chaque région.
Et ensuite ?
Le précédent blog sur la recherche géospatiale s'est concentré sur l'utilisation de fonctions telles que ST_INTERSECTS pour effectuer des recherches, disponibles dans Elasticsearch depuis la version 8.14. Ce blog vous montre comment importer les données que nous avons utilisées pour ces recherches. Cependant, Elasticsearch 8.15 a été doté d'une fonction particulièrement intéressante : ST_DISTANCE qui peut être utilisée pour effectuer des recherches de distance spatiale efficaces, et ce sera le sujet du prochain blog !
Pour aller plus loin

22 mai 2026
Kibana réduit le temps de chargement des tableaux de bord jusqu'à 25 %. Voici la stratégie d'interrogation qui se cache derrière
Découvrez comment Kibana utilise l'interrogation continue et la détection HTTP/2 côté navigateur pour réduire les temps de chargement des tableaux de bord jusqu'à 25 %, avec repli automatique sur HTTP/1.

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

25 mai 2026
AI Chat dans Kibana prend désormais en charge l'affichage natif des tableaux de bord
Elastic AI Chat dans Kibana permet désormais de créer des tableaux de bord à partir du langage naturel. Vos visualisations et analyses sont conservées dans un seul fil de discussion et vous pouvez les enregistrer en tant qu'objets Kibana réutilisables.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.
19 janvier 2026
Statistiques ES|QL plus rapides avec des tables de hachage de style suisse
Comment le hachage d'inspiration suisse et la conception compatible SIMD permettent d'obtenir des accélérations constantes et mesurables dans le langage de requête Elasticsearch Query Language (ES|QL).