Recentemente, substituímos partes importantes da implementação de tabelas hash do Elasticsearch por um design no estilo de Swiss Tables e observamos tempos de construção e iteração de 2 a 3 vezes mais rápidos em cargas de trabalho uniformes e de alta cardinalidade. O resultado é menor latência, melhor taxa de transferência e desempenho mais previsível para a linguagem de consulta do Elasticsearch (ES|QL) em estatísticas e operações de análise.
Por que isso é importante
A maioria dos fluxos de trabalho analíticos típicos acaba se resumindo ao agrupamento de dados. Seja calculando a média de bytes por host, contando eventos por usuário ou agregando métricas entre dimensões, a operação principal é a mesma: mapear chaves para grupos e atualizar agregados em execução.
Em pequena escala, praticamente qualquer tabela hash razoável funciona bem. Em grande escala (centenas de milhões de documentos e milhões de grupos distintos), os detalhes começam a importar. Fatores de carregamento, estratégia de sondagem, layout da memória e comportamento do cache podem fazer a diferença entre um desempenho linear e uma série de falhas de cache.
O Elasticsearch oferece suporte a essas cargas de trabalho há anos, mas estamos sempre buscando oportunidades para modernizar os algoritmos principais. Assim, avaliamos uma abordagem mais recente inspirada nas Swiss Tables e a aplicamos à maneira como o ES|QL calcula as estatísticas.
Afinal, o que são Swiss Tables?
As Swiss Tables são uma família de tabelas de hash modernas popularizadas pelo SwissTable do Google e posteriormente adotadas na Abseil e em outras bibliotecas.
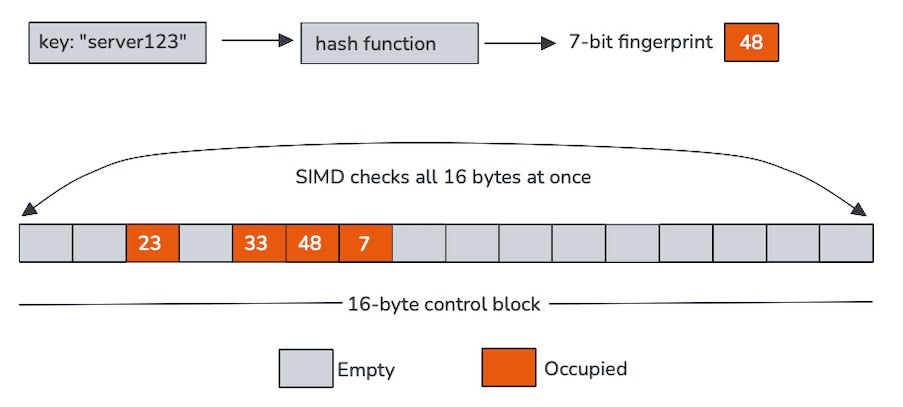
Tabelas hash tradicionais gastam muito tempo atrás de ponteiros ou carregando chaves apenas para descobrir que não correspondem. O principal recurso das Swiss Tables é a capacidade de rejeitar a maioria das sondagens usando uma pequena estrutura de matriz residente em cache, armazenada separadamente das chaves e valores, chamada de bytes de controle, para reduzir drasticamente o tráfego de memória.
Cada byte de controle representa um único slot e, em nosso caso, codifica duas coisas: se o slot está vazio e uma pequena impressão digital derivada do hash. Esses bytes de controle são dispostos de maneira contígua na memória, geralmente em grupos de 16, tornando-os ideais para processamento de instrução única e dados múltiplos (SIMD).
Em vez de sondar um slot de cada vez, as Swiss Tables analisam um bloco inteiro de controle de bytes usando instruções vetoriais. Em uma única operação, a CPU compara a impressão digital da chave de entrada com 16 slots e retira as entradas vazias. Somente os poucos candidatos que sobrevivem a esse processo rápido precisam ser carregados e comparados às chaves reais.
Esse design troca uma pequena quantidade extra de metadados por uma melhor localidade de cache e muito menos carregamentos aleatórios. À medida que a tabela cresce e as cadeias de sondagem se alongam, essas propriedades tornam-se cada vez mais valiosas.
SIMD no centro
A verdadeira estrela do espetáculo é o SIMD.
Bytes de controle não são apenas compactos, eles também são explicitamente projetados para serem processados com instruções vetoriais. Uma única comparação SIMD pode verificar 16 impressões digitais de uma vez, transformando o que normalmente seria um loop em algumas operações amplas. Por exemplo:
Na prática, isso significa:
- Menos ramificações.
- Cadeias de sondagem mais curtas.
- Menos carregamentos da memória de chave e valor.
- Utilização muito melhor das unidades de execução da CPU.
A maioria das pesquisas nunca passa da verificação do byte de controle. Quando isso acontece, o restante do trabalho é focado e previsível. Esse é exatamente o tipo de carga de trabalho que CPUs modernas fazem bem.
SIMD nos bastidores
Para os leitores que gostam de espiar os bastidores, aqui está o que acontece ao inserir uma nova chave na tabela. Usamos a Panama Vector API com vetores de 128 bits, operando assim em 16 bytes de controle em paralelo.
O trecho a seguir mostra o código gerado em um Intel Rocket Lake com AVX-512. Embora as instruções reflitam esse ambiente, o design não depende do AVX-512. As mesmas operações vetoriais de alto nível são emitidas em outras plataformas usando instruções equivalentes (por exemplo, AVX2, SSE ou NEON).
Cada instrução tem um papel claro no processo de inserção:
vmovdqu: Carrega 16 bytes de controle consecutivos no registradorxmm0de 128 bits.vpbroadcastb: Replica a impressão digital de 7 bits da nova chave em todas as faixas do registradorxmm1.vpcmpeqb: Compara cada byte de controle com a impressão digital transmitida, produzindo uma máscara de possíveis correspondências.kmovq+test: Move a máscara para um registrador de uso geral e verifica rapidamente se existe uma correspondência.
Finalmente, decidimos sondar grupos de 16 bytes de controle por vez, pois o benchmarking mostrou que a expansão para 32 ou 64 bytes com registros mais amplos não oferecia nenhum benefício mensurável de desempenho.
Integração em ES|QL
Adotar o hashing com a técnica de Swiss Tables no Elasticsearch não foi uma simples substituição. O ES|QL tem requisitos rigorosos em relação à contabilidade de memória, segurança e integração com o restante do motor de computação.
Integramos a nova tabela hash de maneira precisa com o gerenciamento de memória do Elasticsearch, incluindo o reciclador de páginas e a contabilização de mecanismos de interrupção, garantindo que as alocações permaneçam visíveis e limitadas. As agregações do Elasticsearch são armazenadas densamente e indexadas por uma ID de grupo, mantendo o layout da memória compacto e rápido para iterações, além de possibilitar certas otimizações de desempenho ao permitir acesso aleatório.
Para chaves de bytes de comprimento variável, armazenamos em cache o hash completo junto com a ID do grupo. Isso evita o recálculo de códigos hash caros durante a sondagem e melhora a localidade do cache ao manter os metadados relacionados próximos uns dos outros. Durante o rehashing, podemos confiar no hash e bytes de controle em cache sem inspecionar os próprios valores, mantendo os custos de redimensionamento baixos.
Uma simplificação importante em nossa implementação é que as entradas nunca são excluídas. Isso elimina a necessidade de lápides (marcadores para identificar slots ocupados anteriormente) e permite que os slots vazios permaneçam realmente vazios, o que melhora ainda mais o comportamento da sondagem e mantém a eficiência das varreduras dos bytes de controle.
O resultado é um design que se encaixa naturalmente no modelo de execução do Elasticsearch, preservando as características de desempenho que tornam as Swiss Tables interessantes.
Qual é o desempenho?
Em pequenas cardinalidades, as Swiss Tables apresentam desempenho aproximadamente equivalente à implementação existente. Isso é esperado: quando as tabelas são pequenas, os efeitos de cache dominam menos e há pouca sondagem para otimizar.
À medida que a cardinalidade aumenta, o cenário logo muda.
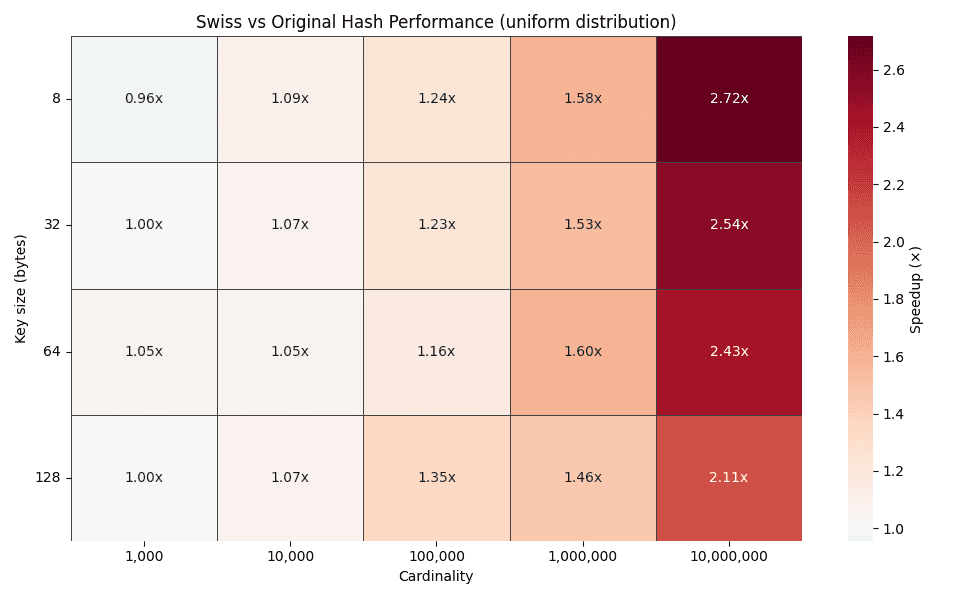
O heatmap acima mostra fatores de melhoria de tempo para diferentes tamanhos de chave (8, 32, 64 e 128 bytes) entre cardinalidades de 1.000 a 10.000.000 de grupos. À medida que a cardinalidade aumenta, o fator de melhoria aumenta constantemente, chegando a 2 a 3 vezes para distribuições uniformes.
Essa tendência é exatamente o que o design prevê. Uma maior cardinalidade leva a cadeias de sondagem mais longas em tabelas hash tradicionais, enquanto a sondagem com a técnica Swiss Tables continua resolvendo a maioria das pesquisas em blocos de bytes de controle compatíveis com SIMD.
O comportamento do cache conta a história
Para entender melhor as acelerações, executamos os mesmos benchmarks JMH sob o Linux perf e capturamos cache e estatísticas do TLB.
Em comparação com a implementação original, a versão Swiss Tables realiza cerca de 60% menos referências de cache no geral. Os carregamentos de cache no último nível caem mais de 4 vezes, e as falhas de carregamento da LLC caem mais de 6 vezes. Como as falhas de LLC costumam se traduzir diretamente em acessos à memória principal, essa redução sozinha explica grande parte da melhoria de ponta a ponta.
Mais próximo da CPU, observamos menos falhas de cache de dados L1 e quase 6 vezes menos falhas de dados TLB, indicando uma localidade espacial mais precisa e padrões de acesso à memória mais previsíveis.
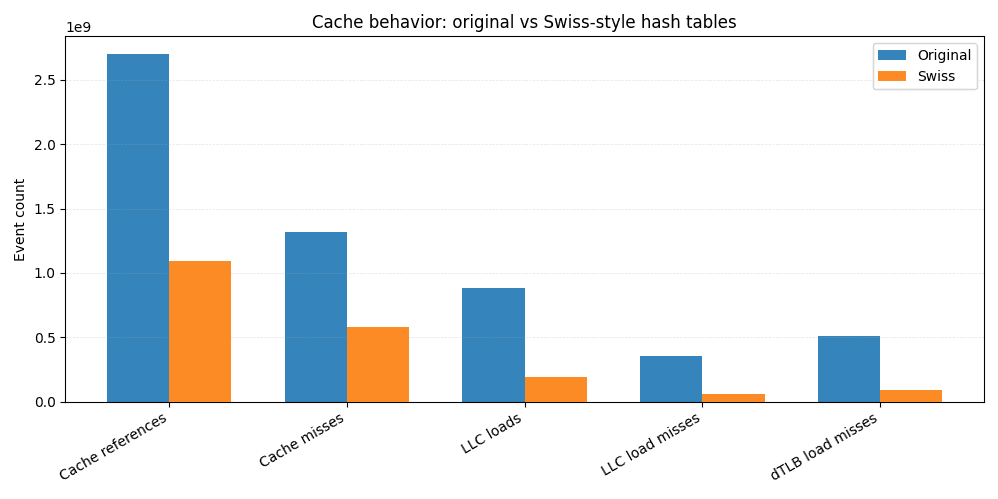
Esse é o benefício prático dos bytes de controle compatíveis com SIMD. Em vez de carregar repetidamente chaves e valores de locais de memória dispersos, a maioria das sondagens é resolvida analisando uma estrutura compacta residente no cache. Menos memória acessada significa menos falhas, e menos falhas significam consultas mais rápidas.
Conclusão
Ao adotar um design de tabela hash com a técnica Swiss Tables e apostar fortemente na sondagem compatível com SIMD, alcançamos uma aceleração de 2 a 3 vezes para cargas de trabalho de estatísticas ES|QL de alta cardinalidade, além de um desempenho mais estável e previsível.
Este trabalho destaca como estruturas de dados modernas conscientes da CPU podem desbloquear ganhos substanciais, mesmo para problemas já conhecidos, como tabelas hash. Há mais espaço para explorar aqui, como especializações adicionais de tipos primitivos e uso em outros caminhos de alta cardinalidade, como joins, todos eles apenas parte do esforço mais amplo e contínuo para modernizar continuamente os internos do Elasticsearch.
Se você tiver interesse nos detalhes ou quiser acompanhar o trabalho, confira o rastreamento de progresso de pull request e meta issue no Github.
Boa sorte com o hashing!
Conteúdo relacionado

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.
12 de dezembro de 2025
Introdução do suporte ao Elasticsearch no Google MCP Toolbox for Databases
Veja como o suporte ao Elasticsearch agora está disponível no Google MCP Toolbox for Databases e adote as ferramentas ES|QL para integrar seu índice com segurança a qualquer cliente MCP.
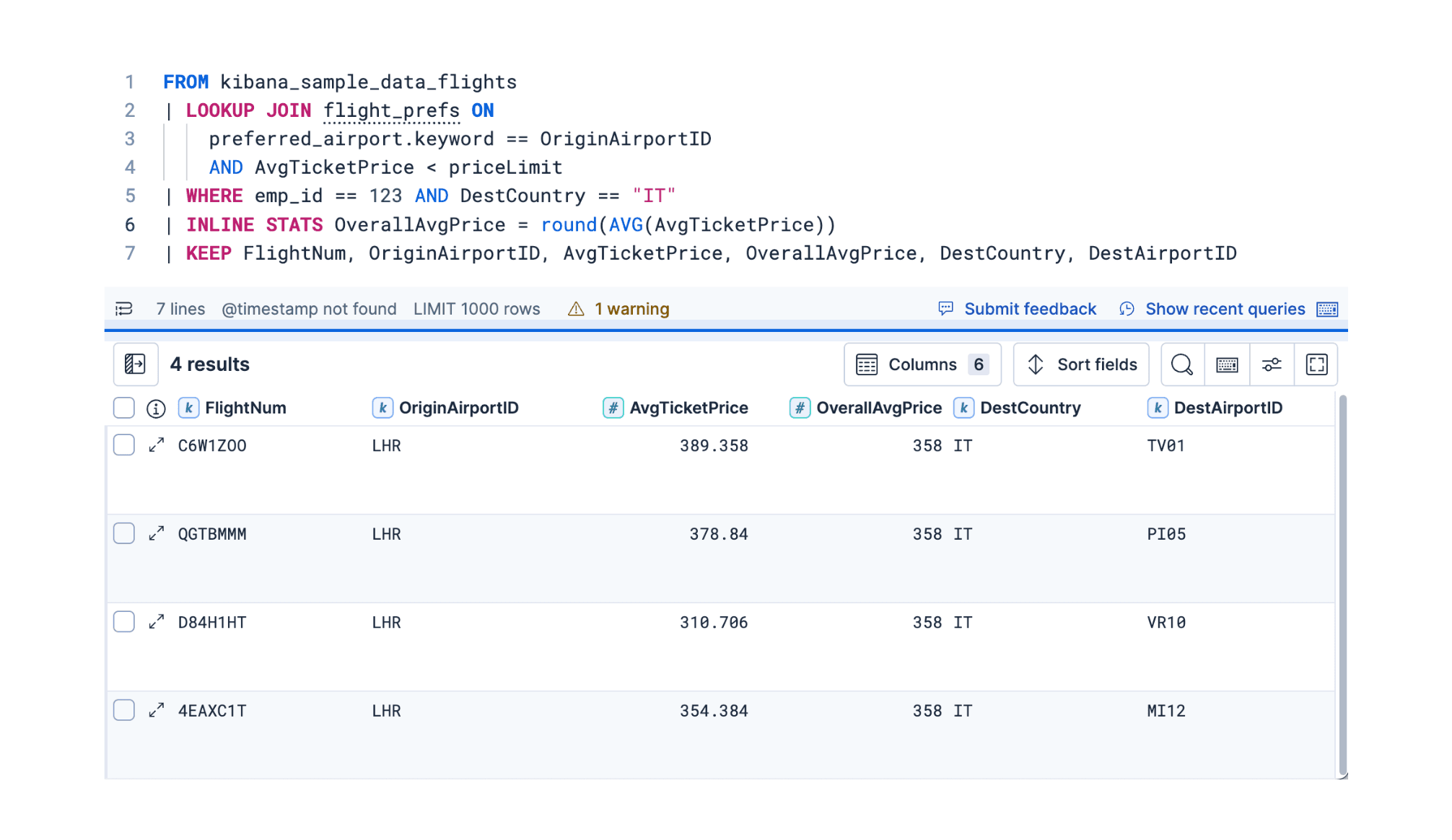
2 de dezembro de 2025
ES|QL na 9.2: Smart Lookup Joins e compatibilidade com séries temporais
Explore três atualizações separadas do ES|QL no Elasticsearch 9.2: um LOOKUP JOIN aprimorado para uma correlação de dados mais expressiva, o novo comando TS para análise de séries temporais e o comando INLINE STATS flexível para agregação.

18 de setembro de 2025
Experiência do editor ES|QL do Elasticsearch versus o analisador de eventos PPL do OpenSearch.
Descubra como os recursos avançados do ES|QL Editor aceleram seu fluxo de trabalho, em contraste direto com a abordagem manual do PPL Event Analyzer da OpenSearch.

Apresentamos o construtor de consultas ES|QL para o cliente Ruby do Elasticsearch.
Aprenda a usar o construtor de consultas ES|QL recém-lançado para o cliente Ruby do Elasticsearch. Uma ferramenta para criar consultas ES|QL mais facilmente com código Ruby.