Recientemente reemplazamos partes clave de la implementación de tablas hash de Elasticsearch por un diseño de estilo suizo y observamos tiempos de construcción e iteración hasta 2–3 veces más rápidos en cargas de trabajo uniformes y de alta cardinalidad. El resultado es una latencia más baja, un mejor rendimiento y un desempeño más predecible para las operaciones de estadísticas y análisis del lenguaje de búsqueda de Elasticsearch (ES|QL).
¿Por qué importa esto?
La mayoría de los flujos de trabajo analíticos típicos acaban reduciéndose a agrupar datos. Ya sea para calcular el promedio de bytes por host, contar eventos por usuario o agregar métricas en diferentes dimensiones, la operación de núcleo es la misma: asignar claves a grupos y actualizar los agregados en ejecución.
A pequeña escala, casi cualquier tabla hash razonable funciona bien. A gran escala (cientos de millones de documentos y millones de grupos distintos), los detalles empiezan a importar. Los factores de carga, la estrategia de sondeo, el diseño de la memoria y el comportamiento de la memoria caché pueden marcar la diferencia entre un rendimiento lineal y una barrera de fallos de caché.
Elasticsearch ha soportado estas cargas de trabajo durante años, pero siempre estamos buscando oportunidades para modernizar los algoritmos de núcleo. Por lo tanto, evaluamos un enfoque más reciente inspirado en las tablas suizas y lo aplicamos a cómo ES|QL calcula las estadísticas.
¿Qué son realmente las tablas suizas?
Las tablas suizas son una familia de tablas hash modernas popularizadas por la SwissTable de Google y posteriormente adoptadas en Abseil y otras bibliotecas.
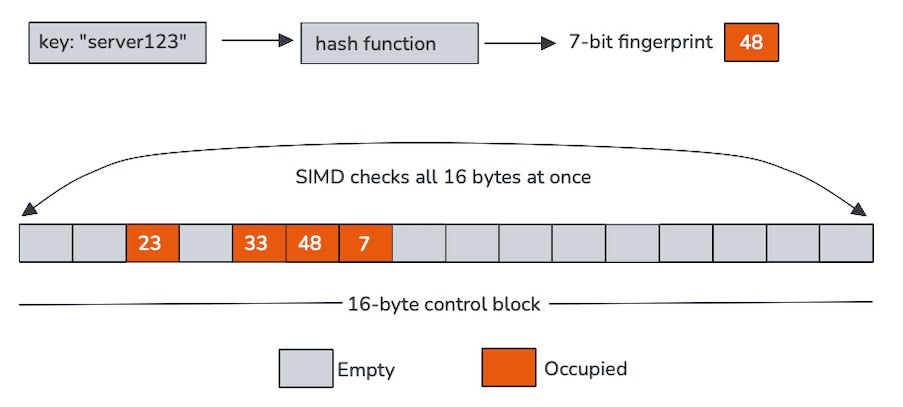
Las tablas hash tradicionales pasan mucho tiempo persiguiendo punteros o cargando claves solo para descubrir que no coinciden. La característica definitoria de las tablas suizas es la capacidad de rechazar la mayoría de las sondas usando una pequeña estructura de matriz residente en caché, almacenada separadamente de las claves y valores, llamadas bytes de control, para reducir significativamente el tráfico de memoria.
Cada byte de control representa un solo slot y, en nuestro caso, codifica dos cosas: si el slot está vacío y una huella corta derivada del hash. Estos bytes de control están dispuestos de forma continua en la memoria, típicamente en grupos de 16, lo que los hace ideales para el procesamiento de una sola instrucción y múltiples datos (SIMD).
En lugar de sondear una ranura a la vez, las tablas suizas escanean todo un bloque de bytes de control utilizando instrucciones vectoriales. En una sola operación, la CPU compara la huella digital de la clave entrante con 16 ranuras y filtra las entradas vacías. Solo los pocos candidatos que sobreviven a esta ruta rápida requieren cargar y comparar las claves reales.
Este diseño intercambia una pequeña cantidad de metadatos adicionales por una mejor localización de caché y muchas menos cargas aleatorias. A medida que la tabla crece y las cadenas de sonda se alargan, esas propiedades se vuelven cada vez más valiosas.
SIMD en el centro
La verdadera estrella del espectáculo es SIMD.
Los bytes de control no solo son compactos, sino que también están diseñados explícitamente para ser procesados con instrucciones vectoriales. Una sola comparación SIMD puede verificar 16 huellas dactilares a la vez, lo que convierte lo que normalmente sería un bucle en un puñado de operaciones amplias. Por ejemplo:
En la práctica, esto significa:
- Menos ramas.
- Cadenas de sondeo más cortas.
- Menos cargas de la memoria de claves y valores.
- Mucho mejor utilización de las unidades de ejecución de la CPU.
La mayoría de las búsquedas nunca pasan del escaneo de bytes de control. Cuando lo hacen, el trabajo restante es enfocado y previsible. Este es precisamente el tipo de carga de trabajo en el que destacan las CPU modernas.
SIMD bajo el capó
Para los lectores a quienes les gusta echar un vistazo por dentro, aquí está lo que sucede al insertar una nueva clave en la tabla. Utilizamos la API Panama Vector con vectores de 128 bits, por lo que opera en 16 bytes de control en paralelo.
El siguiente fragmento muestra el código generado en un Intel Rocket Lake con AVX-512. Aunque las instrucciones reflejan ese entorno, el diseño no depende de AVX-512. Las mismas operaciones vectoriales de alto nivel se emiten en otras plataformas usando instrucciones equivalentes (por ejemplo, AVX2, SSE o NEON).
Cada instrucción tiene una función clara en el proceso de inserción:
vmovdqu: Carga 16 bytes de control consecutivos en el registroxmm0de 128 bits.vpbroadcastb:Replica la huella digital de 7 bits de la nueva clave en todos los carriles del registroxmm1.vpcmpeqb: Compara cada byte de control con la huella digital transmitida, lo que genera una máscara de posibles coincidencias.kmovq+test: Mueve la máscara a un registro de propósito general y comprueba rápidamente si existe una coincidencia.
Finalmente, decidimos sondear grupos de 16 bytes de control a la vez, ya que las pruebas de rendimiento mostraron que expandirse a 32 o 64 bytes con registros más amplios no proporcionaba ningún beneficio de rendimiento medible.
Integración en ES|QL
Adoptar el hash al estilo suizo en Elasticsearch no fue solo un reemplazo inmediato. ES|QL tiene exigencias estrictas en cuanto a contabilidad de memoria, seguridad e integración con el resto del motor de cálculo.
Integramos la nueva tabla hash estrechamente con la gestión de memoria de Elasticsearch, que incluye el reciclador de páginas y la contabilidad del interruptor de circuito, lo que garantiza que las asignaciones permanezcan visibles y limitadas. Las agregaciones de Elasticsearch se almacenan densamente y se indexan por un ID de grupo, lo que mantiene el diseño de memoria compacto y rápido para la iteración, además de habilitar ciertas optimizaciones de rendimiento al permitir el acceso aleatorio.
Para las claves de bytes de longitud variable, almacenamos en caché el hash completo junto con el ID del grupo. Esto evita la recomputación de costosos códigos hash durante el sondeo y mejora la localidad de la caché al mantener los metadatos relacionados juntos. Durante el reprocesamiento, podemos confiar en el hash en caché y en los bytes de control sin inspeccionar los valores en sí, lo que mantiene bajos los costos de redimensionamiento.
Una simplificación importante en nuestra implementación es que las entradas nunca se eliminan. Esto elimina la necesidad de marcadores (marcadores para identificar ranuras previamente ocupadas) y permite que las ranuras vacías permanezcan verdaderamente vacías, lo que mejora aún más el comportamiento de la sonda y mantiene eficientes los escaneos de bytes de control.
El resultado es un diseño que se ajusta naturalmente al modelo de ejecución de Elasticsearch a la vez que preserva las características de rendimiento que hacen atractivas a las tablas suizas.
¿Cómo funciona?
En cardinalidades pequeñas, las tablas suizas rinden aproximadamente al mismo nivel que la implementación existente. Esto es lo que se espera: cuando las tablas son pequeñas, los efectos de la caché tienen menos importancia y hay poco que optimizar.
A medida que aumenta la cardinalidad, la imagen cambia rápidamente.
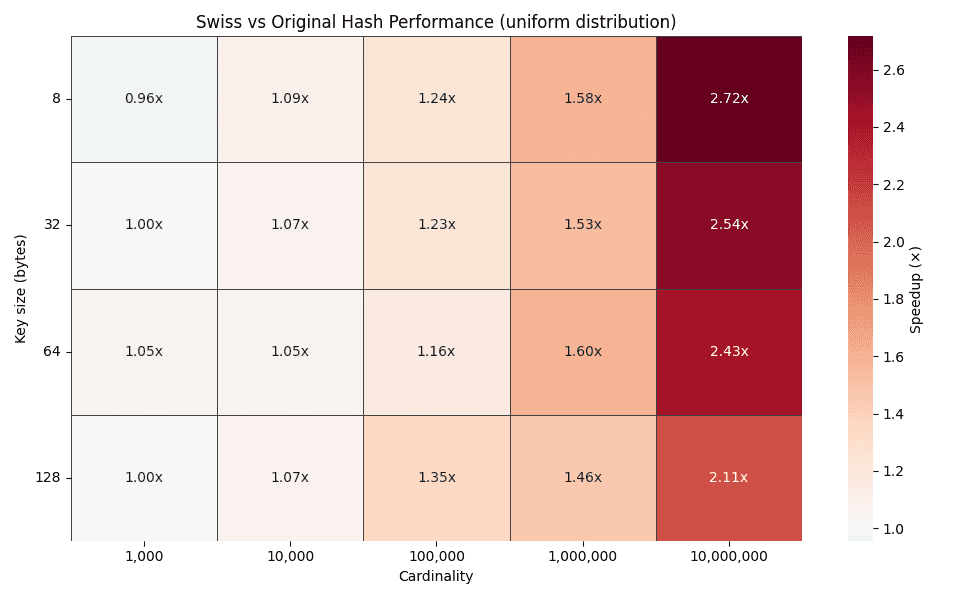
El mapa de calor anterior traza los factores de mejora del tiempo para diferentes tamaños de clave (8, 32, 64 y 128 bytes) en cardinalidades desde 1,000 hasta 10,000,000 de grupos. A medida que aumenta la cardinalidad, el factor de mejora aumenta constantemente, y llega a hasta 2–3x para distribuciones uniformes.
Esta tendencia es exactamente lo que predice el diseño. Una cardinalidad más alta conduce a cadenas de sondeo más largas en las tablas hash tradicionales, mientras que el sondeo de estilo suizo continúa resolviendo la mayoría de las búsquedas dentro de los bloques de bytes de control amigables con SIMD.
El comportamiento de la caché cuenta la historia
Para comprender mejor las aceleraciones, ejecutamos el mismo JMH benchmarks en Linux perf y capturamos estadísticas de caché y TLB.
En comparación con la implementación original, la versión suiza realiza aproximadamente un 60% menos de referencias de caché en general. Las cargas de la caché de último nivel disminuyen más de 4 veces, y los fallos de carga de la LLC caen en más de 6 veces. Dado que las omisiones de LLC a menudo se traducen directamente en accesos a la memoria principal, esta reducción por sí sola explica una gran parte de la mejora de extremo a extremo.
Más cerca de la CPU, vemos menos pérdidas de caché de datos L1 y casi 6 veces menos pérdidas TLB de datos, lo que apunta a una localidad espacial más estrecha y patrones de acceso a la memoria más predecibles.
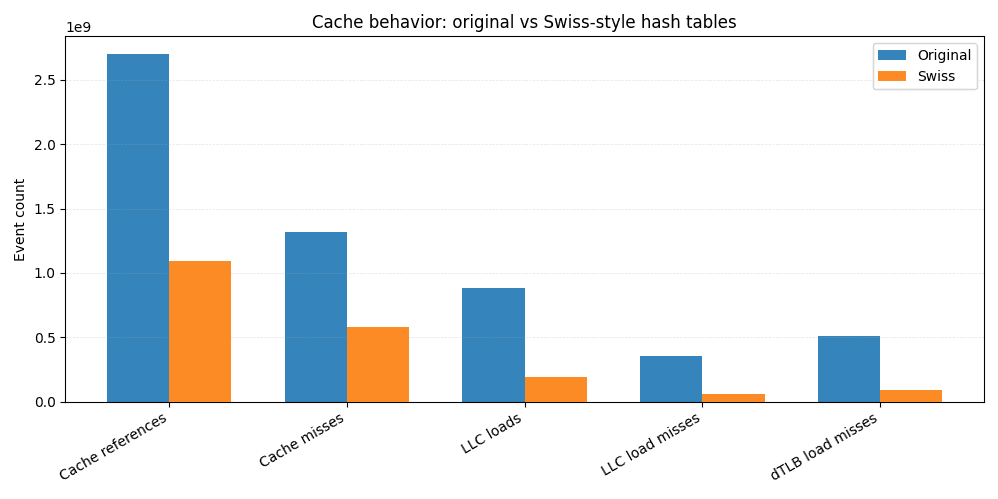
Esta es la recompensa práctica de los bytes de control compatibles con SIMD. En lugar de cargar repetidamente claves y valores desde ubicaciones de memoria dispersas, la mayoría de las pruebas se resuelven escaneando una estructura compacta residente en la caché. Menos memoria afectada significa menos fallos, y menos fallos significan consultas más rápidas.
Resumen
Al adoptar un diseño de tabla hash al estilo suizo y al inclinarnos por el sondeo amigable con SIMD, logramos una velocidad de 2 a 3 veces mayor para cargas de trabajo de estadísticas ES|QL de alta cardinalidad, junto con un rendimiento más estable y predecible.
Este trabajo destaca cómo las estructuras de datos modernas con conocimiento de CPU pueden desbloquear ganancias sustanciales, incluso para problemas bien conocidos, como las tablas hash. Hay más para explorar aquí, como especializaciones adicionales de tipo primitivo y el uso en otras rutas de alta cardinalidad, como las uniones, que son solo parte del esfuerzo más amplio y continuo para modernizar continuamente los internos de Elasticsearch.
Si te interesan los detalles o quieres seguir el trabajo, echa un vistazo a esta solicitud de extracción y problema meta en Github.
¡Feliz hash!
Contenido relacionado

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.
12 de diciembre de 2025
Introducción del soporte de Elasticsearch en Google MCP Toolbox for Databases
Descubre cómo el soporte de Elasticsearch ya está disponible en Google MCP Toolbox for Databases y aprovecha las herramientas ES|QL para integrar de forma segura tu índice con cualquier cliente MCP.
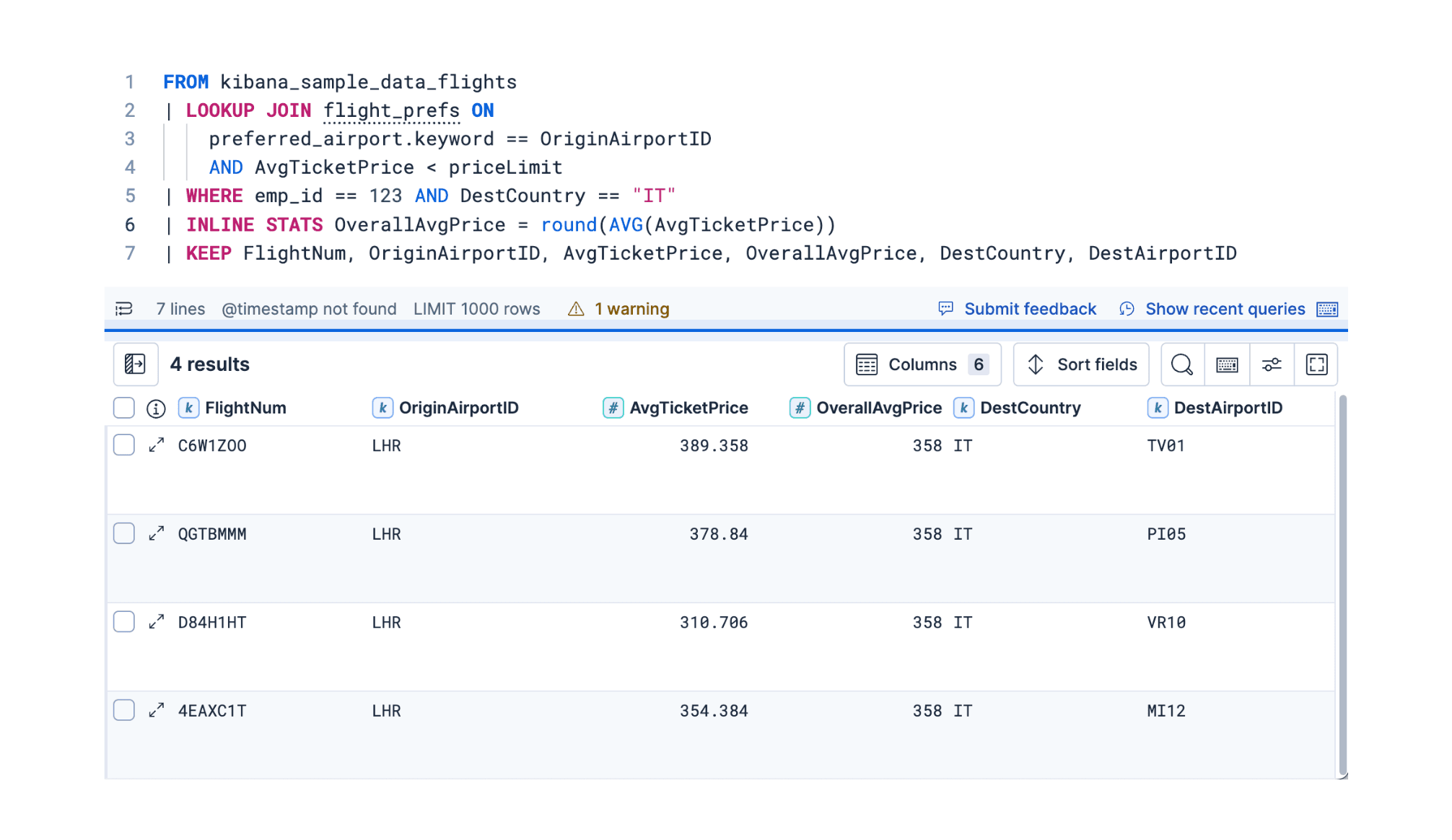
2 de diciembre de 2025
ES|QL en la versión 9.2: incorporación de la búsqueda inteligente (Lookup Joins) y compatibilidad con series temporales
Explora tres actualizaciones separadas de ES|QL en Elasticsearch 9.2: un LOOKUP JOIN mejorado para una correlación de datos más expresiva, el nuevo comando TS para análisis de series temporales y el comando flexible INLINE STATS para la agregación.

18 de septiembre de 2025
ES| de ElasticsearchExperiencia en el editor QL frente al analizador de eventos PPL de OpenSearch
Descubre cómo ES|Las funciones avanzadas de QL Editor aceleran tu flujo de trabajo, en contraste directo con el enfoque manual del PPL Event Analyzer de OpenSearch.

Presentamos el ES|Generador de consultas QL para el cliente Ruby de Elasticsearch
Aprende a usar el recientemente lanzado ES|Generador de consultas QL para el cliente Ruby de Elasticsearch. Una herramienta para construir ES|QL consulta más fácilmente con código Ruby.